HPC
OCI HPC 소개 및 HPC Cluster 구성 실습
Table of Contents
서비스 소개
이번 글에서는 고성능 컴퓨팅이 필요한 업무를 지원할 수 있는 오라클 클라우드(OCI) 의 HPC 서비스에 대해서 알아보도록 하겠습니다. HPC 는 다양한 산업군 즉 제조, 항공, 자동차 분야 등 High Tech 산업 분야에서 고성능 컴퓨팅 자원이 필요한 경우 많이 사용되고 있습니다. 특히 연구 분야에서는, 빅데이터 분석 혹은 ML/AI 등의 분야에서 학습을 위한 컴퓨팅 자원으로써 HPC를 활용하고 계시구요. 물리 모델을 빠르게 시뮬레이션하기 위한 유체 역학 (Fluid Dynamics) 분야라던지, 생명 공학 (Life Science) R&D 분야에서는 게놈 모델링 및 분자에 대한 Virtual Screening 등을 위해 사용하고 있습니다.
HPC 분야 도전 과제
High Performance Computing 이 요구가 되는 업무들을 On-Premise 에서 동작시킬때 맞닥뜨리게 되는 어려움은 용량 계획 및 장비 수급의 어려움등이 있습니다.
- 용량 Planning - 최초 구입한 H/W 용량에 추가 용량이 필요 시 용량 증설의 어려움 및 H/W의 적시 공급 및 조달
- 비용 - 과잉 Provisioning 시 과잉 지출 및 H/W 운영 비용, 전력 비용, H/W, S/W 비용 등 다양한 비용 발생
- 운영 최적화 - 유휴 자원들에 대한 회수 및 자원 재분배의 어려움
이런 HPC 분야의 다양한 어려움들을 해결할 수 있는 적절한 대안이 클라우드 컴퓨팅이 될 수 있습니다.
OCI HPC 소개
HPC 를 위해 필요한 구성 요소는 아주 간단합니다. 딱 세가지 고성능 CPU 를 탑재한 컴퓨팅이 필요하구요. 두번째로, 컴퓨팅 과정에서 발생하는 여러가지 파일 및 데이터를 저장하고 Access 하는 고성능 스토리지, 마지막이 병렬 컴퓨팅을 수행할 수 있는 고성능 네트워크 지원이 필수적입니다.

- OCI 컴퓨팅 서비스 - OCI 컴퓨팅 서비스에서 제공하는 서버들에 탑재된 프로세서들을 살펴보면 고성능의 CPU 프로세서들을 탑재하고 있습니다. AMPERE 사의 알트라 프로세서, AMD 사의 EPYC 프로세서, 인텔의 Skylake, Icelake 프로세서, NVIDIA 의 GPU 프로세서등 워크로드 형태에따라 프로세서를 선택하여 사용할 수가 있습니다.

- OCI 스토리지 서비스 - OCI 에 탑재된 스토리지 서비스는 기본적으로 NVMe SSD 기반으로 고성능을 보장합니다. Block 스토리지, NFS 기반의 File Storage Service, 대용량 파일 저장을 위한 저비용 Object 스토리지 등 용도에 맞는 다양한 스토리지를 HPC 와 함께 구성하여 사용 가능합니다. 또한 HPC 에서 중요하게 요구되는 병렬 파일 처리 시스템을 위해 마켓플레이스에서 제공하는 HPC File System 이라는 구성을 통해 심플하게 병렬 파일 처리 시스템을 구축하실 수 있습니다. 병렬 처리 시스템을 위한 툴로는 IBM Spectrum 이나 BeeGFS 등을 마켓플레이스에서 쉽게 사용할 수 있도록 지원합니다.
- OCI 네트워킹 서비스 - HPC 를 위해 가장 중요한 사항 중의 하나는 병렬 처리를 위한 클러스터 네트워킹입니다. OCI는 노드간 HPC 병렬처리 및 고성능 데이터베이스와의 통신을 위해 1.5 마크크로세컨드의 레이턴시를 제공하는 RDMA 기반의 클러스터 네트워크를 제공합니다. 이러한 Cluster RDMA 네트워크를 통해 On-Premise 에서 구축되어 있는 병렬처리를 위한 Infiniband 네트워킹과 동일한 클러스터 네트워크를 이용하실 수 있습니다.
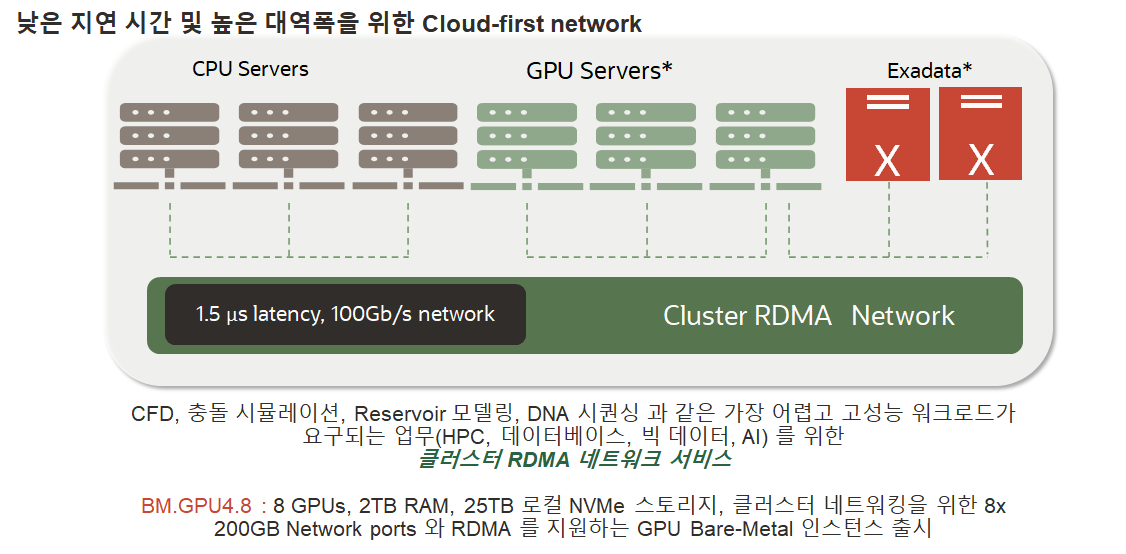
- OCI RDMA Network 주요 특징
- 100 Gbps 네트워크 인터페이스 카드 (RDMA over converged Ethernet (RoCE) v2)
- RDMA switch 에 직접 CPU, GPU, Exadata DB 서버들을 연결
- Cluster Networking – 단일 RDMA cluster 에 20,000 코어 지원
- No hypervisor, No virtualization, No jitter bare metal HPC
- 속도 : 1.5 µs latency, 100Gb/s
- Marketplace 의 HPC Cluster Stack 구성 시 RDMA 네트워크 자동 구성 지원
- 다양한 HPC 구성 지원 - OCI 에서는 HPC 를 쉽게 구성할 수 있는 다양한 구성 방법들을 마켓플레이스에서 제공합니다. HPC Cluster 를 비롯한 HPC File System, CFD Ready Cluster 등 보다 HPC Cluster 를 손쉽게 구성하고 바로 사용이 가능하도록 Deploy 가 자동화된 툴들을 제공합니다.
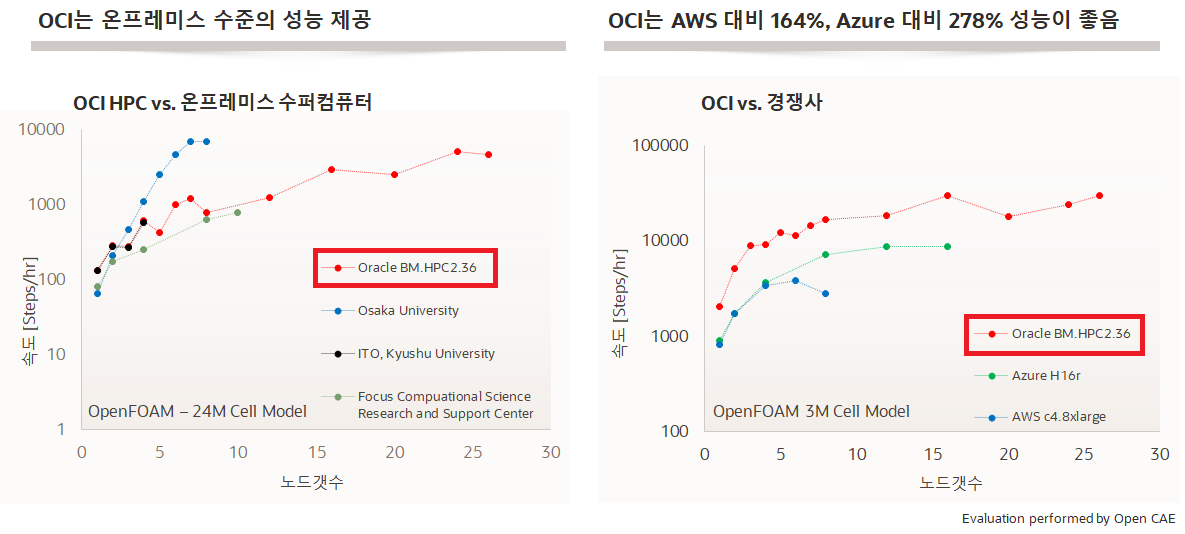
- OCI HPC 성능 비교 - 다음 그림은 OCI HPC vs. On-Premise Super Computer 에 대한 비교와 OCI HPC 와 타사 클라우드 Provider 의 HPC 에 대한 성능 비교 그래프입니다. 좌측 그래프는 오라클 HPC 와 On-Premise 수퍼컴퓨터들과 성능 측정을 한 그래프인데요. OCI HPC 가 On-Prem 수퍼 컴퓨터와 유사한 성능을 보이 것을 나타내고 있고, 오른쪽 그래프는 AWS, Azure 등과 성능 비교한 그래프인데 OCI HPC 가 가장 성능이 빠른 것을 나타내고 있습니다.
다음 장부터는 OCI 에서 제공하는 HPC Cluster 를 구성하고 사용하는 방법에 대해 실습해 보도록 합니다.
OCI HPC Cluster 구성 따라하기
사전 준비 사항
OCI HPC 를 Provisioning 하려면 먼저, 사전에 아래와 같은 사항들이 준비되어야 합니다.
- HPC 로 사용하는 BM.HPC2.36, BM.Optimized3.36, BM.GPU4.8 등의 자원들을 생성할 수 있도록 Service Limit 확인 및 부족 시 확장
- HPC 가 위치하게 될 구획 (Compartment)
- Bastion/Headnode Host Access 를 위한 SSH Public Key 와 Private Key (※ Key가 없을 경우, Provisioning 화면에서 key 다운로드가 가능함)
OCI HPC 아키텍쳐 이해
OCI 마켓플레이스에서 제공하는 HPC는 아래와 같은 아키텍쳐로 자동 Provisioning 을 수행합니다.
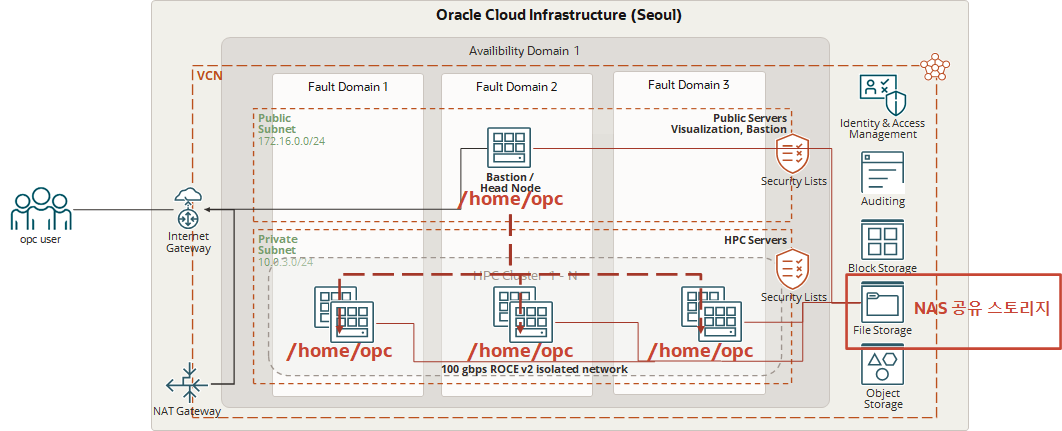
프로비져닝된 Cluster 에는 기본적으로 Bation/Headnode 와 Bare Metal (BM) 장비들이 Cluster 환경으로 묶이게 됩니다. Cluster 된 환경은 opc 사용자 계정으로 “/home/opc” 위치가 NFS 로 묶이게 됩니다. 또한 추가적으로 NAS 공유 스토리지 역할을 하는 File Storage 도 자동으로 선택적으로 프로비저닝할 수 있습니다.
- Bastion opc 계정의 홈디렉토리인 “/home/opc” 에 필요 S/W 설치 시 모든 BM Node 들에도 자동 반영 (NFS Sharing)
- Bastion opc 계정의 프로파일 (.bash_profile, .bashrc 등) 변경 시 BM Node 들에도 자동 반영
- HPC Software (OpenMM, Ansys, StarMM 등) 설치 필요 시 “/home/opc” 홈디렉토리에 한번 설치 시 다른 BM Node 들에서 함께 사용 가능하게 됨
- S/W 설치 시 Bastion 서버 의 Boot Volume 이 부족할 경우, Boot Volume 추가 가이드를 참조하여 Volume 확장
OCI HPC Cluster 검색 - Marketplace
OCI HPC Cluster 는 Marketplace 에서 검색을 통해 Terraform Stack 을 생성하게 됩니다. Marketplace 에서 HPC Cluster 를 검색해서 사용하는 방법을 알아봅니다.
OCI Console 메뉴에서 “Marketplace” 을 선택합니다.
Marketplace 에서 키워드 “HPC” 를 입력 후 나온 결과 화면 중 “HPC Cluster” 메뉴를 클릭합니다.
- OCI HPC Cluster Stack 이 동작하게 되면 아래와 같이 OCI 의 Resource 들 및 HPC 사용을 위한 Open Source 툴들이 설치됩니다.
- OCI Resources
- Virtual Cloud Network
- NFS (File Storage Service / Mount Target)
- Compute (B-astion Node)
- Compute (HPC Cluster Node)
- RDMA Cluster Network
- Instance Pool
- Instance Configuration
- Monitoring 용 MySQL DB Cloud
- Opne Source 3rd Party 툴
- Influxdb
- Open Ldap
- Telegraf
- Grafana
- SLURM
OCI HPC Cluster Stack 생성
- OCI Resources
마켓플레이스의 검색을 통해 찾은 HPC Cluster Automated Deployment 툴 화면에서 Stack 을 저장할 Compartment 를 선택 후 “스택 실행” 버튼을 클릭합니다.
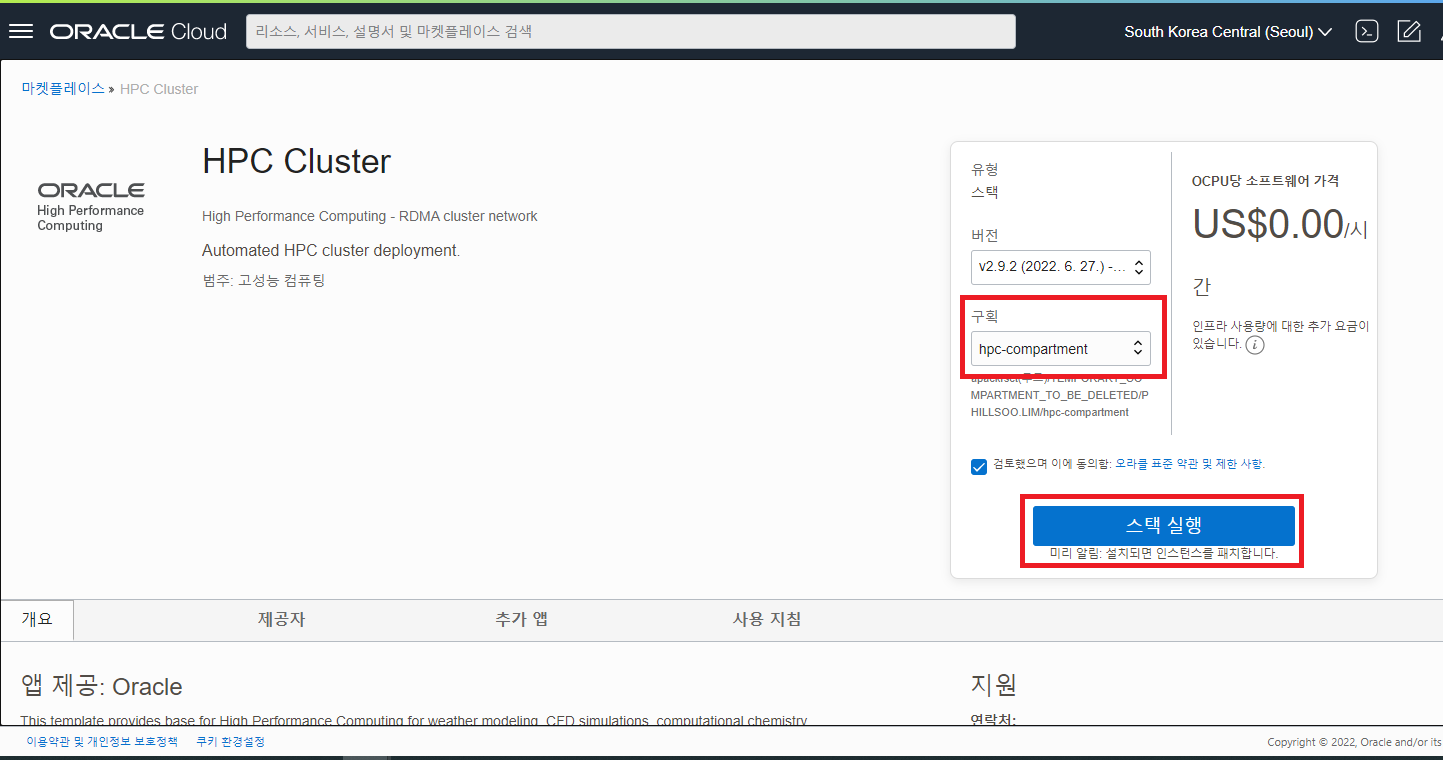
스택 생성 화면이 나타나며 HPC Cluster Stack 의 이름과 설명을 입력합니다. 아래로 스크롤 다운하여 앞 화면에서 선택했던 구획(Compartment)이 잘 선택되어 있는지 확인 후 다음 버튼을 클릭합니다.
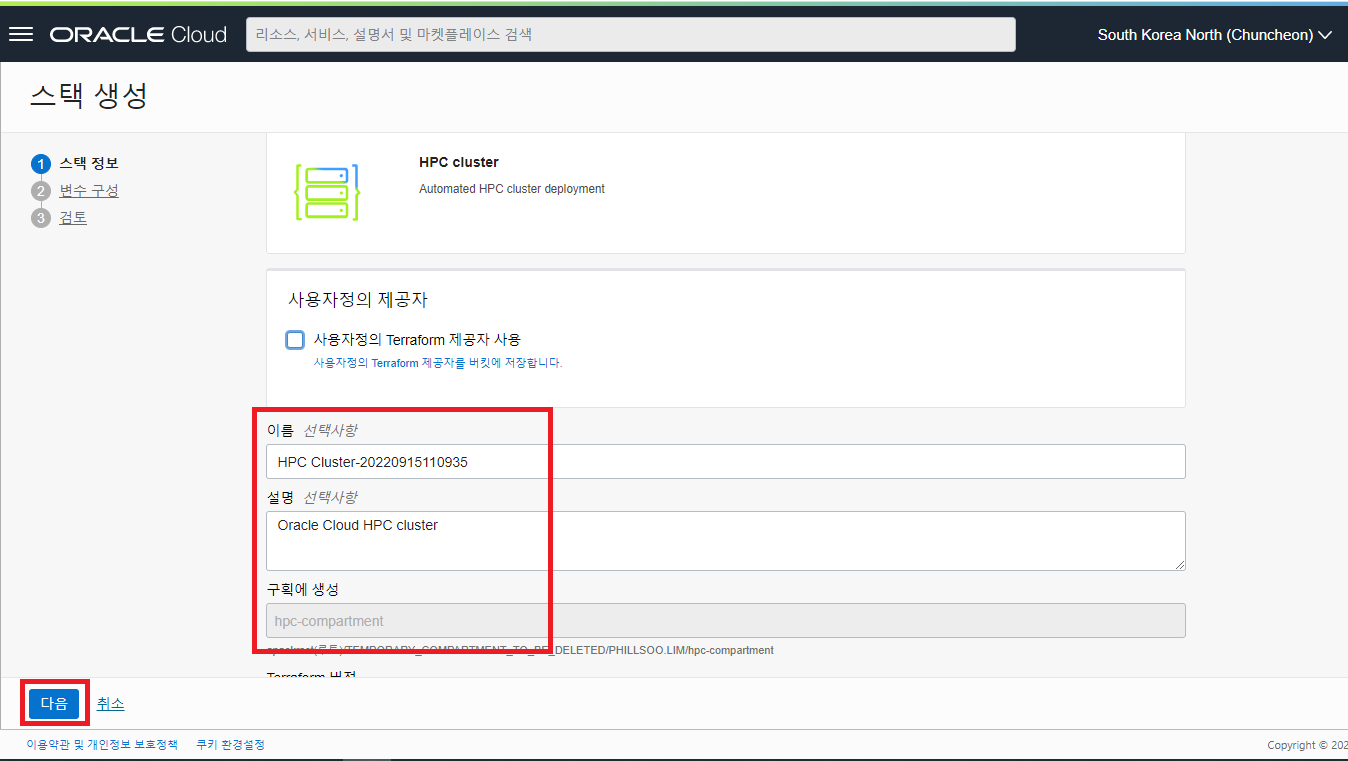
- 다음 화면은 Cluster 를 구성할때 사용할 HPC 이미지, VCN 네트워크, NFS 스트로지 옵션, HPC 와 관련된 각종 S/W 설치를 선택할 수 있는 다양한 옵션들이 나타납니다. Cluster Configuration 화면에서 HPC Cluster 가 위치할 target compartment 와 SSH 로 접근 시 사용할 ssh key, 사용할 cluster name 등을 지정 후 스크롤 다운 합니다.
- Cluster Name 은 반드시 12자 이하로 입력합니다. HPC Cluster 에서 설치되는 OpenLDAP 의 제약 사항 중 OCI 의 VCN 과 합쳐진 FQDN 의 총 길이가 64자로 제한이 있어 12자가 넘을 경우 Cluster 생성의 오류가 발생할 수 있습니다.
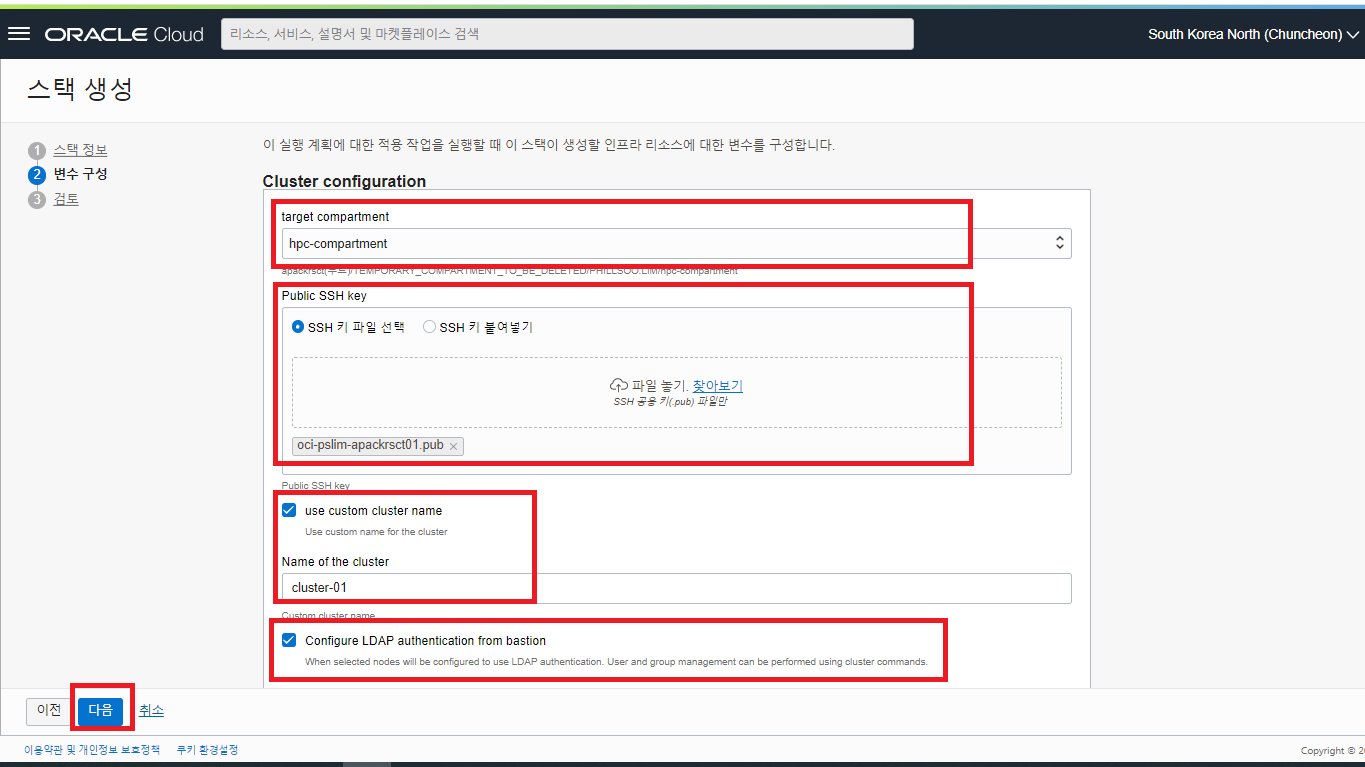
- Headnode Options 입력 항목들을 선택 또는 입력합니다.
- Availability Domain : 화면과 같이 HPC Cluster 를 위치시킬 AD 를 선택합니다.
- bastion_shape : Headnode 의 VM Shape 을 선택합니다.
- bastion_ocpus : Headnode 의 CPU 갯수를 입력해 줍니다. (Default 2 OCPU)
- Use custom memory size : 해당 체크박스 선택 시 Headnoe 가 사용할 Memory Size 를 입력할 수 있게 됩니다. (Default 16 GB)
- Size of the boot volume in GB : Headnode 가 사용할 Boot Volume 의 크기를 지정할 수 있습니다. 설치할 HPC S/W 의 사이즈가 클 경우, 충분한 공간으로 Boot Volume 의 사이즈를 잡아 줍니다. (Default : 50 GB, Max : 400 GB)
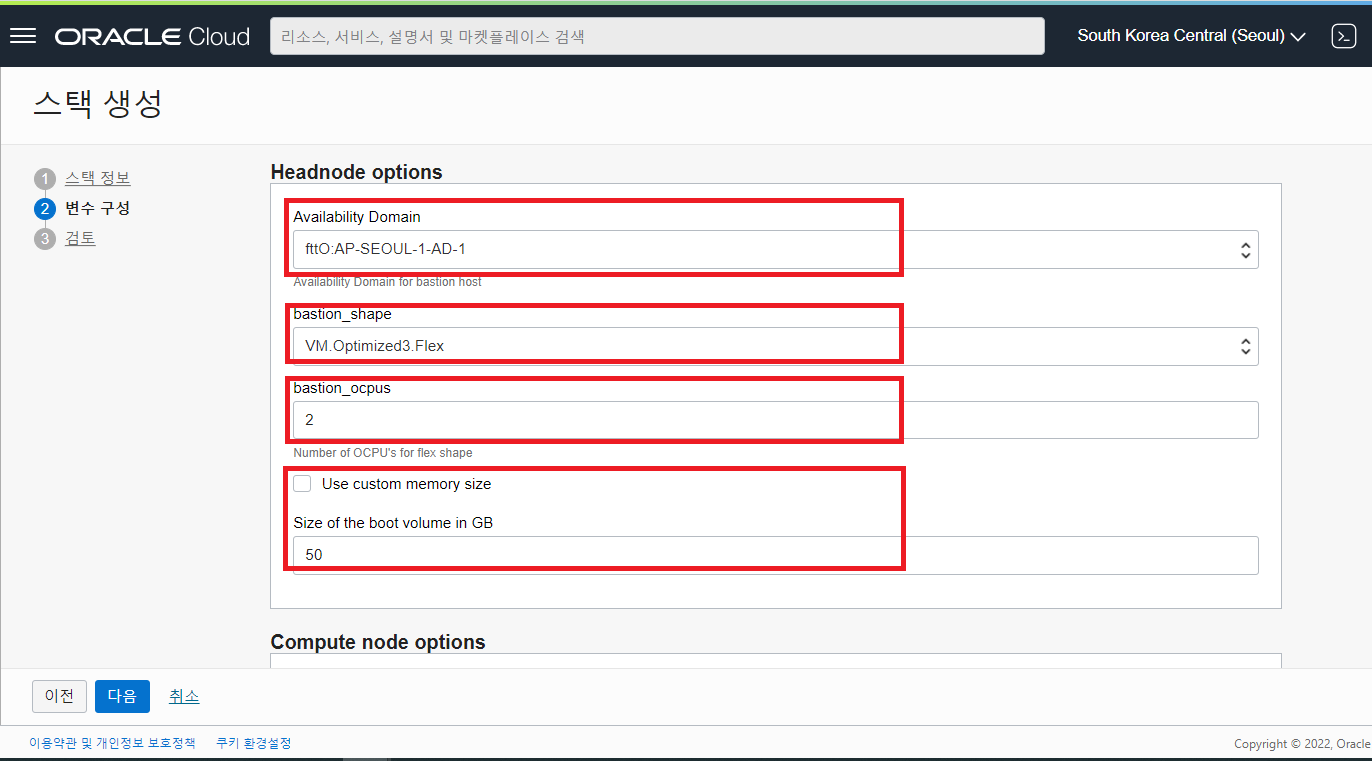
- Compute node Options 의 아래 입력 항목들을 선택 또는 입력 후 아래로 스크롤 다운합니다.
- Availability Domain : 화면과 같이 HPC Cluster 를 위치시킬 AD 를 선택합니다.
- Use cluster network : RDMA (ROCEv2) network 을 사용할 것인지 체크를 합니다. (Default RDMA 사용 체크)
- Shape of the Compute Nodes : HPC 의 Compute Node 로 활용할 Bare Metal 장비의 종류를 선택합니다. 현재 HPC Compute Node 를 위해 지원하는 Shape 은 아래와 같습니다.
BM.HPC2.36 : Intel Xeon Gold 6154 (Skylake) 3.7GHz. 384GB RAM 6.4TB NVME. 1x25Gb/s vNIC 사양의 Bare Metal 장비 BM.GPU4.8 : 클라우드에서 가장 빠른 GPU performance 제공. 8 x NVIDIA A100. 2 TB Mem 27.2 TB NVMe. NVIDIA GPU Cloud Platform. 100 Gb/s RDMA (RoCEv2) 사양의 Bare Metal GPU 탑재 장비 BM.Optimized3.36 : Intel Xeon Gold 6354 (Ice Lake) 3.6Ghz. 512GB RAM 3.84TB NVME. 2x50Gb/s vNIC 사양의 Bare Metal 장비 BM.HPC2.36 장비는 구형으로 일부 Region 에서는 사용 불가BM.Optimized3.36 Shape 을 선택 - 최신 X9 기반의 BM 장비
- Initial cluster size : HPC Compute Node 로 사용할 BM 장비의 댓수를 입력합니다.
- Hyperthreading enabled : 하이퍼 스레딩을 이용할지 여부를 체크 (사용 시 CPU 성능 20 ~ 30% 향상)
Size of the boot volume in GB : HPC Compute Node 가 사용할 Boot Volume 의 크기를 지정할 수 있습니다. 설치할 HPC S/W 의 사이즈가 클 경우, 충분한 공간으로 Boot Volume 의 사이즈를 잡아 줍니다. (Default : 50 GB, Max : 400 GB)
use marketplace image : 마켓플레이스에서 제공되는 이미지를 사용할 것인지 체크하는 항목입니다. 별도의 S/W 가 설치된 커스텀 이미지를 사용할 경우, 이 항목을 UNCHCEK 하면 커스텀 이미지를 선택할 수 있는 메뉴로 전환됩니다. (Default Check)
Image Version : HPC Compute Node 에 설치할 이미지를 지정하실 수 있습니다. 커스텀 이미지로 변경이 가능합니다. (Default 마켓플레이스 이미지 : 4.Oracle Linux 7.9 OFED 5.0-XXXX)
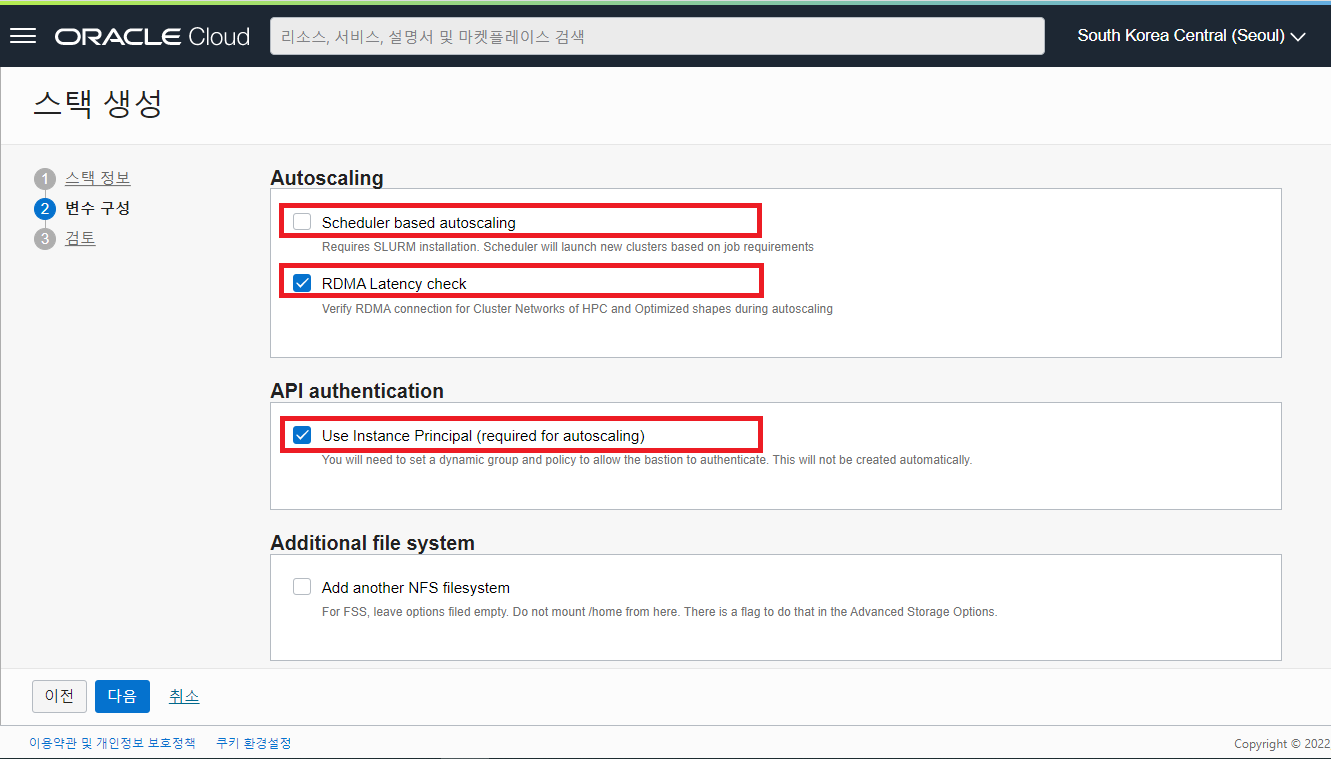
- Autoscaling 관련 체크 항목들을 그림과 같이 선택합니다.
- Scheduler based autoscaling : SLURM 기반의 Scheduler 를 설치할지 체크하는 것으로 Job 이 실행될때 새로운 클러스터를 launch 시킬 수 있습니다. (Default UNCHECK)
- RDMA Latency check : RDMA Connection 검증 (Default Check)
- API authentication 관련 체크 항목을 아래 그림과 같이 선택 후 아래로 스크롤 다운 합니다.
- Use Instance Principal (required for autoscaling) : (Default Check)
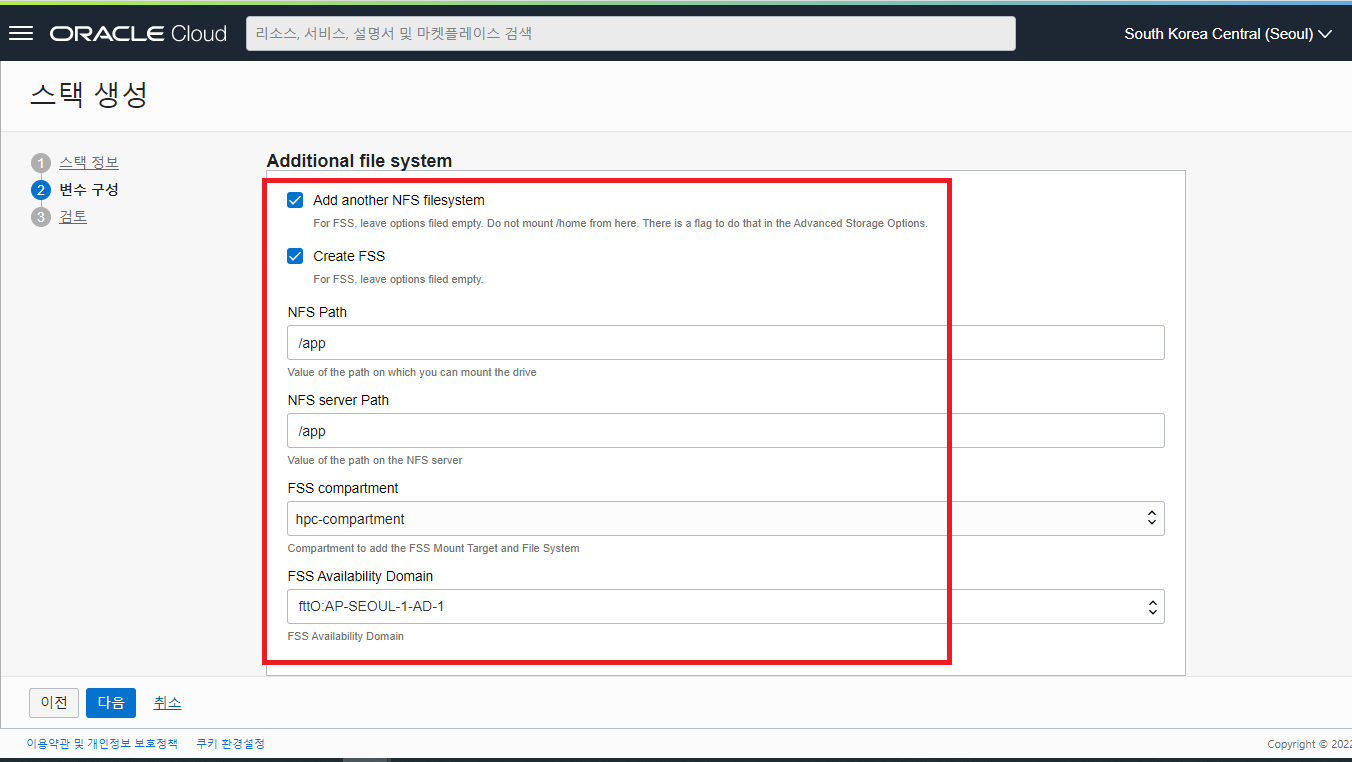
- Additional file system 관련 체크 항목을 아래 그림과 같이 선택합니다.
- Add another NFS filesystem : 이 옵션을 체크하지 않아도 기본적으로 HPC Compute Node들과 Headnode 가 함께 사용하는 NFS shared filesystem 이 생성됩니다. (※ /home/opc 디렉토리, 및 /nfs/cluster 디렉토리) 하지만, 별도로 공유 스토리지를 필요로하고 공유할 용량이 많을 경우를 위해 NFS filesystem 을 추가로 구성하는 옵션입니다. (Defualt UNCHECK)
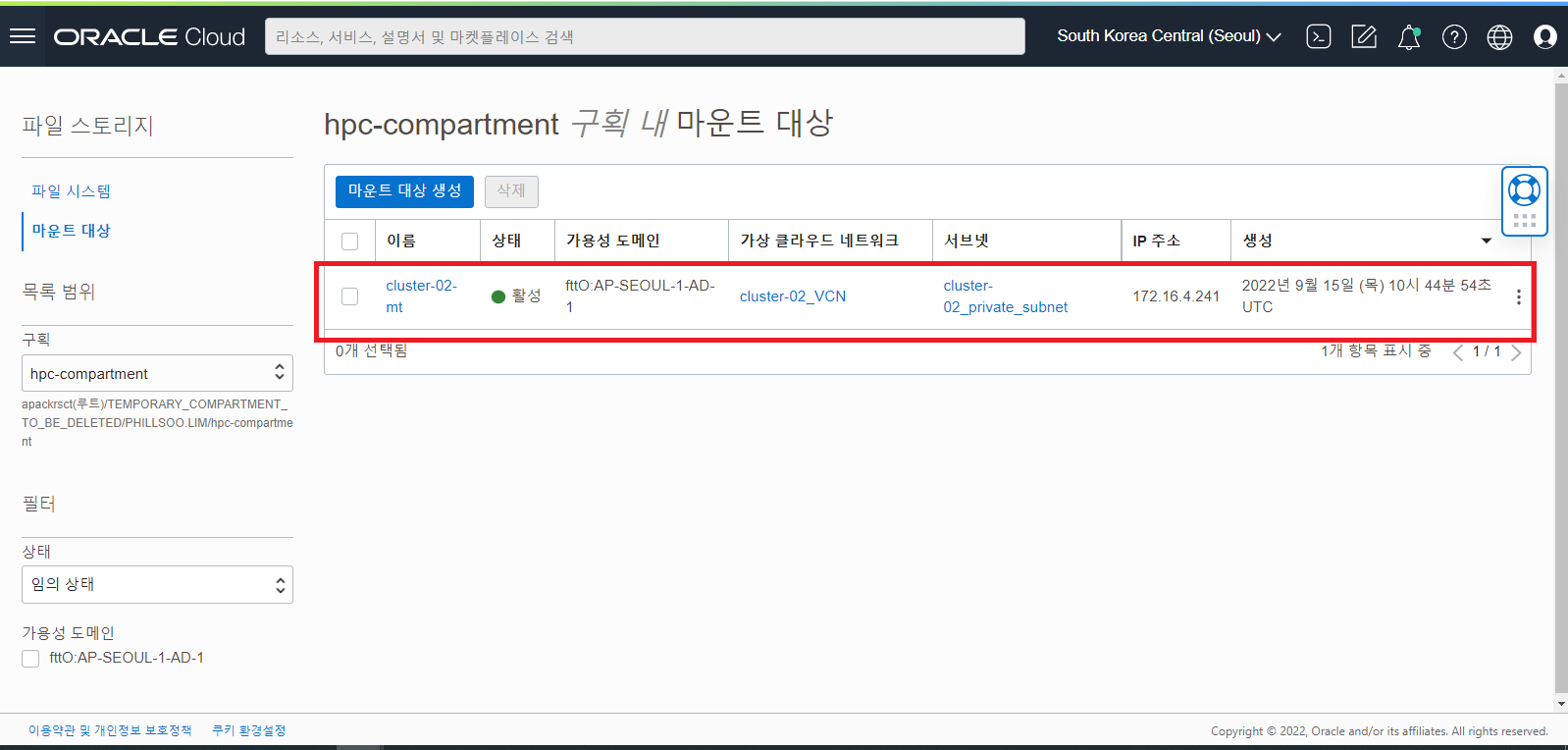
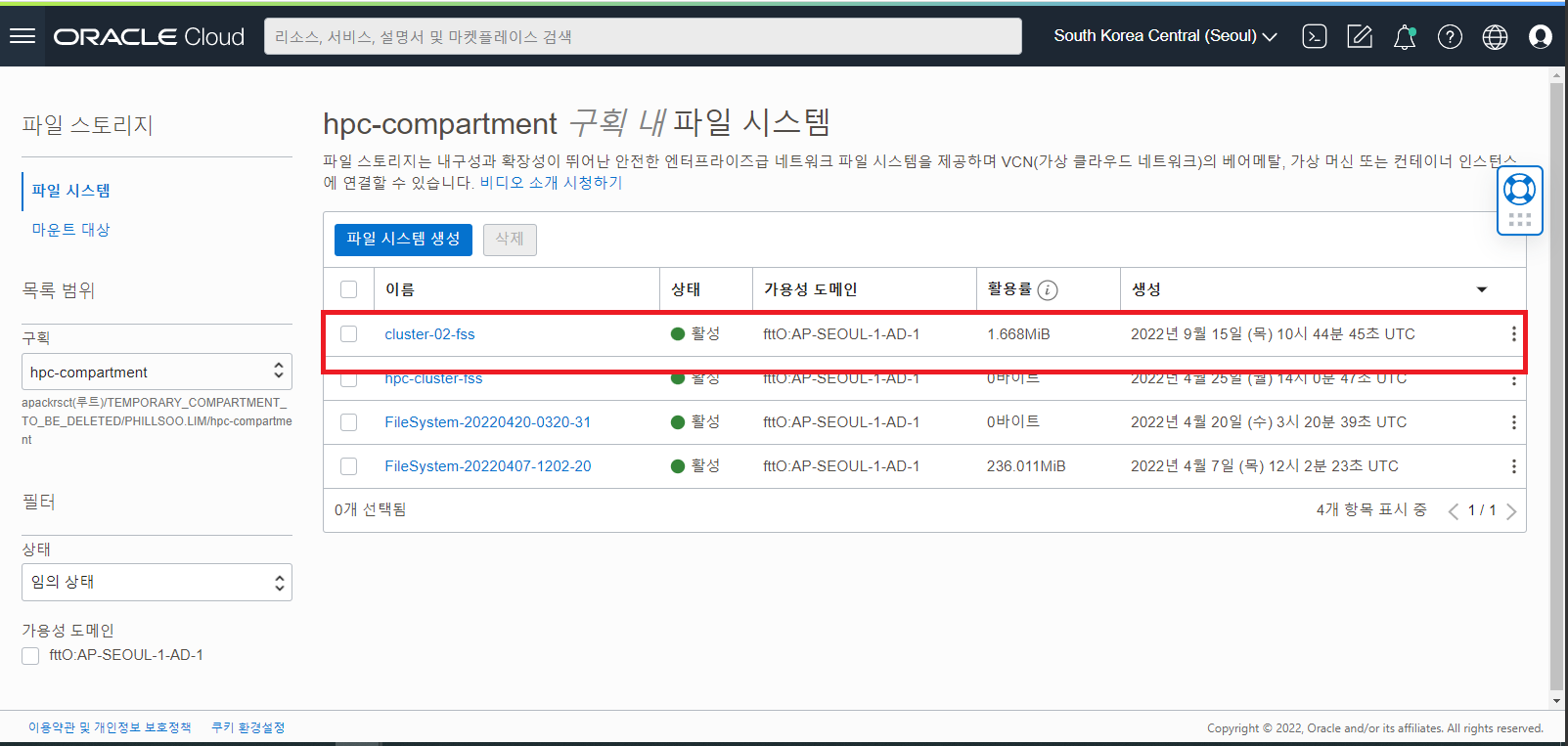
- Create FSS : 추가적으로 공유 스토리지가 필요하다면 이 옵션을 선택해서 OCI 의 File Storage Service 에 Mount Target 및 File System 을 생성하여 NFS Filesystem 을 추가 구성합니다. (Defualt UNCHECK)
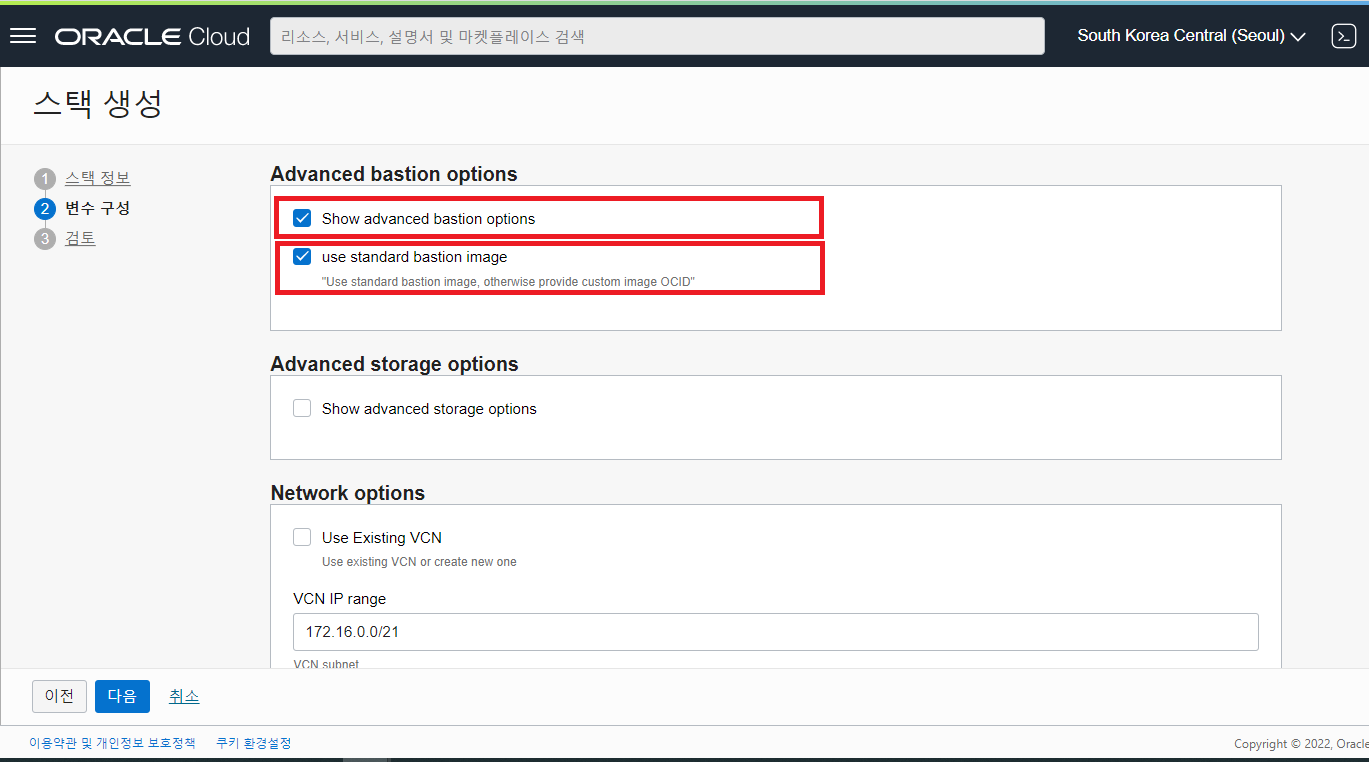
- Advanced bastion options : Bastion Node 의 이미지 구성을 위한 옵션을 체크합니다.
- Show advanced bastion options : 체크 시 바로 아래에 standard 이미지를 사용할 것인지 체크하는 항목이 나타납니다. (Default UNCHECK)
- use standard bastion image : 체크 시 마켓플레이스에서 제공되는 standard 이미지를 사용하게 되며, UNCHECK 시 커스텀 이미지를 지정할 수 있는 메뉴들이 나타납니다. 각종 S/W 를 설치한 커스텀 이미지를 사용하시려면 체크박스를 UNCHECK 후 커스텀 이미지를 지정해 줍니다.
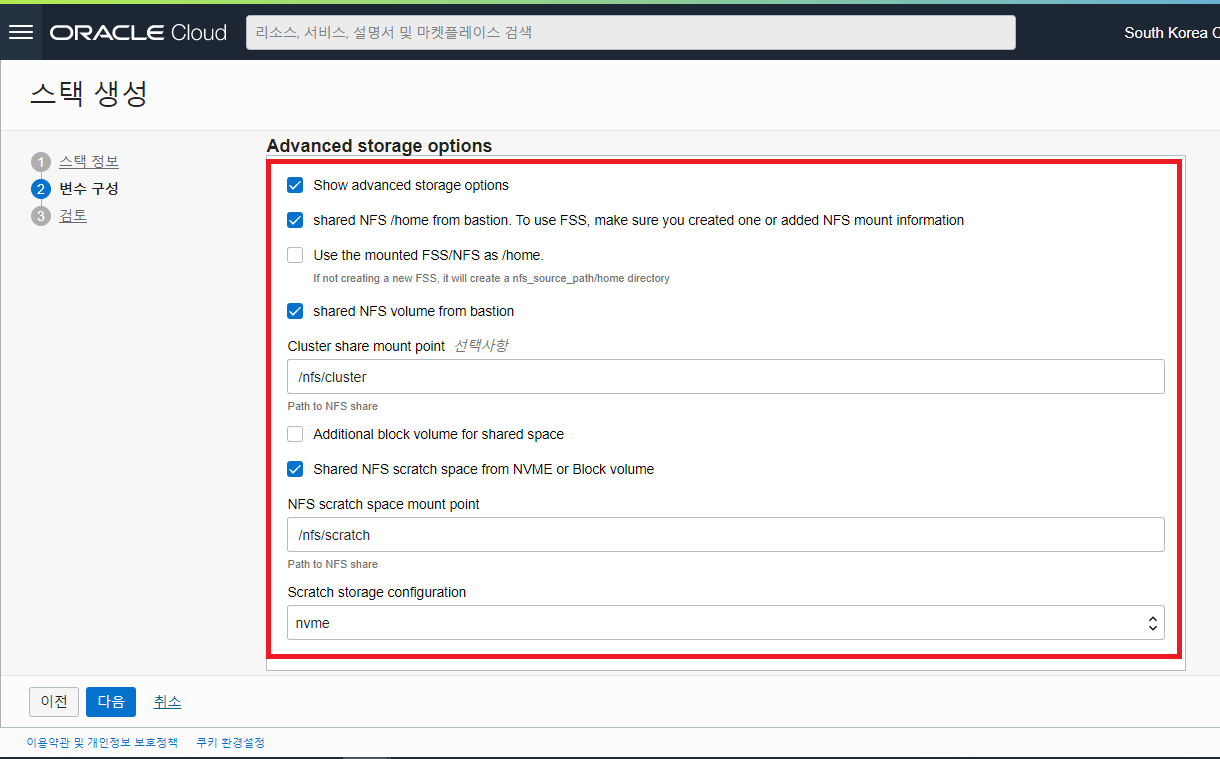
- Advanced storage options : 추가적인 스토리지 구성이 필요할 경우에만 체크합니다.
- Show advanced storage options : 체크 시 바로 아래에 스토리지 추가 구성과 관련된 입력 필요 항목 및 체크 박스들이 나타납니다. (Default UNCHECK)
- shared NFS /home from bastion. To use FSS, make sure you created on or added NFS mount information : 체크 시 /home 디렉토리가 NFS 로 공유됨 (Default 로 공유됨)
- Use the mounted FSS/NFS as /home : UNCHECK (기본적으로 /home 이 NFS 로 공유되는 곳을 새로이 생성할 OCI 의 FSS로 사용할지를 묻는 것으로 /home 디렉토리 공유는 자체 NFS Share 를 사용하도록 함)
- shared NFS volume from bastion : Check
- Cluster share mount point : /nfs/cluster (Default)
- Additional block volume for shared space : UNCHECK (Default) - 추가적으로 Block Voume 스토리지를 구성하여 Compute Node 에서 사용하고자 할 경우, 체크하는 옵션
- Shared NFS scratch space from NVME or Block volume : Check (Default)
- NFS scratch space mount point : /nfs/scratch (Default)
- Scratch storage configuration : nvme (Default)
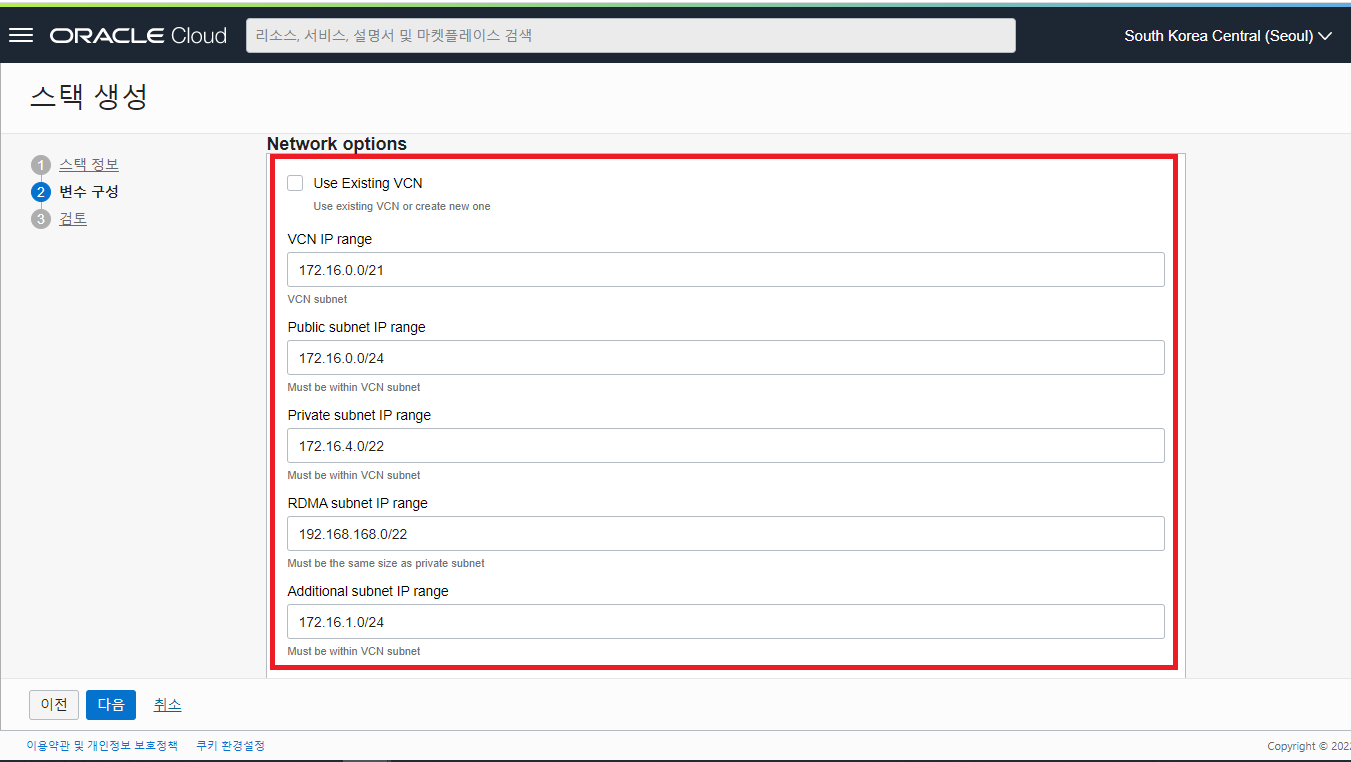
- Network options : HPC Cluster 가 사용할 네트워크와 관련된 입력 사항들을 입력 후 스크롤 다운합니다.
- Use Existing VCM : 기본적으로는 새로운 VCN 을 생성하여 구성되도록 되어 있으나 기존에 만들어 놓은 VCN 에 생성을 원할 경우 체크 박스를 Check 해 줍니다. (Default UNCHECK)
- VCN IP range : 172.16.0.0/21 (Default 로 지정됨)
- Public subnet IP range : 172.16.0.0/24 (Default 로 지정됨)
- Private subnet IP range : 172.16.4.0/24 (Default 로 지정됨)
- RDMA subnet IP range : 192.168.168.0/22 (Default 로 지정됨) - RDMA Cluster network 이 사용할 IP 대역
- Additional subnet IP range : 172.16.1.0/24 (Default 로 지정됨)
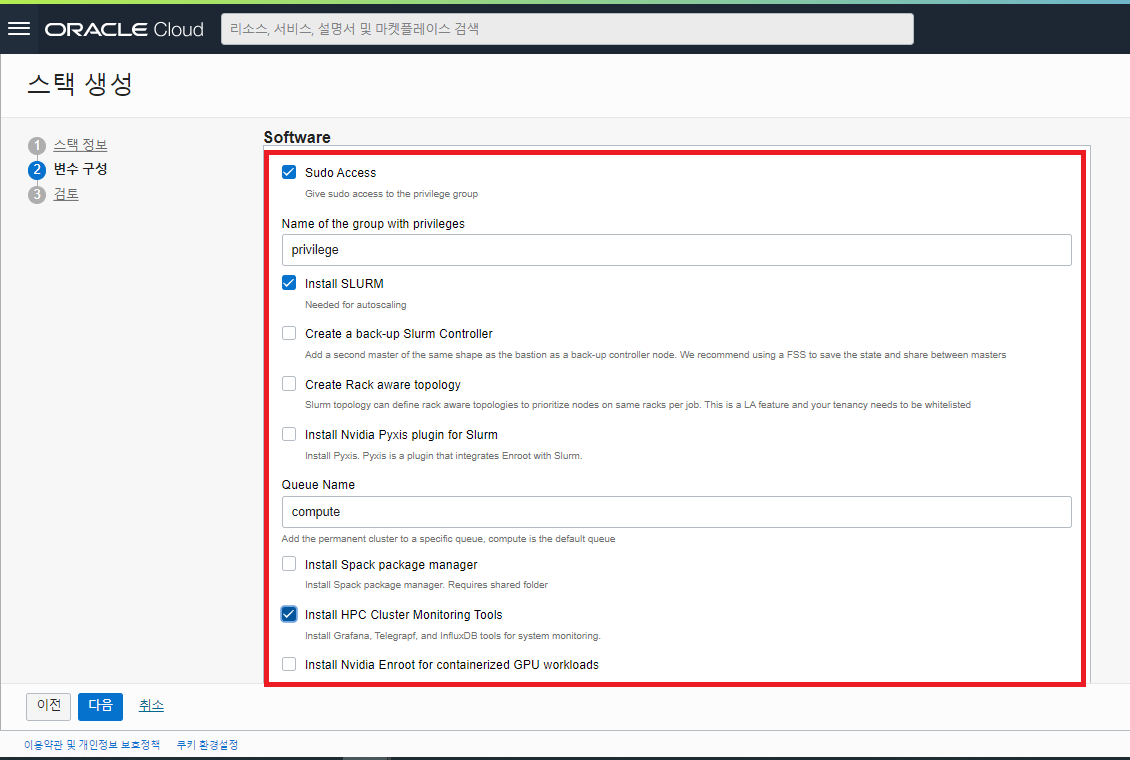
- Software : HPC Cluster 에 설치할 Software 들을 선택할 수 있습니다. HPC 업무에 필요서 선택적으로 설치해 줍니다.
- Sudo Access : Check (Default)
- Name of the group with privileges : privilege (Default)
- Install SLURM : Check (Default) - (※ HPC Job 을 Control 하는 Open Source 로 HPC 업무에서 범용적으로 사용하는 Software 임)
- Create a back-up Slurm Controller : UNCHECK (Default) - Backup Slurm 을 구성하는 옵션임
- Create Rack aware topology : UNCHECK (Default)
- Install Nvidia Pyxis plugin for Slurm : UNCHECK (Default) - Slurm Workload Manager 를 위한 SPANK plugin
- Queue Name : compute (Default) - 변경 입력 가능
- Install Spack package manager : UNCHECK (Default)
- Install HPC Cluster Monitoring Tools : Check - HPC Node 들에 대한 모니터링을 위한 Grafana, Telegrapf, InfluxDB 등을 설치
- Install Nvidia Enroot for containerized GPU workloads : UNCHECK (Default)
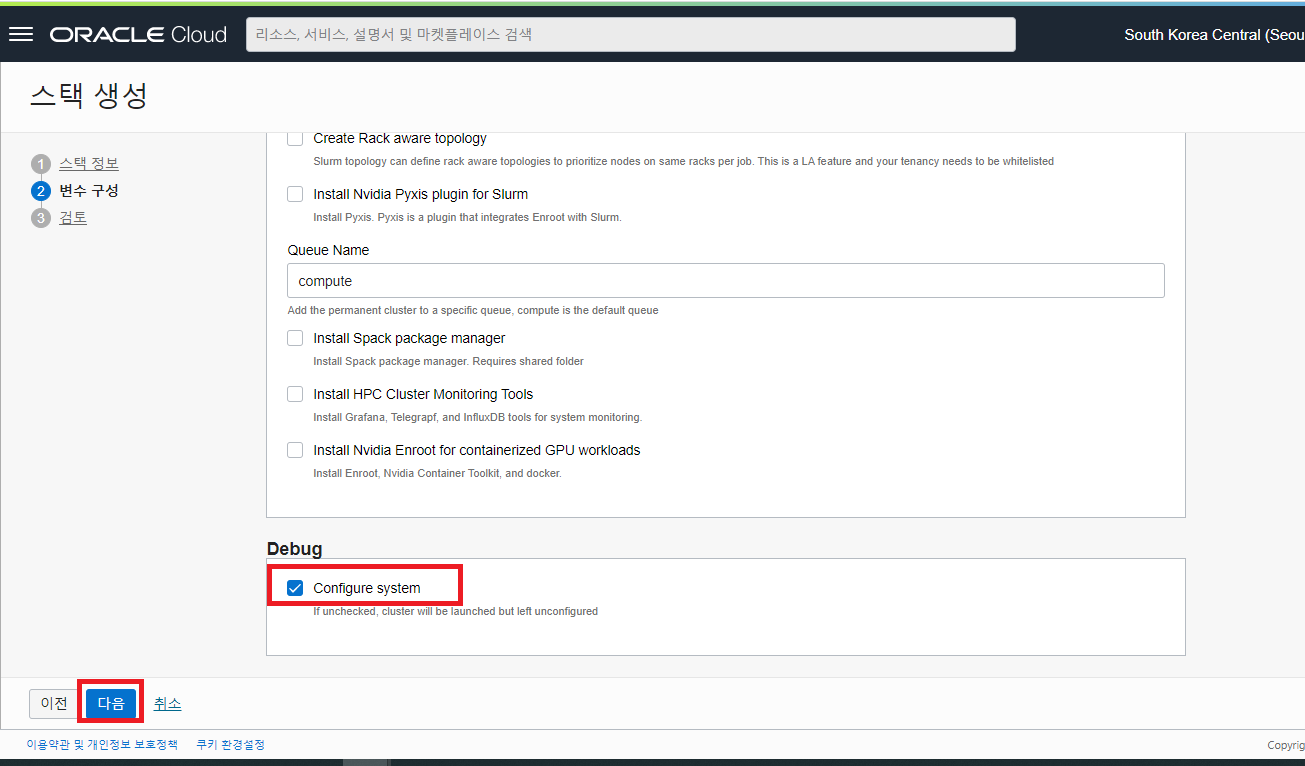
Debug : Configure System 항목을 체크 후 “다음” 버튼을 클릭하여 다음 단계로 진행합니다.
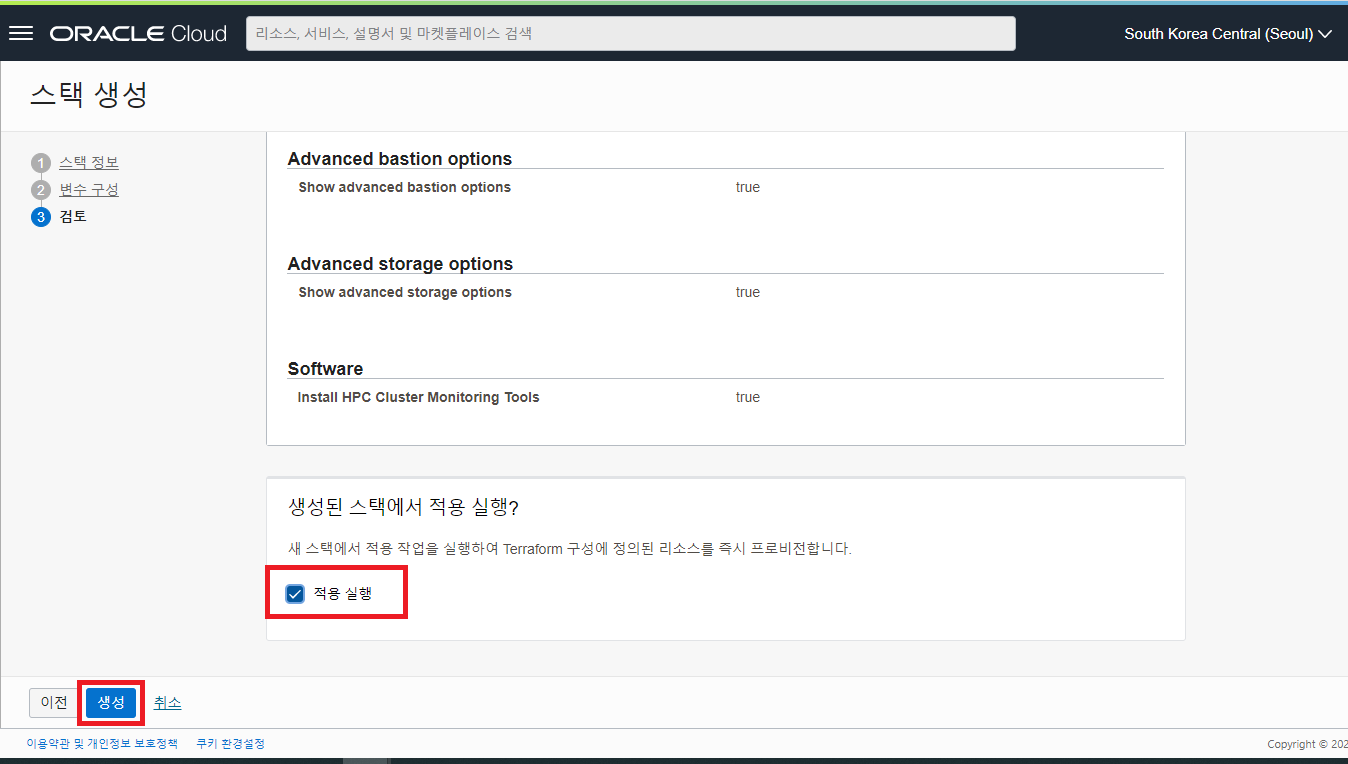
스택 생성 시 선택한 옵션 및 변수 구성을 점검하고 생성하는 Stack 을 곧바로 실행할 것인지 선택하는 옵션이 나옵니다. 적용 실행 옵션을 Check 하고 “생성” 버튼을 클릭하여 Job 을 실행 시킵니다.
OCI HPC Cluster Stack 실행 Job
이 단계에서는 앞서 생성한 Stack 을 수행하는 단계입니다. 이미 “적용 실행” 옵션을 체크 후 생성을 하게 되면 자동으로 실행 Job 이 동작하게 됩니다.
아래는 시작한 Stack 의 실행 Job 화면입니다.
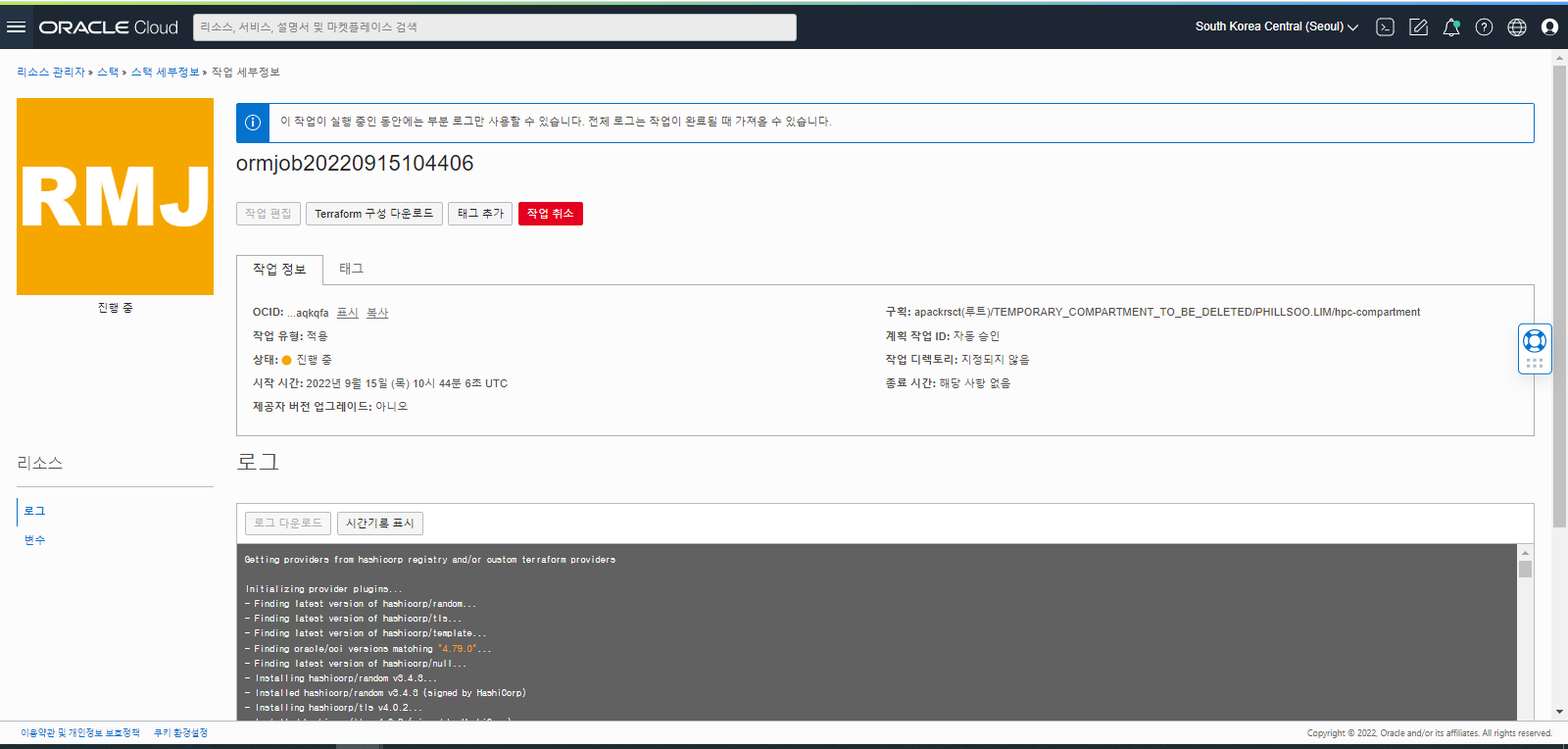
Stack 이 동작하면서 HPC Cluster 를 생성하는 과정을 Job 실행화면의 아래쪽 로그를 확인하면 확인이 가능합니다.
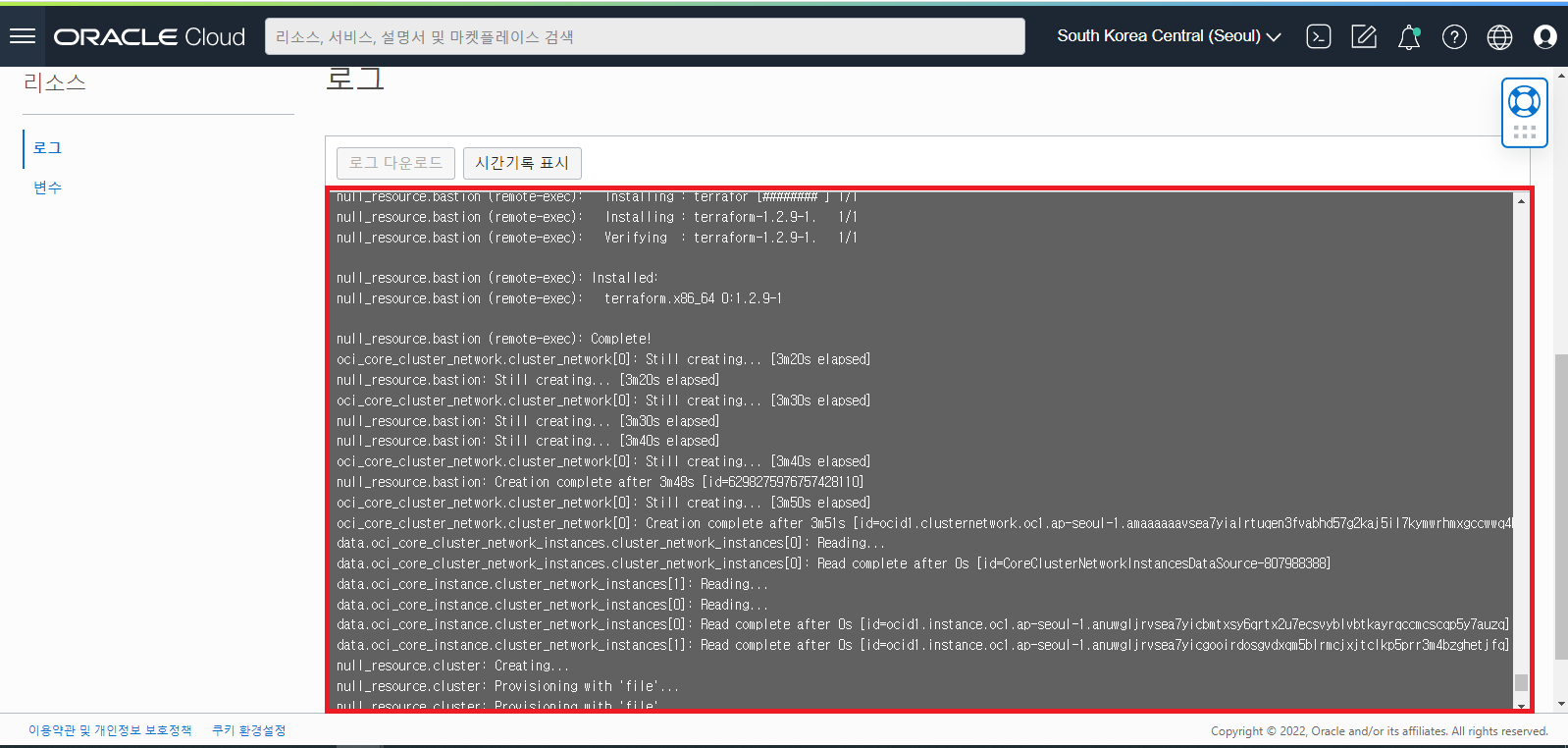
Stack 실행 Job 이 완료되고 성공적으로 HPC Cluster 구성이 완료되면 아래와 같이 Stack 의 상태 화면이 Green 상태로 나타나고 아래 로그창에 실행한 로그들을 확인하실 수 있습니다.
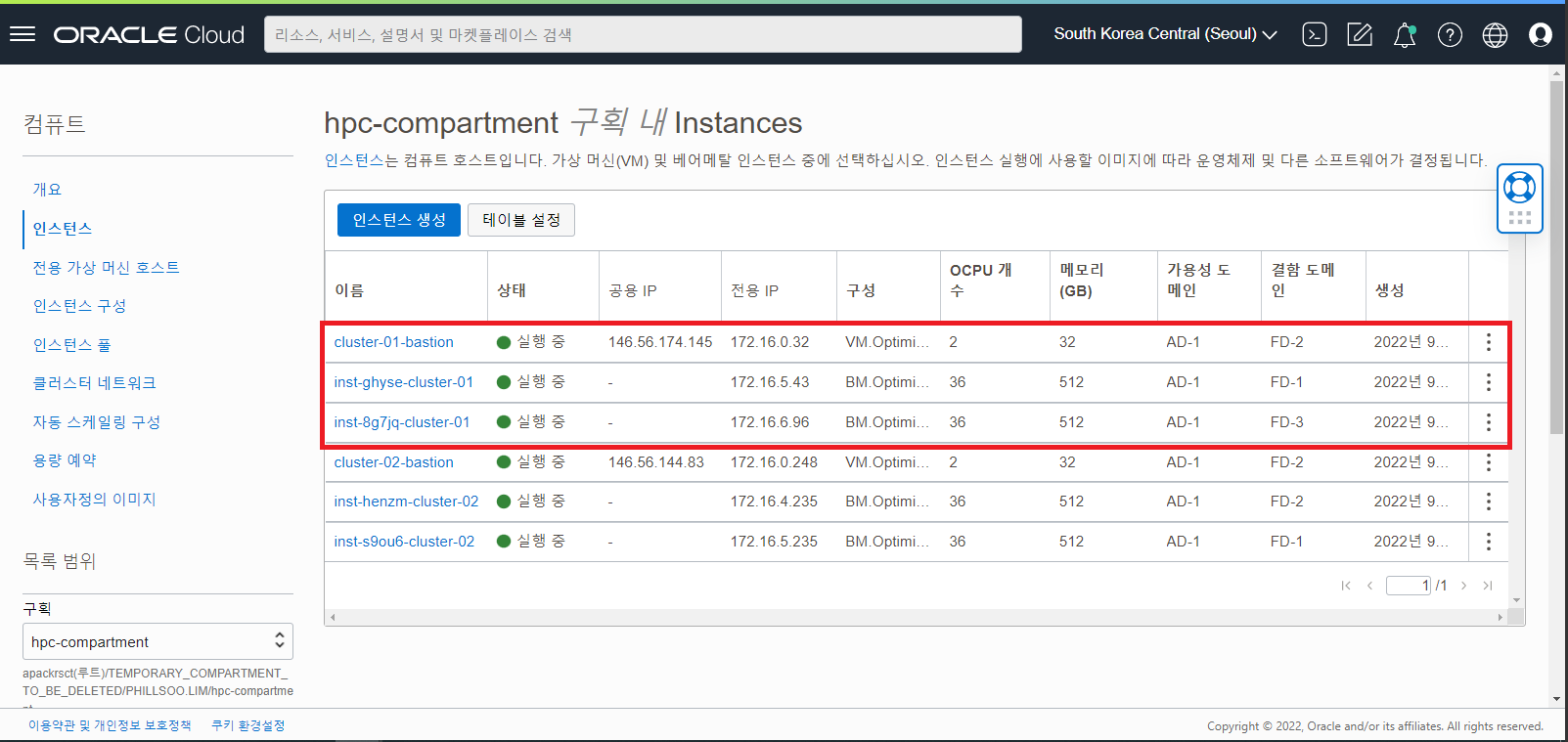
OCI HPC Cluster 생성 결과 확인
HPC Stack 실행을 통해 생성된 컴퓨트 인스턴스, 네트워크 등의 자원을 확인합니다.
컴퓨트 인스턴스
VCN 네트워크
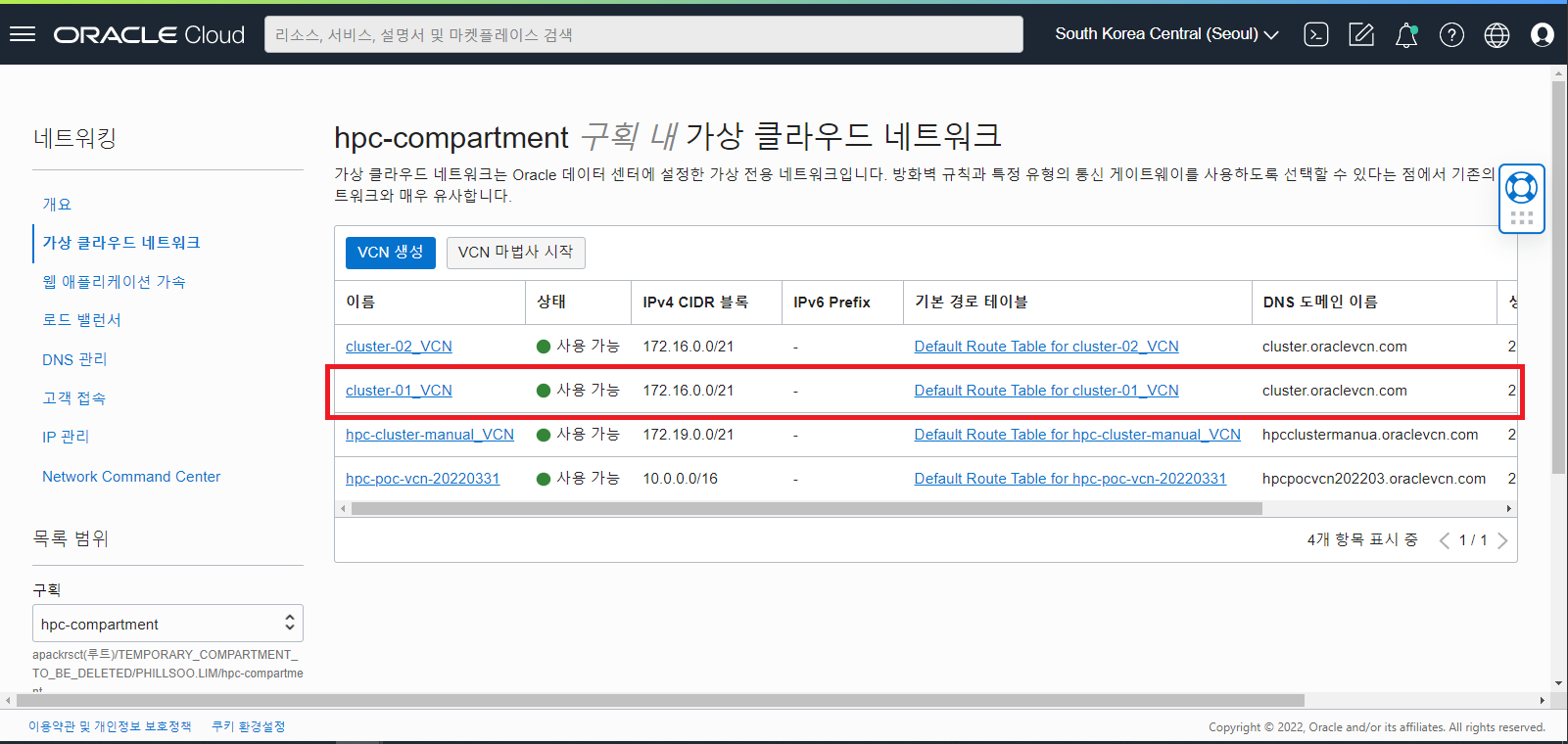
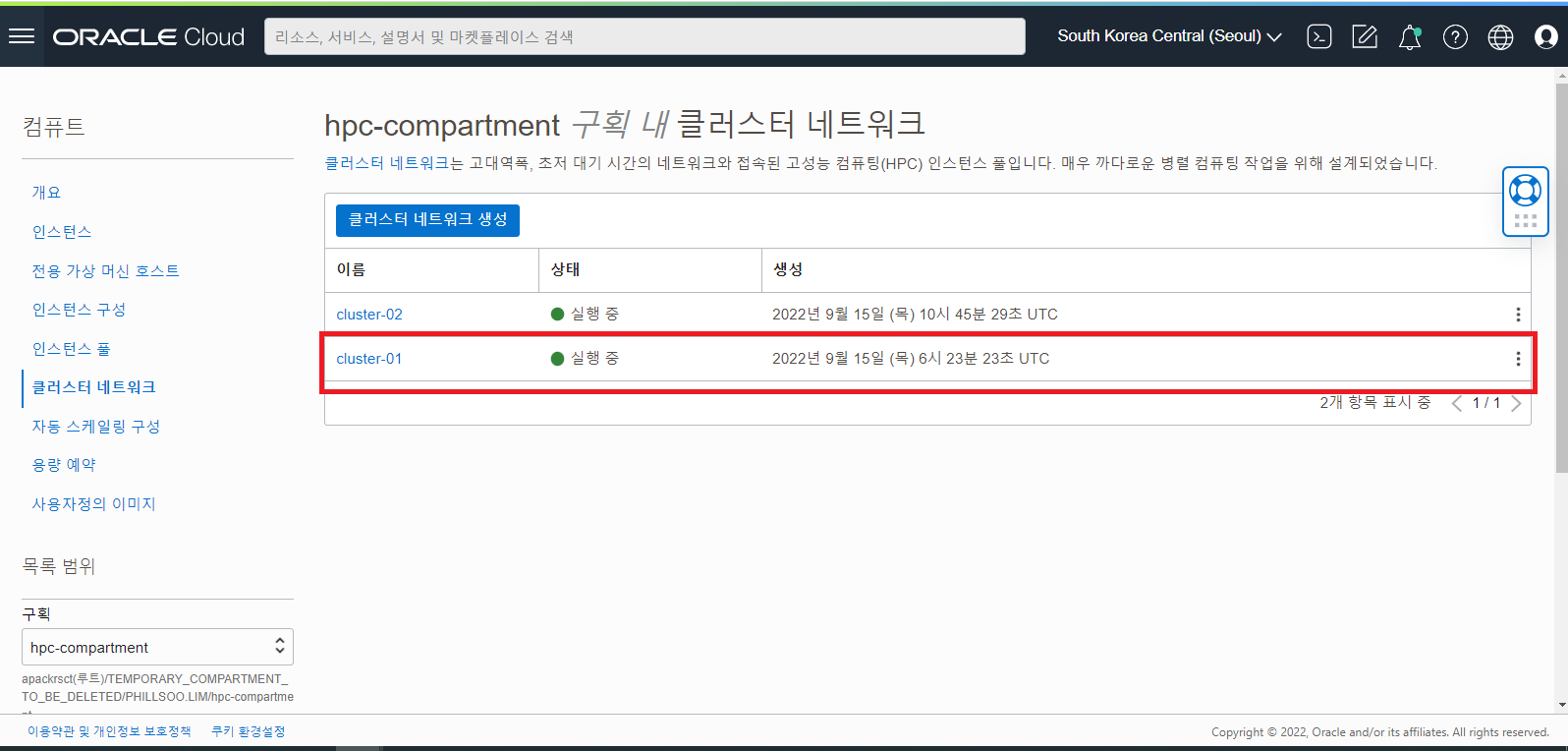
Cluster 네트워크 (RDMA)
File Storage Service 추가 확인
OCI HPC Cluster 접속 및 Grafana 설치 확인
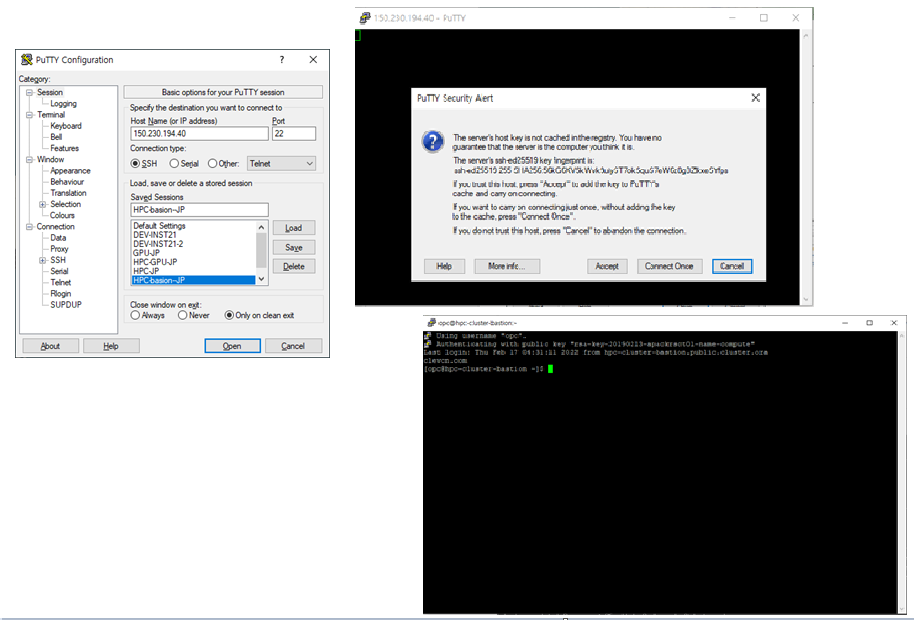
생성된 HPC Cluster 는 Bation 서버 역할을 하는 Headnode 를 통해 접속할 수 있습니다. Bastion 서버에 부여된 Public IP 를 PUTTY 같은 터미널에 연결 설정하여 접속을 하고 Bastion 서버를 통해 Compute Node 들에게 HPC Workload Job 을 Control 하게 됩니다.
Headnode 에 대해 아래와 같이 Putty 터미널을 통해 로그인합니다.
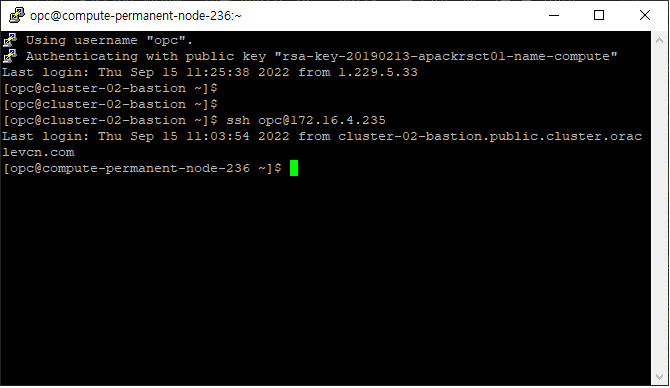
Compute Node 로 접속할 경우, ssh 명령을 통해 직접 접속이 됩니다.
ssh opc@computenode-ip
SSH 를 통한 BM Compute Node 접속 화면
접속한 Compute Node 인 BM 장비에 CPU 가 제대로 탑재되어 있는지 확인하기 위해 다음의 명령을 통해 확인합니다.
/opt/intel/oneapi/mpi/latest/bin/cpuinfo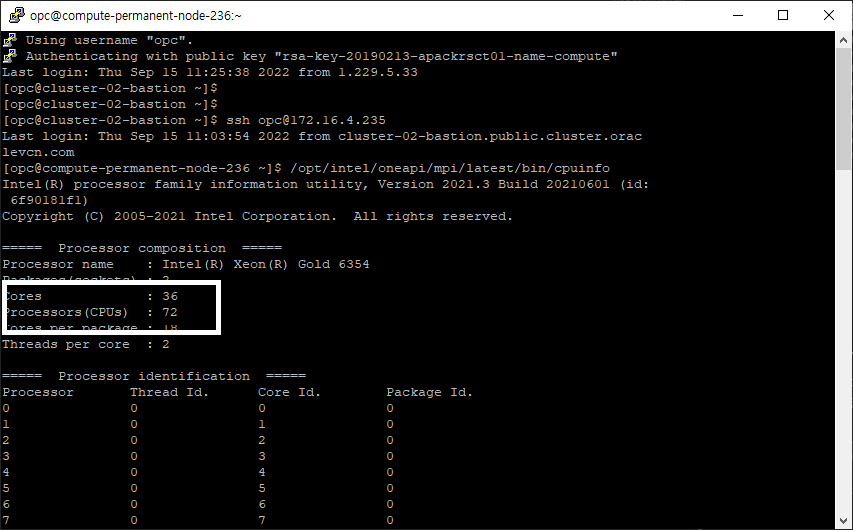
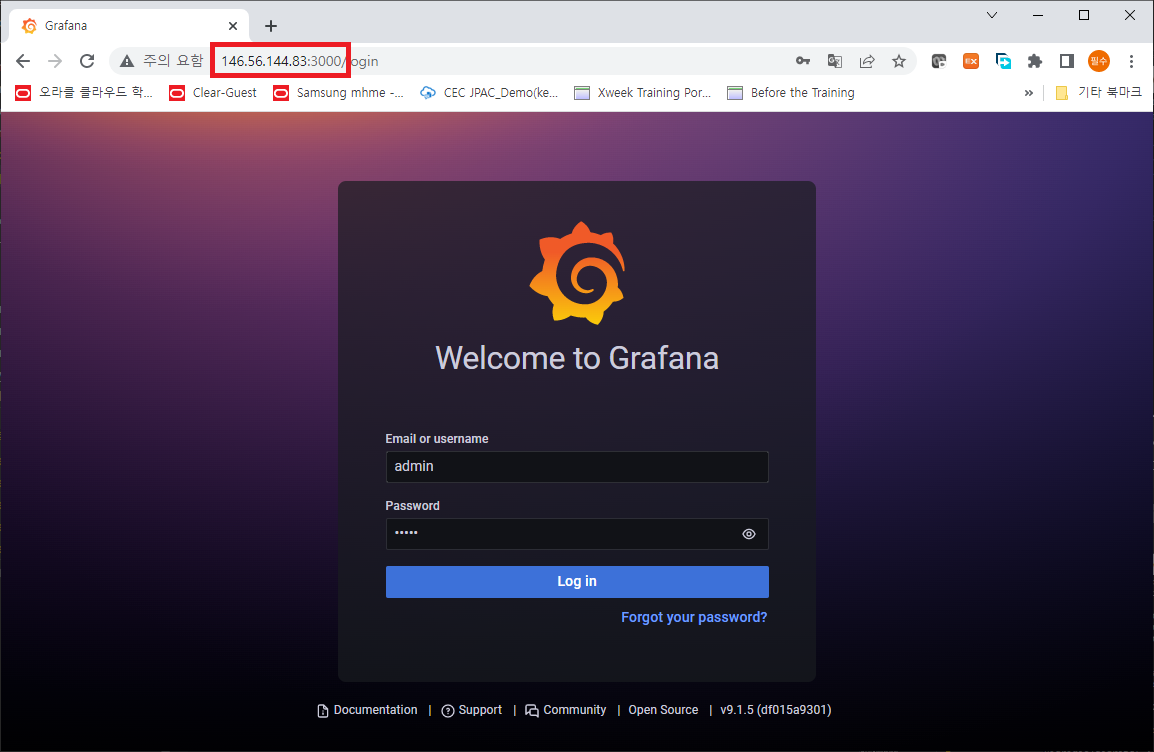
선택 사항인 HPC Cluster 에 대한 모니터링 툴이 제대로 설치되어 있는지 확인하기 위해 웹브라우져의 주소창에 “Headnode-public-ip:3000” 을 입력합니다. 최초 로그인시 admin/패스워드 로그인 버튼 클릭 시 신규 password 를 세팅하게 됩니다.
Grafana 로그인 화면
Grafana 메인
Grafana 대시보드로 미리 구성되어 있는 Cluster Dashboard 를 선택합니다.
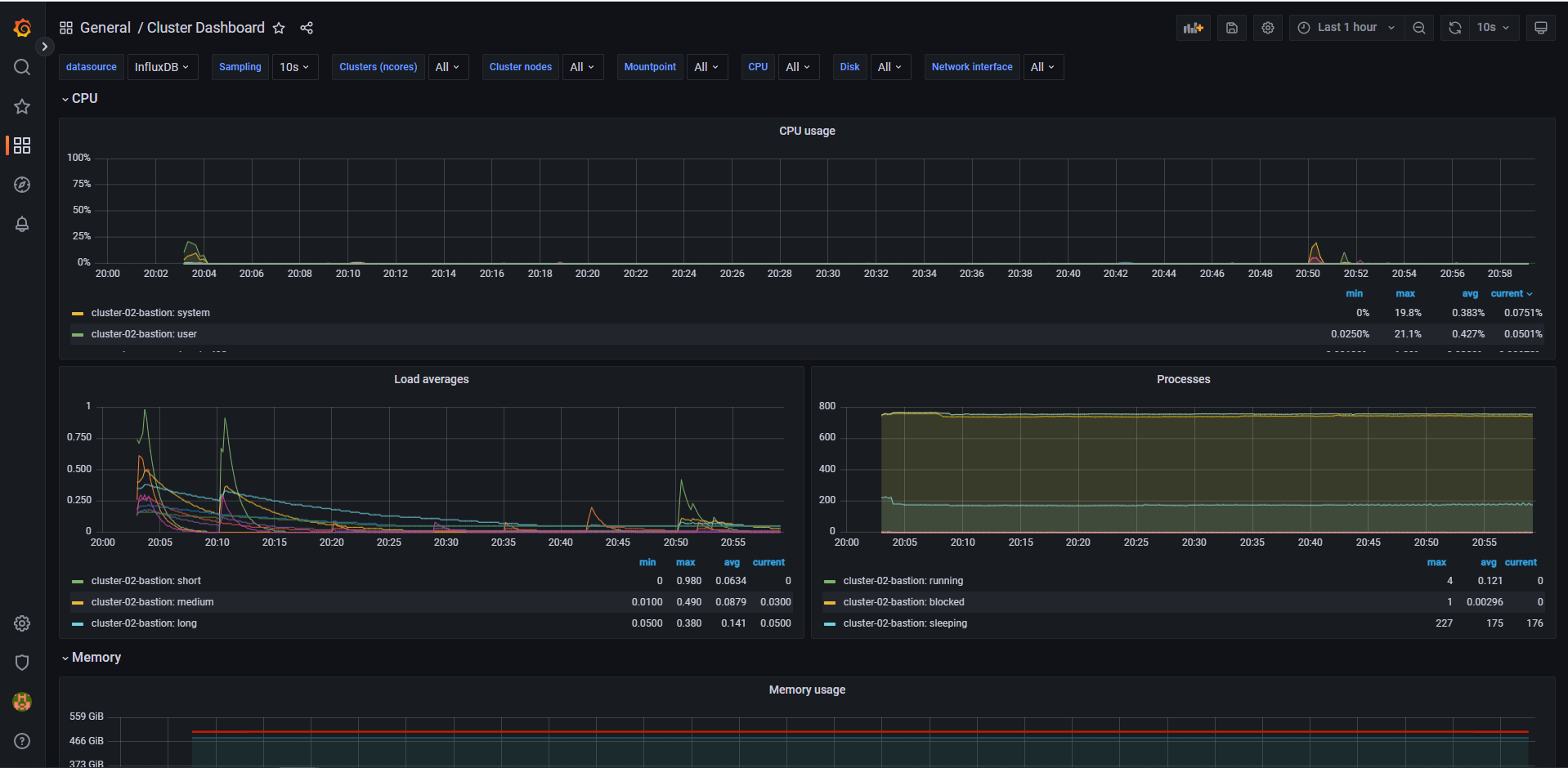
Cluster Dashboard 를 이용하여 HPC Workload 구동 시 CPU 및 메모리, 네트워크 사용 현황을 모니터링 하게 됩니다.
확인이 완료되었으면, 이제 Headnode 에 설치되어 있는 Slurm Job 을 이용해 Workload 를 동작시키거나, HPC 관련 S/W 를 직접 설치하여 HPC Workload 를 동작시키실 수 있습니다.
OCI HPC Cluster 삭제 (Destory by Stack)
HPC Cluster Stack 에 의해 생성된 Cluster 는 반드시 Stack 에 의해 생성했던 Resource 들을 정리해야 합니다. 앞서 Stack 을 통해 HPC Cluster 에 생성했던 자원들은 매우 다양하게 30 여개의 자원들이 생성됩니다. 모두 일일이 수작업으로 찾아서 삭제, 정리하는 번거로운 과정을 거치지 않도록 반드시 Stack 에서 일괄 정리하게 됩니다.
- OCI 콘솔에서 개발자 서비스 -> 리소스 관리자 -> 스택 메뉴를 실행합니다.
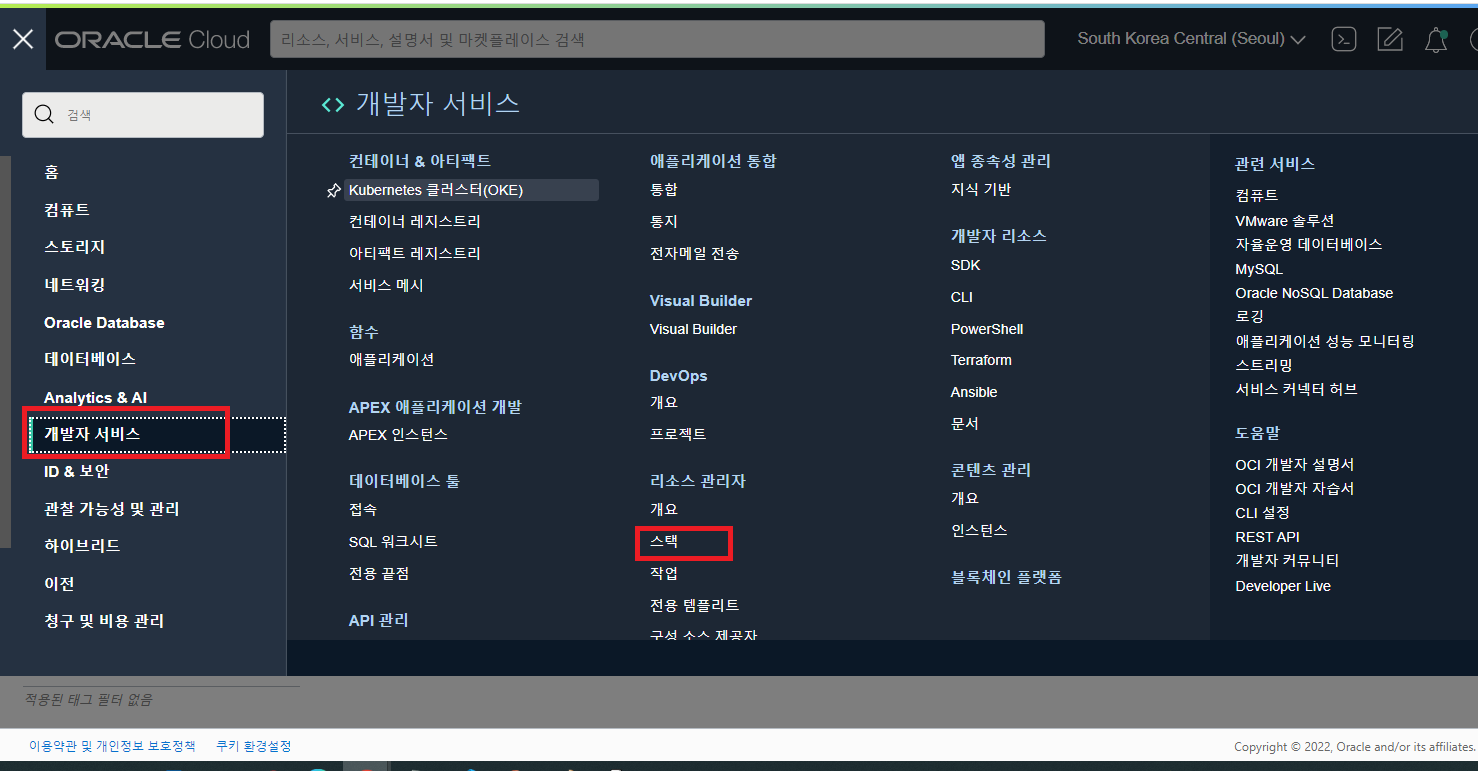
- 스택 목록에서 HPC Cluster 를 생성했을때 사용한 HPC Stack 을 선택합니다.
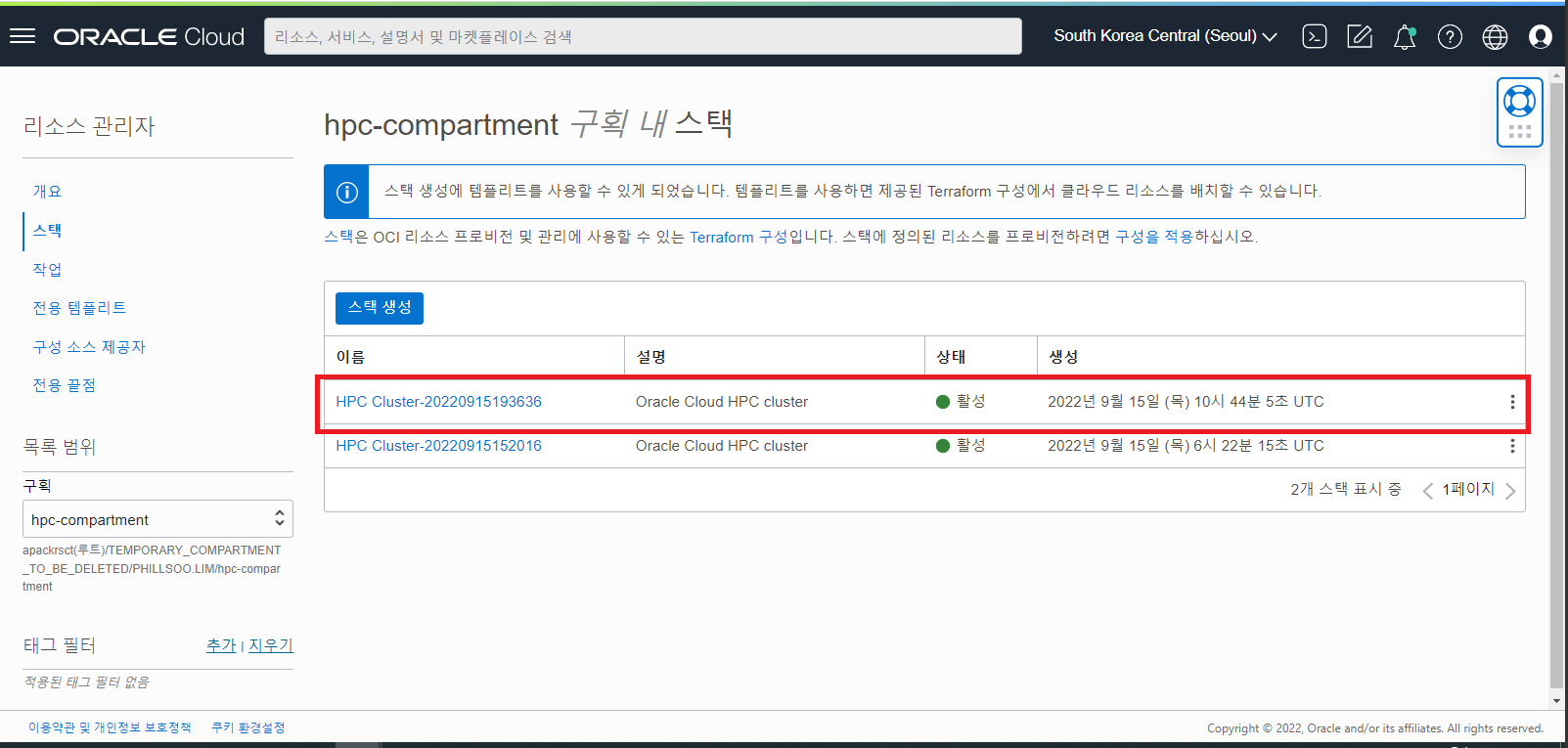
- Stack 상단의 “삭제 (Destroy)” 버튼을 클릭하여 HPC Cluster 자원들을 정리합니다.
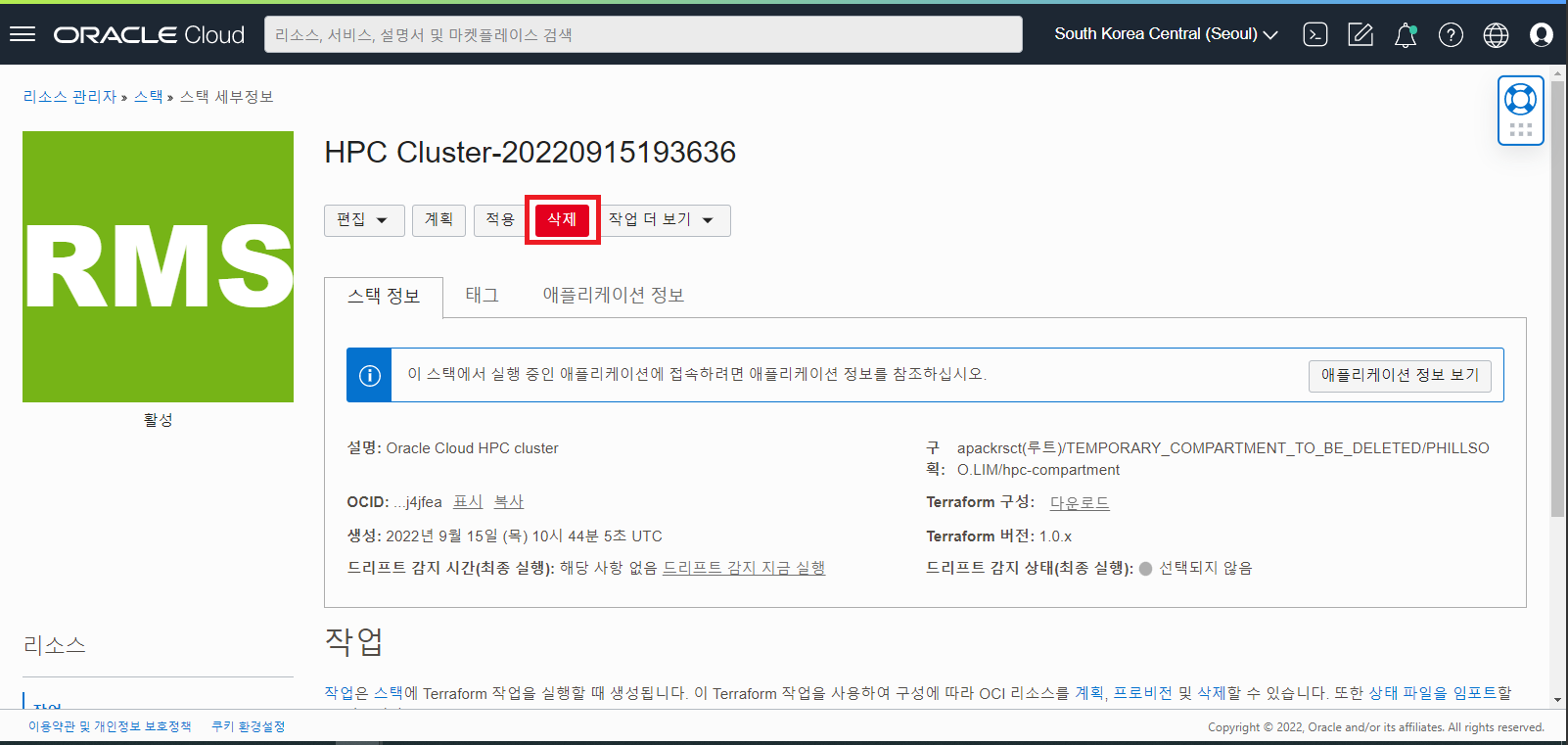
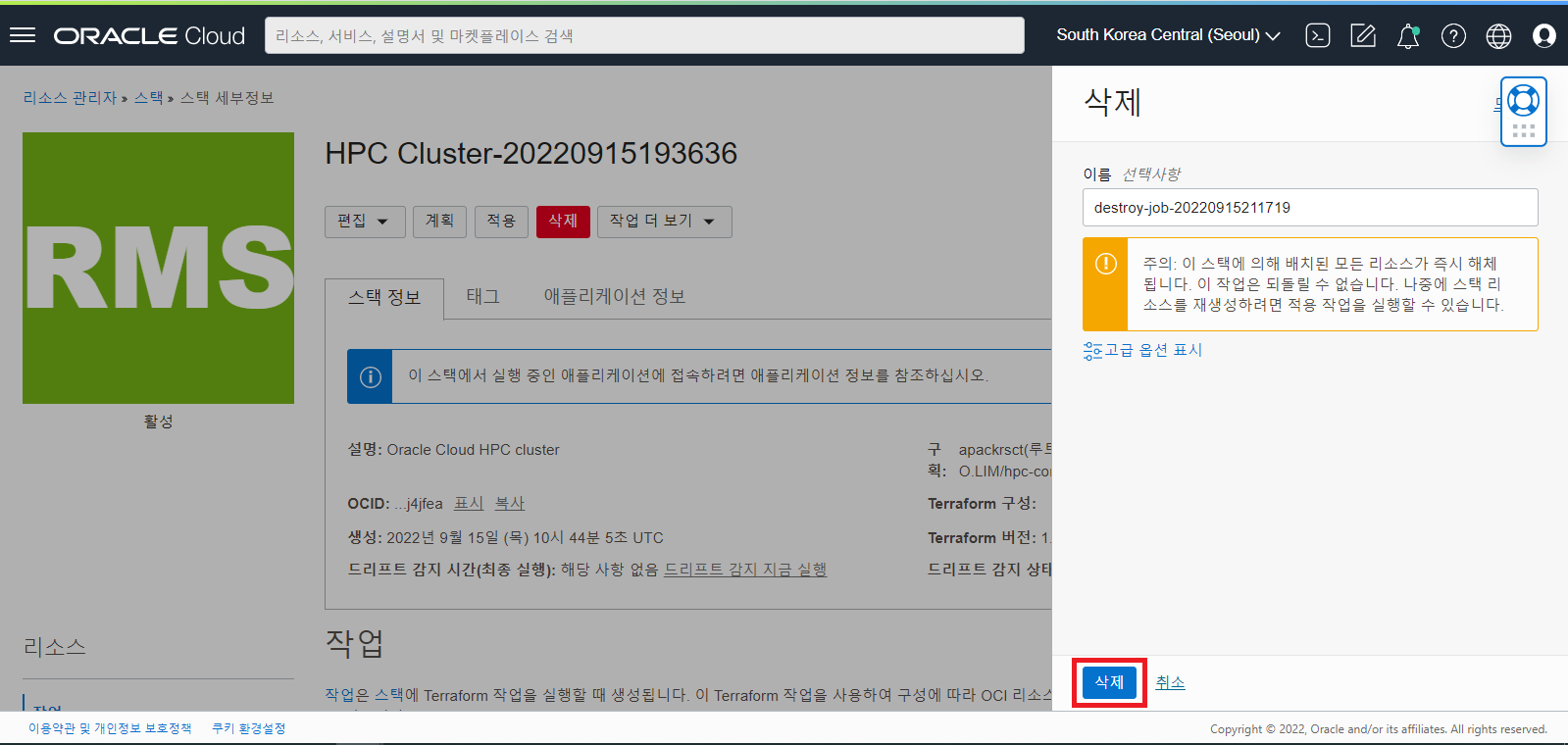
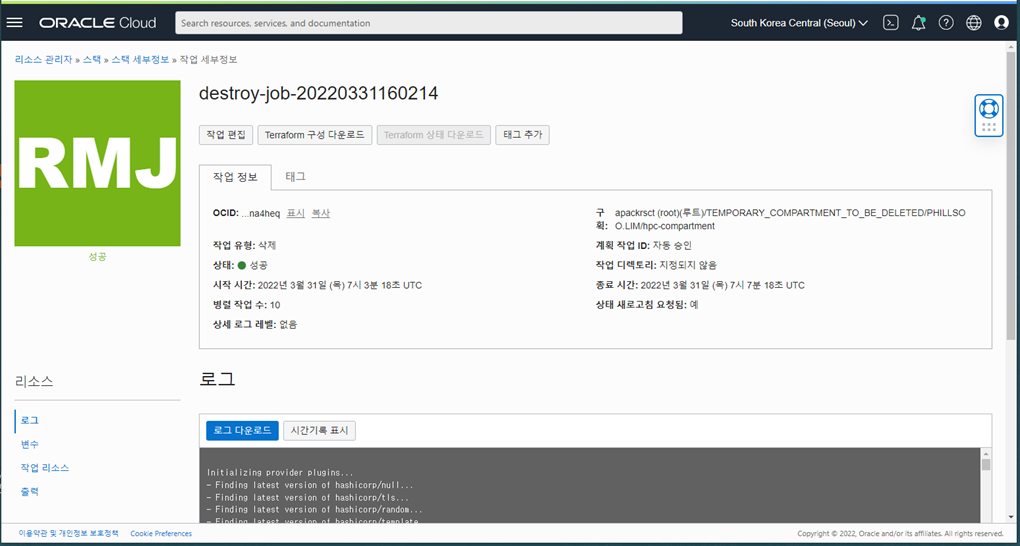
- Stack 의 삭제 Job 이 구동하면서 HPC Cluster 의 모든 자원들의 정리를 시작합니다.
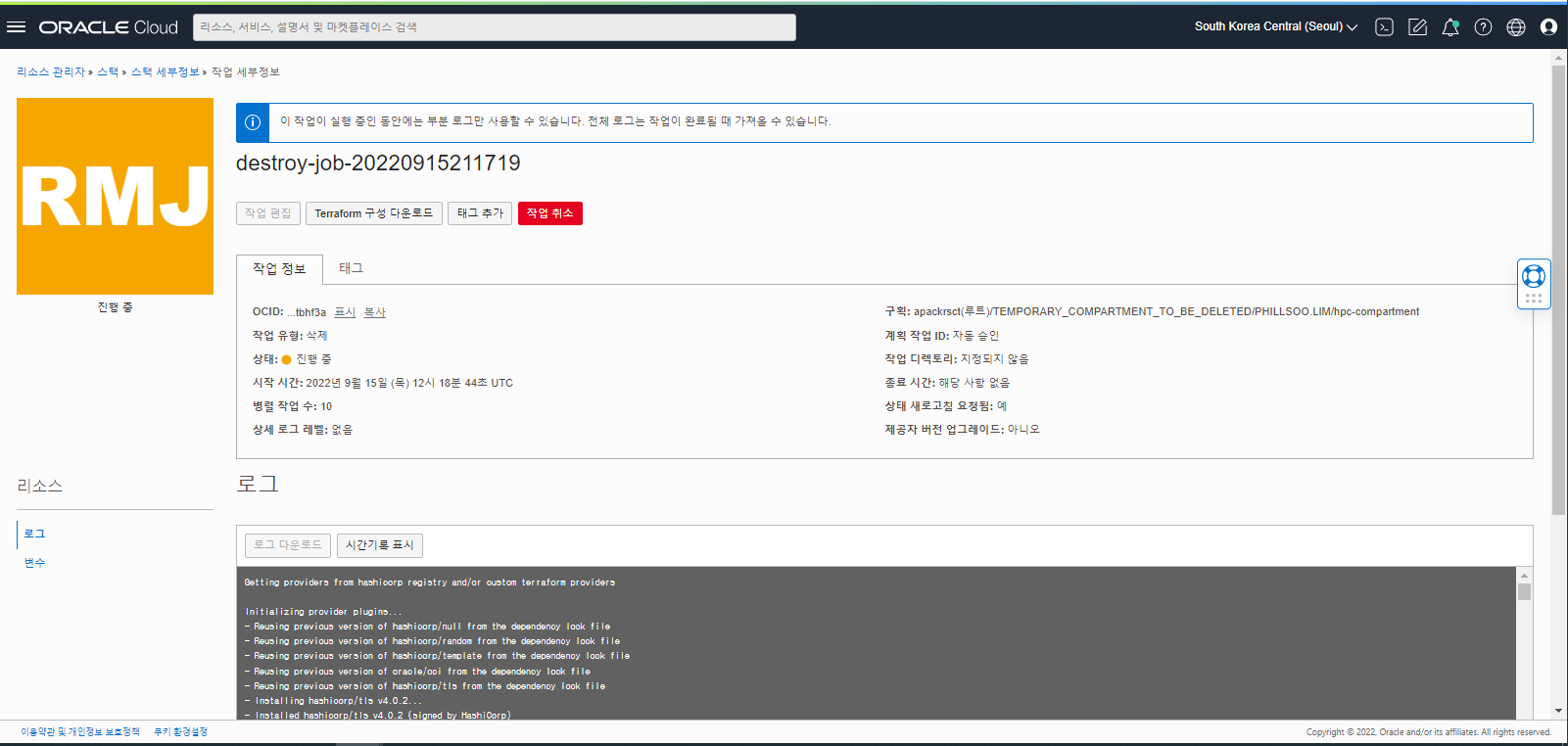
- 삭제 Job 이 완료되면 Job 의 상태 그림이 Green 으로 바뀌며 정리한 자원들의 목록을 로그에서 확인할 수 있습니다.
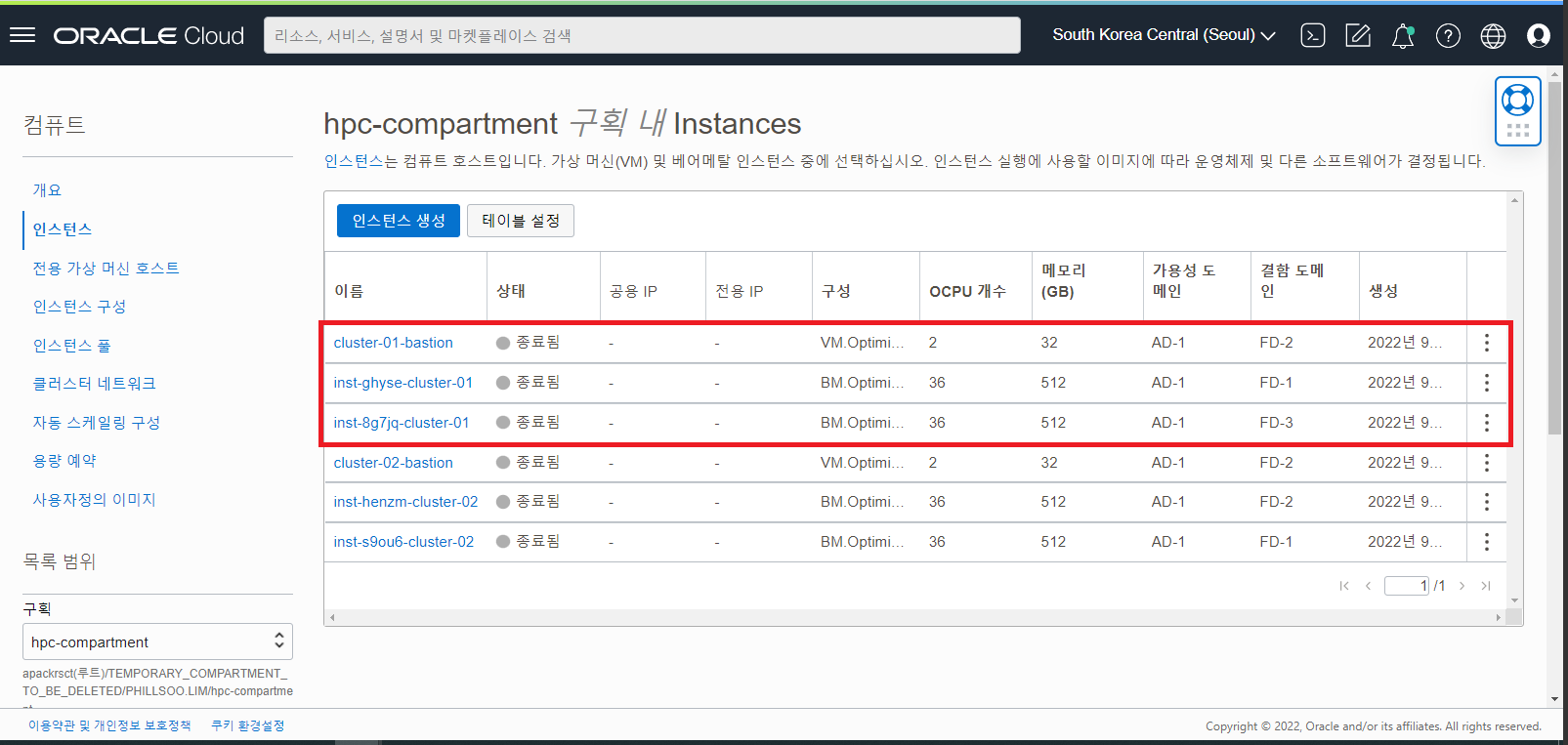
- 컴퓨트 인스턴스 목록 화면에서 HPC Cluster 로 생성했던 Headnode 와 BM Compute Node 들이 잘 삭제되었는지 확인합니다.
이제 모든 HPC Cluster 의 자원들이 정리되었습니다. 수고하셨습니다. 그외 HPC Cluster 사용과 관련된 부가적인 정보들은 Marketplace HPC Cluster Stack 사용 지침 을 참고바랍니다.
이 글은 개인적으로 얻은 지식과 경험을 작성한 글로 내용에 오류가 있을 수 있습니다. 또한 글 속의 의견은 개인적인 의견으로 특정 회사를 대변하지 않습니다.
Phillsoo Lim INFRASTRUCTURE
oci hpc cluster rdma cfd healthcare research