DataPlatform
Autonomous Database Cloud Service Hands-On - Provisioning, Object Storage Parquet Data Load 하기
Table of Contents
Hands-On 소개
OCI Autonomous Database는 클라우드 기반 자율 데이터 관리 솔루션으로, 자동 패치 적용, 업그레이드 및 튜닝을 제공합니다. Autonomous Database 클라우드는 자체 관리, 자체 보안 및 자체 복구 기능을 갖추고 있어 수동 데이터베이스 관리 및 인적 오류를 방지하는 데 도움이 됩니다. 이번 Hands-On 블로그에서는 새로운 Autonomous Database 중 Autonomous Data Warehouse 를 프로비저닝하고 Object Storage 에 저장된 Parquet 파일을 Database 에 로드하는 방법과 Local 에 있는 파일 데이터를 로드하는 방법에 대해 실습 상세히 설명합니다.
Hands-On 실습
Autonomous Data Warehouse (ADW) 프로비저닝
간단하게 Database 의 이름과 ADMIN 사용자의 Password 만 입력하여 수분안에 빠르게 데이터베이스가 생성되어 즉시 사용이 가능합니다.
OCI Console 에 로그인하여 아래의 Navigation 메뉴에서 Autonomous Database (자율운영 데이터베이스) 메뉴를 선택합니다.
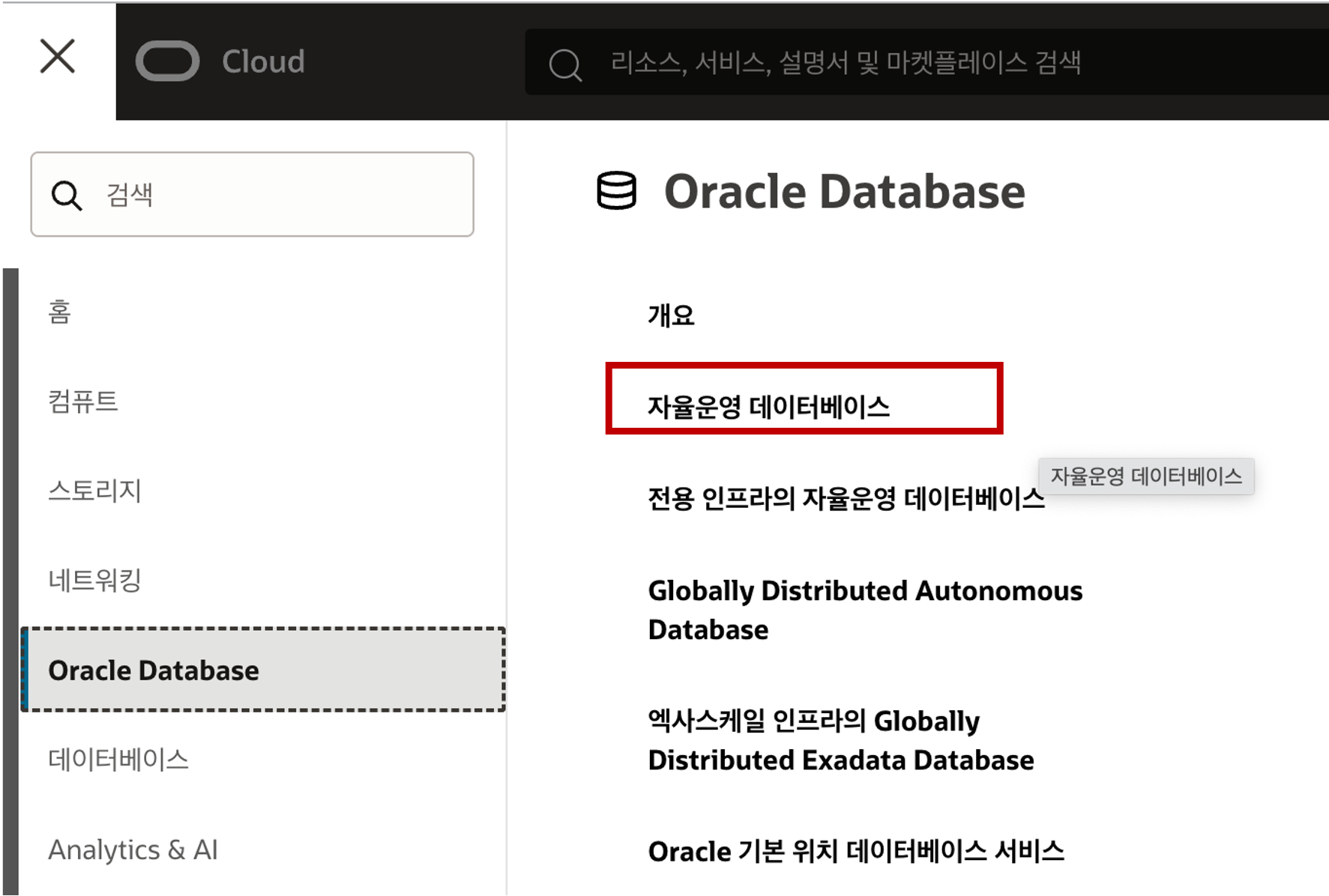
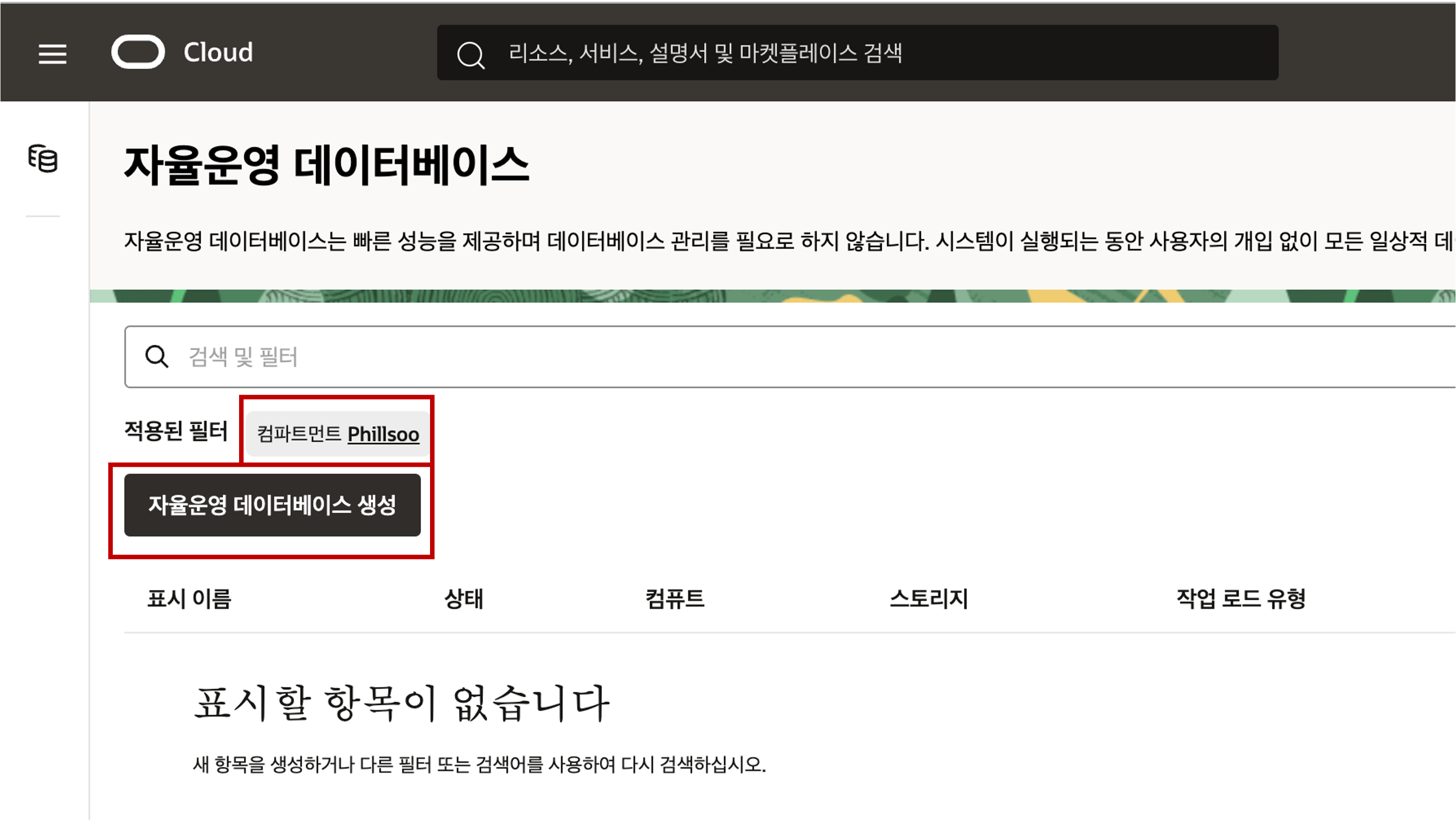
Autonomous Database (자율운영 데이터베이스) 목록 화면에서 선택된 Compartment (컴파트먼트) 를 확인하고 “자율운영 데이터베이스 생성” 버튼을 클릭합니다.
- Autonomous Database (자율운영 데이터베이스) 생성 화면에서 아래 화면과 같이 표시 이름과 DB 이름을 입력하고 워크로드 유형을 선택 후 화면 아래로 스크롤을 합니다.
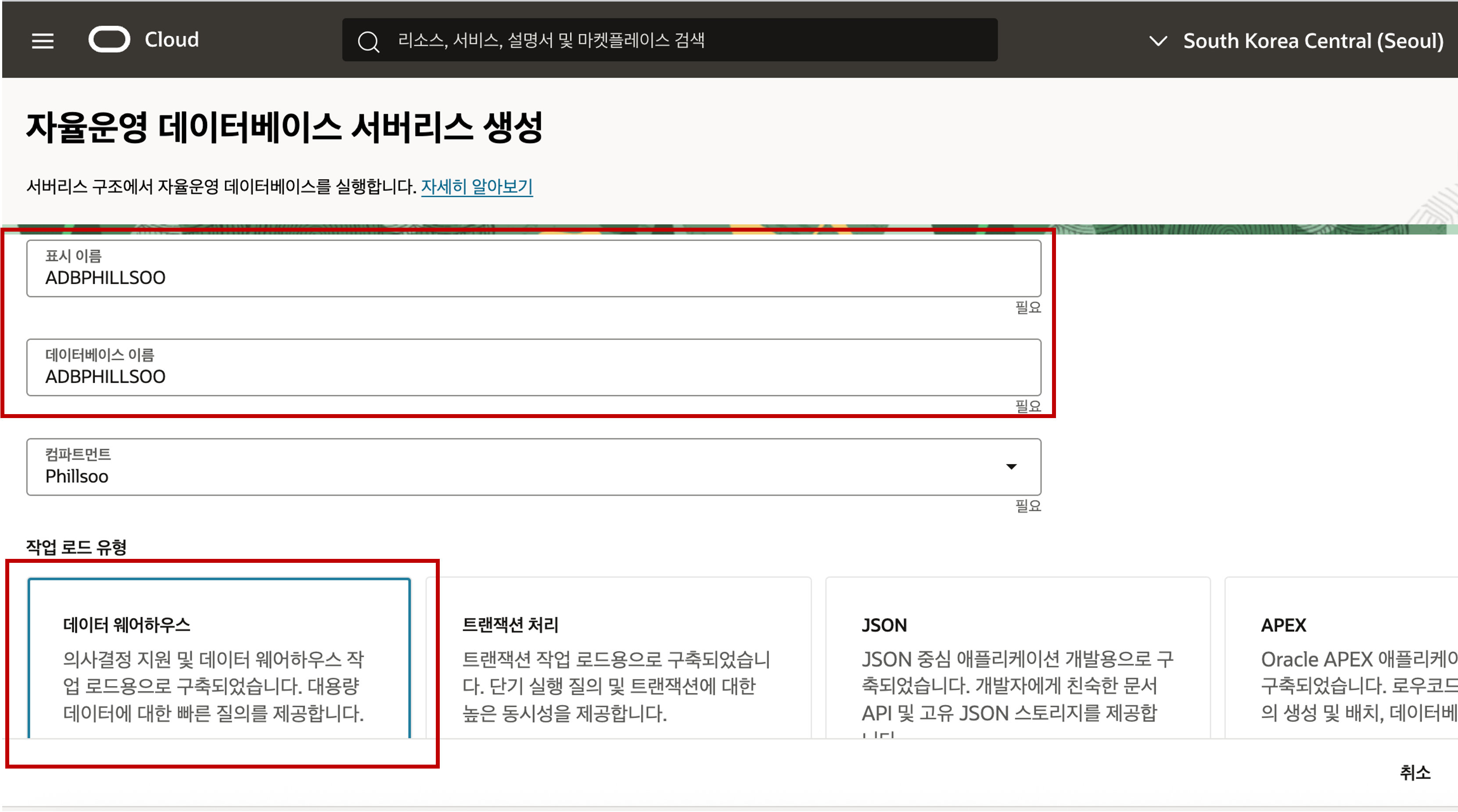
- 표시 이름 : 목록에서 나타낼 이름을 입력합니다.
- 데이터베이스 이름 : 데이터베이스를 인식할 이름으로 영문과 숫자 조합으로 입력합니다.
- 작업 로드 유형 (워크로드 유형) : 데이터베이스가 주로 처리해야할 워크로드 유형에 따라 선택합니다.
- 데이터 웨어하우스 - DW 용도로 데이터를 적재하고 분석하는 용도로 선택해서 사용
- 트랜잭션 처리 - OLTP 워크로드를 주로 처리하는 데이터베이스 용도로 선택해서 사용
- JSON - MongoDB 와 같은 DocumentDB 워크로드를 처리하는 데이터베이스
- 데이터베이스 구성 섹션에서 개발자 모드, 데이터베이스 버전, 초기 세팅할 CPU 갯수, 컴퓨츠 자동 스케일링 여부, 스토리지 용량, 스토리지 자동 스케일링 여부를 선택한 후 아래로 스크롤을 합니다.
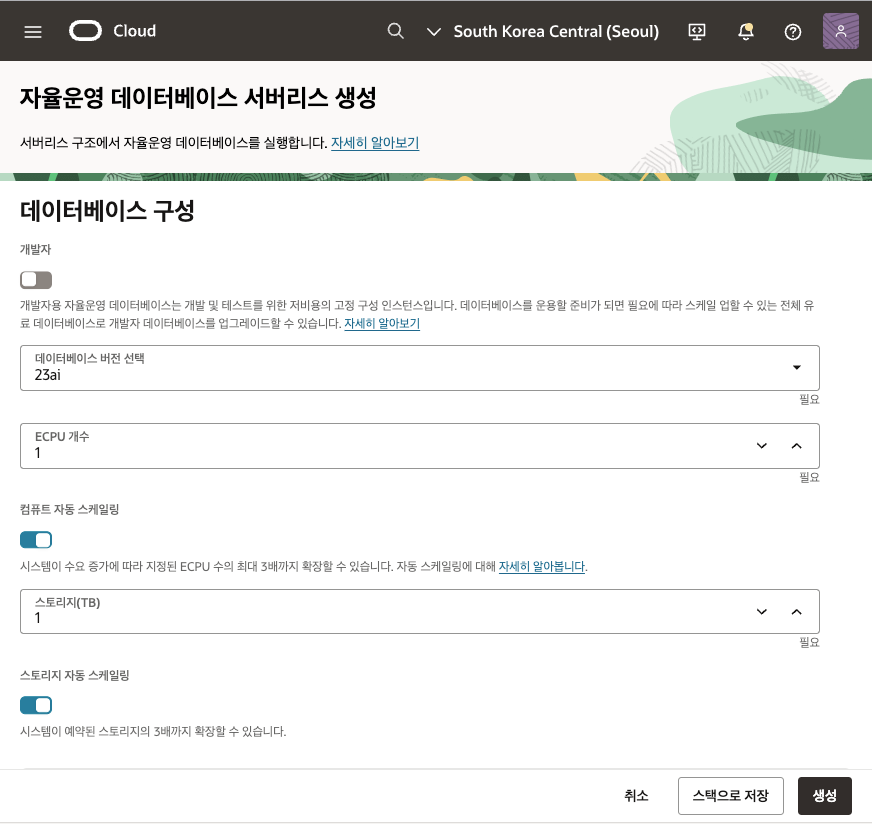
- 개발자 : 개발자용 Autonomous Database 로 고정된 4 ECPU, 최대 20GB 스토리지 사양으로 사용하실 수 있는 모드입니다.
- 자동 백업 옵션은 Default 로 두고 관리자 인증 생성 섹션까지 아래로 스크롤 하여 아래 화면처럼 ADMIN 사용자에 대한 Password 를 입력 후 생성 버튼을 클릭합니다.
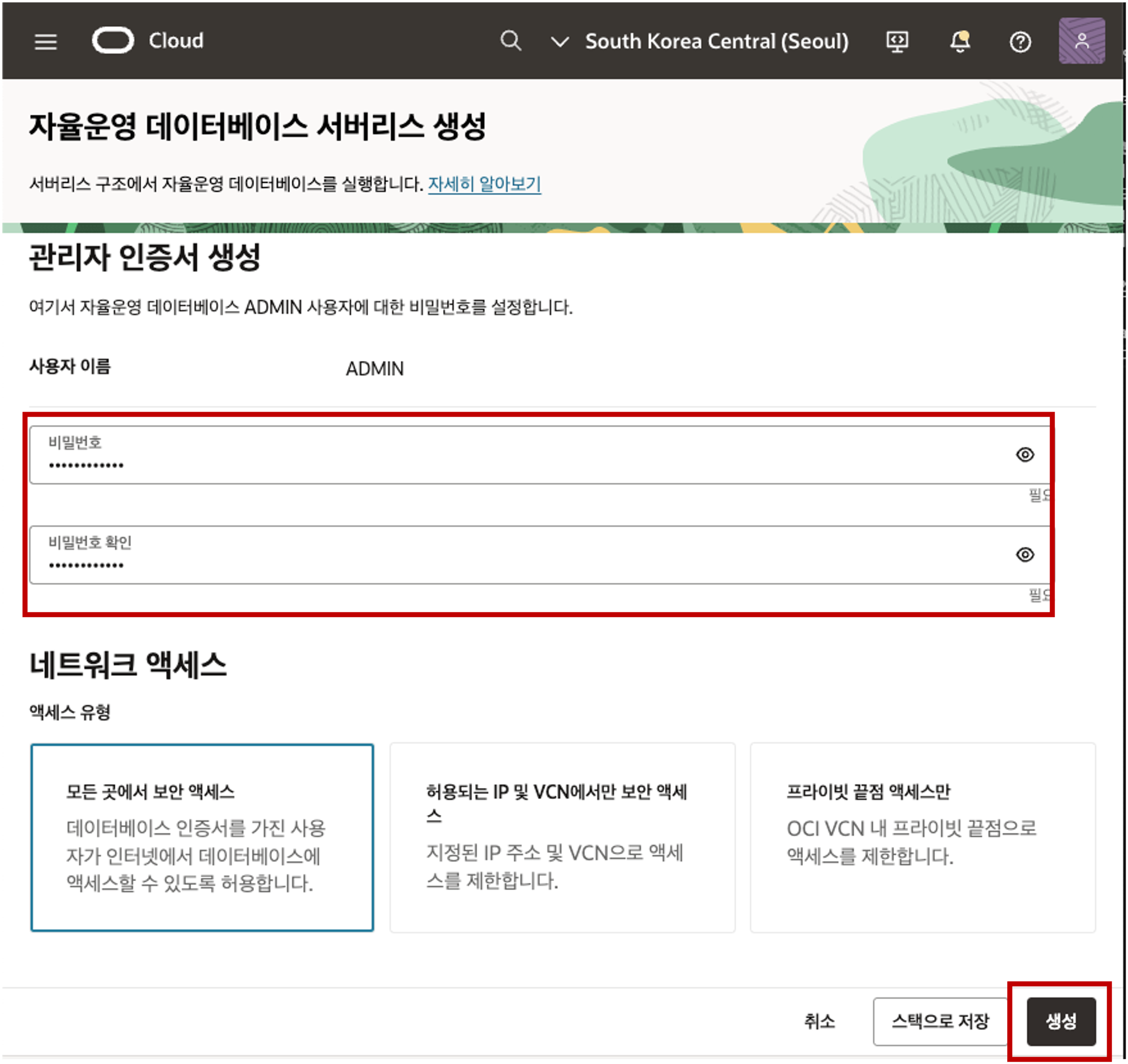
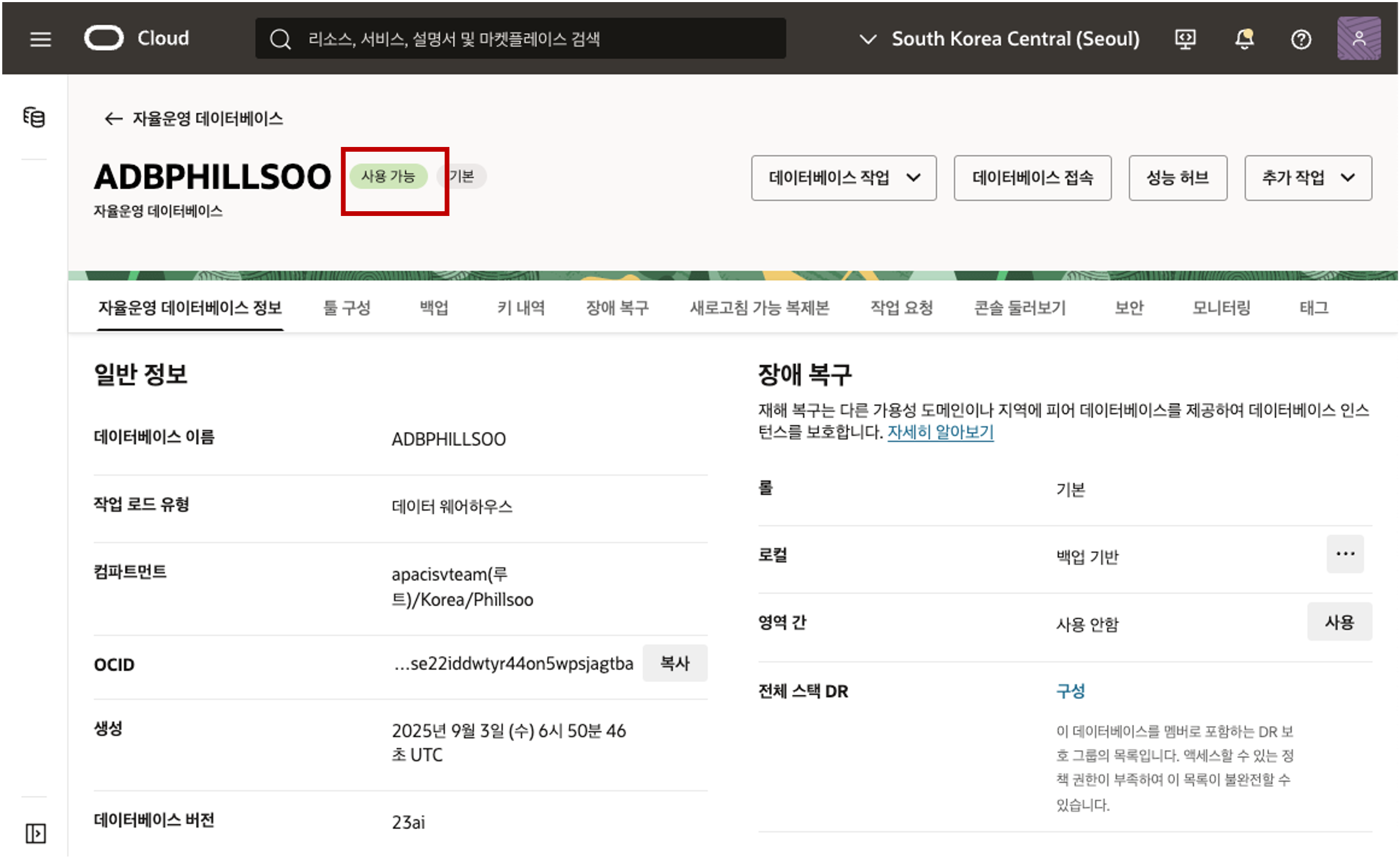
- 생성 버튼을 클릭하면 아래와 같이 화면이 전환되며 상태가 “프로비저닝” 상태였다가 2 ~ 3분 뒤 “사용 가능” 상태로 전환이 되면 데이터베이스를 즉시 사용하실 수 있습니다.
Autonomous Database 사용자 추가
Autonomous Database 에서는 사용자 관리, SQL Developer, Data Loader 등 다양한 데이터베이스 사용 툴들을 제공합니다. 데이터베이스에 신규 스키마를 생성하고 어플리케이션 개발을 위해 스키마의 Owner 인 신규 사용자를 생성해야 합니다. (기본적으로 생성된 관리자 사용자인 ADMIN 사용자는 관리 용도로만 사용 권고) 데이터베이스 사용자 관리 툴을 이용하여 사용자 추가를 실습합니다.
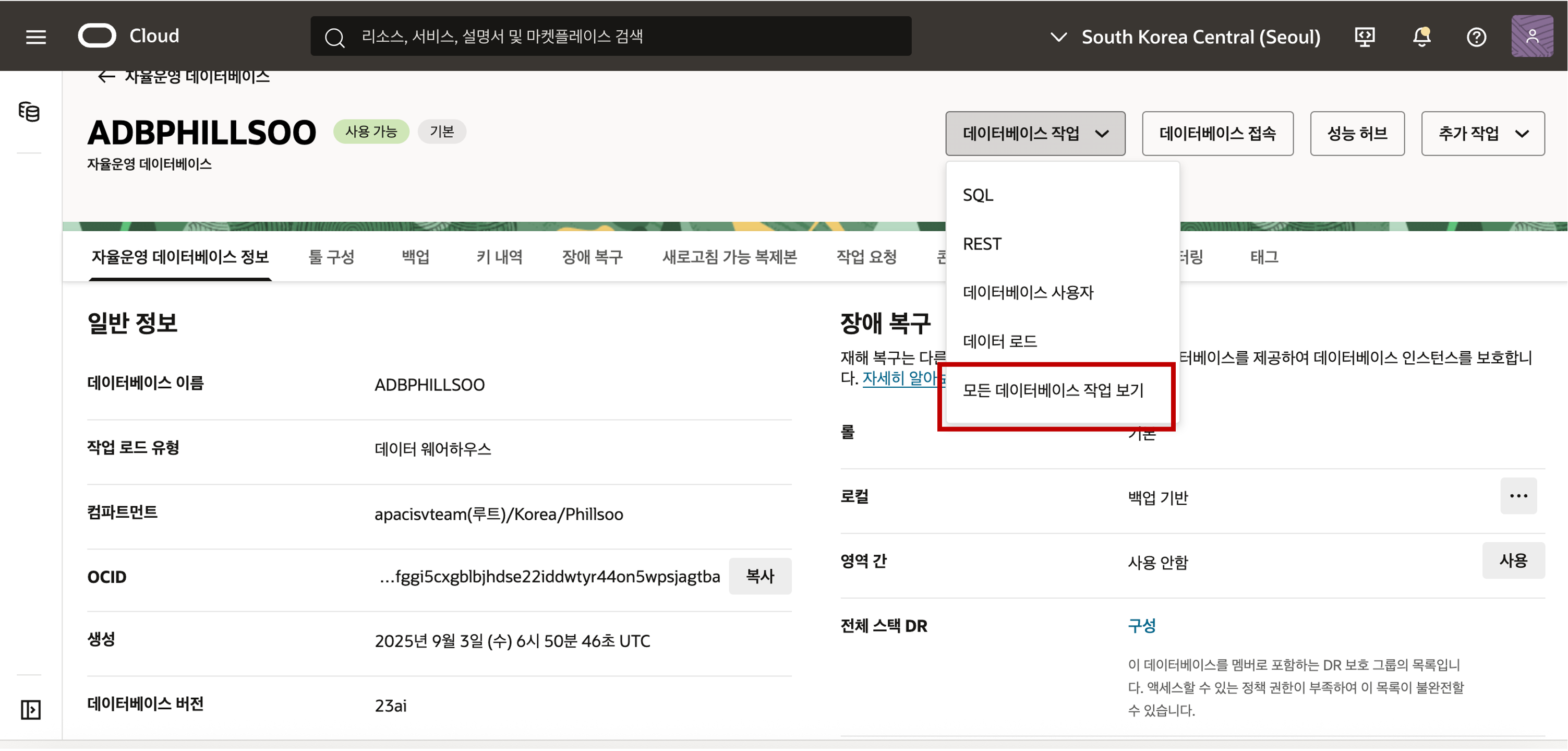
Autonomous Database 의 상세 화면에서 우측 상단의 “모든 데이터베이스 작업 보기” 버튼을 클릭하면 별도의 브라우저 윈도우가 팝업되어 사용할 수 있는 Autonomous Database 사용 Tool들이 있는 Database Actions 메뉴 화면이 나타납니다.
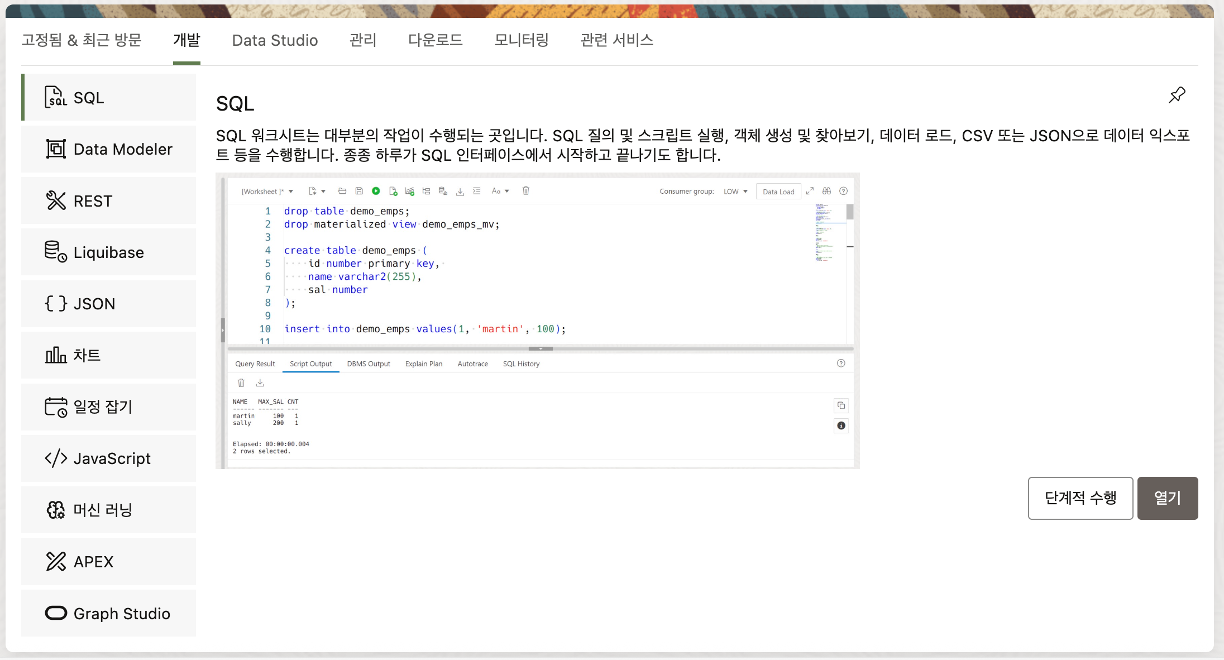
Database Actions 메뉴에서 관리 탭의 데이터베이스 사용자 메뉴를 선택하여 클릭하면 사용자를 추가할 수 있는 화면으로 전환됩니다.
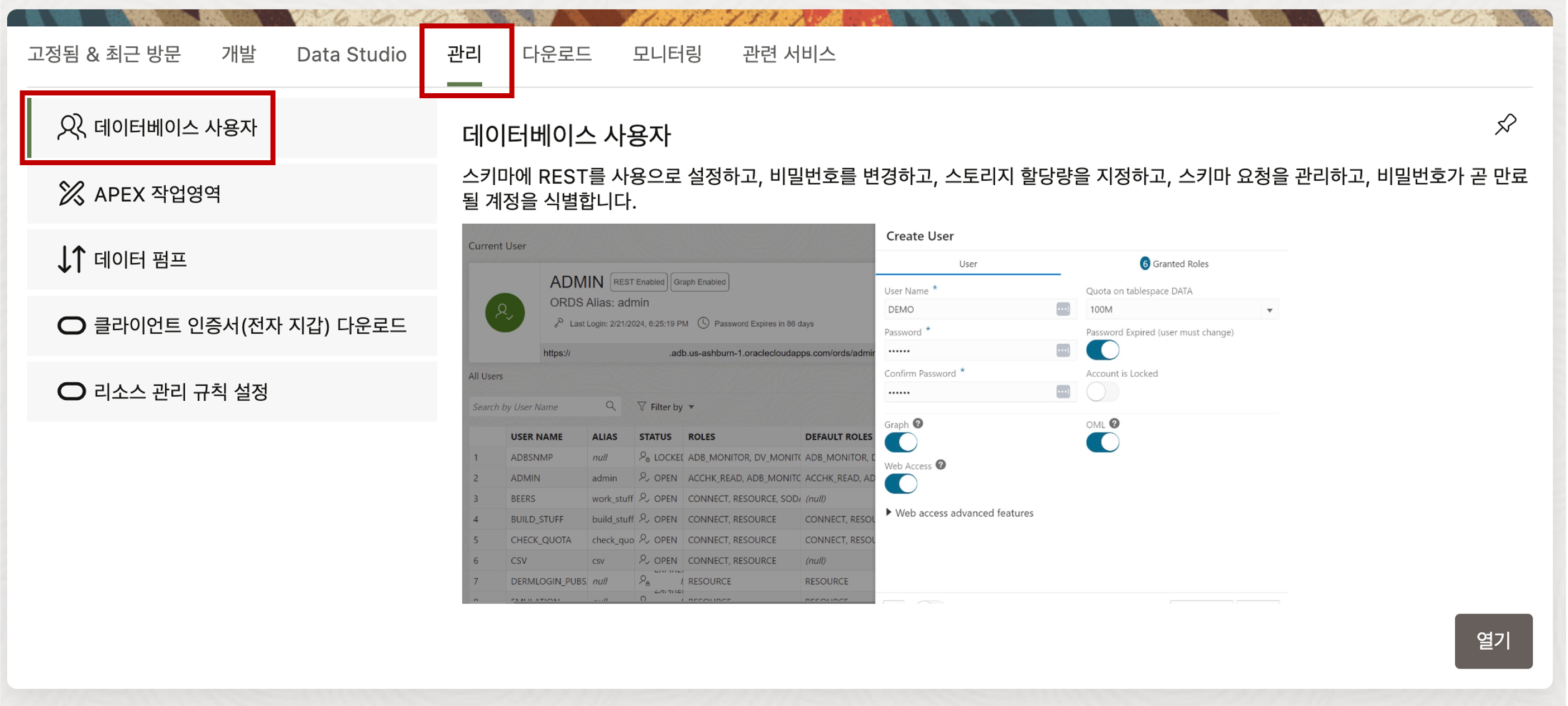
전환된 사용자 관리 화면에서 “+사용자 생성” 버튼을 클릭하면 사용자를 추가할 수 있는 메뉴가 나타납니다.
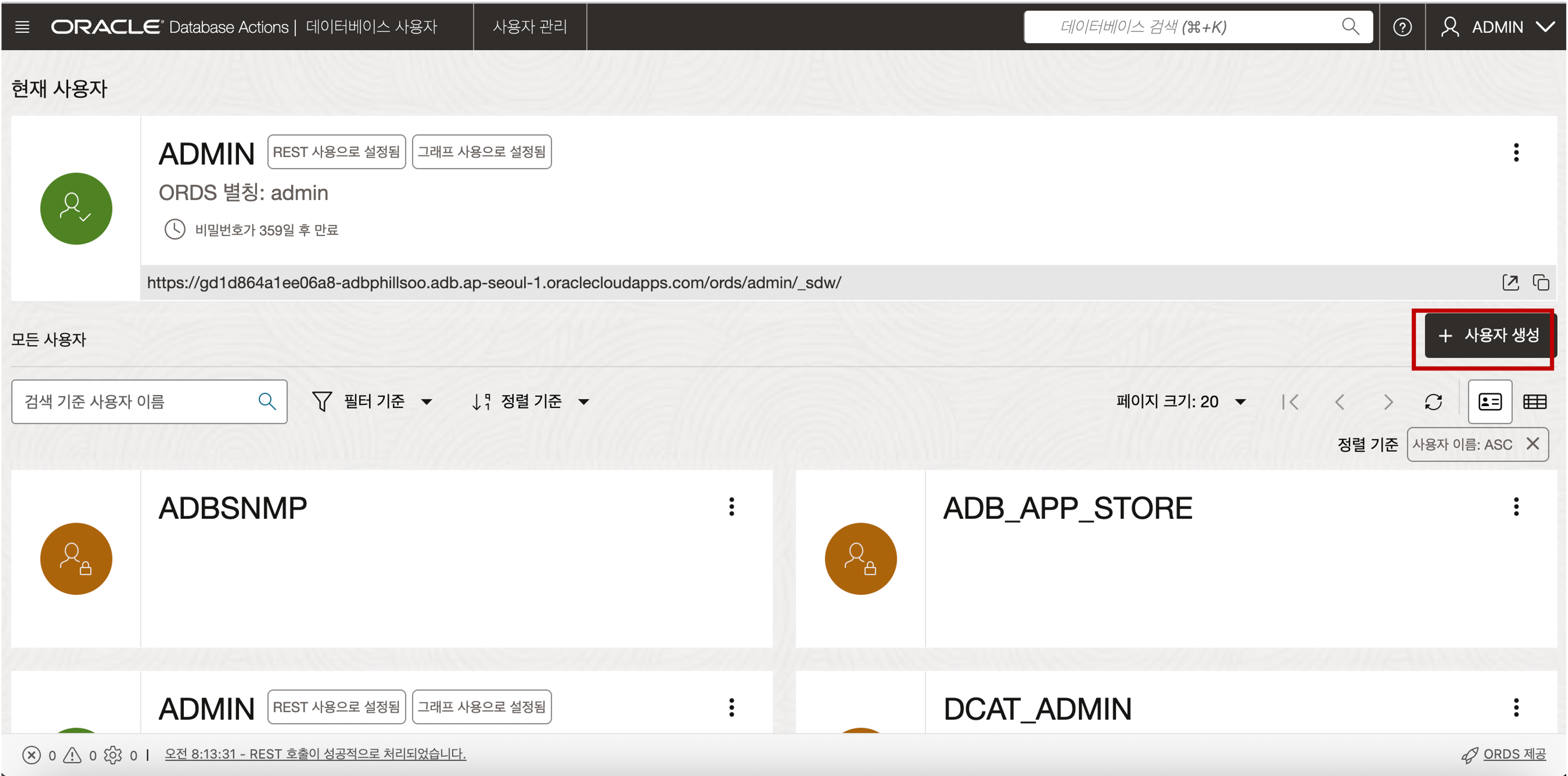
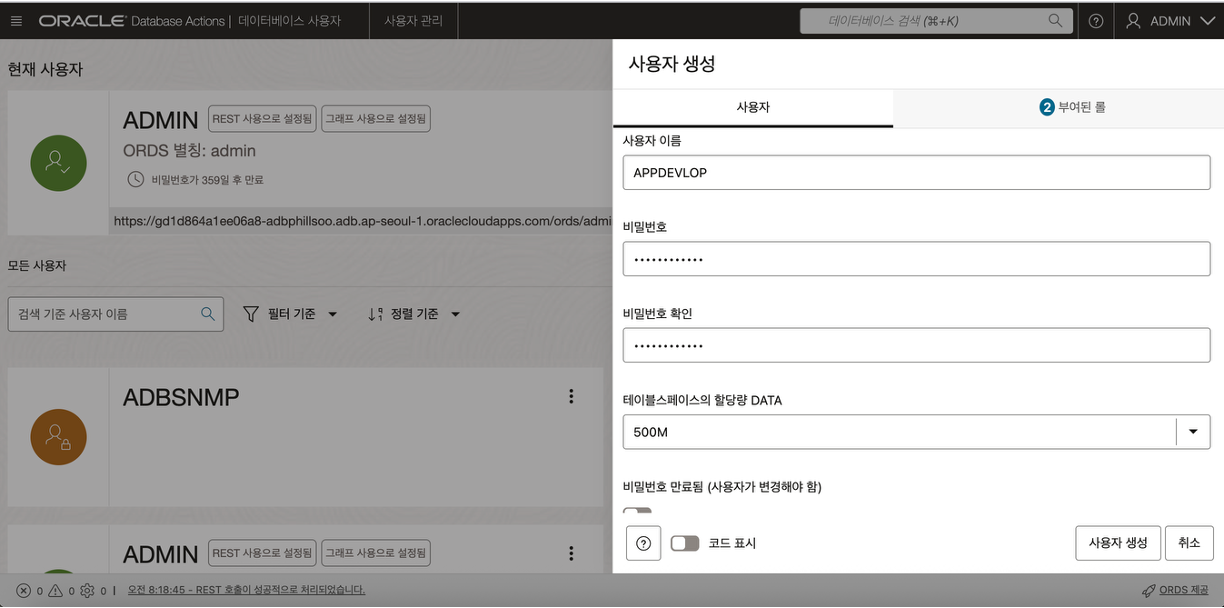
- 전환된 사용자 관리 화면에서 “+사용자 생성” 버튼을 클릭하면 사용자를 추가할 수 있는 메뉴가 나타납니다. 사용자 추가를 위해 아래의 항목들을 입력 및 선택하여 사용자를 생성합니다.
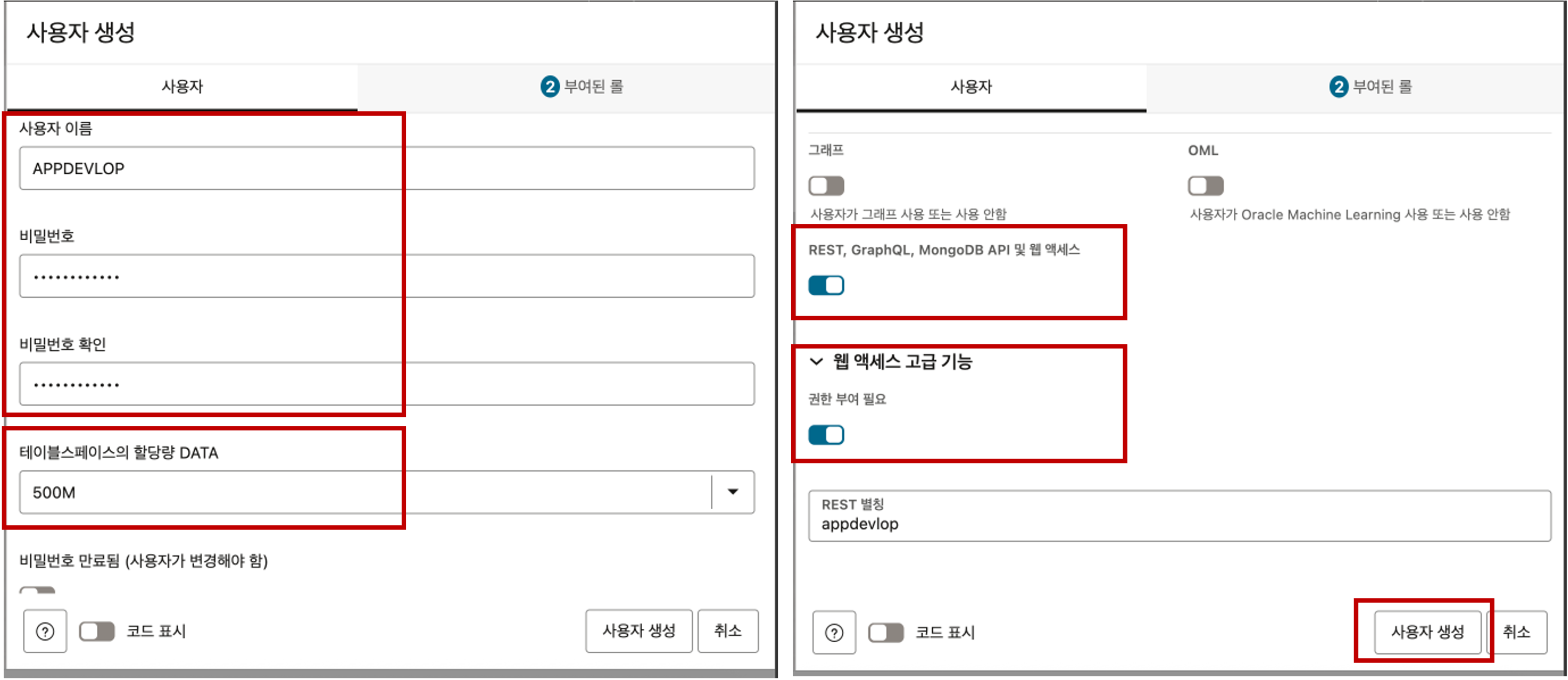
- 사용자 이름 : 데이터베이스 사용자 이름을 입력합니다.
- 비밀 번호 : 데이터베이스 사용자 비밀번호를 입력합니다.
- 테이블스페이스의 할당량 DATA : 데이터베이스 사용자에게 할당될 데이터 사이즈를 드랍다운 목록에서 선택하여 줍니다. (사이즈:25M, 100M, 500M, 1GB, UNLIMITED 중 택 1)
- REST, GraphQL, MongoDB API 및 웹 엑세스 : True 로 선택
- 웹 엑세스 고급 기능의 권한 부여 필요 옵션 : True 로 선택
추가한 사용자(예:APPDEVELOP)가 사용자 목록에 나타났는지 확인 후 로그인된 ADMIN 사용자를 사인아웃합니다.
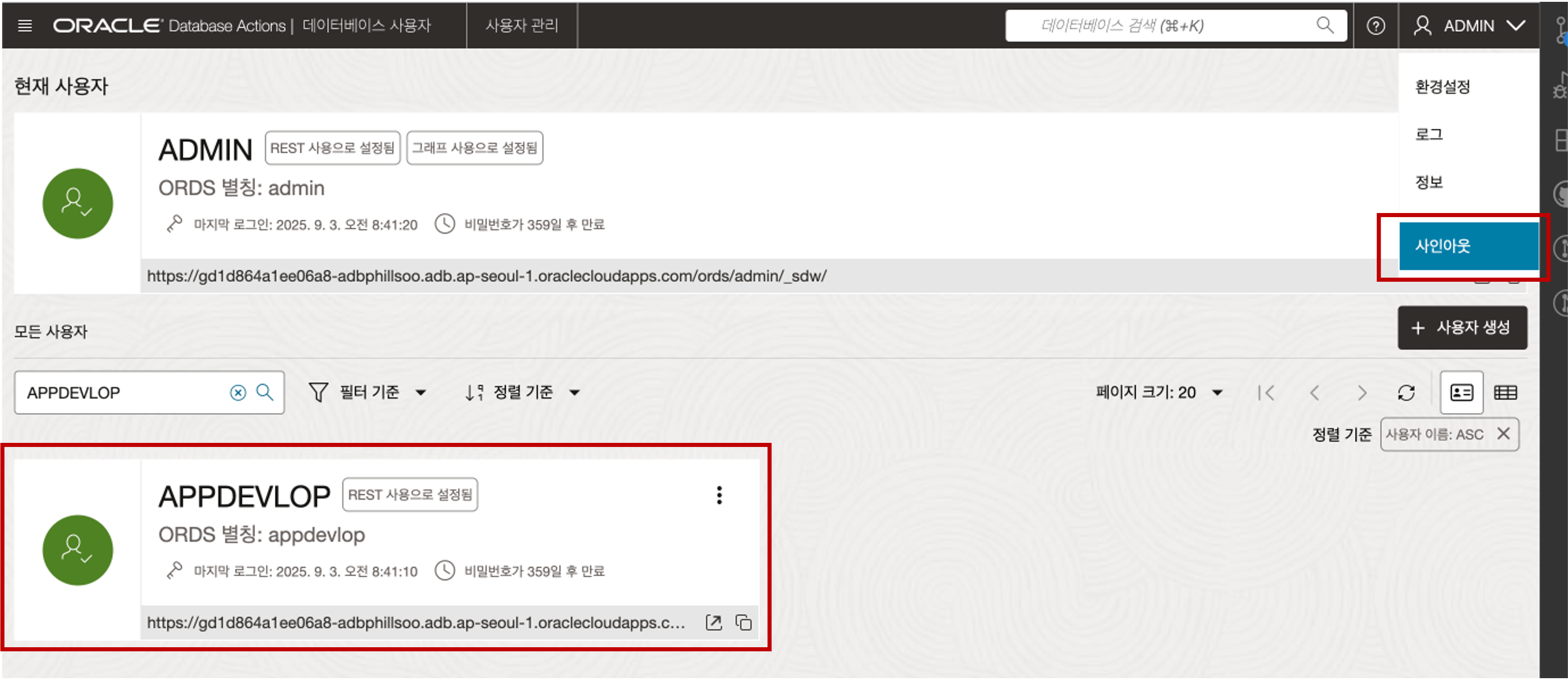
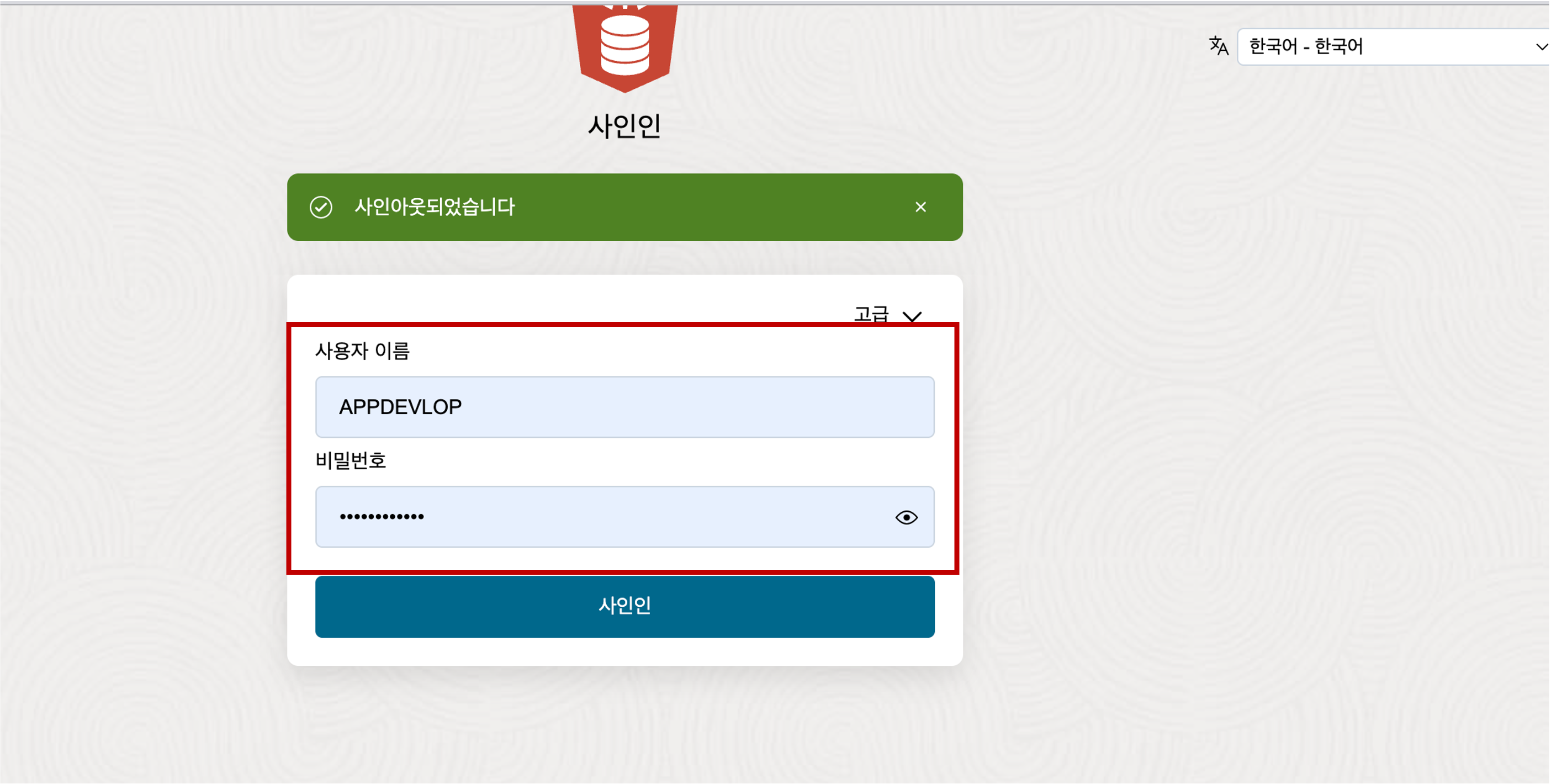
로그아웃을 수행하면 다시 로그인 화면이 나타납니다. 추가한 사용자(예:APPDEVELOP)로 Database Actions 화면으로 제대로 로그인이 되는지 확인합니다.
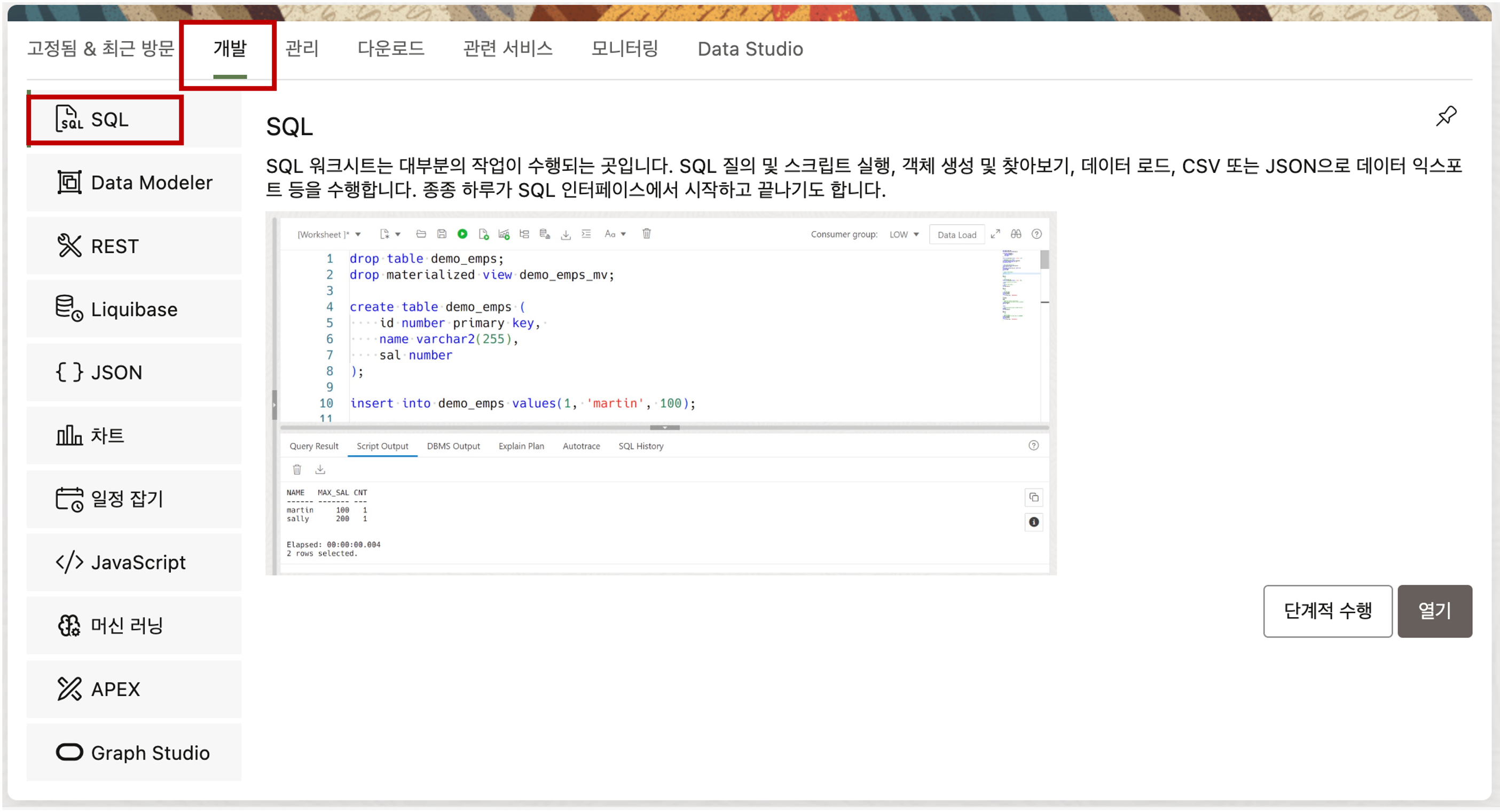
로그인한 Database Actions 화면에서 개발 탭의 SQL 메뉴를 클릭하여 SQL Developer 가 실행되는지 확인합니다.
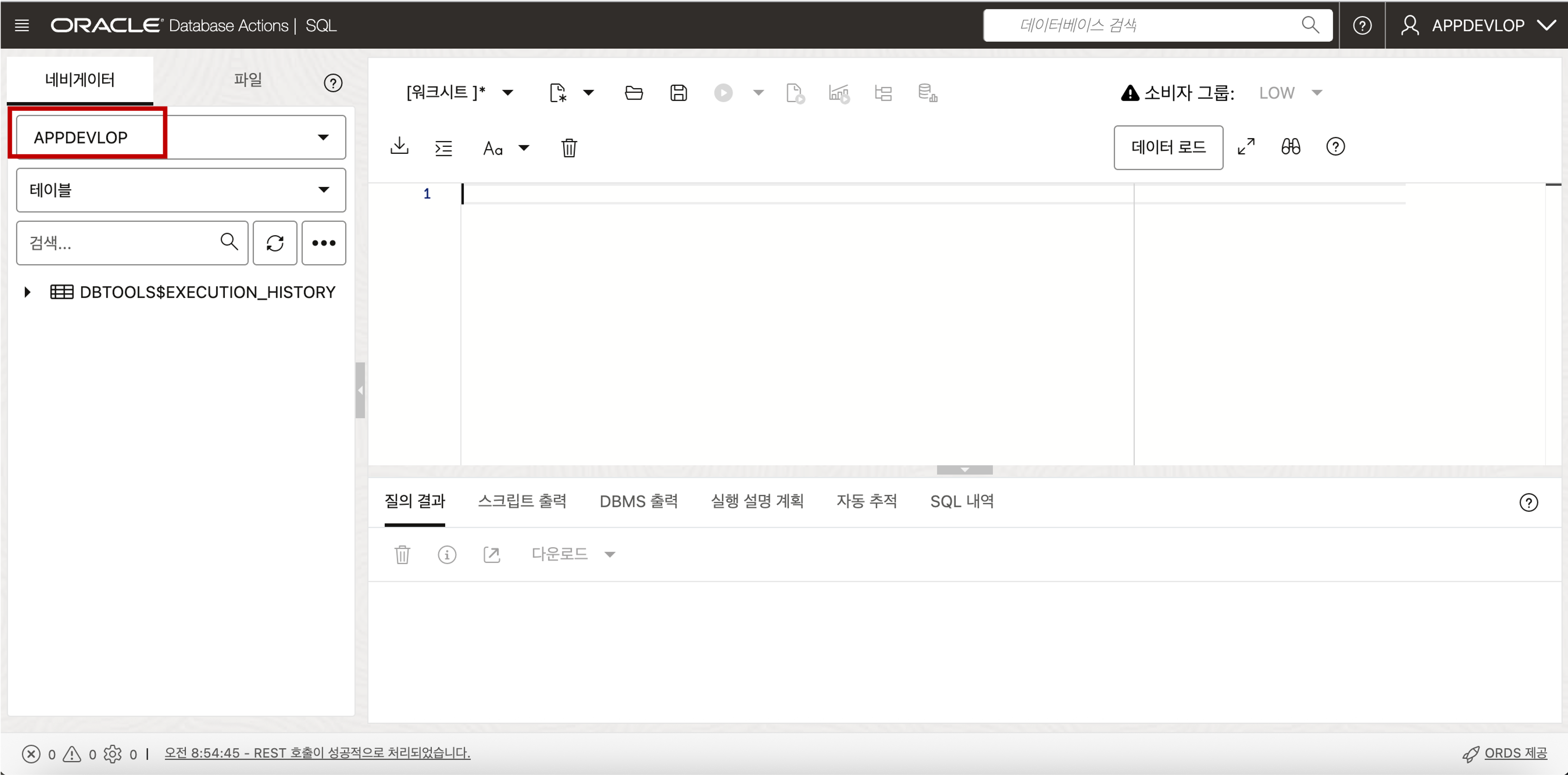
- 이제 추가된 사용자를 가지고 데이터를 Loading 하고 어플리케이션을 개발할 준비가 되었습니다.
Autonomous Database 에 Data Loading (Local CSV 파일)
이제 준비된 Autonomous Database 에 추가한 사용자의 스키마에 데이터를 로딩하는 방법에 대해 살펴봅니다. Autonomous Database 는 보다 손쉽게 데이터를 로딩할 수 있는 방법을 제공합니다. 로컬에 있는 CSV 파일을 Autonomous Database 로 데이터를 로딩하는 방법에 대해 실습합니다.
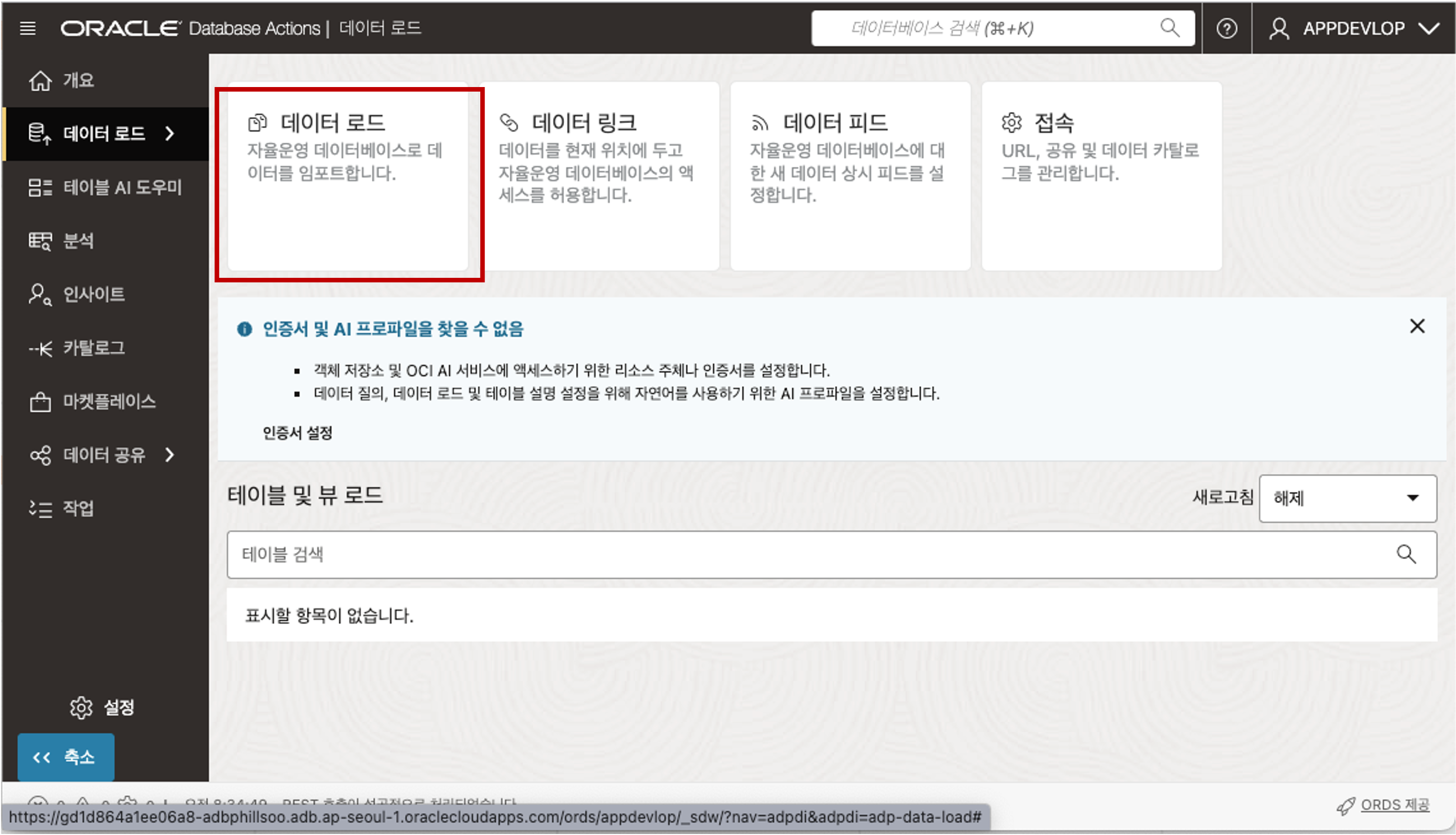
Database Actions 의 Data Load 툴을 이용하여 Local Disk 에 있는 CSV 파일을 Loading 할 수 있습니다. 먼저, 아래의 화면에서 Data Studio 의 데이터 로드 메뉴를 선택합니다. 전환된 데이터 로드 화면에서 데이터 로드 타일을 선택합니다.
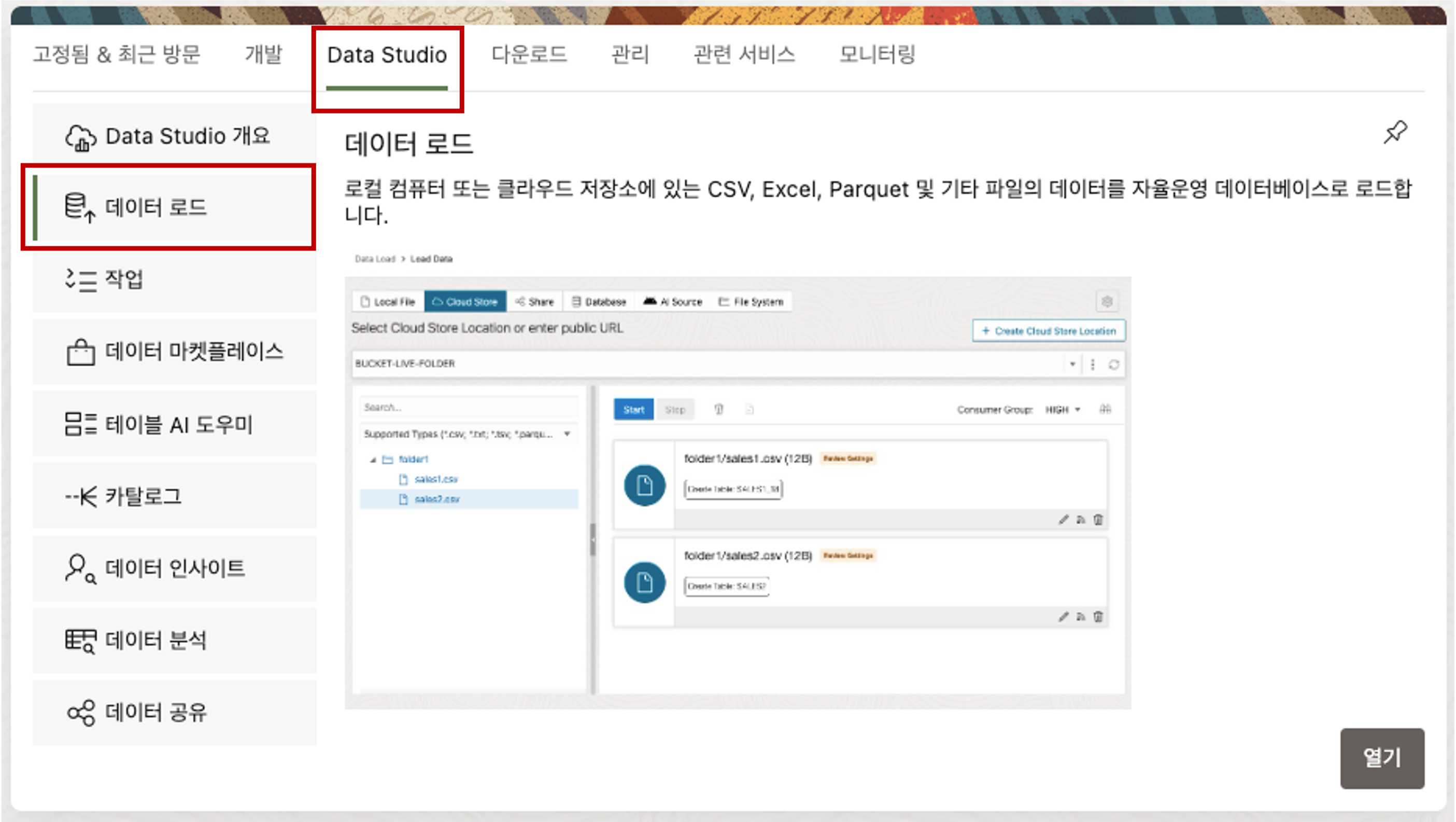
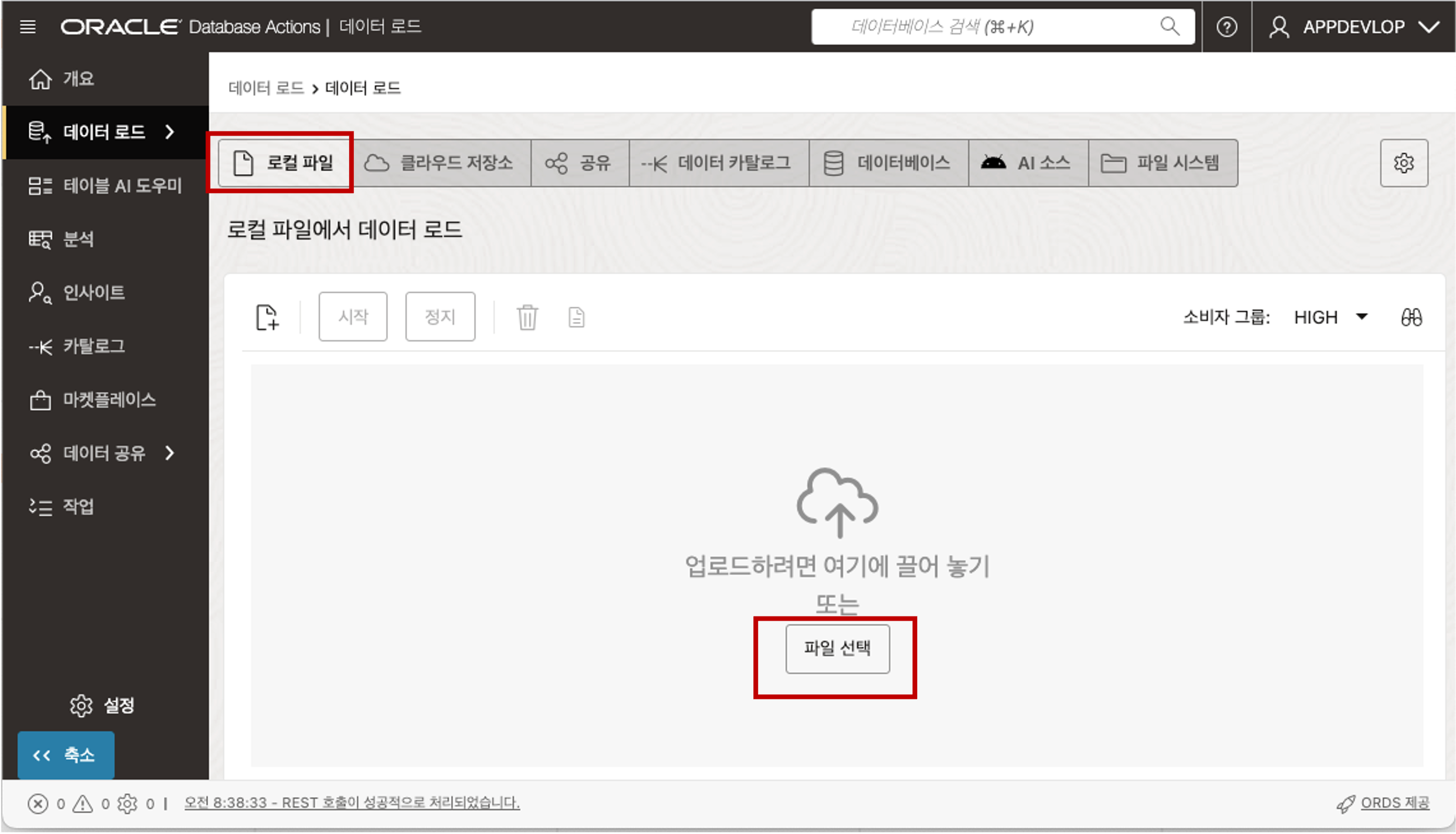
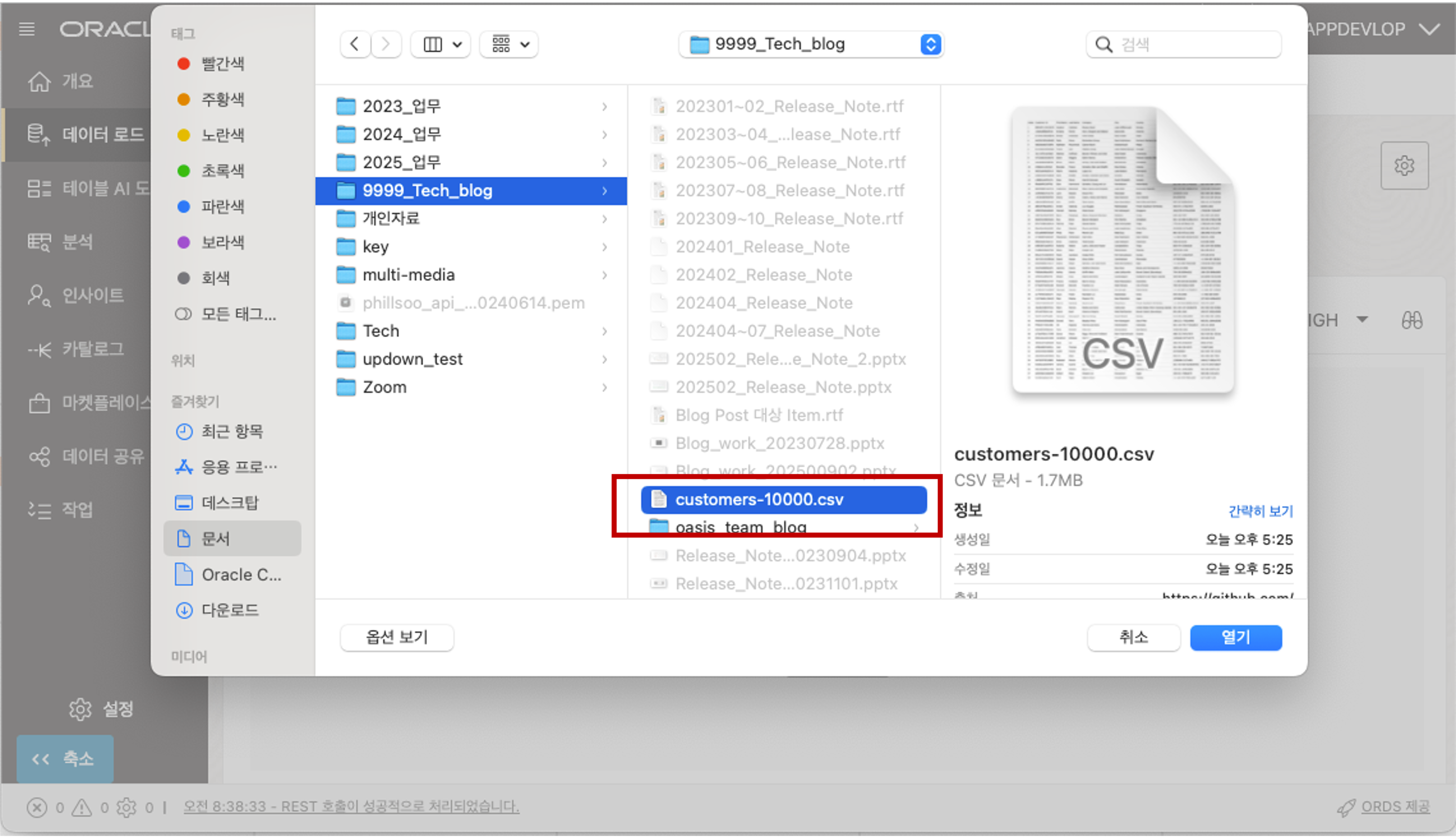
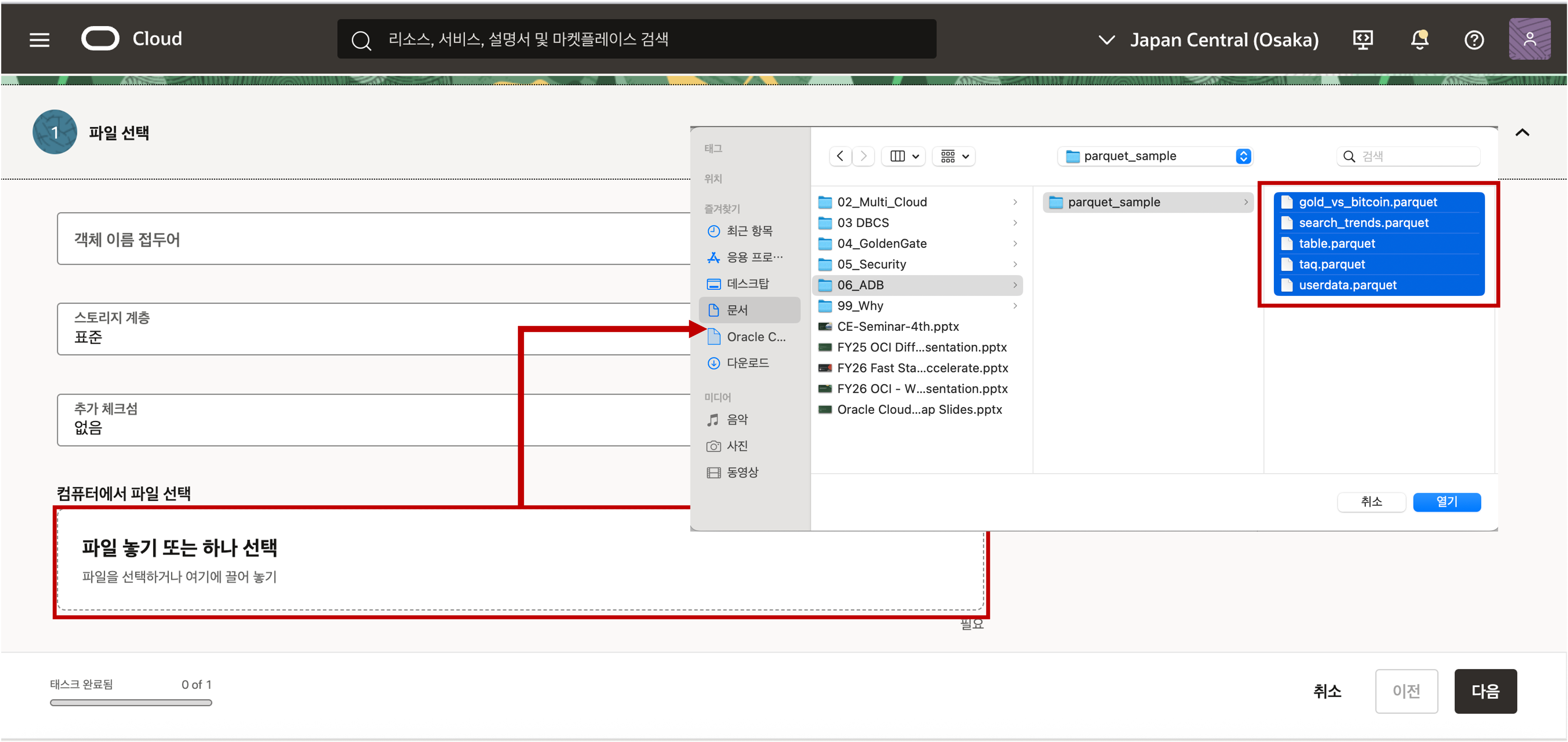
데이터 로드 메뉴에서 로컬 파일 메뉴를 선택하면 아래에 로컬 파일을 업로드 할 수 있는 창이 나타납니다. 로컬 파일을 Drag 해서 파일을 끌어 놓거나 파일 선택 버튼을 클릭하여 로드할 데이터 CSV 파일을 선택하여 줍니다.
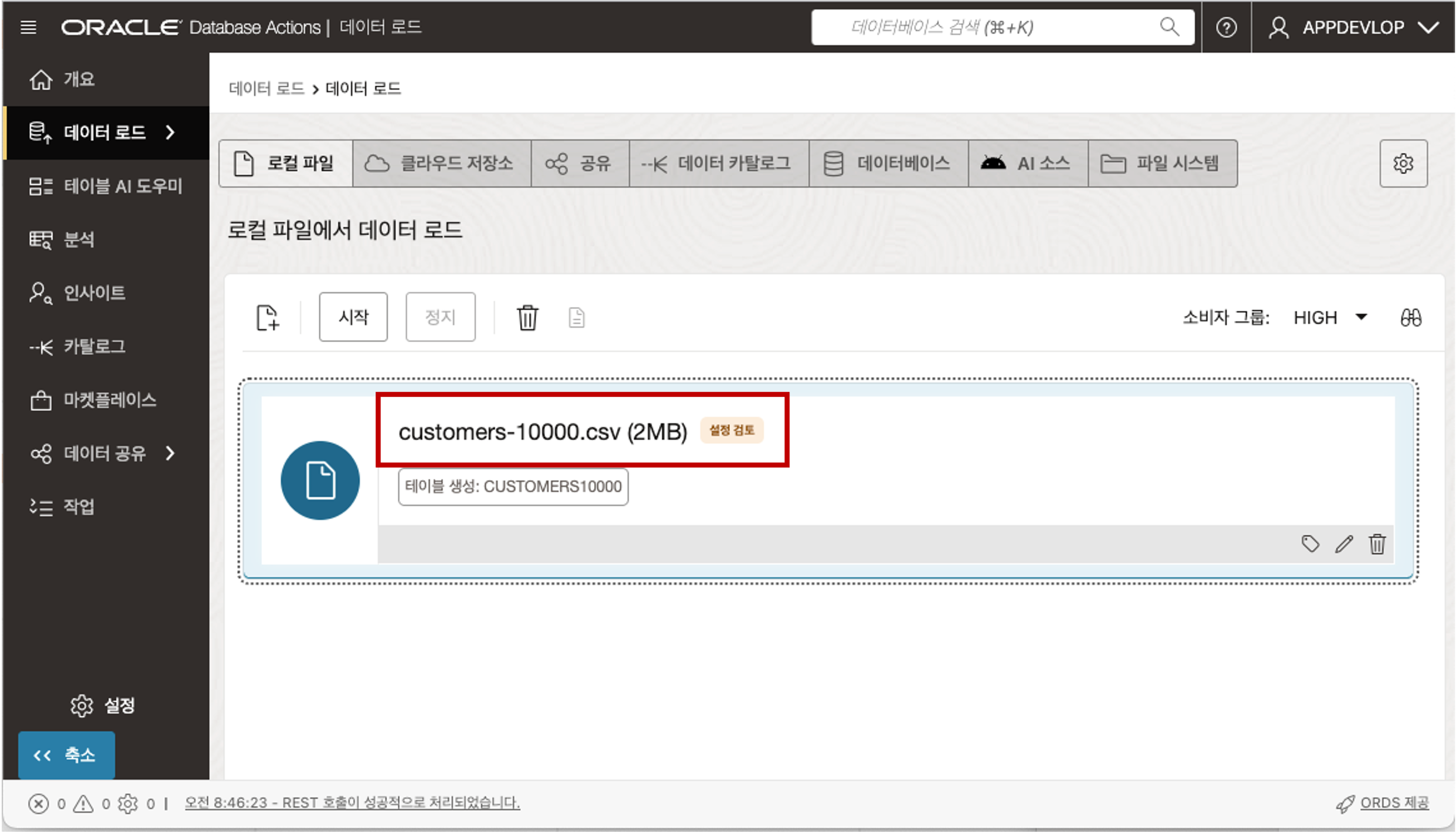
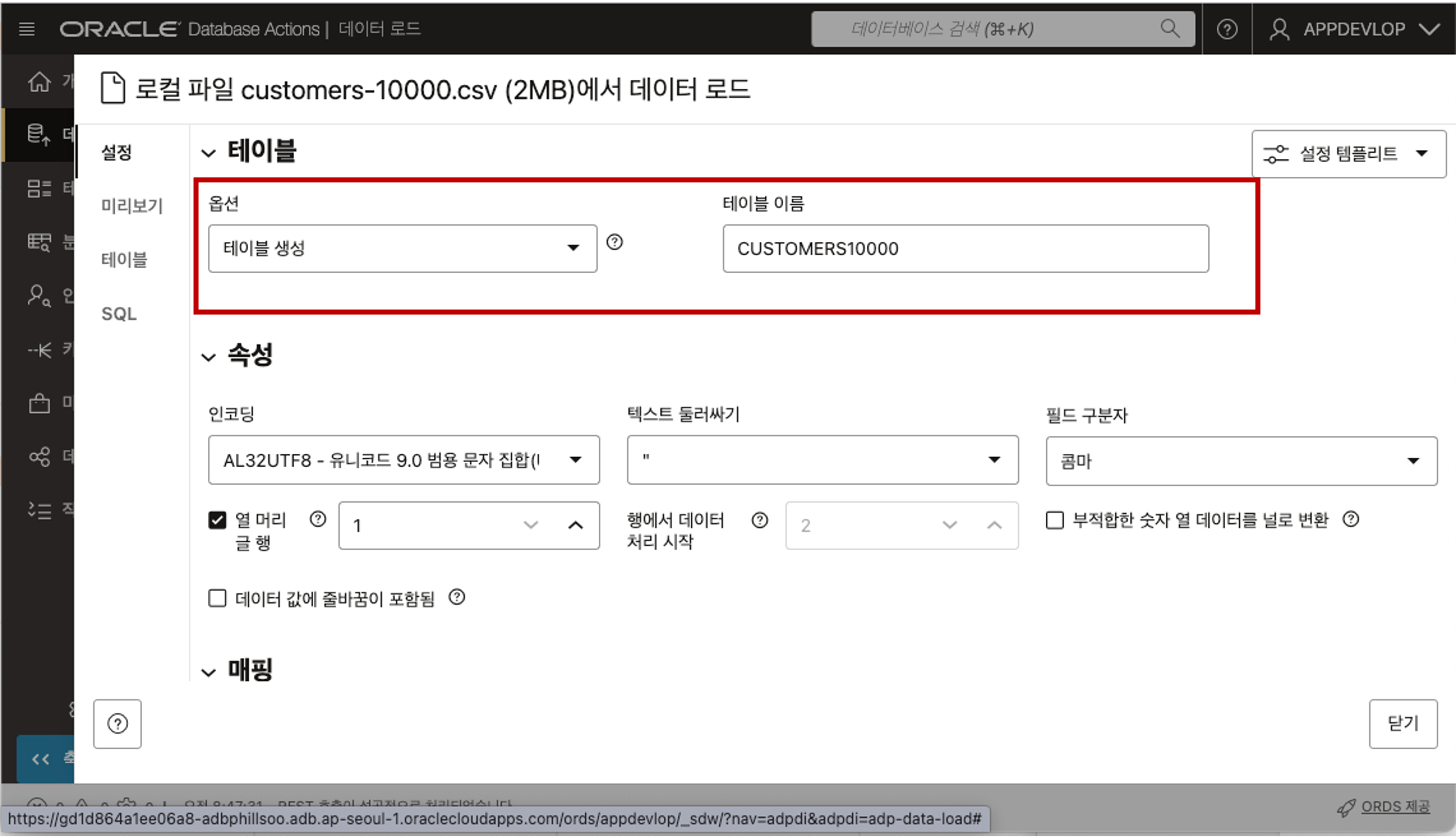
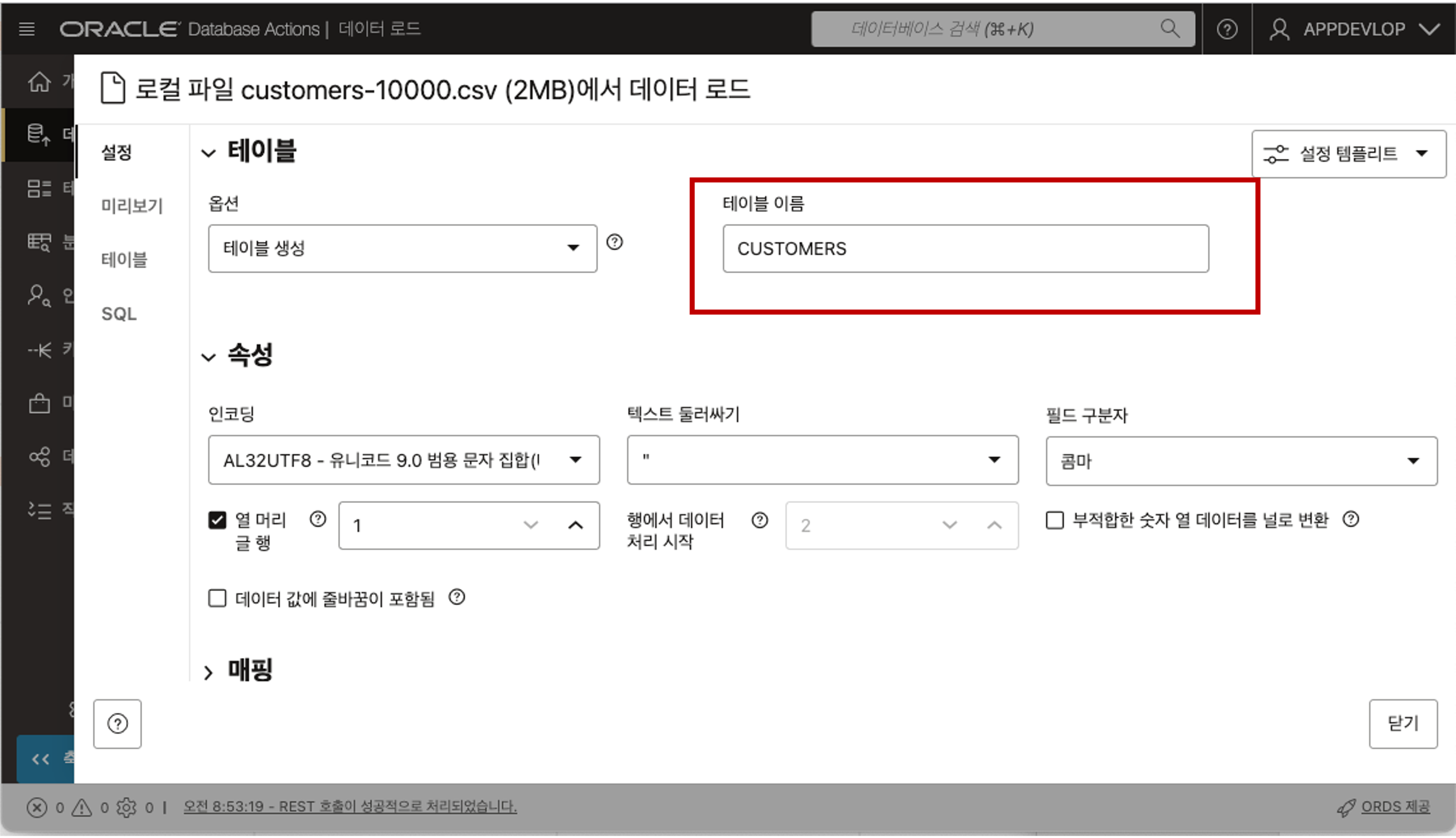
선택한 CSV 파일이 업로드되고 해당 파일을 Database 에 로드하기 전에 검토할 수 있습니다. 업로드된 파일명을 클릭하면 아래와 같이 테이블의 이름은 어떤 이름으로 만들 것인지 혹은 기존 테이블이 존재하면 데이터를 삽입하거나 병합할 것인지를 선택할 수 있습니다. 테이블 이름은 파일이름을 기준으로 자동으로 입력이 되는데 원하는 이름으로 변경할 수 있습니다.
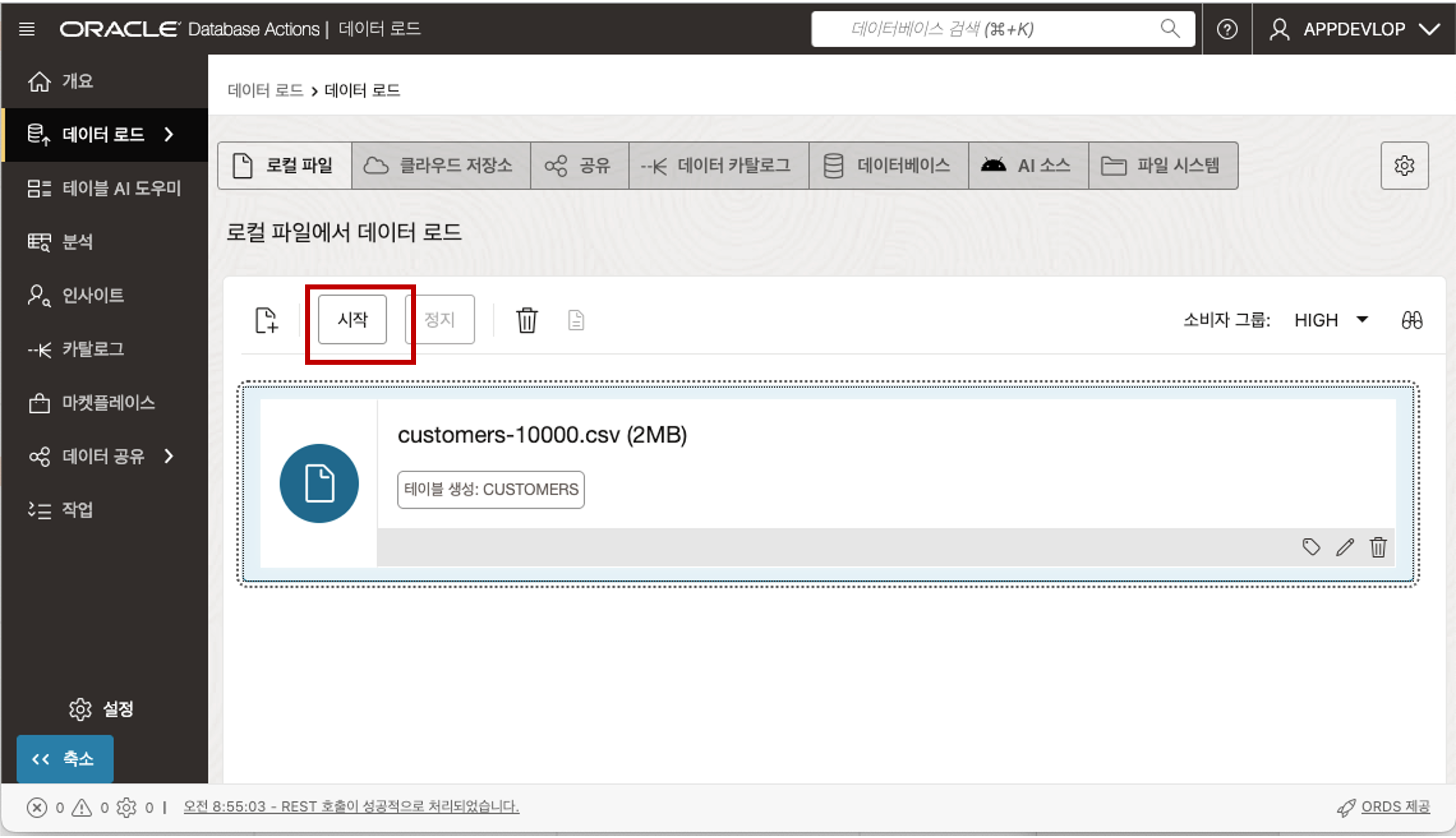
닫기 버튼을 클릭하고 파일 목록 상단의 시작 버튼을 클릭하면 데이터 로딩을 시작합니다. 데이터 로딩이 완료되면 로딩 결과 보고서를 확인하실 수 있습니다.
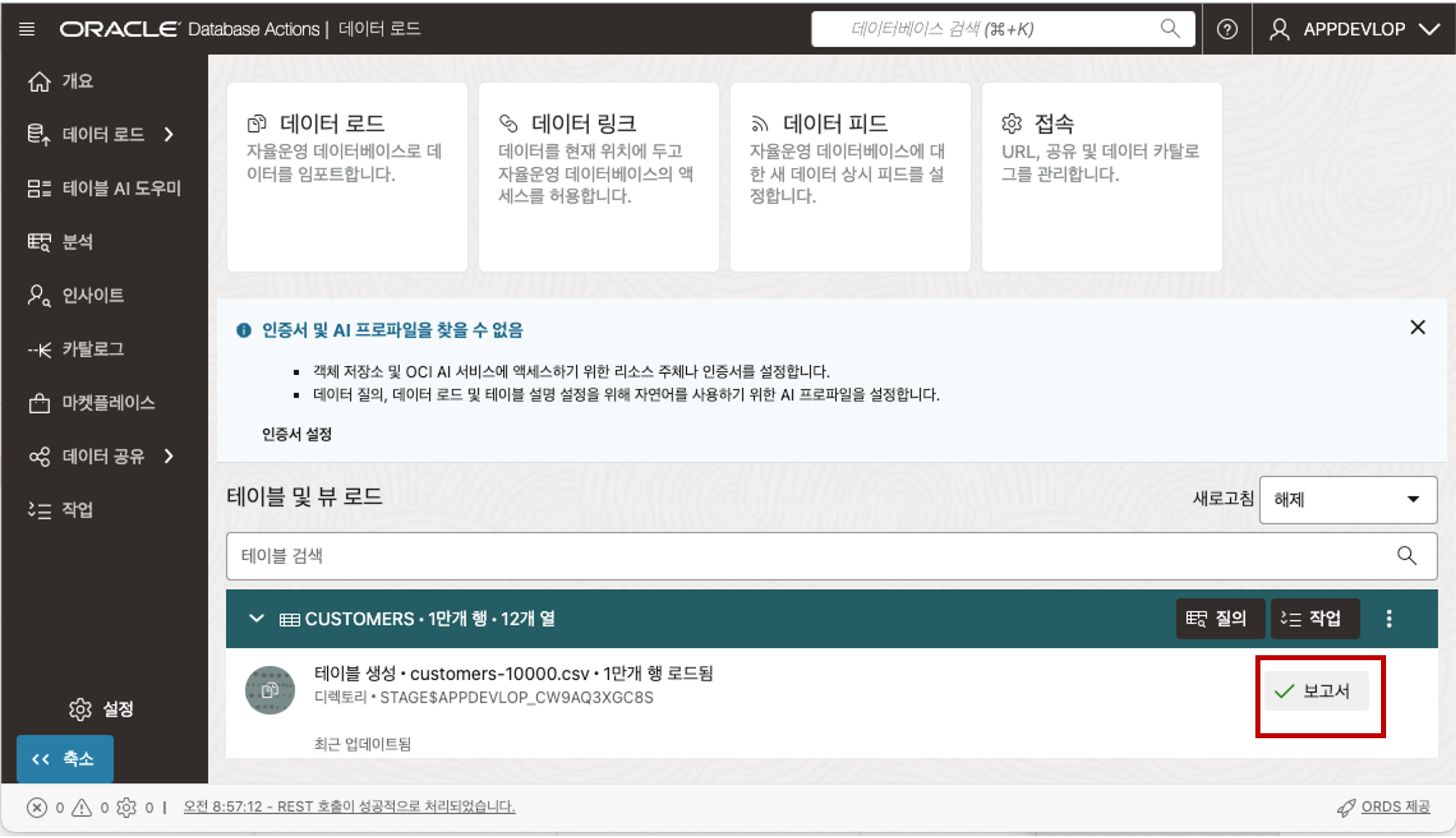
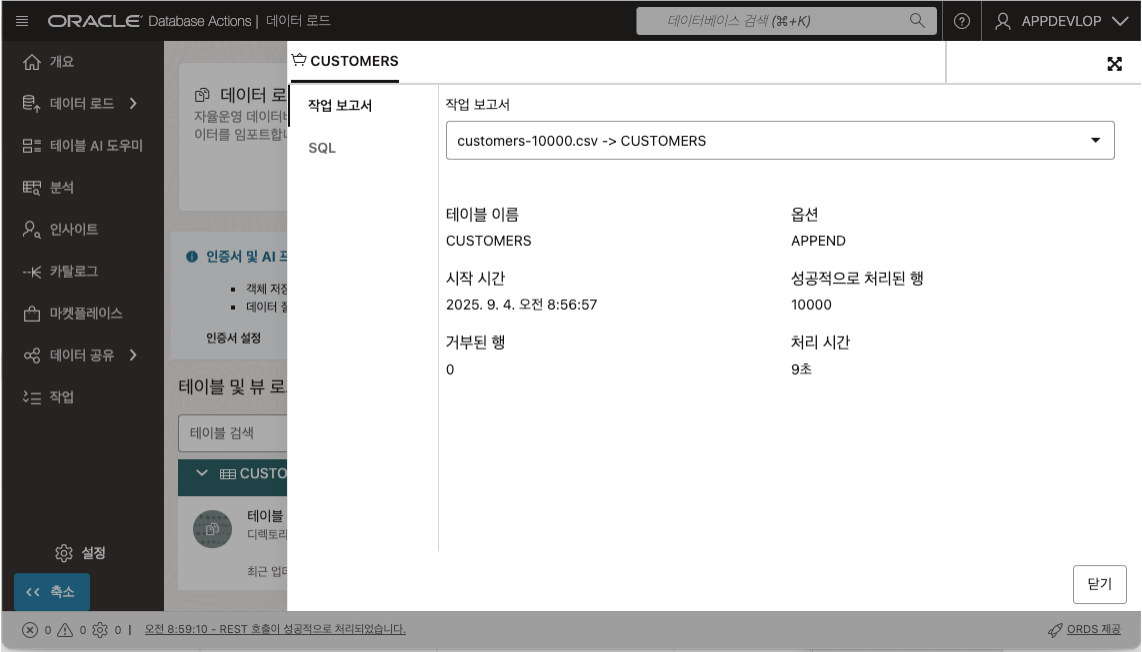
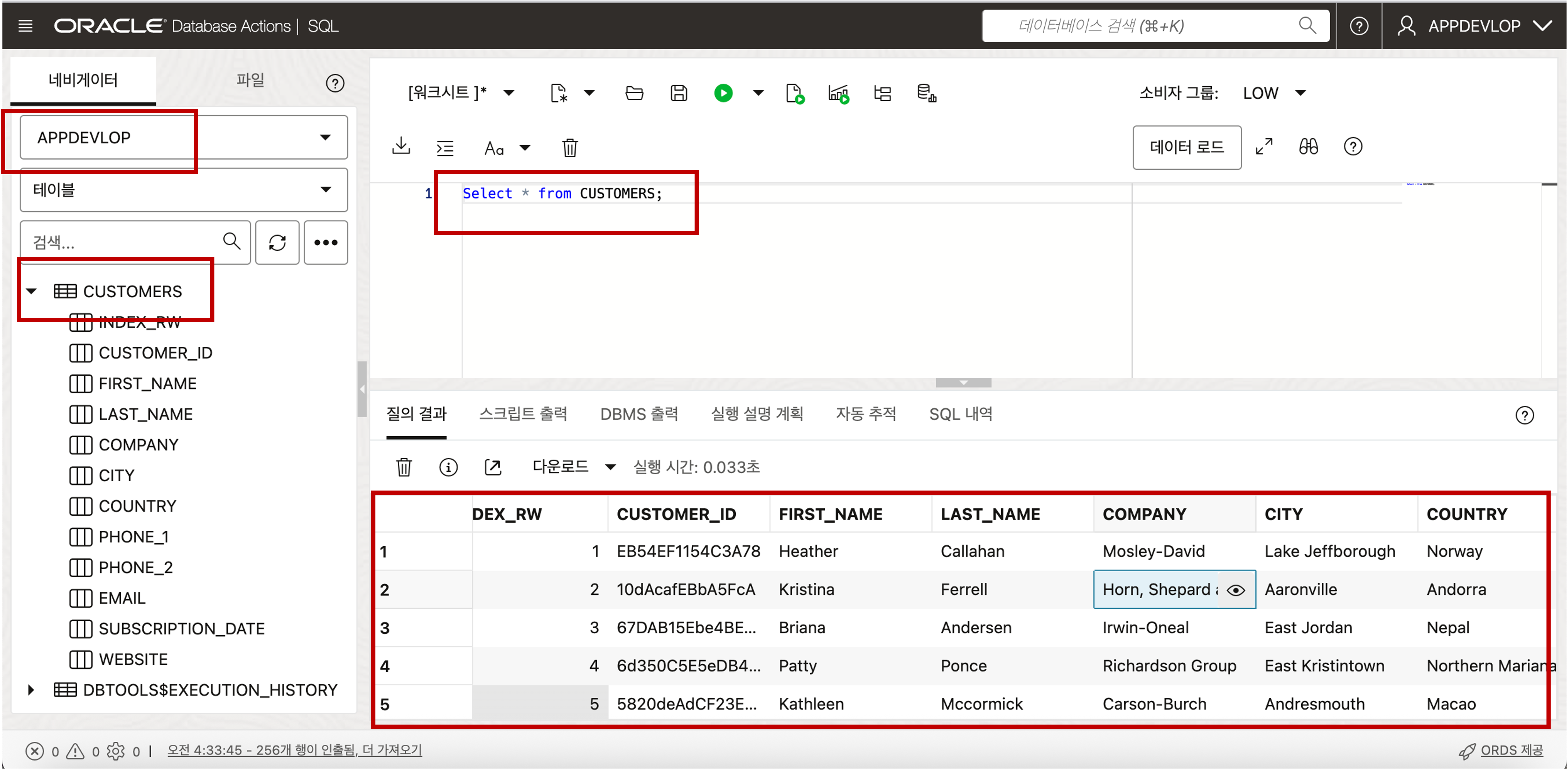
로딩된 데이터를 확인하기 위해서 Database Actions 툴에서 제공하는 SQL Developer 를 통해 확인할 수 있습니다.
Autonomous Database 에 Data Loading (Private Object Storage 의 Parquet 파일)
데이터를 Private Object Storage 에 대량으로 Parquet 파일 형태로 보관하고 있을 경우, Autonomous Database 의 Data Loader 툴을 통해 직접 Object Storage 에서 Autonomous Database 로 Data Load 를 수행할 수 있습니다.
Object Storage 에 있는 Parquet 파일을 Data Loading 하기 위해 Parquet 파일을 준비하여 Object Storage 로 업로드 합니다. 테스트를 위해 공개된 Parquet 파일을 다운로드하여 Object Storage 로 업로드 실습을 진행합니다. 먼저, 버킷 생성을 위해 Object Storage 의 버킷 메뉴로 이동합니다.

컴파트먼트를 확인한 후 버킷 생성 버튼을 클릭한 후 버킷 이름을 입력하고 스토리지 계층을 표준으로 선택한 후 버킷 생성 버튼을 클릭합니다.

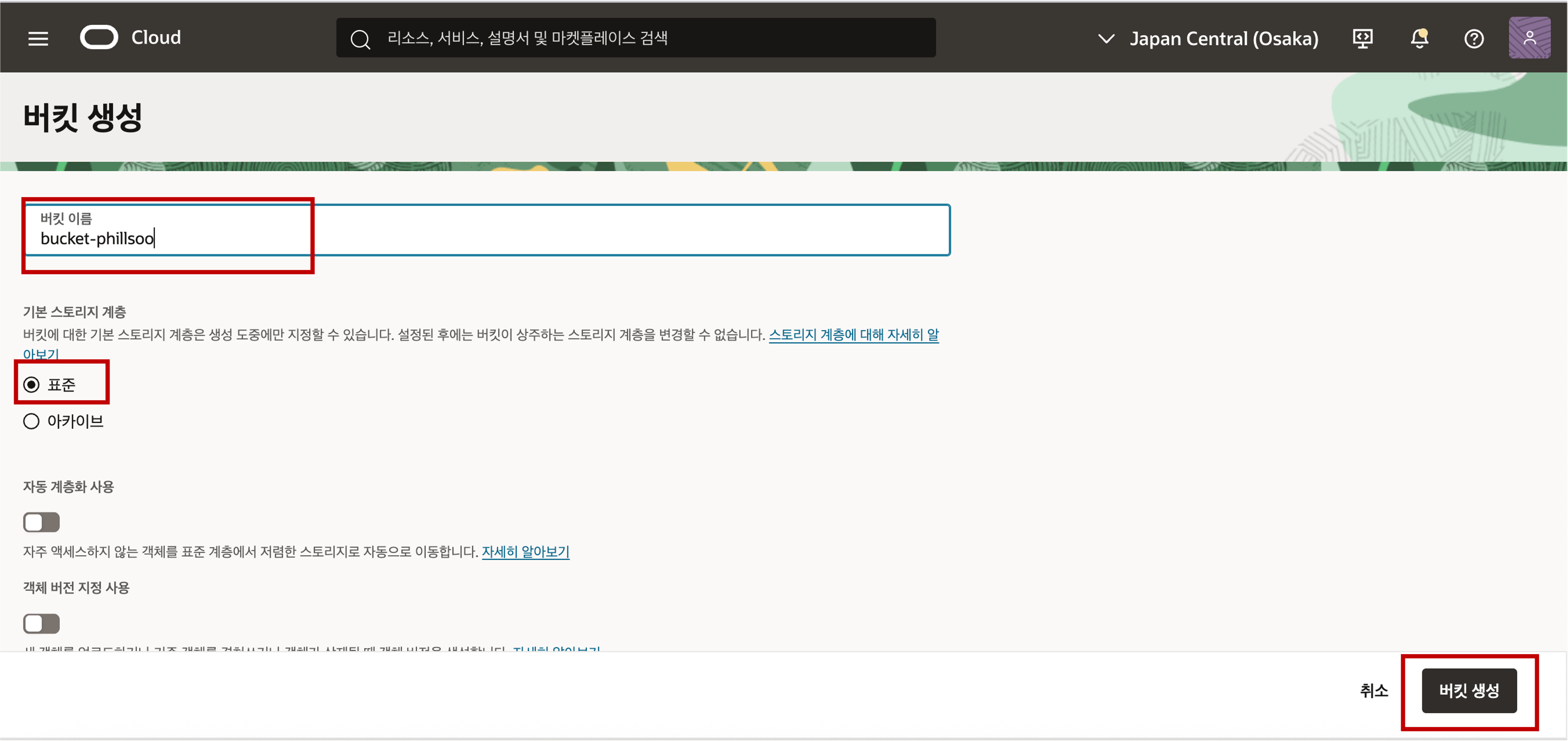
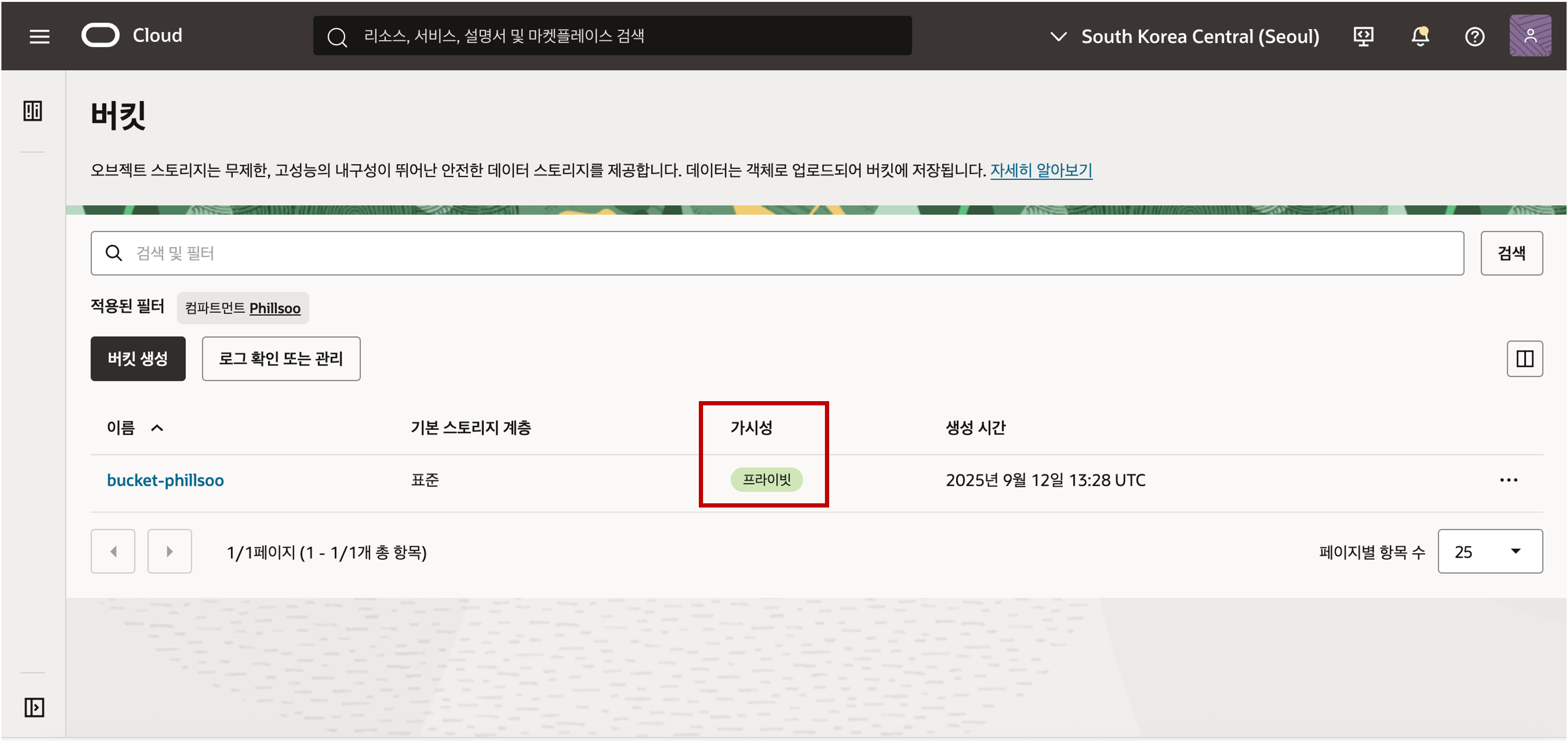
생성된 버킷의 가시성은 기본적으로 보안이 보장된 프라이빗 버킷으로 설정된 것을 확인할 수 있습니다.
버킷을 클릭하여 버킷의 상세 정보로 접근해서 객체 탭을 클릭하면 버킷에 올라가 있는 파일이나 폴더의 객체를 확인하실 수 있습니다. 객체 업로드 버튼을 클릭하여 로컬 디스크에 준비한 Parquet 파일들을 Object Storage 의 Bucket 에 업로드 합니다.
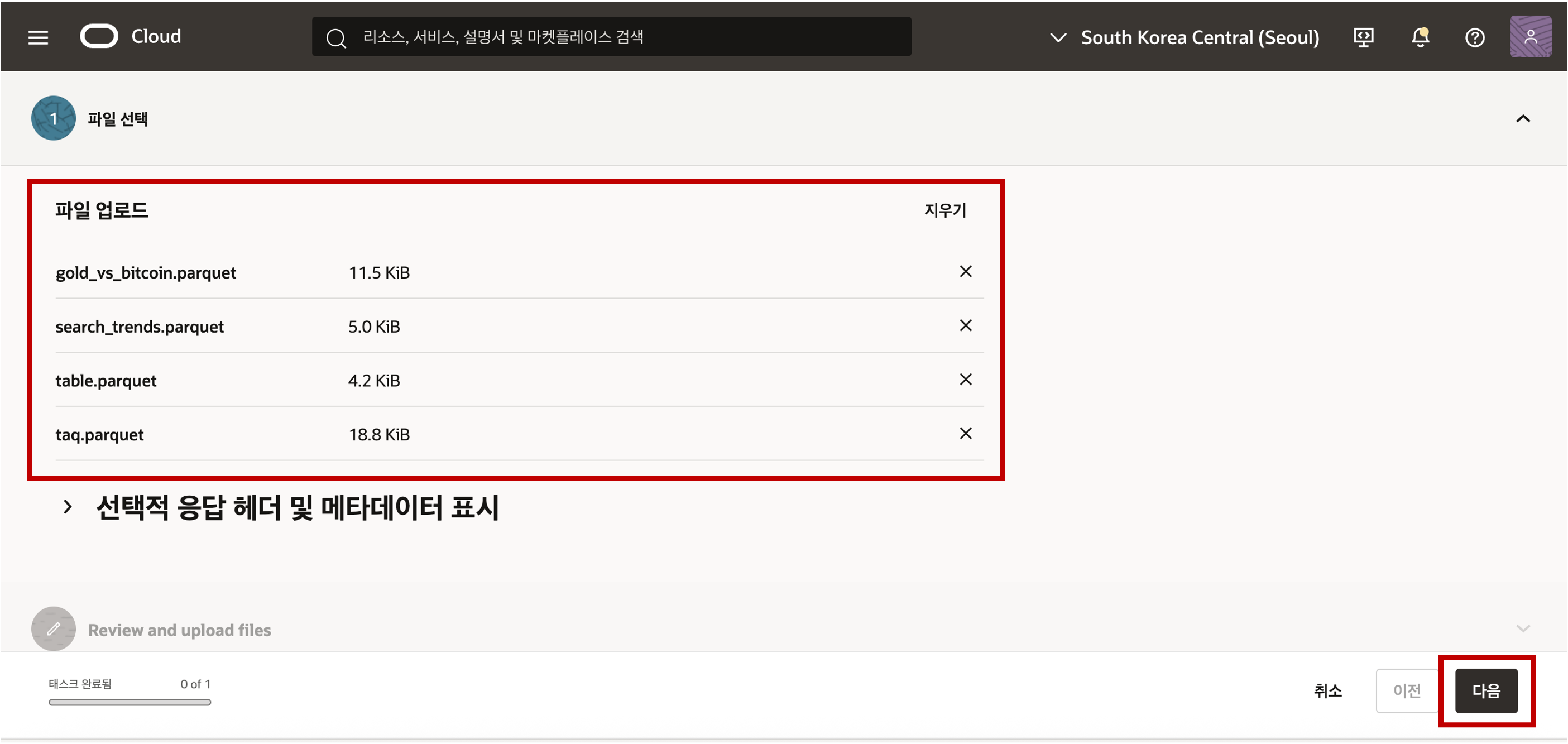
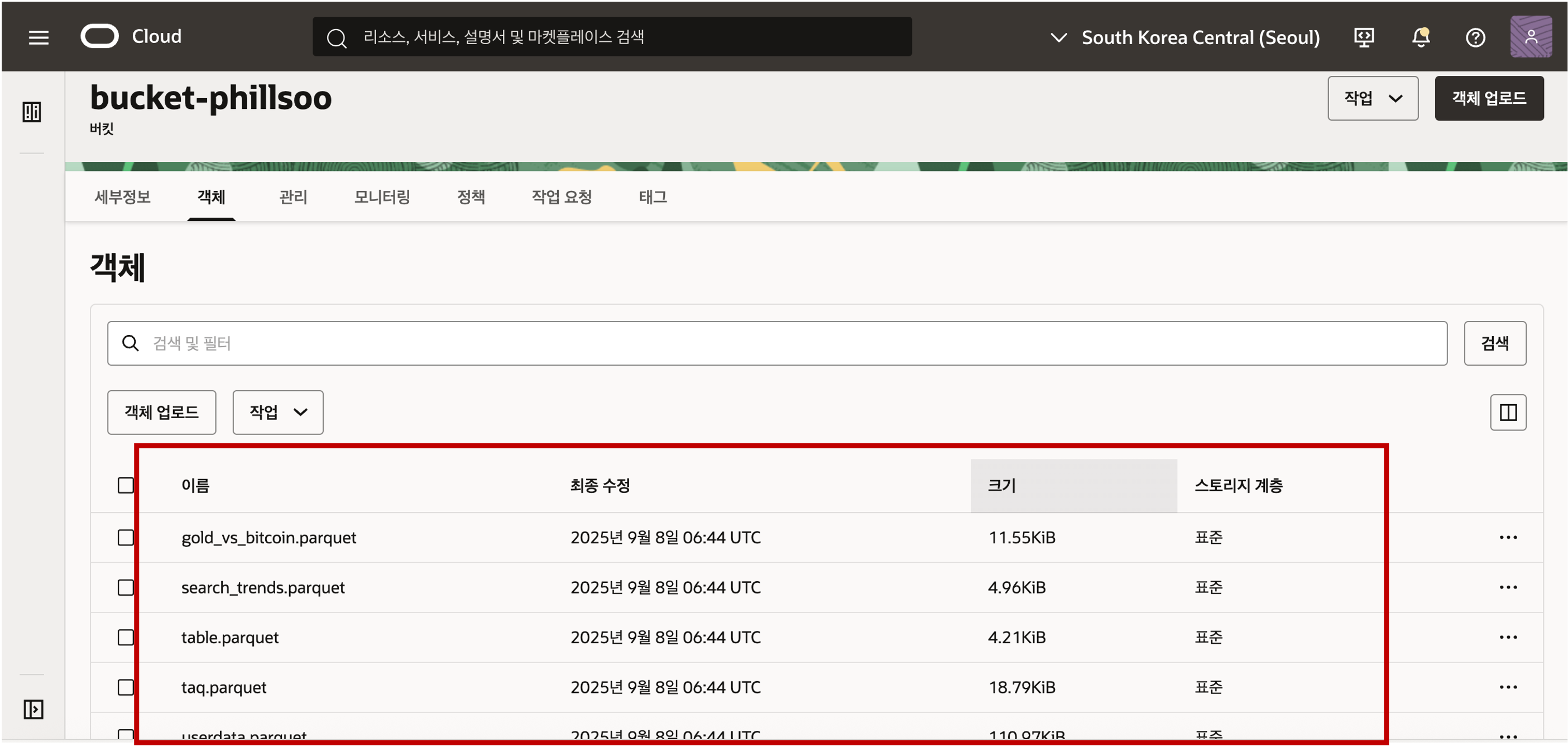
- 업로드된 Object Stroage 의 데이터를 접근하기 위해서는 객체의 위치 정보인 URI 정보를 획득해야 합니다. URI 정보는 아래와 같은 샘플 형식으로 객체의 위치 정보가 저장되어 있습니다. 객체의 위치 정보는 아래 화면과 같이 객체 세부정보 보기 메뉴를 선택하여 확인할 수 있습니다.
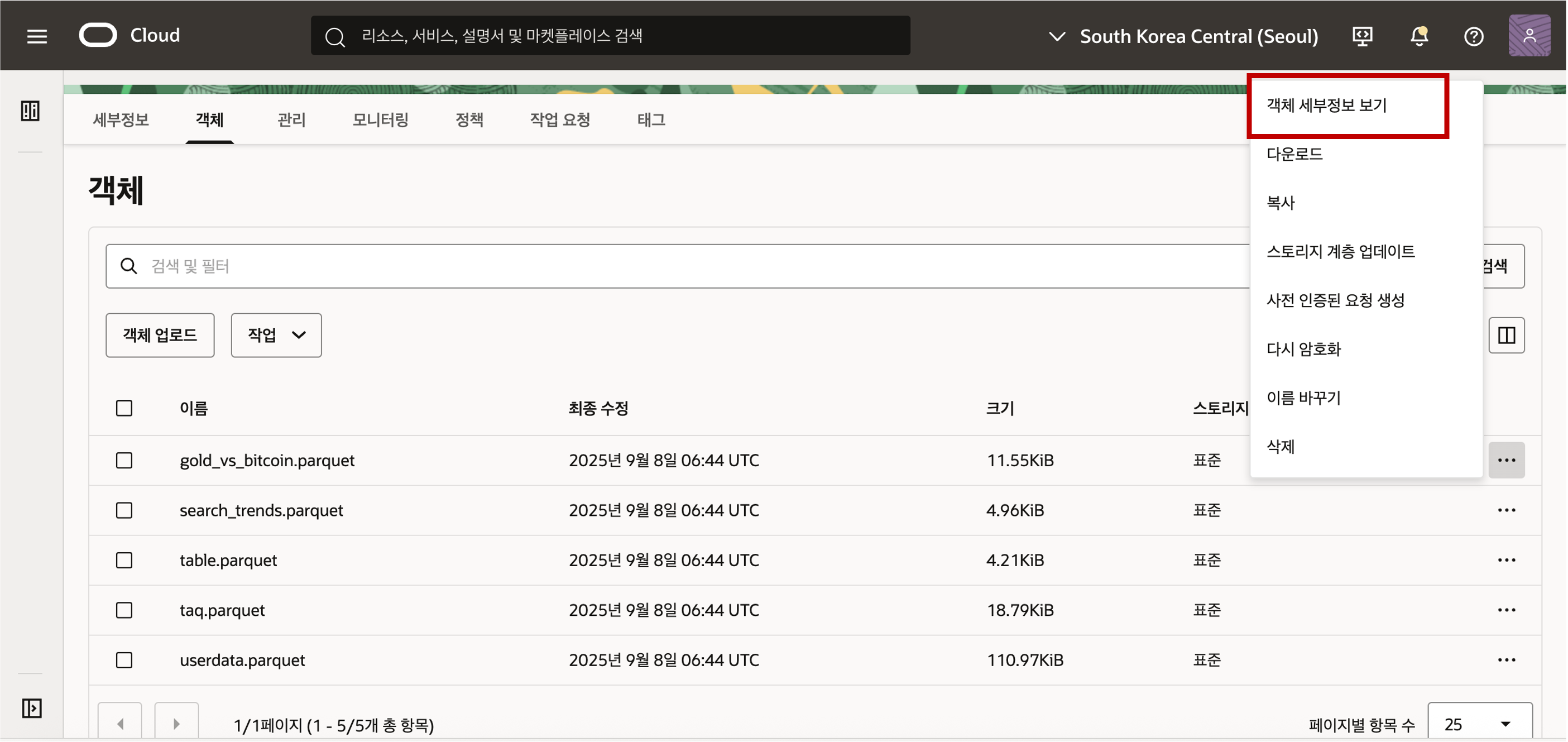
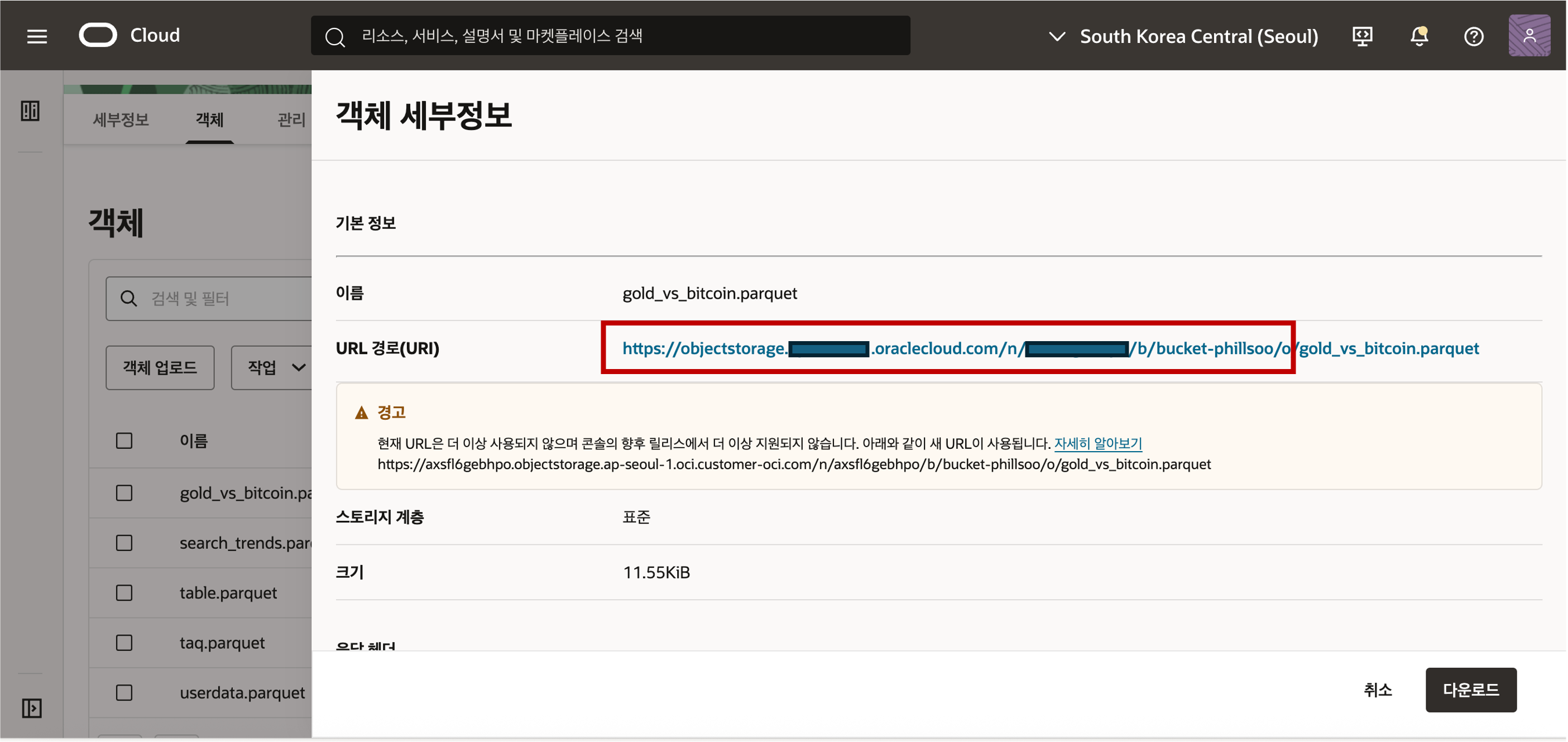 - 객체 정보의 샘플 형식은 아래와 같이 객체를 뜻하는 ‘/o’ 까지의 위치 정보를 복사해 클립보드나 메모장에 복사하여 둡니다. 끝에 "/" 가 안 붙도록 주의해야 합니다.
- 객체 정보의 샘플 형식은 아래와 같이 객체를 뜻하는 ‘/o’ 까지의 위치 정보를 복사해 클립보드나 메모장에 복사하여 둡니다. 끝에 "/" 가 안 붙도록 주의해야 합니다.https://objectstorage.<region>.oraclecloud.com/n/<namespace>/b/<bucket>/o Object Storage Auth Token 생성 - Oracle Cloud Infrastructure(OCI) Object Storage에서 데이터를 로드하려면 Object Storage 버킷에 데이터를 읽거나 업로드할 수 있는 적절한 권한을 가진 OCI 사용자가 필요합니다. 데이터베이스와 Object Storage 간의 통신은 기본 URI와 OCI 사용자의 인증 토큰을 사용합니다.
- Console Banner 에서 Profile 아이콘을 클릭하면 나오는 메뉴에서 “사용자 설정” 을 선택합니다.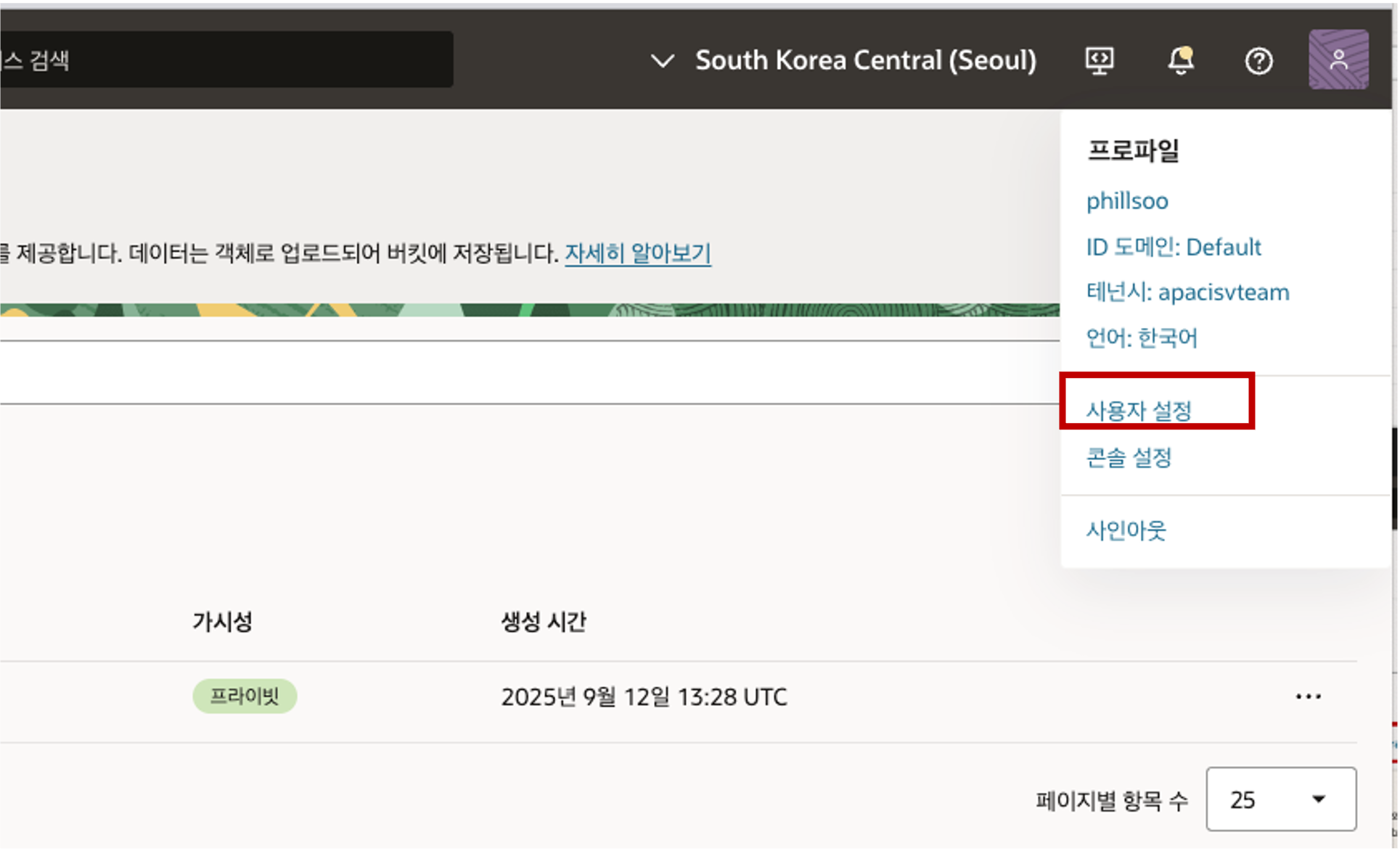
- 사용자 프로파일 페이지에서 “토큰 및 키” 탭을 클릭합니다.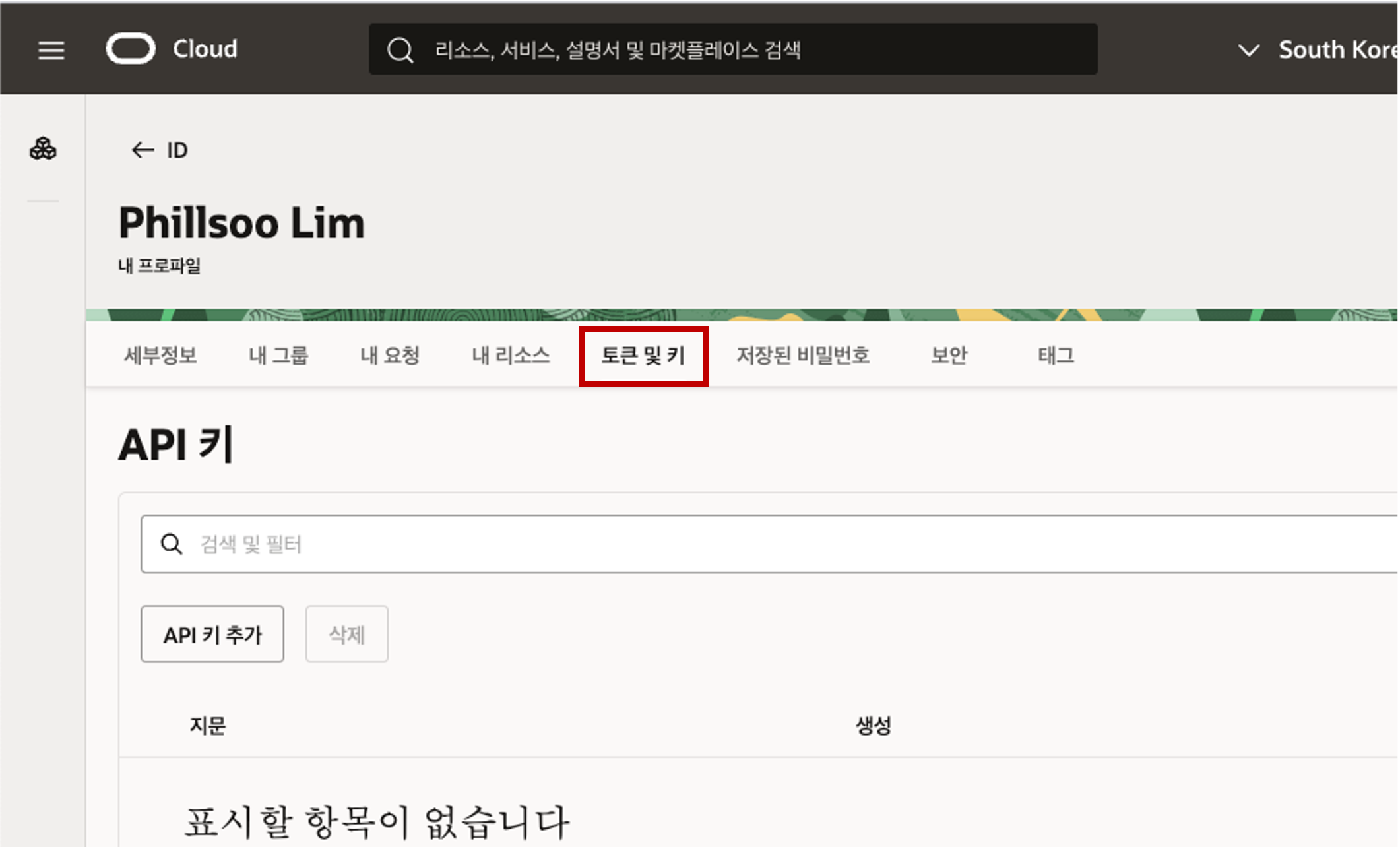 - 페이지를 아래로 스크롤하여 “인증 토큰” 섹션으로 이동한 다음 토큰 생성 버튼을 클릭합니다.
- 페이지를 아래로 스크롤하여 “인증 토큰” 섹션으로 이동한 다음 토큰 생성 버튼을 클릭합니다. 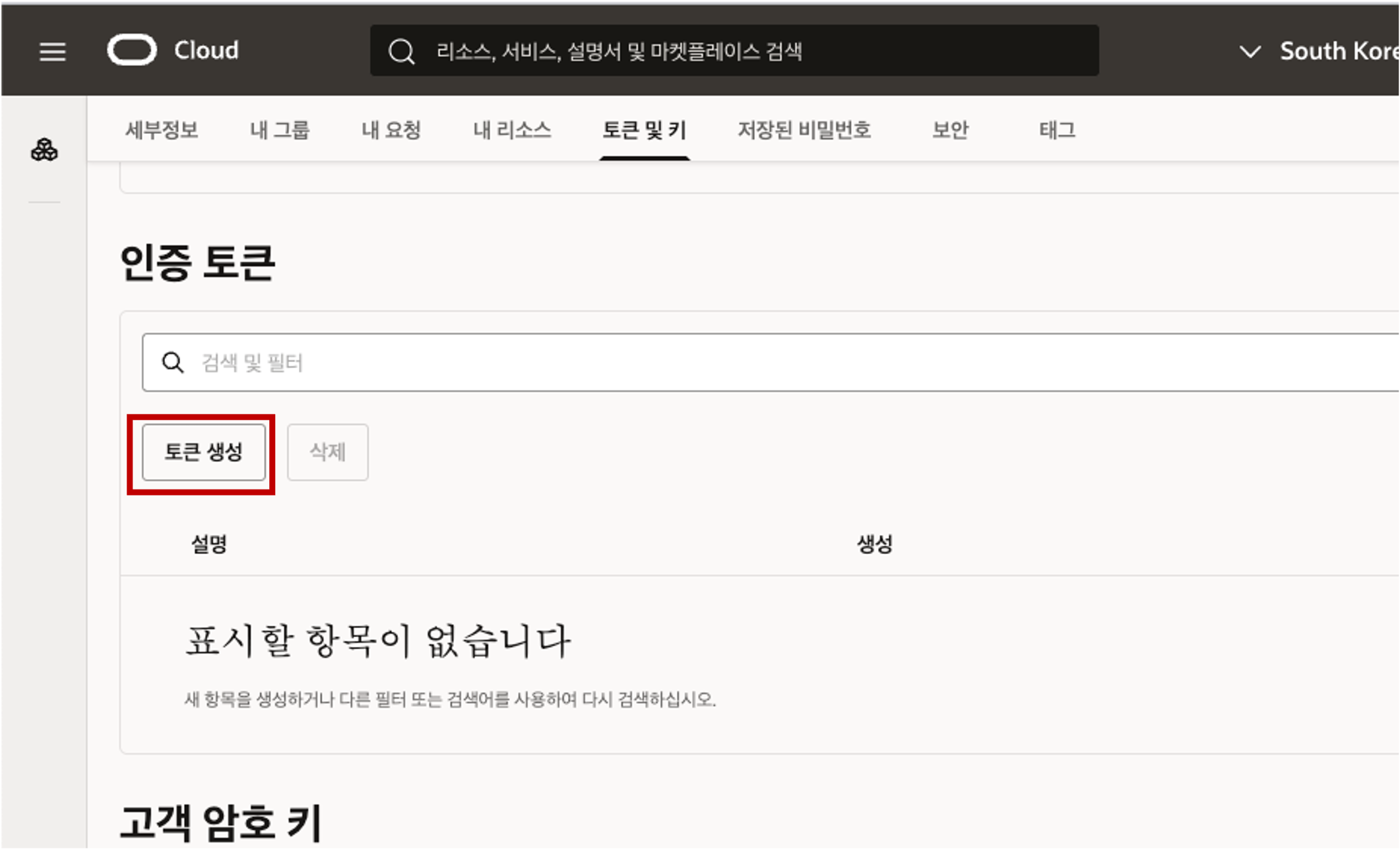 - 토큰 생성 패널에서 토큰에 대한 설명을 입력한 다음 토큰 생성을 클릭합니다.
- 토큰 생성 패널에서 토큰에 대한 설명을 입력한 다음 토큰 생성을 클릭합니다. 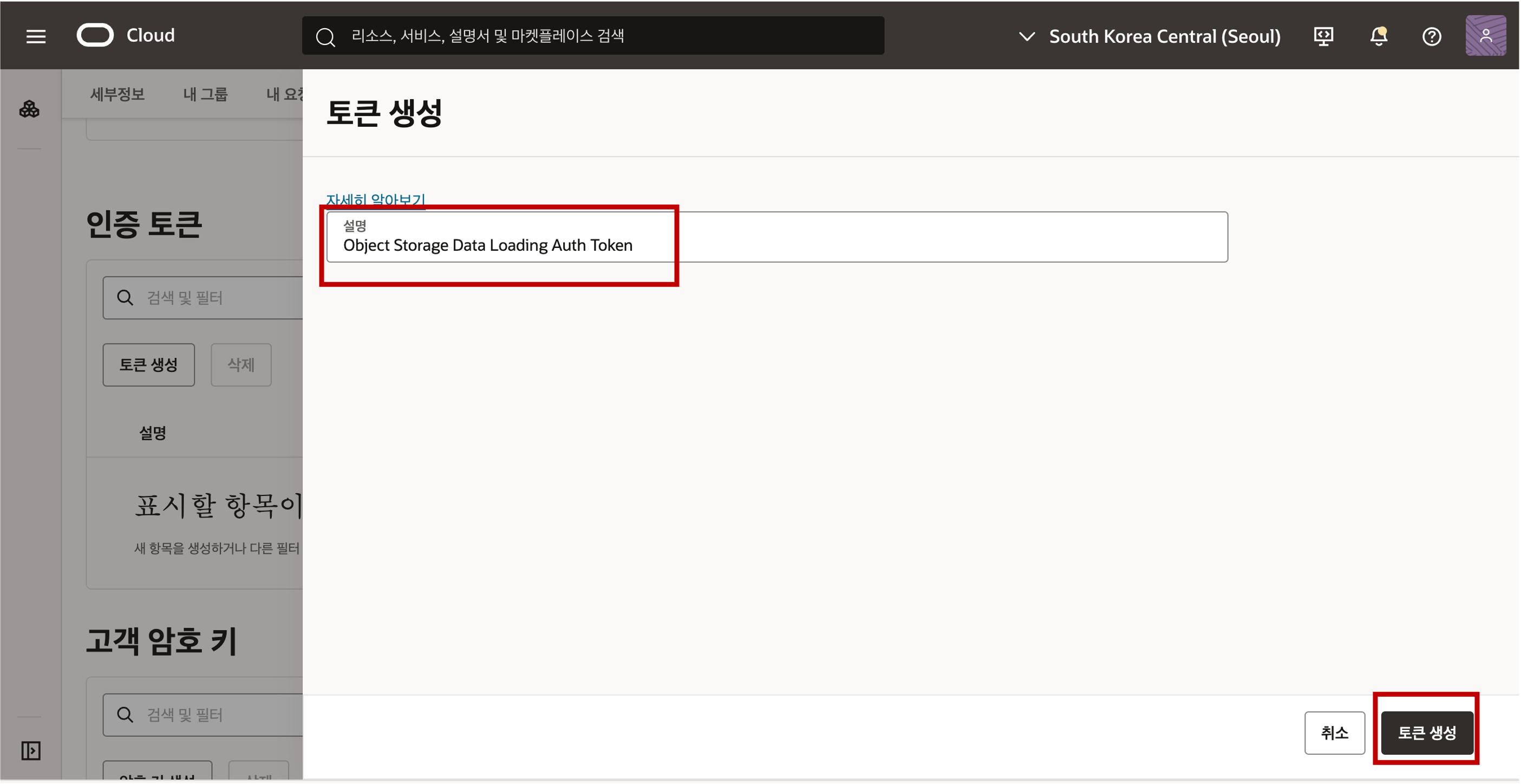 - 생성된 새 인증 토큰이 표시됩니다. 오른쪽 그림과 같이 아이콘을 클릭한 다음 팝업 메뉴에서 ‘복사’를 클릭하여 인증 토큰을 클립보드에 복사합니다. 클립보드의 내용을 원하는 텍스트 편집기나 메모장에 저장합니다. 이 인증 텍스트는 다음 작업에서 사용됩니다. 주의 : 인증토큰은 다시 표시가 되지 않아서 닫기 버튼을 클릭하기 전에 텍스트롤 복사하여 메모장에 잘 보관합니다.
- 생성된 새 인증 토큰이 표시됩니다. 오른쪽 그림과 같이 아이콘을 클릭한 다음 팝업 메뉴에서 ‘복사’를 클릭하여 인증 토큰을 클립보드에 복사합니다. 클립보드의 내용을 원하는 텍스트 편집기나 메모장에 저장합니다. 이 인증 텍스트는 다음 작업에서 사용됩니다. 주의 : 인증토큰은 다시 표시가 되지 않아서 닫기 버튼을 클릭하기 전에 텍스트롤 복사하여 메모장에 잘 보관합니다. 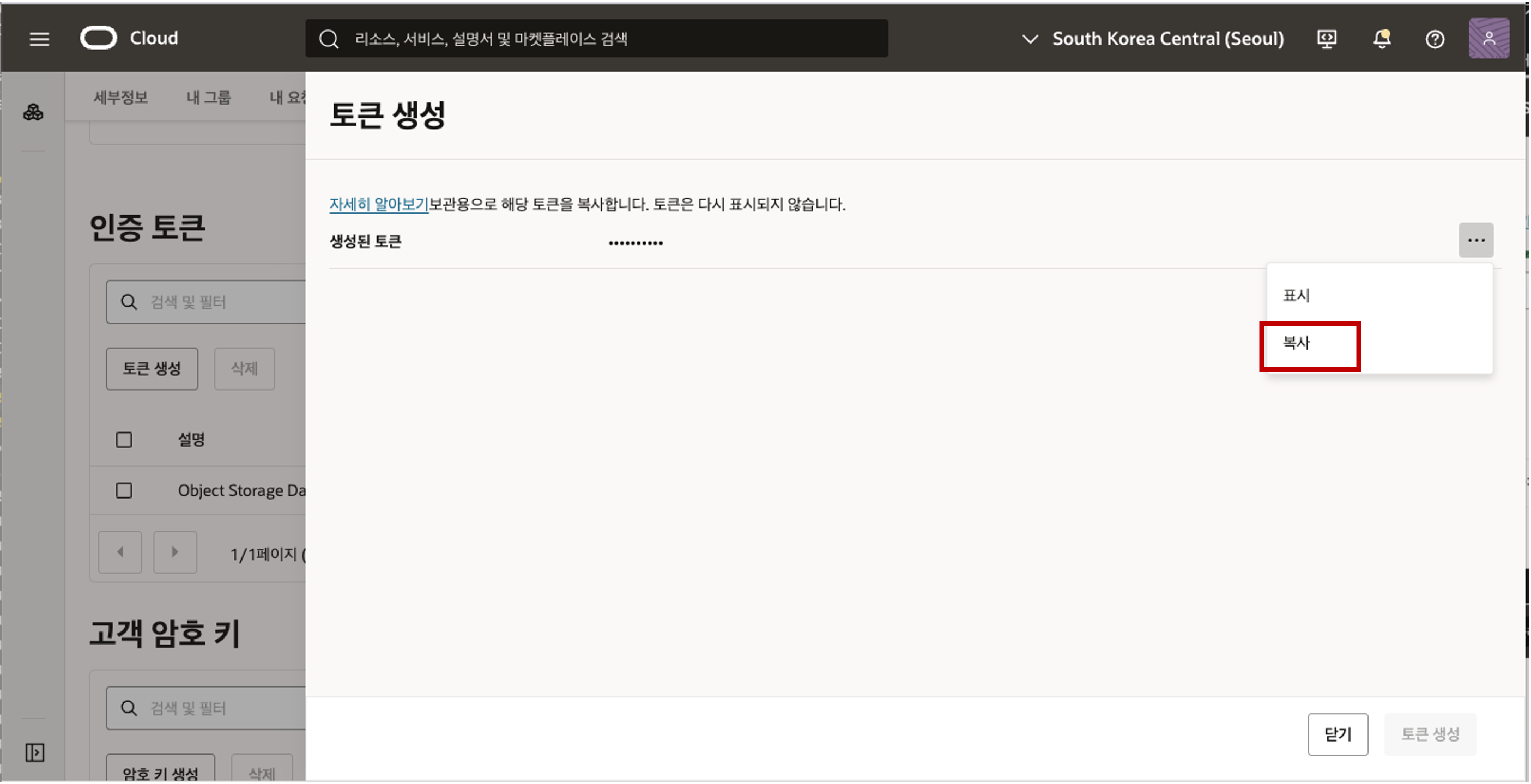 - 닫기 버튼을 클릭하면 생성된 인증 토큰을 확인할 수 있습니다.
- 닫기 버튼을 클릭하면 생성된 인증 토큰을 확인할 수 있습니다. 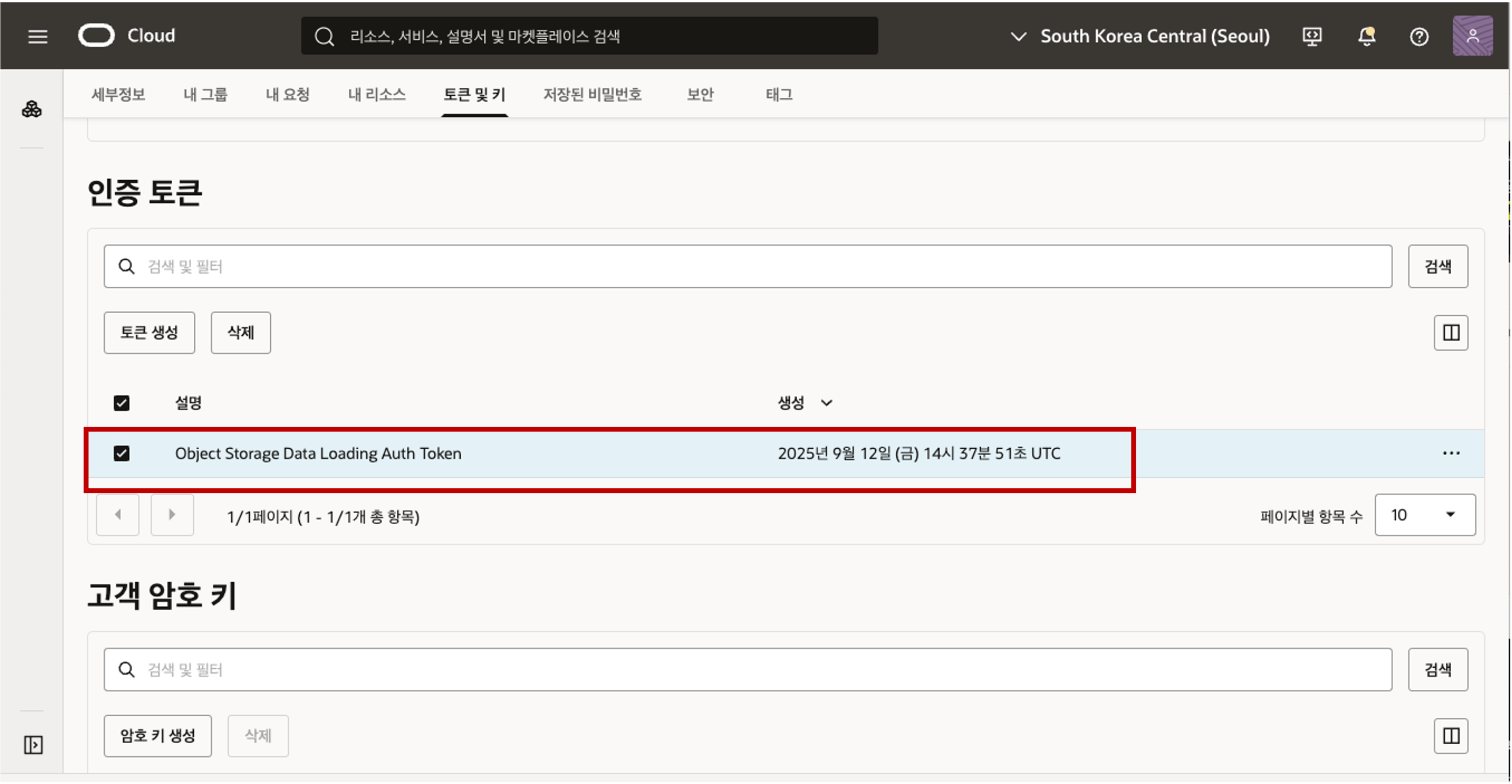
Data Load 도구를 사용하여 클라우드 위치 정의 및 자격 증명 생성
- 이전에 프로비저닝한 자율 데이터베이스 인스턴스의 자율 데이터베이스 세부 정보 페이지로 이동합니다. 데이터베이스 작업 드롭다운 목록을 클릭한 다음 데이터 로드를 선택합니다.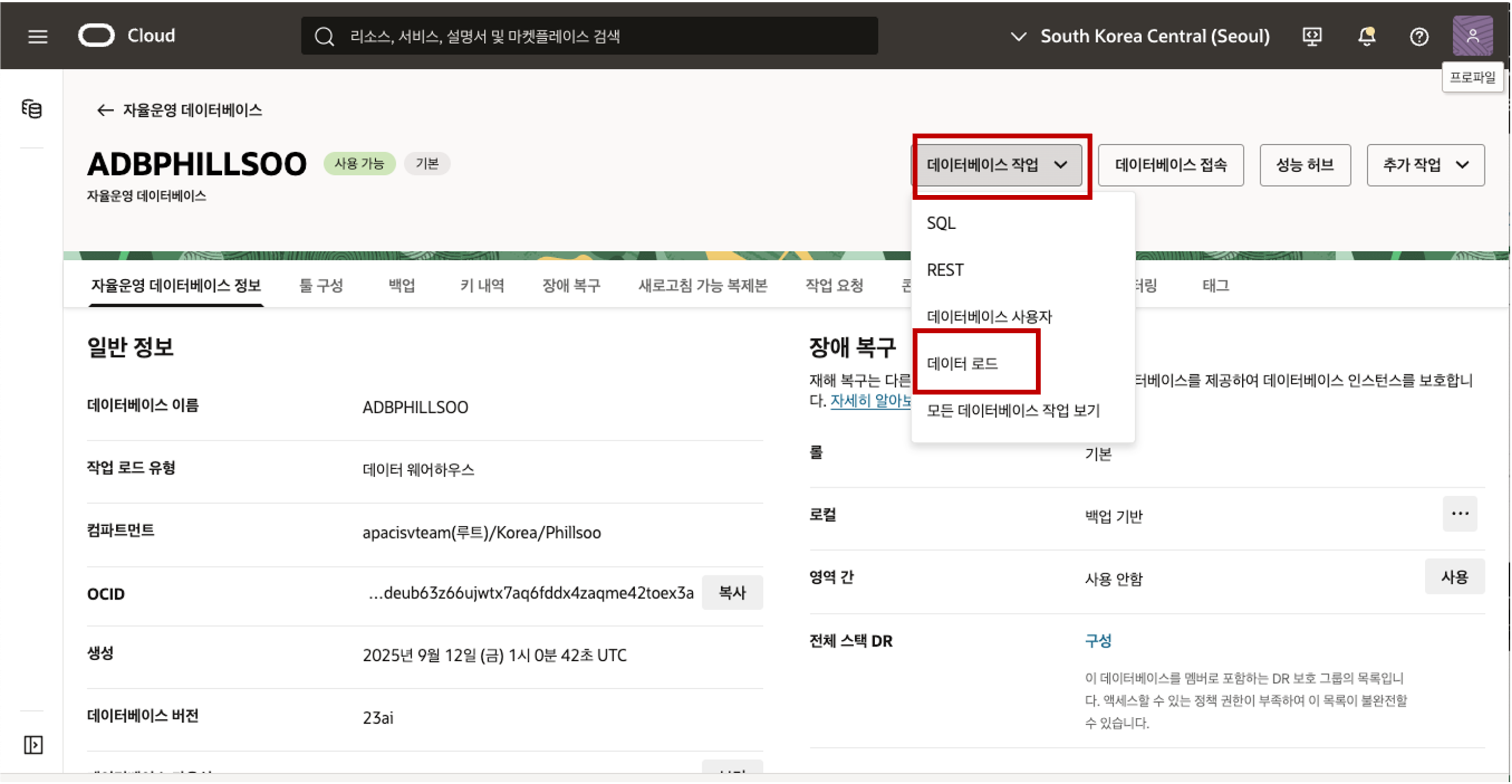 - 데이터 로드 홈페이지가 새 브라우저 탭에 표시됩니다. 로그인된 사용자가 새로이 추가한 사용자인 것을 확인합니다. ADMIN 사용자이면 새로이 추가한 사용자로 로그인 합니다. 사용자 인증 정보와 AI 프로필이 없으면 “사용자 인증 정보와 AI 프로필을 찾을 수 없습니다”라는 메시지가 표시됩니다. 이 메시지를 닫으려면 X 버튼을 클릭하시면 메시지가 사라집니다.
- 데이터 로드 홈페이지가 새 브라우저 탭에 표시됩니다. 로그인된 사용자가 새로이 추가한 사용자인 것을 확인합니다. ADMIN 사용자이면 새로이 추가한 사용자로 로그인 합니다. 사용자 인증 정보와 AI 프로필이 없으면 “사용자 인증 정보와 AI 프로필을 찾을 수 없습니다”라는 메시지가 표시됩니다. 이 메시지를 닫으려면 X 버튼을 클릭하시면 메시지가 사라집니다. 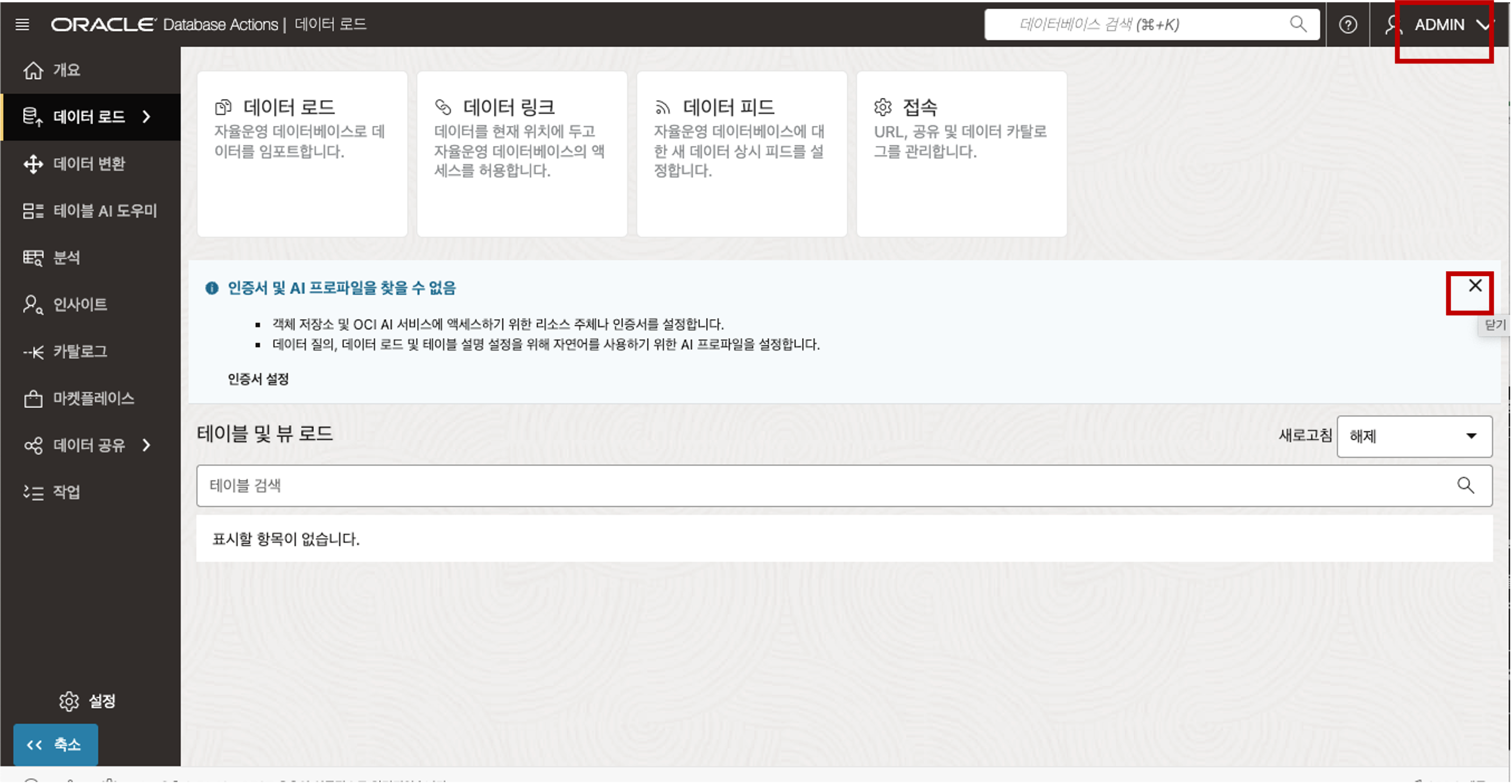
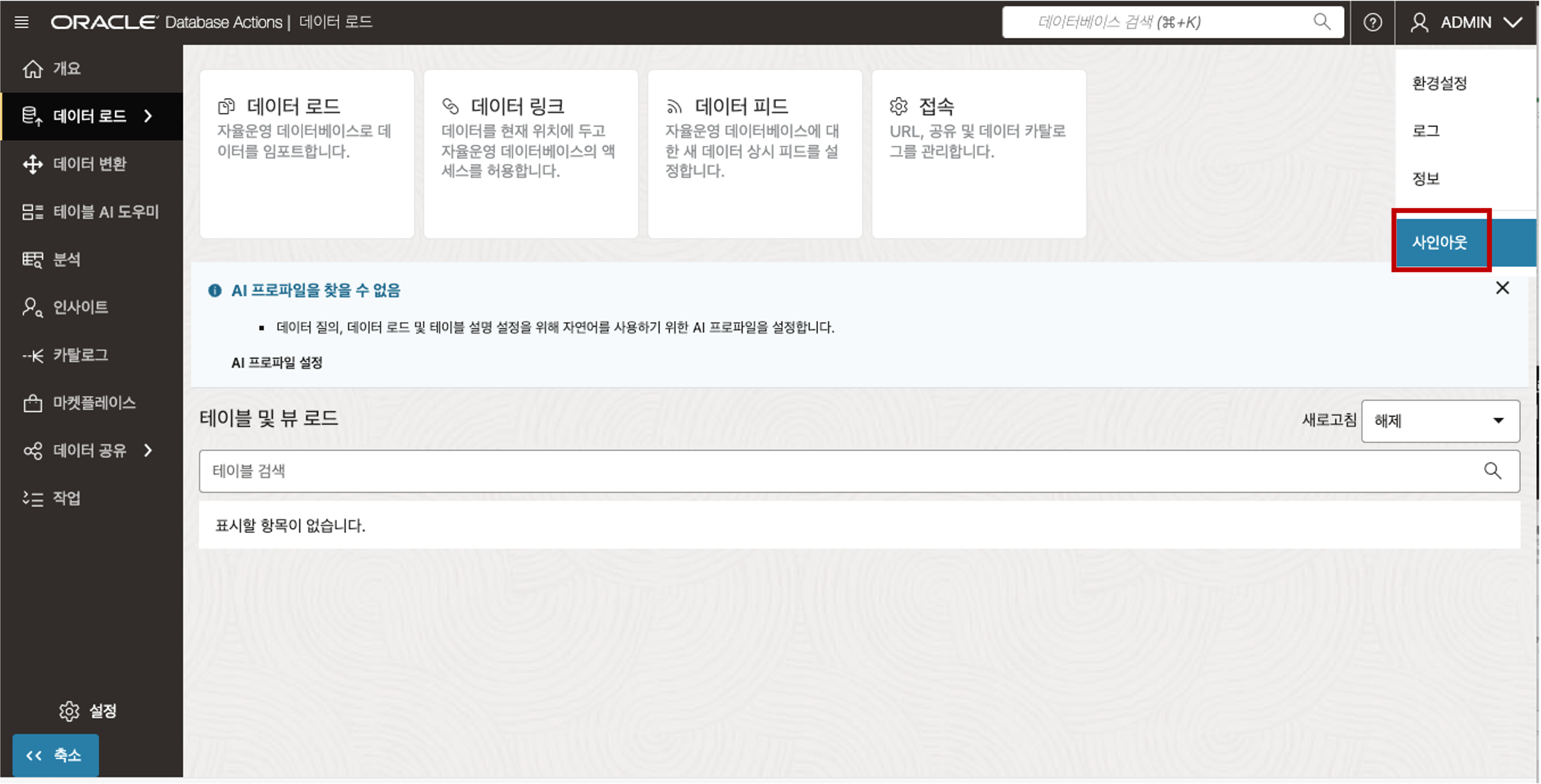
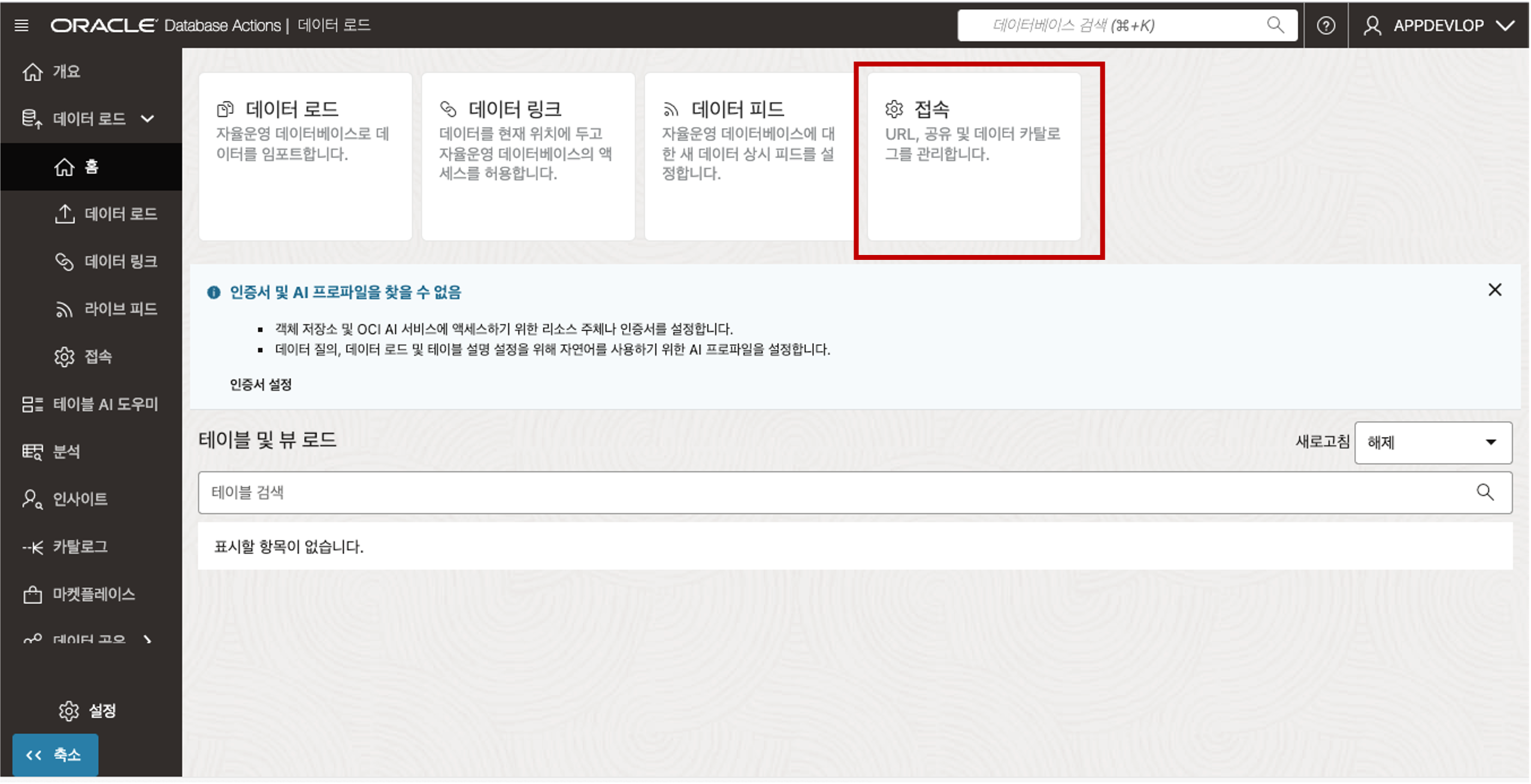
Data Load 메인 페이지에서 “접속” 카드 메뉴를 클릭합니다.
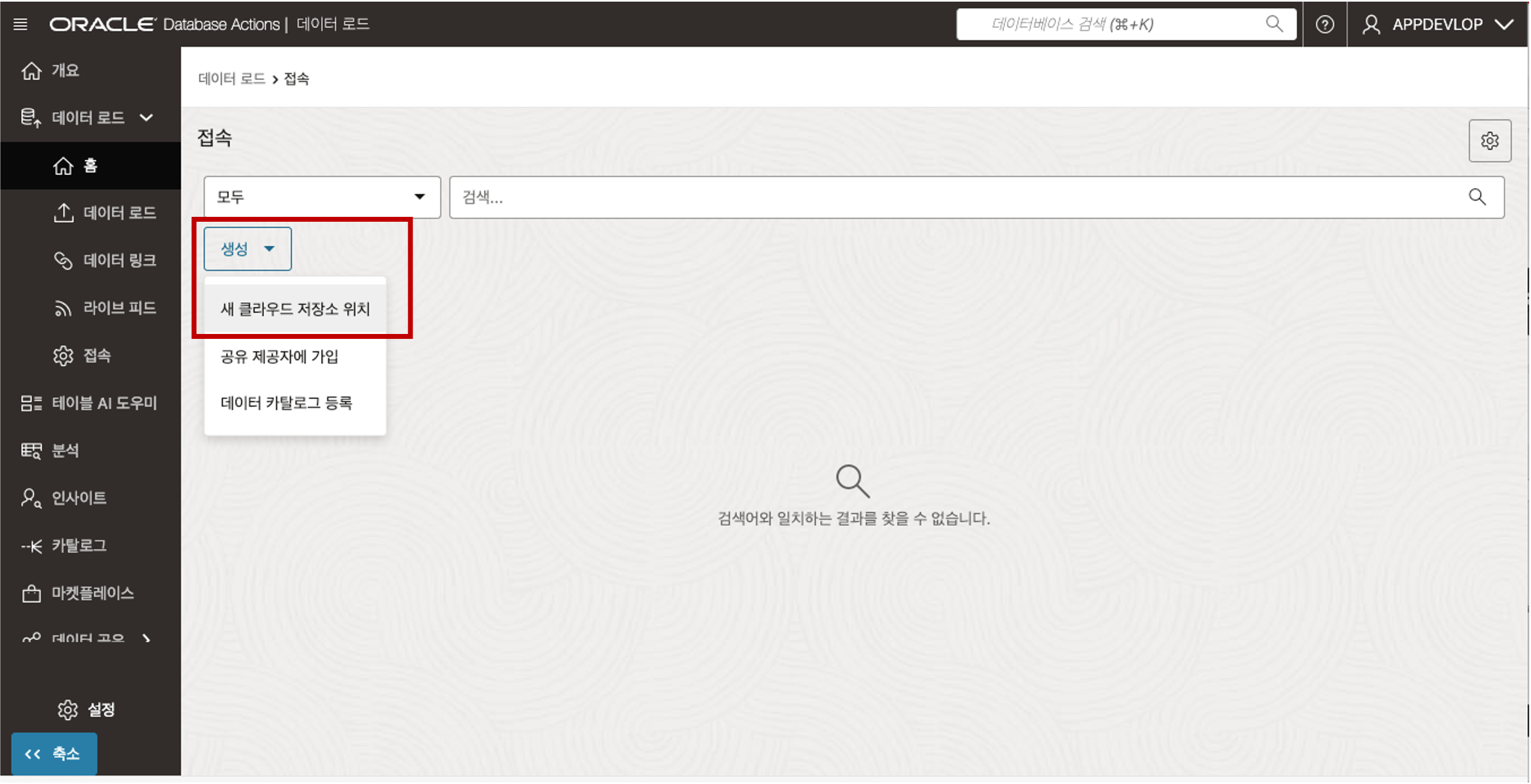
연결 페이지에서 생성 드롭다운 리스트를 클릭한 다음 “새 클라우드 저장소 위치”를 선택합니다.
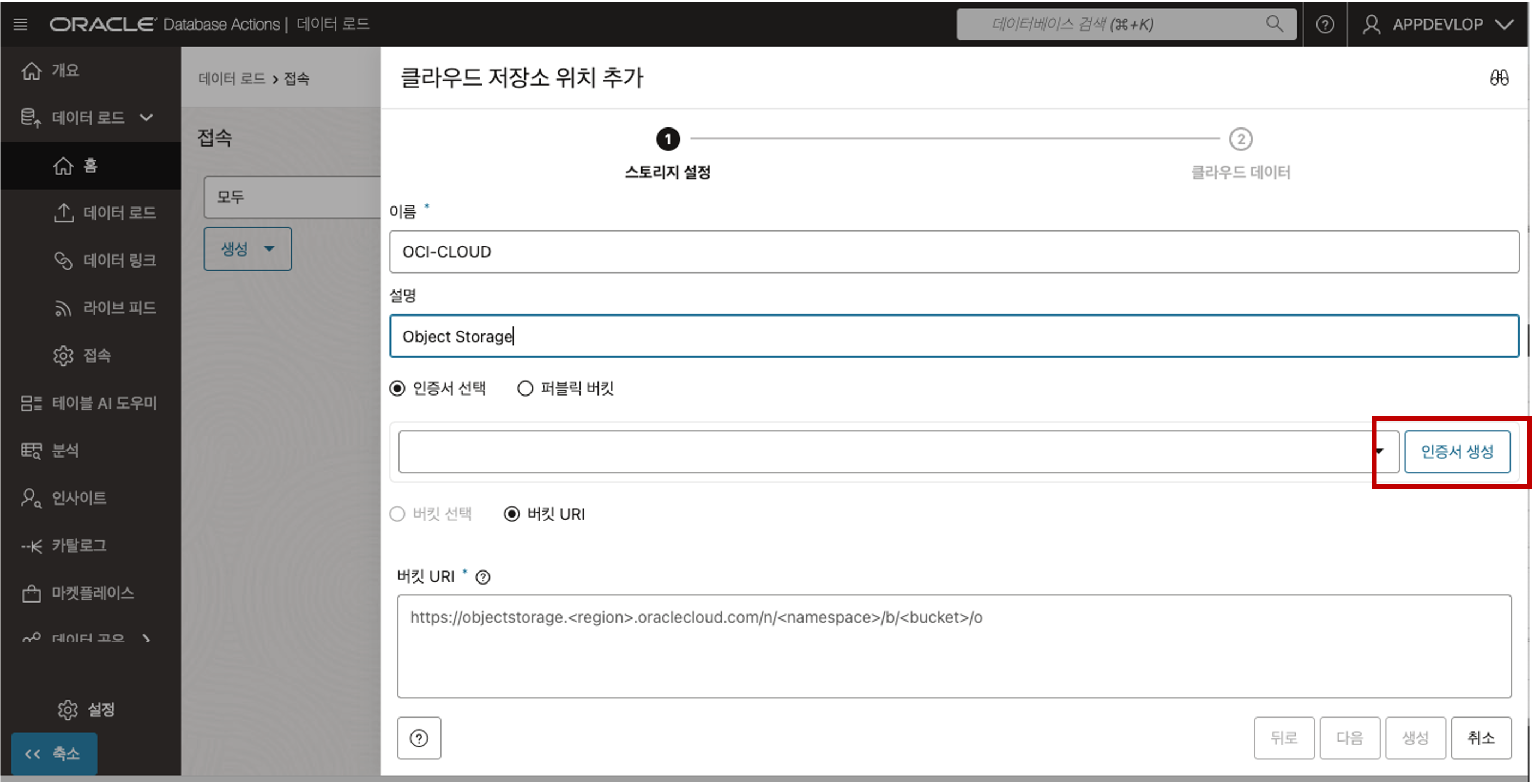
- 클라우드 저장소 위치 추가 패널에서 다음을 지정합니다.
- 이름: OCI-CLOUD 를 입력합니다.
- 설명: 선택적 설명을 입력합니다.
- 기본값인 “인증서 선택” 옵션을 선택합니다. 객체 저장소의 데이터에 액세스하려면 데이터베이스 사용자가 OCI 객체 저장소 계정과 인증서 사용하여 객체 저장소에 인증할 수 있도록 설정해야 합니다.
- “인증서 생성” 버튼을 클릭하여 아래와 같이 인증서를 생성합니다.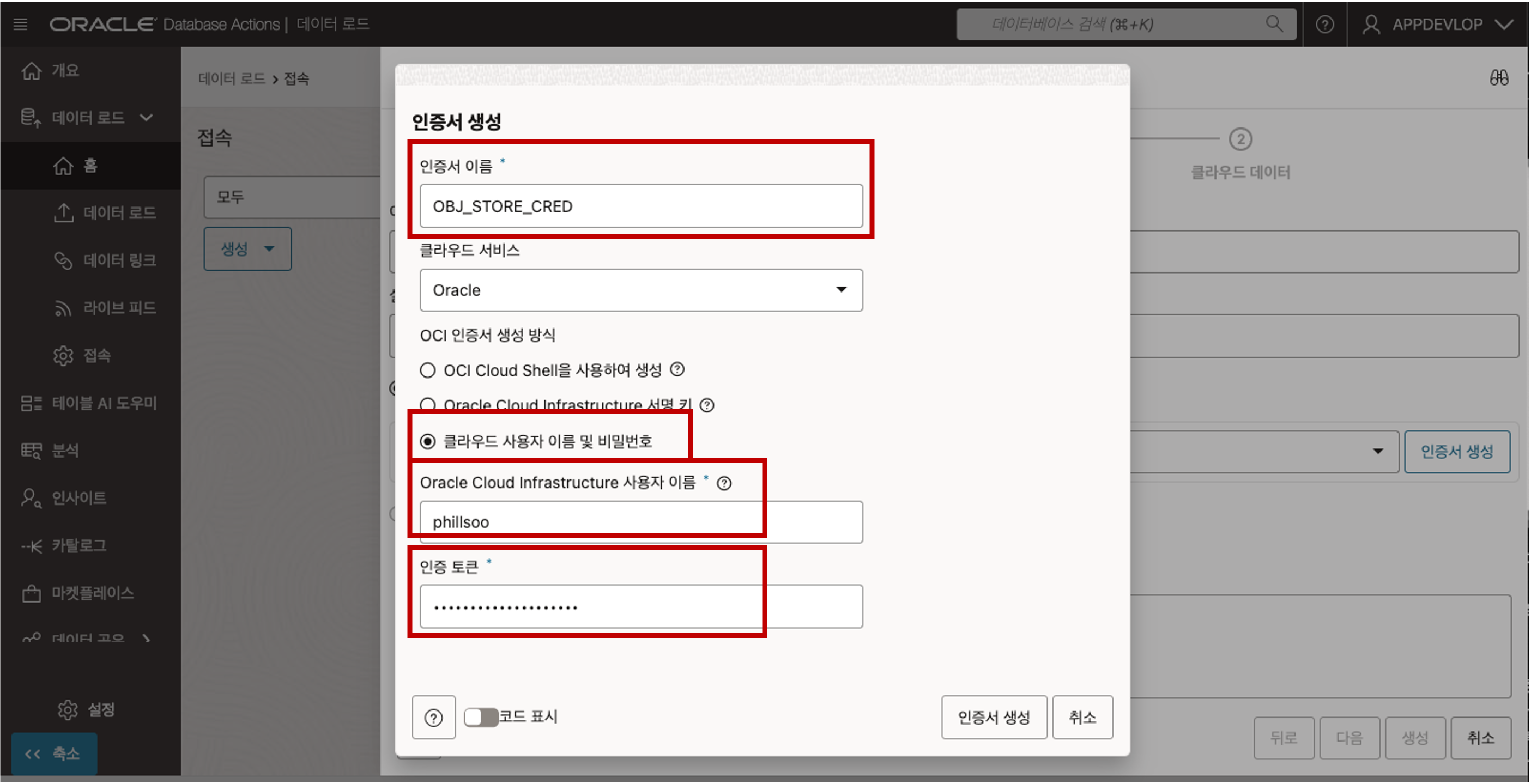
- 인증서 이름: OBJ_STORE_CRED를 입력합니다. 참고: 인증서 이름은 공백이나 하이픈을 허용하지 않는 Oracle 객체 명명 규칙을 따라야 합니다.
- 클라우드 서비스: Oracle Object Storage 버킷에서 데이터를 로드하므로 드롭다운 목록에서 Oracle을 선택합니다.
- OCI 인증서 생성 방법 : 클라우드 사용자 이름 및 비밀번호 옵션을 선택합니다.
- Oracle Cloud Infrastructure 사용자 이름: 6번 단계에서 확인한 Oracle Cloud Infrastructure 사용자 이름을 입력합니다. 사용자 이름은 E-mail Address 가 될 수도 있습니다.
- 인증 토큰: 6번 단계에서 생성하여 메모장에 보관한 인증 토큰을 복사하여 붙여 넣습니다.
- “인증서 생성” 버튼을 클릭하면 아래 화면과 같이 생성한 인증서가 자동으로 선택됩니다.
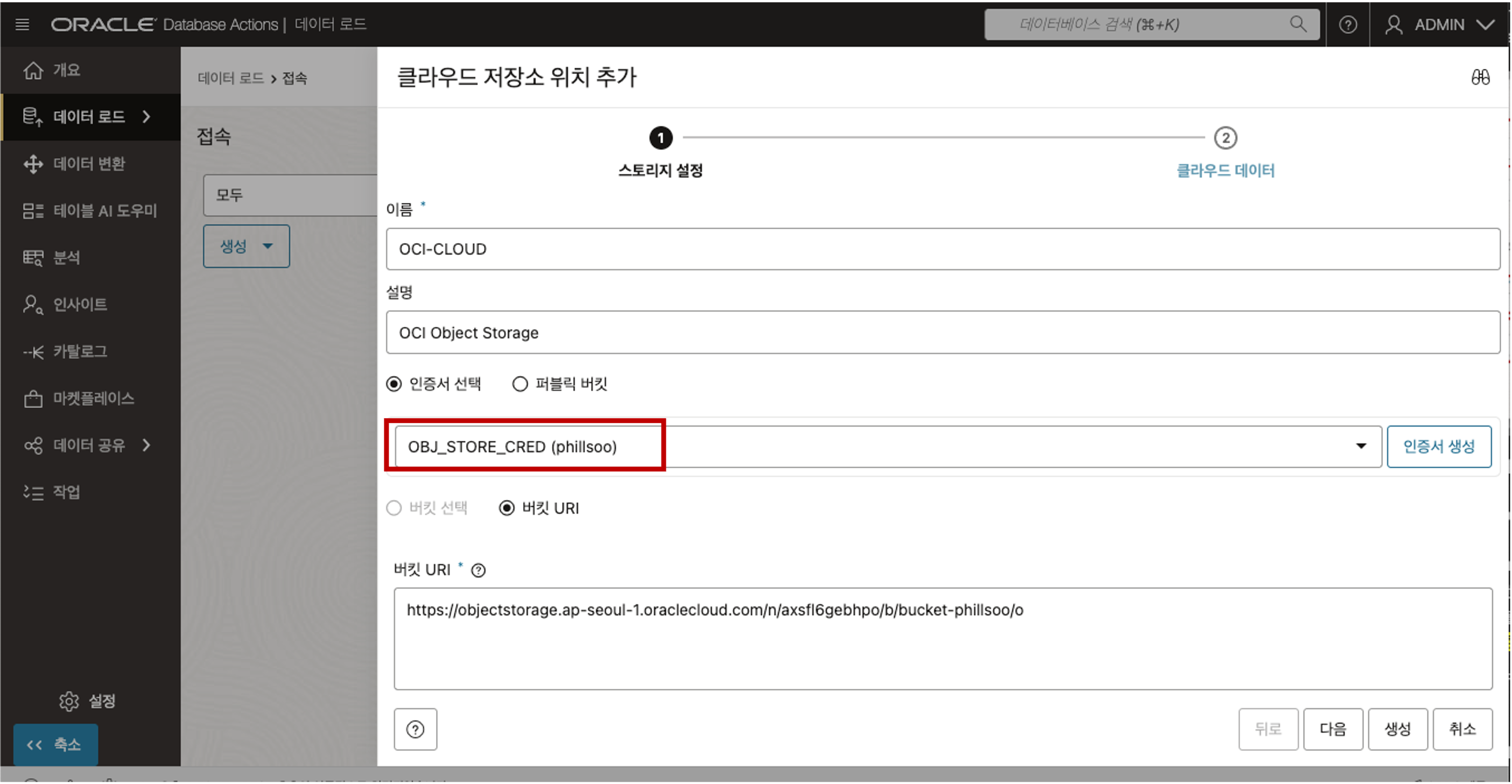
- 인증서 이름: OBJ_STORE_CRED를 입력합니다. 참고: 인증서 이름은 공백이나 하이픈을 허용하지 않는 Oracle 객체 명명 규칙을 따라야 합니다.
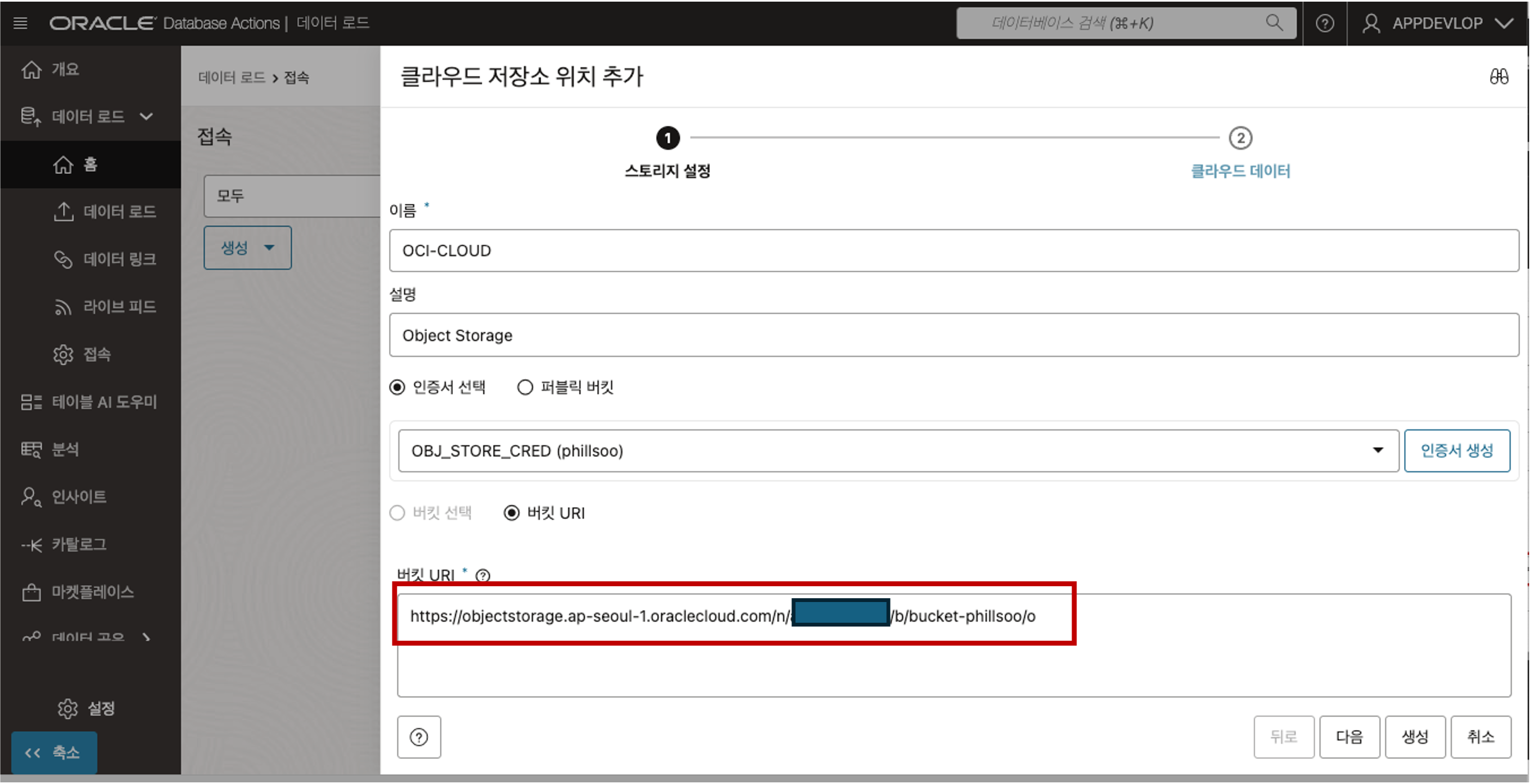
버킷 URI 입력 - 버킷 URI 는 아래의 절차를 통해 정보를 얻을 수 있습니다.
- Object Storage 의 URI 정보를 얻기 위해서는 저장된 파일의 객체세부정보 보기를 클릭하면 정보를 획득할 수 있습니다.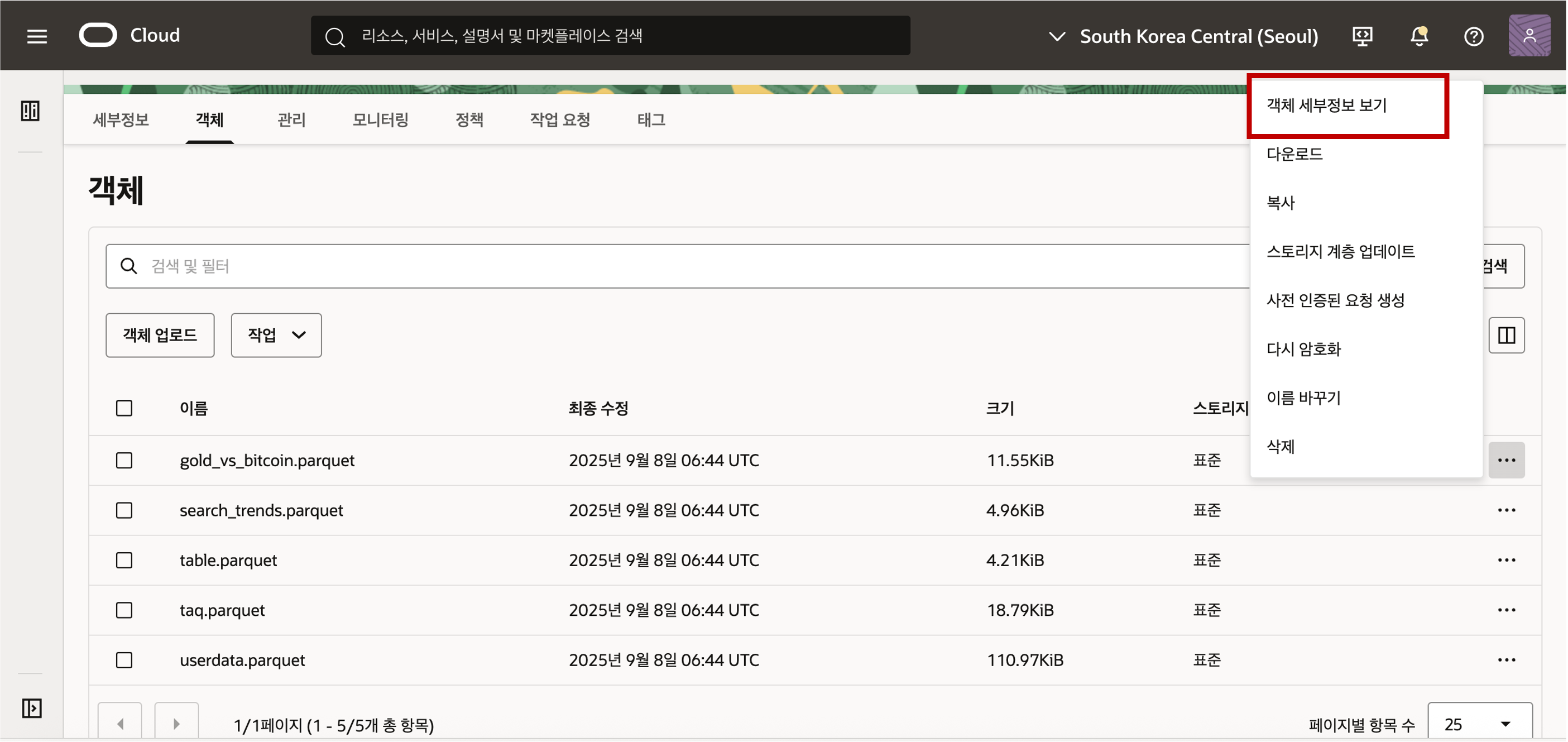
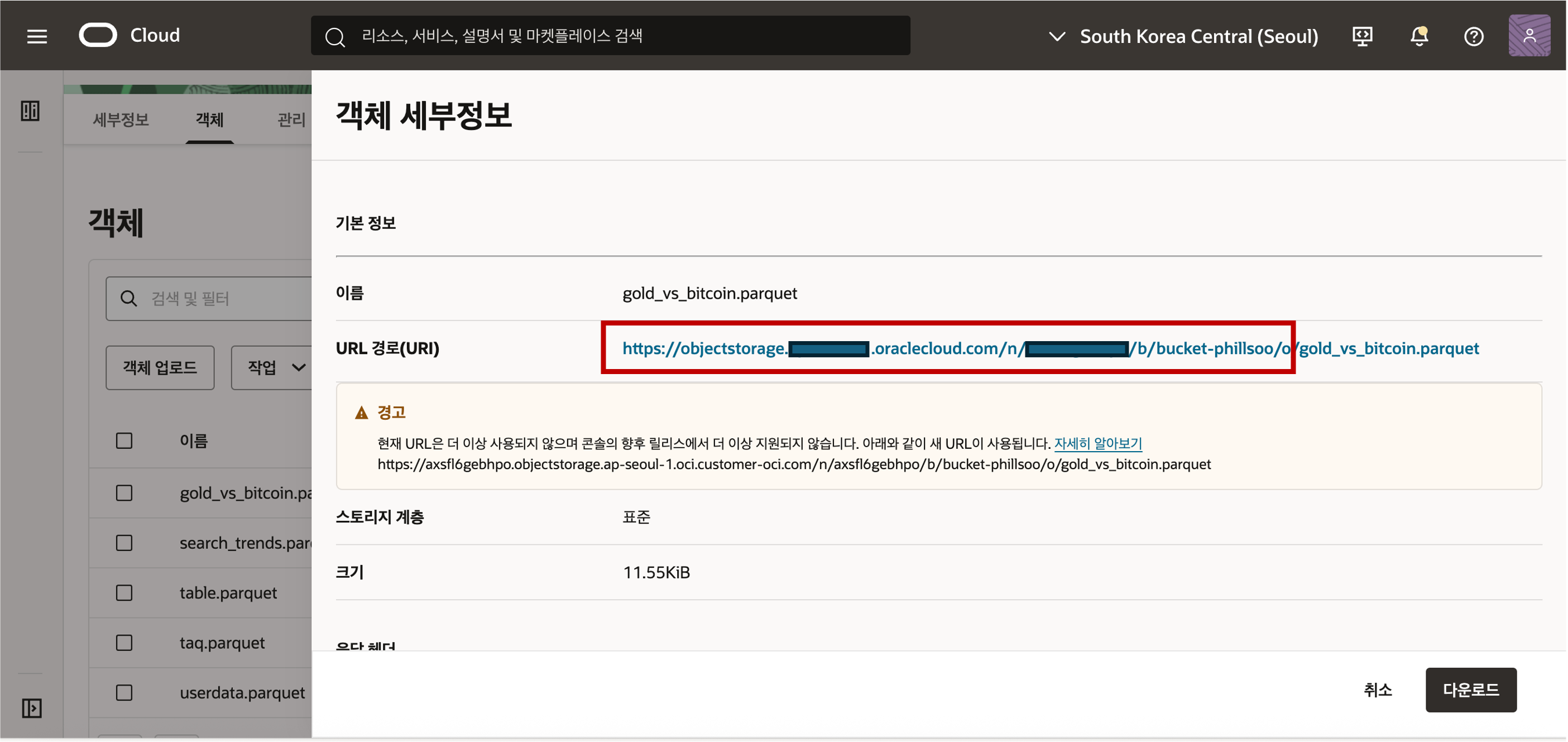
- 객체 정보의 샘플 형식은 아래와 같이 객체를 뜻하는 ‘/o’ 까지의 위치 정보를 복사해 클립보드나 메모장에 복사하여 둡니다. 끝에 "/" 가 붙지 않도록 주의합니다.https://objectstorage.<region>.oraclecloud.com/n/<namespace>/b/<bucket>/oURI 정보를 아래 그림과 같이 입력하고 다음 버튼을 클릭합니다.
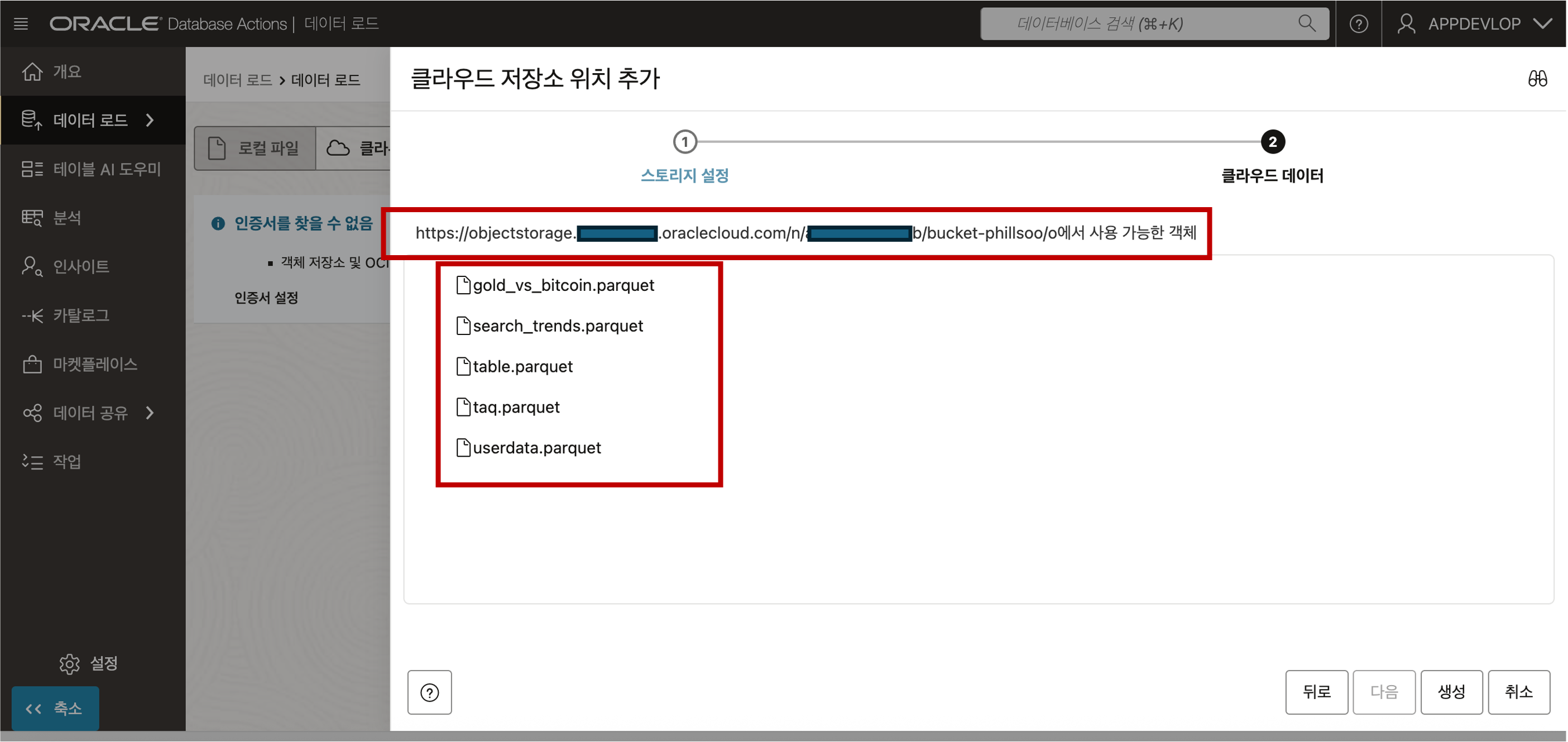
인증서 정보가 옳바르고 입력한 URI 정보가 올바르면 다음과 같이 Object Storage 에 저장된 파일의 목록이 나타납니다. - Object Storage 의 파일 목록 조회
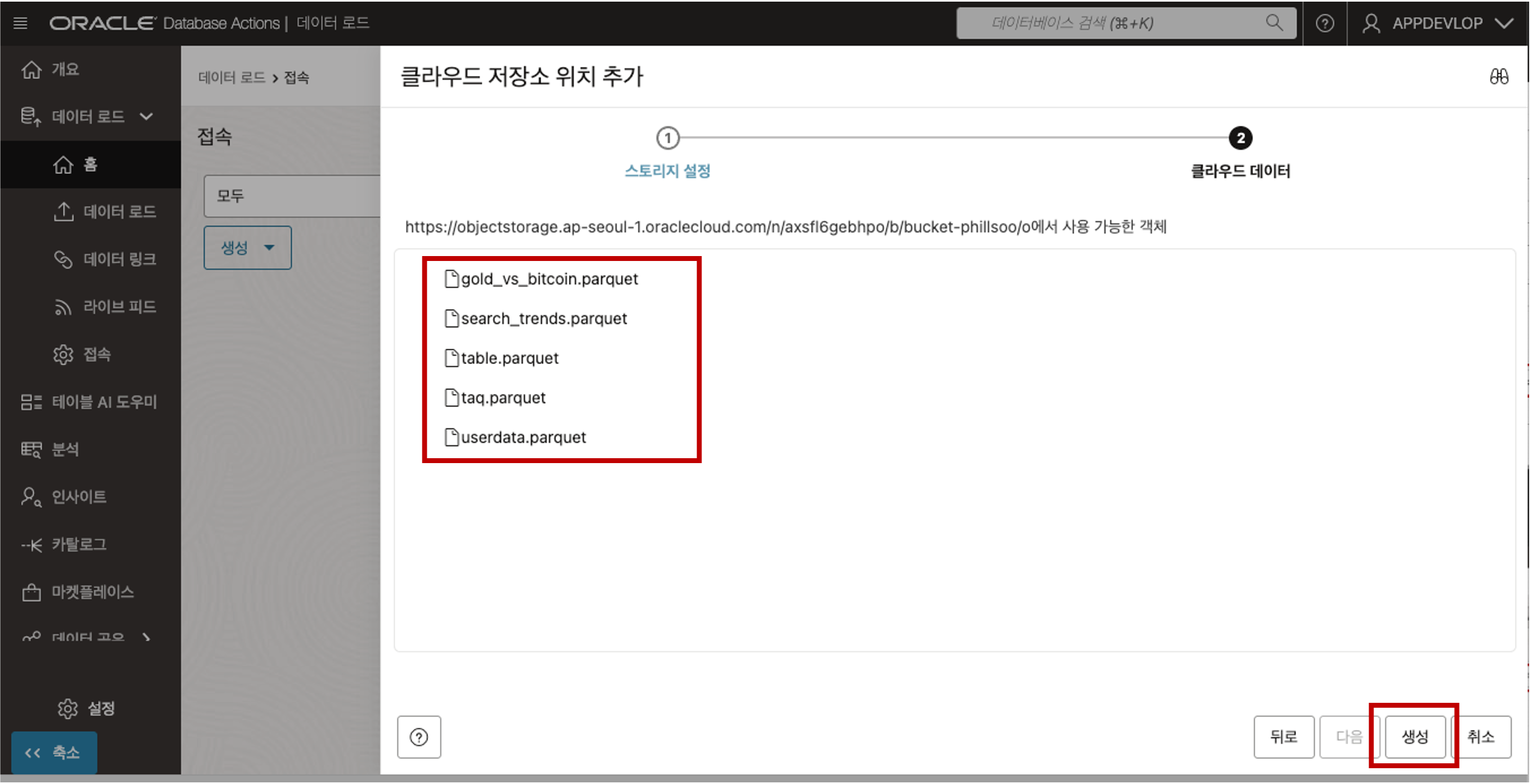
- 파일 목록이 나타나면 “생성” 버튼을 클릭하여 저장소 위치 추가 절차를 마무리 합니다.데이터 로더의 클라우드 저장소 메뉴로 접근하면 생성된 인증서 기반으로 연결된 Object Storage 의 파일 내용을 조회하실 수 있습니다.
- Object Storage 의 파일 목록 조회 - Object Storage 에 업로드했던 Parquet 파일들이 있는지 확인합니다.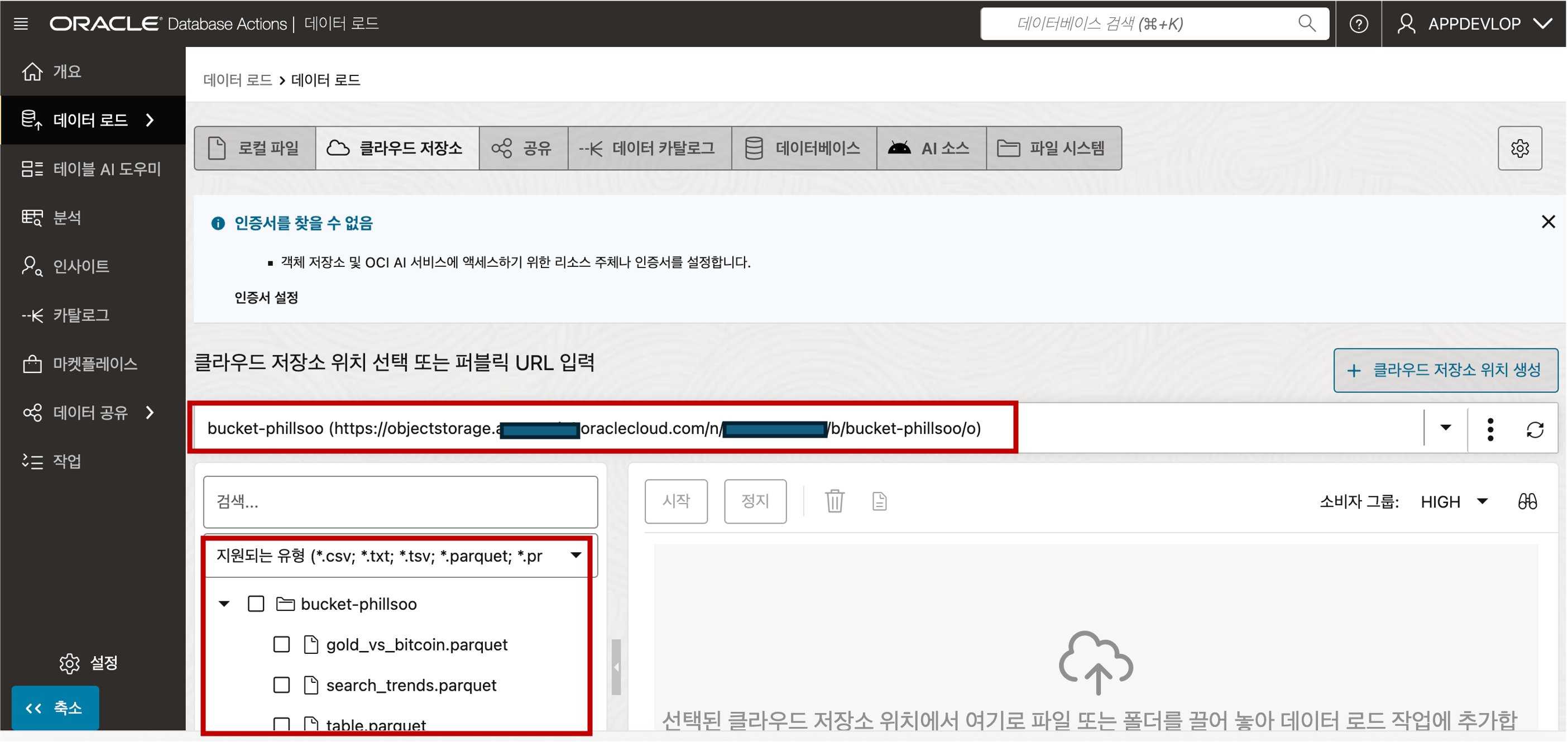
- 좌측의 파일 목록창에서 등록하고자하는 Parquet 파일을 선택하고 오른쪽 창에 Drag 하여 놓으면 Autonomous Database 로의 데이터 로딩이 준비됩니다. 상단의 “시작” 버튼을 클릭하면 데이터 로딩이 시작됩니다.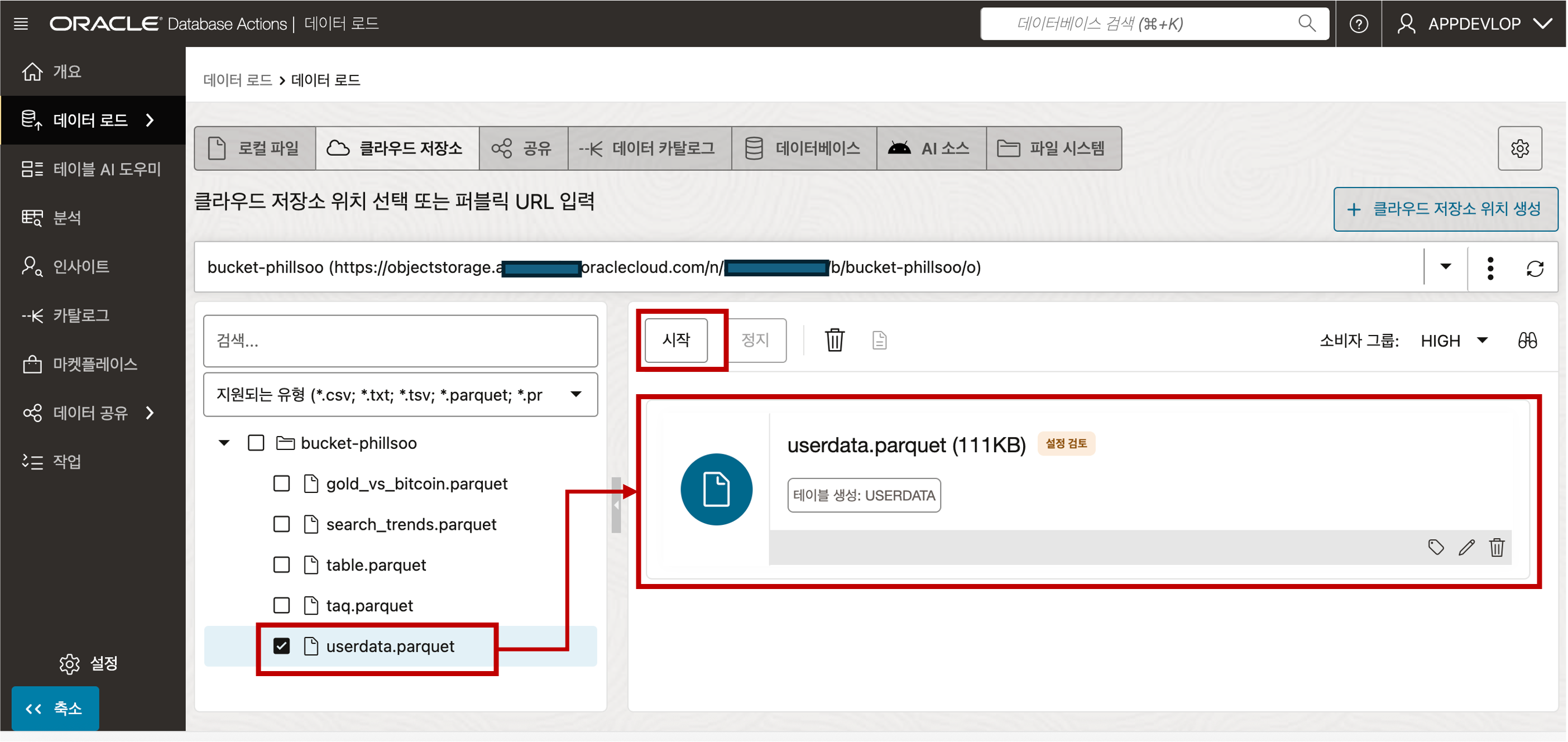
- 데이터 로딩이 완료되면 “보고서” 버튼을 클릭하여 데이터 로딩 결과를 확인할 수 있습니다.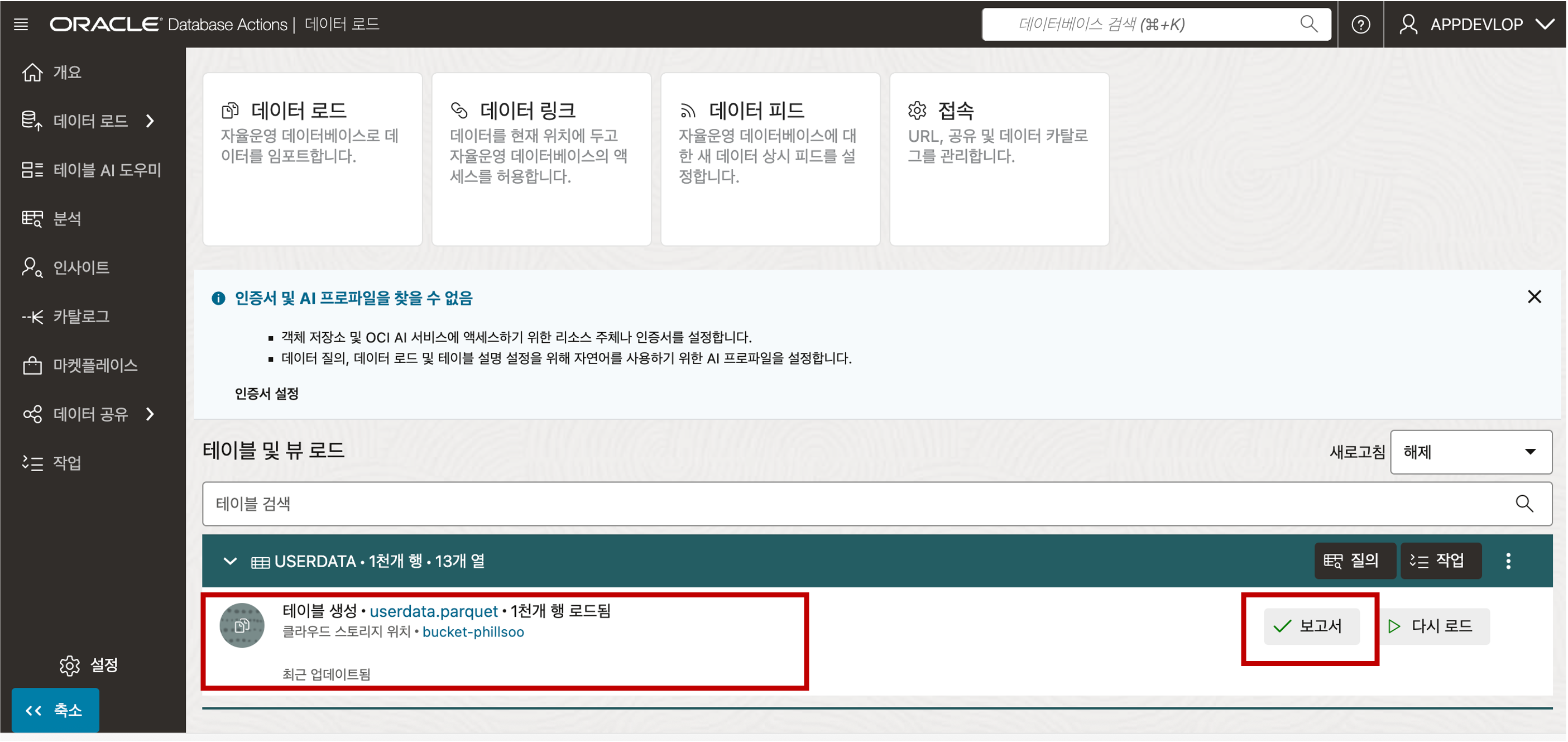
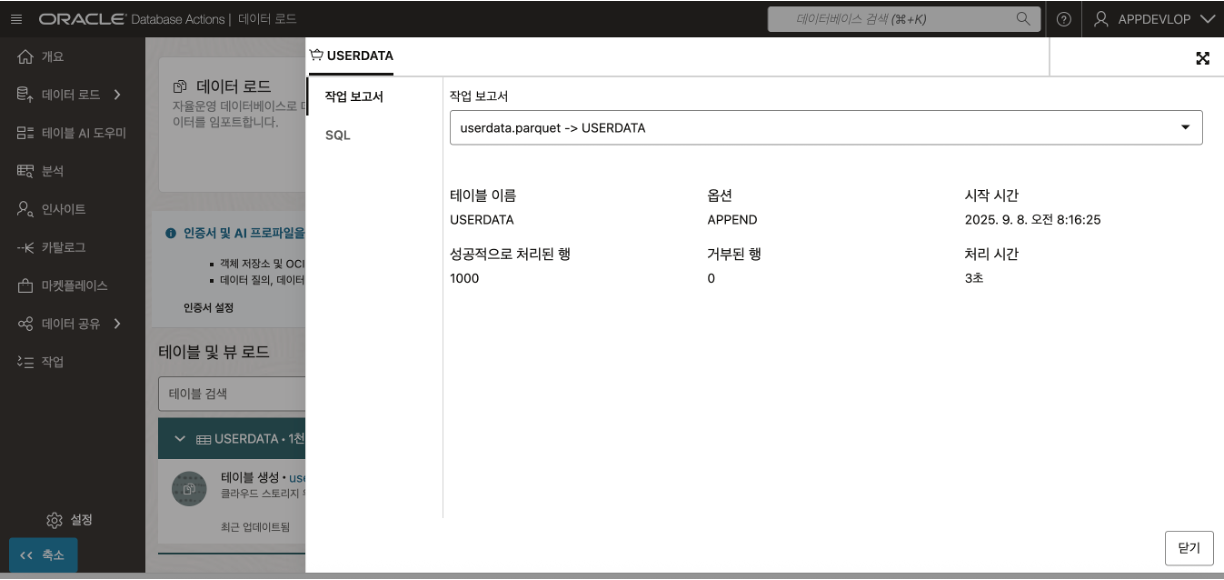
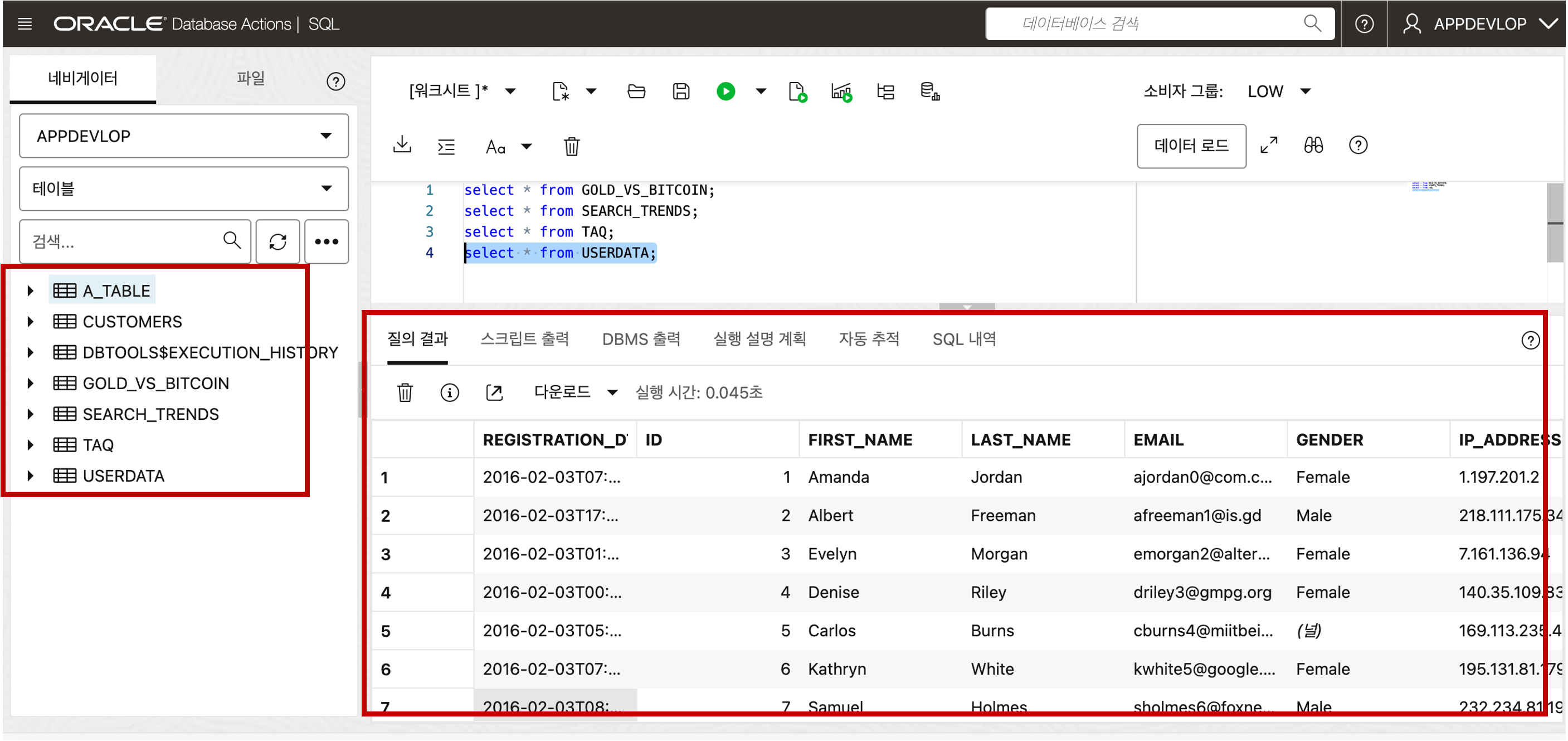
- Object Storage 로부터 로딩된 Parquet 데이터 결과를 확인하기 위해서 Database Actions 툴에서 제공하는 SQL Developer 를 통해 확인할 수 있습니다. SQL Developer 의 좌측 네비게이터 목록에 테이블들이 추가된 것을 확인할 수 있고, 우측의 쿼리 결과 데이터가 성공적으로 로드가 된 것을 확인할 수 있습니다.
(Optional) Autonomous Database 에 Data Loading (Public Object Storage 의 Parquet 파일) - 보안상 권고하지 않는 방법
Public Object Storage 에 대량으로 Parquet 파일 형태로 보관하고 있을 경우, Autonomous Database 의 Data Loader 툴을 통해 직접 Object Storage 에서 Autonomous Database 로 Data Load 를 수행할 수 있습니다.
Object Storage 에 있는 Parquet 파일을 Data Loading 하기 위해 Parquet 파일을 준비하여 Object Storage 로 업로드 합니다. 테스트를 위해 공개된 Parquet 파일을 다운로드하여 Object Storage 로 업로드 실습을 진행합니다. 먼저, 버킷 생성을 위해 Object Storage 의 버킷 메뉴로 이동합니다.
컴파트먼트를 확인한 후 버킷 생성 버튼을 클릭한 후 버킷 이름을 입력하고 스토리지 계층을 표준으로 선택한 후 버킷 생성 버튼을 클릭합니다.
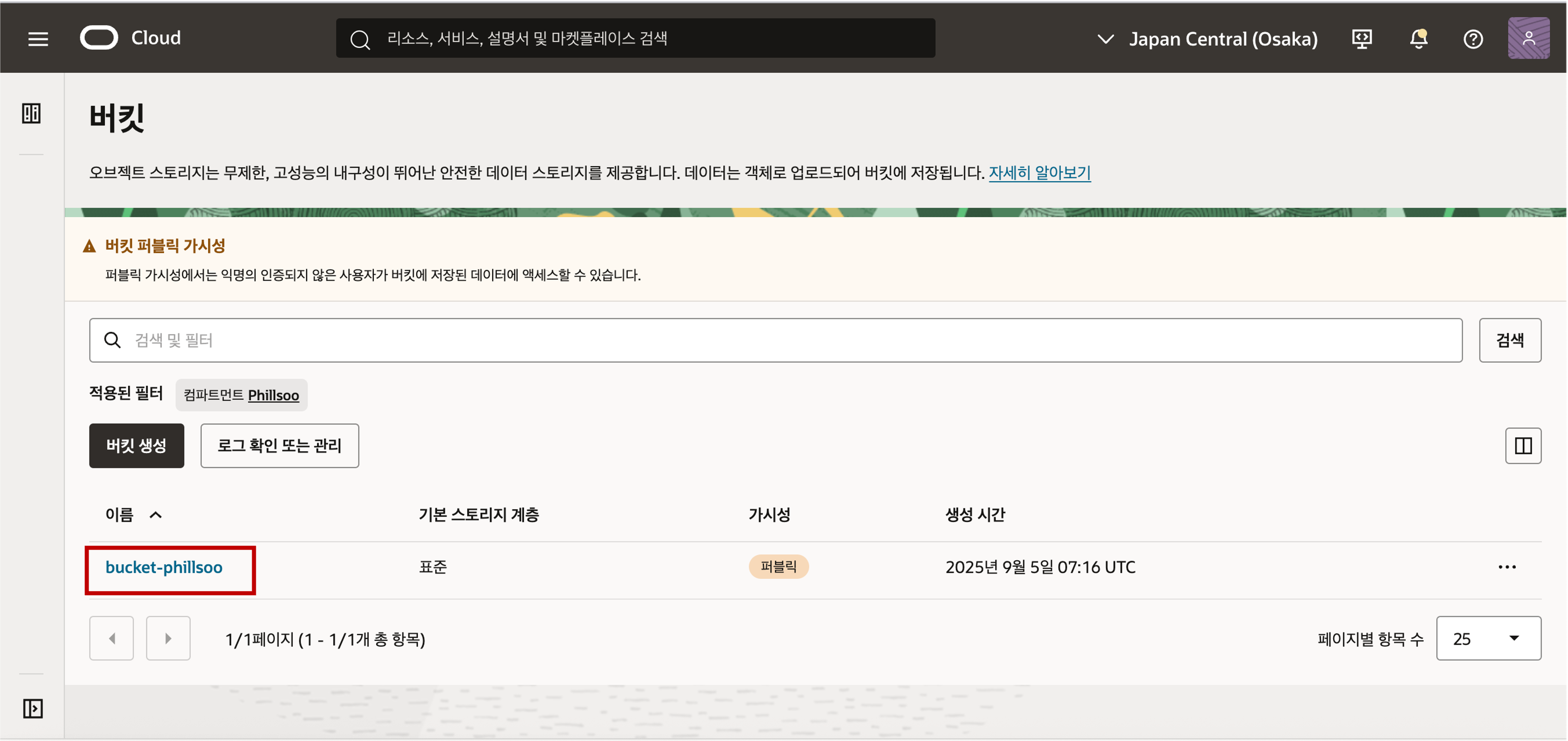
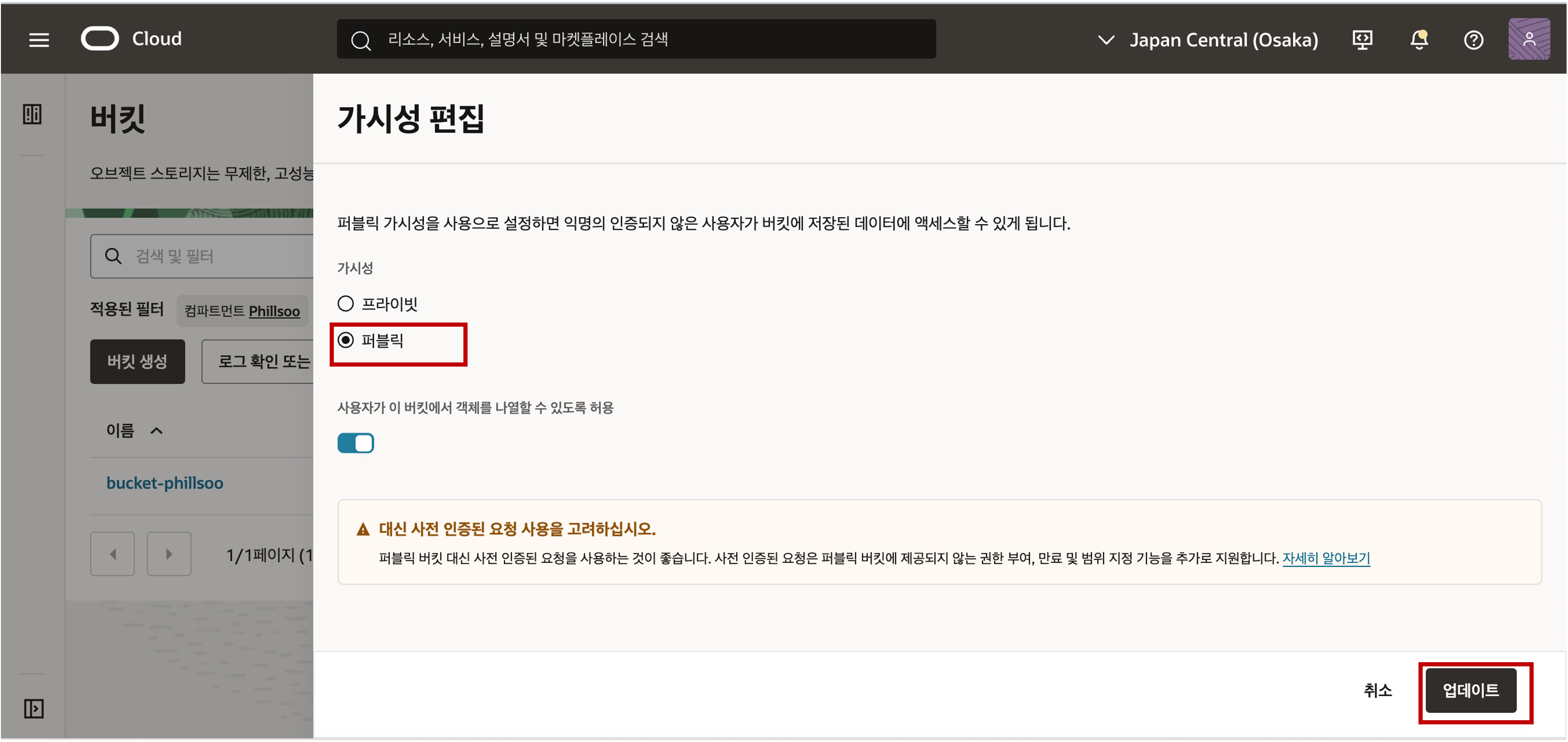
생성된 버킷의 가시성이 기본적으로 프라이빗으로 설정된 것을 확인할 수 있는데, 편의상 이번 실습에서는 간편하게 스토리지의 인증 정보를 설정하지 않는 방법으로 간편하게 데이터 로딩을 하기 위해 가시성을 퍼블릭으로 편집합니다. (권고 사항은 보안을 위해 Object Storage 의 가시성은 프라이빗으로 설정을 권고합니다.)
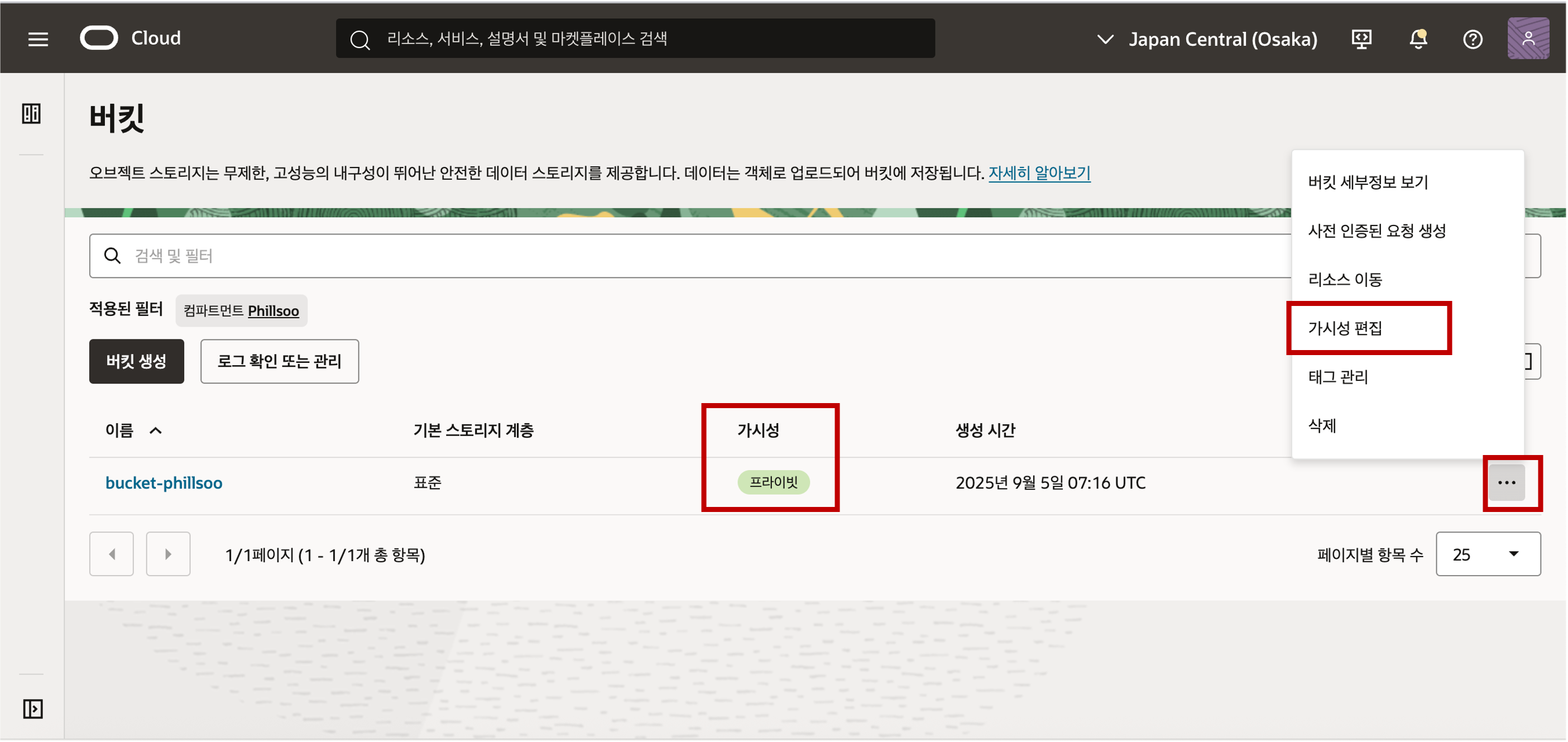
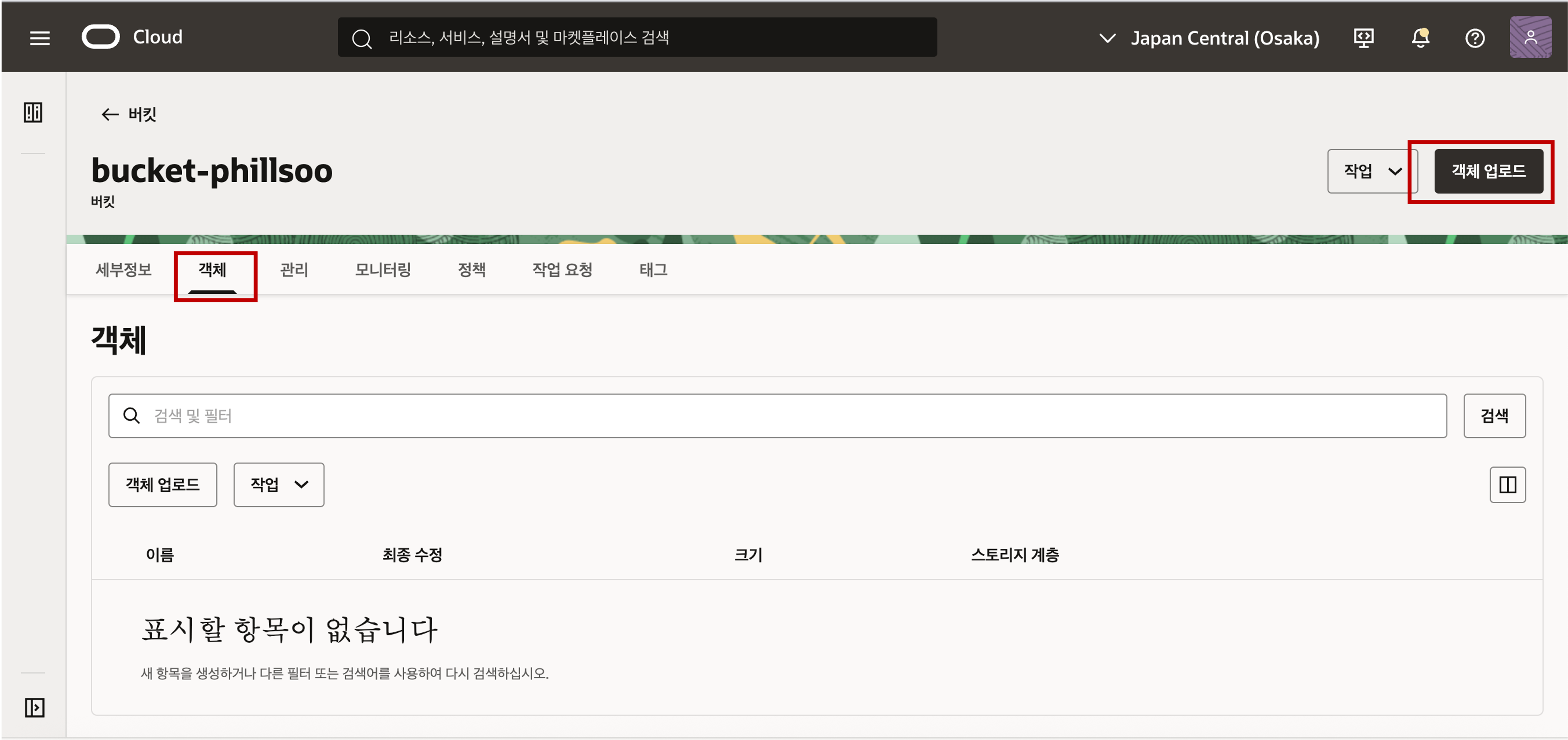
버킷을 클릭하여 버킷의 상세 정보로 접근해서 객체 탭을 클릭하면 버킷에 올라가 있는 파일이나 폴더의 객체를 확인하실 수 있습니다. 객체 업로드 버튼을 클릭하여 로컬 디스크에 준비한 Parquet 파일들을 Object Storage 의 Bucket 에 업로드 합니다.
업로드된 Object Stroage 의 데이터를 접근하기 위해서는 객체의 위치 정보인 URI 정보를 획득해야 합니다. URI 정보는 아래와 같은 샘플 형식으로 객체의 위치 정보가 저장되어 있습니다. 객체의 위치 정보는 아래 화면과 같이 객체 세부정보 보기 메뉴를 선택하여 확인할 수 있습니다.
- 객체 정보의 샘플 형식은 아래와 같이 객체를 뜻하는 ‘/o’ 까지의 위치 정보를 복사해 클립보드나 메모장에 복사하여 둡니다.
https://objectstorage.<region>.oraclecloud.com/n/<namespace>/b/<bucket>/o로컬 파일 업로드와 동일하게 Database Actions 의 Data Load 툴을 이용하여 Object Storage 의 Parquet 파일을 Loading 할 수 있습니다. 먼저, 아래의 화면에서 Data Studio 의 데이터 로드 메뉴를 선택합니다. 전환된 데이터 로드 화면에서 데이터 로드 타일을 선택하고 전환된 화면에서 상단 탭의 클라우드 저장소를 클릭하시고 클라우드 저장소 위치 생성 버튼을 클릭합니다.
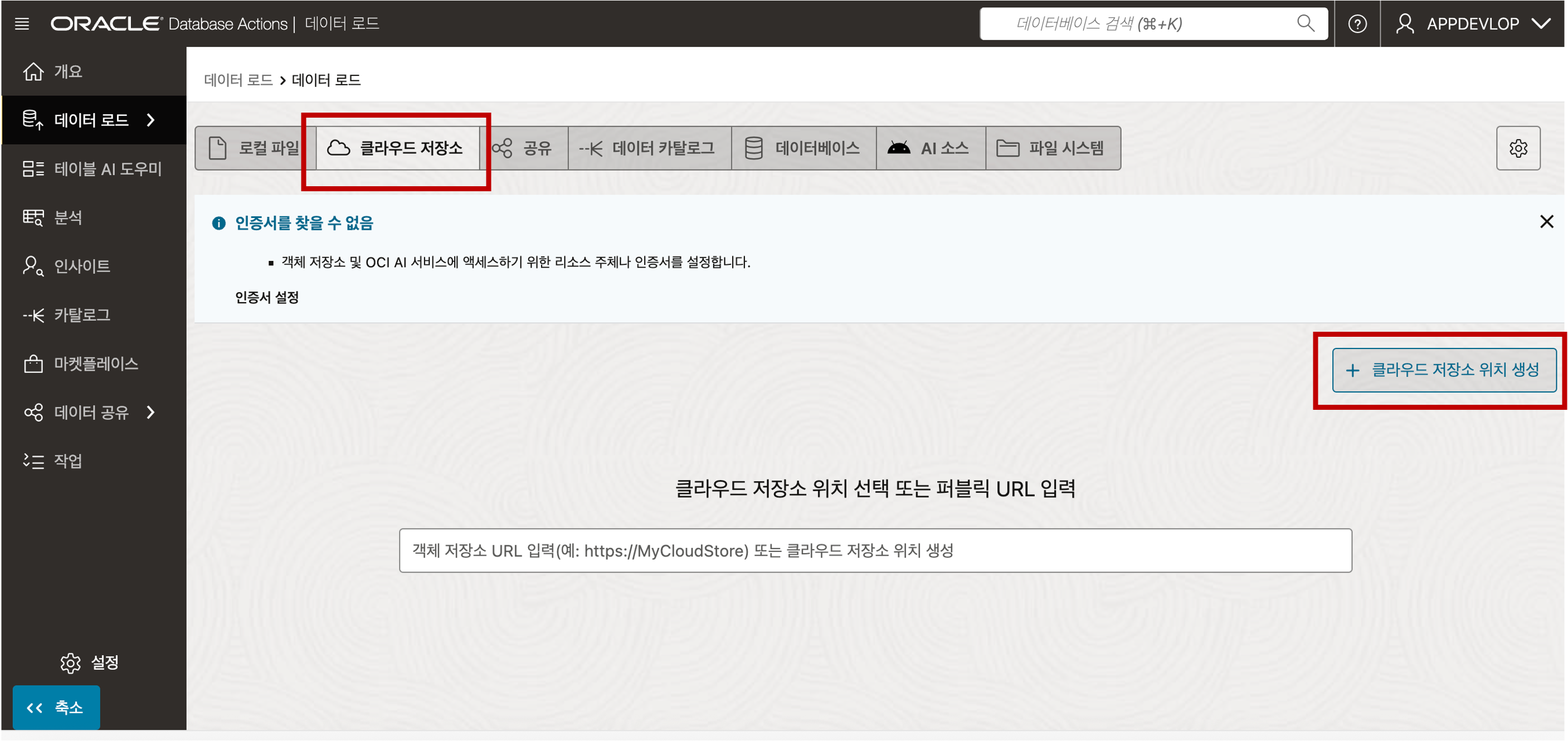
아래의 화면에서 버킷 URI 정보에 앞의 5번 단계에서 획득한 URI 정보를 복사하여 붙여넣기 한 후 다음 버튼을 클릭해 줍니다.
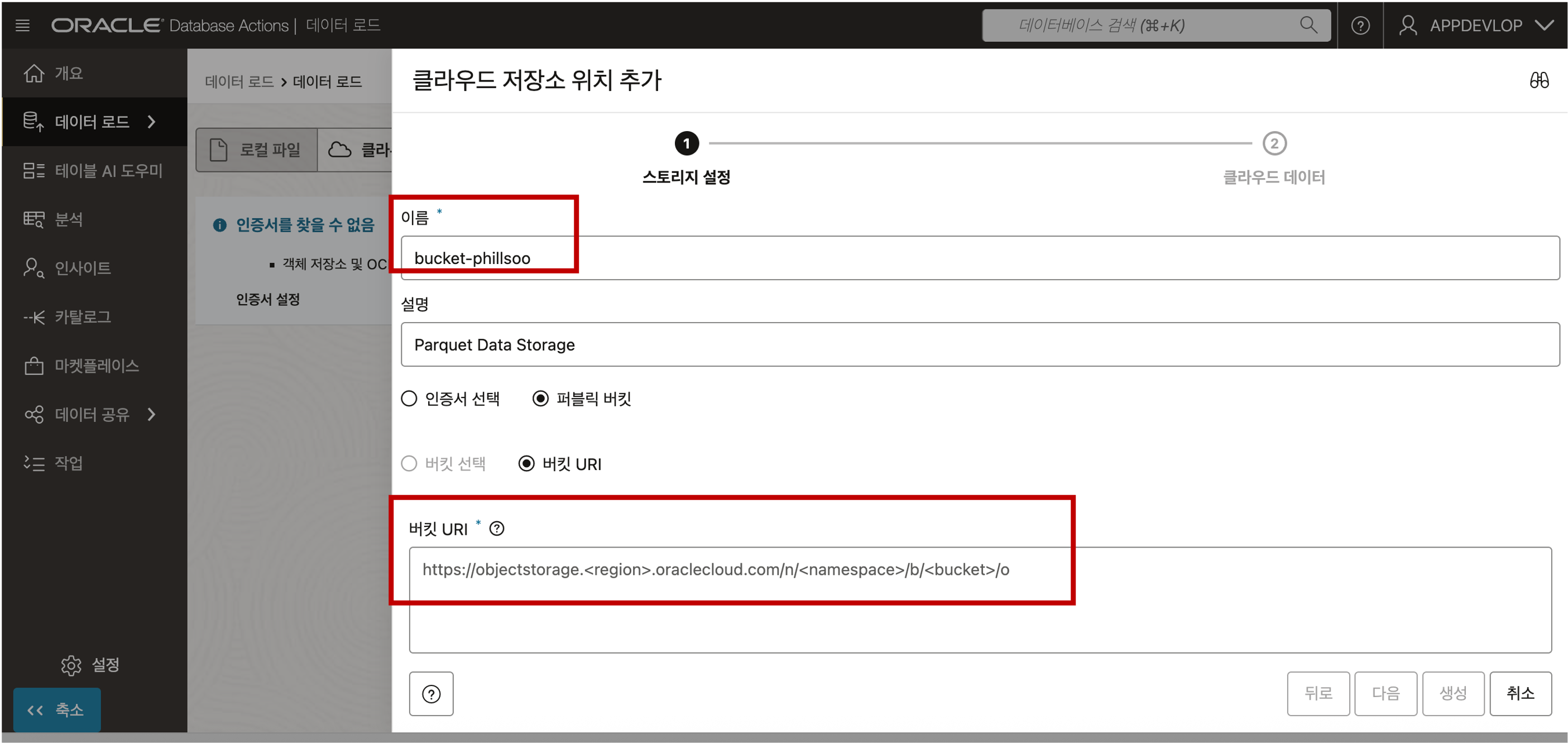
URI 정보에 정확한 정보가 입력되면 아래와 같이 업로드가 가능한 파일 목록이 나타납니다. 생성 버튼을 클릭하여 클라우드 위치 정보 생성을 마칩니다.
좌측의 Object Storage 내의 파일 목록에서 데이터 로드를 수행할 파일을 선택하고 우측의 창에 Drag & Drop 을 해 놓으면 아래 화면 처럼 데이터 로드가 준비됩니다. 시작 버튼을 클릭하여 데이터 로드를 시작합니다. 업로드가 완료되면 아래 그림과 같이 결과 보고서를 확인하실 수 있습니다. 여러개의 Parquet 파일이 있다면 반복적으로 수행하실 수 있습니다.
Object Storage 로부터 로딩된 Parquet 데이터 결과를 확인하기 위해서 Database Actions 툴에서 제공하는 SQL Developer 를 통해 확인할 수 있습니다. SQL Developer 의 좌측 네비게이터 목록에 테이블들이 추가된 것을 확인할 수 있고, 우측의 쿼리 결과 데이터가 성공적으로 로드가 된 것을 확인할 수 있습니다.
마무리
지금까지 Autonomous Database 에 Local Disk 와 Object Storage 에 저장된 CSV 파일, Parquet 파일을 Autonomous Database 에 기본적으로 탑재되어 있는 Data Loading 툴을 이용하여 손쉽게 Load 를 해 보았습니다. Autonomous Database 에 저장된 데이터를 조회할 수 있는 Python, Java, Node.js 어플리케이션 프로그램 개발 방법도 다루도록 하겠습니다. 아래 참고 자료 링크를 참조하세요.
추가 참고 자료
이 글은 개인적으로 얻은 지식과 경험을 작성한 글로 내용에 오류가 있을 수 있습니다. 또한 글 속의 의견은 개인적인 의견으로 특정 회사를 대변하지 않습니다.
Phillsoo Lim DATAPLATFORM
oci database exadata autonomous