OCI Release Notes 2024
12월 OCI AI/ML 업데이트 소식
Table of Contents
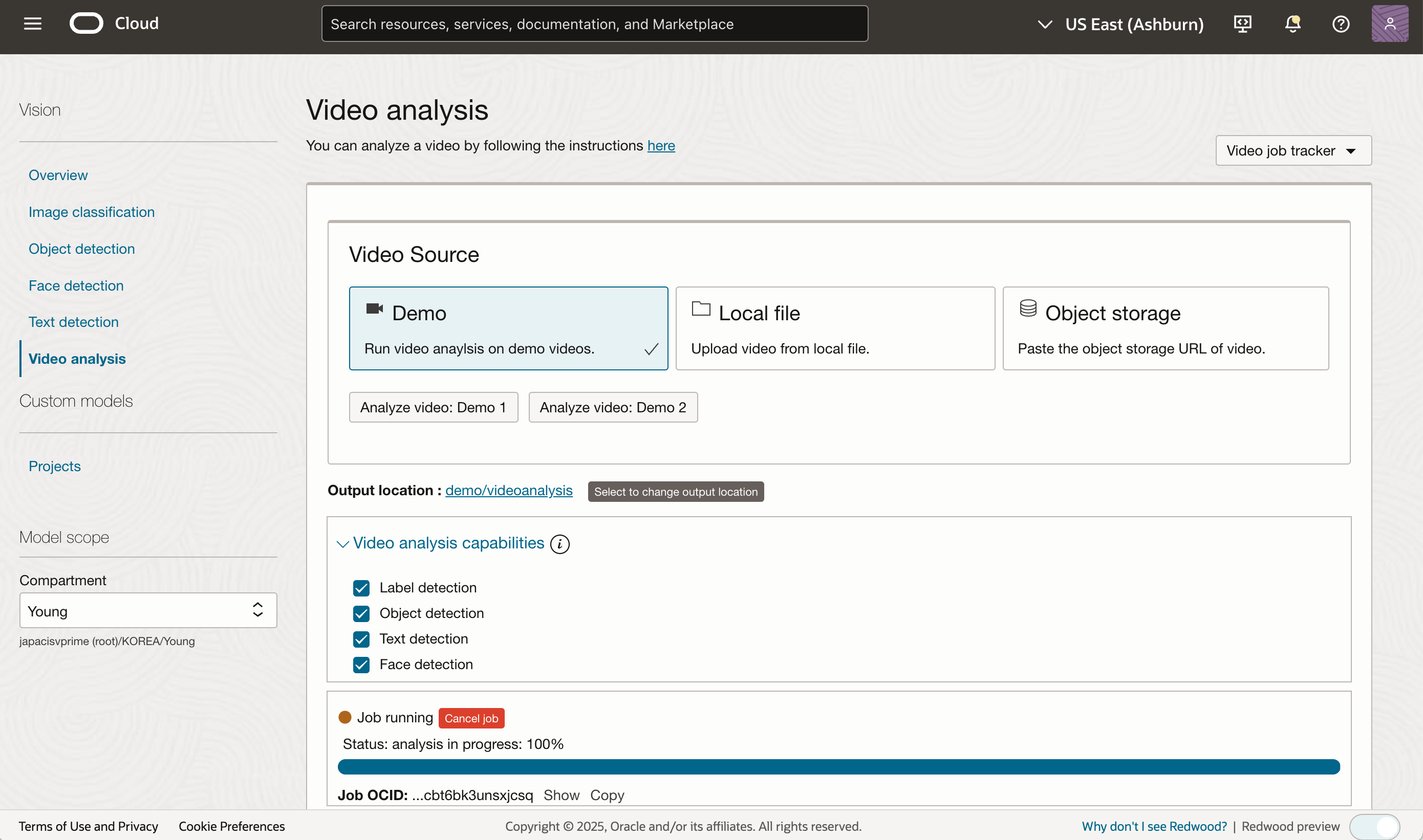
Vision Service now Supports Stored Video Analysis
- Services: Vision
- Release Date: December 17, 2024
- Documentation: https://docs.oracle.com/en-us/iaas/releasenotes/vision/stored-video.htm
업데이트 내용
OCI Vision 서비스를 사용하면 저장된 비디오(Stored Video)를 분석하여
각 프레임에서 레이블(Label) 식별, 이미지 분류(Classification), 객체(Object) 및 얼굴(Face) 감지를 수행할 수 있습니다.
비디오 업로드 옵션
비디오를 처리하기 위해 두 가지 업로드 방법을 제공합니다:
- 로컬 저장소(Local Storage)에서 비디오 업로드
- 오브젝트 스토리지(Object Storage)에서 비디오 업로드
지원 기능 (Supported Features)
또한, 사전 학습된 모델(Pretrained Models)을 사용할 수도 있으며,
사용자가 직접 맞춤형 모델(Custom Models)을 학습하여 비디오를 처리할 수도 있습니다.
지원 리전 (Stored Video Analysis 지원 리전)
| 리전 이름 | 위치 | 리전 식별자 (Region Identifier) | 리전 키 (Region Key) |
|---|---|---|---|
| 미국 동부 (Ashburn) | 애쉬번, VA | us-ashburn-1 | IAD |
| 영국 남부 (London) | 런던 | uk-london-1 | LHR |
| 미국 서부 (Phoenix) | 피닉스, AZ | us-phoenix-1 | PHX |
추가 정보
OCI Vision 서비스에 대한 자세한 내용은 공식 문서를 참고하세요.
New RAG Features in OCI Generative AI Agents
- Services: Generative AI Agents
- Release Date: December 18, 2024
- Documentation: https://docs.oracle.com/en-us/iaas/releasenotes/generative-ai-agents/new-RAG-features.htm
업데이트 내용
OCI 생성형 AI 에이전트 - 새로운 기능 및 개선 사항
더 상세한 인용 정보 (More Detailed Citations)
- 기존의 관련 정보 제공 기능에 더해, 문서 제목 및 페이지 정보를 반환하여 보다 풍부한 컨텍스트(Context)를 제공합니다.
에이전트 응답을 위한 선택적 지침 필드 (Optional Instruction Field for Agent’s Responses)
- 유연성과 제어 향상을 위해, 에이전트의 RAG (Retrieval-Augmented Generation) 응답에 선택적인 지침을 추가할 수 있습니다.
- 예를 들어, 특정 방식으로 프롬프트에 응답하도록 지시할 수 있습니다.
Meta Llama LLM 이용 약관 동의 (Meta Llama LLM Agreement Terms)
- 법적 요구 사항을 준수하기 위해, 에이전트를 생성할 때 Meta Llama LLM 약관에 동의해야 합니다.
선택적 멀티모달(Multi-Modal) 분석 기능 (Optional Multi-Modal Parsing Feature)
- 에이전트가 데이터 소스의 문서에서 차트 및 그래프 정보를 포함할 수 있도록,
- 데이터 소스를 생성하거나 편집할 때 멀티모달 분석 기능을 활성화할 수 있습니다.
지식 베이스 크기 정보 제공 (Knowledge Base Size Information)
- 지식 베이스의 저장 크기를 확인하는 방법:
GetKnowledgeBaseAPI 호출- OCI 콘솔(Console)에서 해당 지식 베이스의 상세 페이지를 통해 확인
장시간 실행되는 데이터 수집 작업 지원 (Long Running Ingestion Jobs)
- 24시간 이상 실행되는 대규모 데이터 수집 작업을 위해,
- Generative AI Agents가 리소스 프린시플(Resource Principals)을 지원합니다.
- 이 기능을 활용하면 대량의 콘텐츠를 효율적으로 수집할 수 있습니다.
사용자 지정 Object Storage 메타데이터를 통한 인용 링크 재정의 (Citation Link Override Through Custom Object Storage Metadata)
- 인용(citation) 관리 시, Object Storage의 인용 링크를 사용자 지정 URL로 변경할 수 있습니다.
- 설정 방법:
- Object Storage의 각 객체에
customized_url_source라는 메타데이터 추가 - 해당 메타데이터 값으로 사용자 지정 URL 입력
- Object Storage의 각 객체에
추가 정보
- OCI 생성형 AI 에이전트에 대한 자세한 내용은 공식 문서를 참고하세요.
이 글은 개인적으로 얻은 지식과 경험을 작성한 글로 내용에 오류가 있을 수 있습니다. 또한 글 속의 의견은 개인적인 의견으로 특정 회사를 대변하지 않습니다.
Younghwan Cho RELEASE-NOTES-2024-AIML
oci-release-notes-2024 Dec-2024 AI/ML Gen AI