DataPlatform
AI Data Platform 을 이용한 Lakehouse 분석 Hands-on
Table of Contents
- 들어가며
- 참고 문서
- 사전 준비 사항
- STEP-1. Hands-on 아키텍처와 Medallion 레이어 이해
- STEP-2. Compartment 및 ATP Source Database 구성
- STEP-3. Autonomous AI Lakehouse 및 Gold Schema 구성
- STEP-4. AI Data Platform, Object Storage, OAC 구성
- STEP-5. AIDP 에서 ATP Source 연결 및 Bronze Layer 생성
- STEP-6. Silver Layer 생성 및 Generative AI 기반 데이터 보강
- STEP-7. Gold Layer 생성 및 Autonomous AI Lakehouse 적재
- STEP-8. Oracle Analytics Cloud 에서 Gold 데이터 분석
- 문제 해결(트러블슈팅) 체크리스트
- 리소스 정리
- 마무리
들어가며
Oracle AI Data Platform(AIDP)은 다양한 데이터 소스를 연결하고, Spark/Delta Lake 기반으로 데이터를 처리하며, AI/ML 및 분석용 데이터 파이프라인을 구성할 수 있는 Oracle Cloud 의 데이터 플랫폼입니다. 이번 블로그에서는 Oracle LiveLabs 의 Accelerate Analytics on OAC with Generative AI, AIDP Data Platform, and Autonomous AI Lakehouse 워크숍을 기반으로, AIDP 를 이용한 Lakehouse 분석 Hands-on 절차를 정리했습니다.
이번 Hands-on 에서는 항공 운항 데이터를 예제로 사용합니다. Transactional Source 역할의 ATP 에서 데이터를 읽어와 AIDP 에서 Bronze, Silver, Gold 레이어로 정제하고, Gold 데이터를 Autonomous AI Lakehouse 에 적재한 뒤 Oracle Analytics Cloud(OAC) 에서 시각화와 Assistant 기반 자연어 분석을 수행합니다.
구성을 위한 아키텍처 및 데이터 흐름은 아래와 같습니다.
- AI Data Platform 기반 Lakehouse 분석 아키텍처
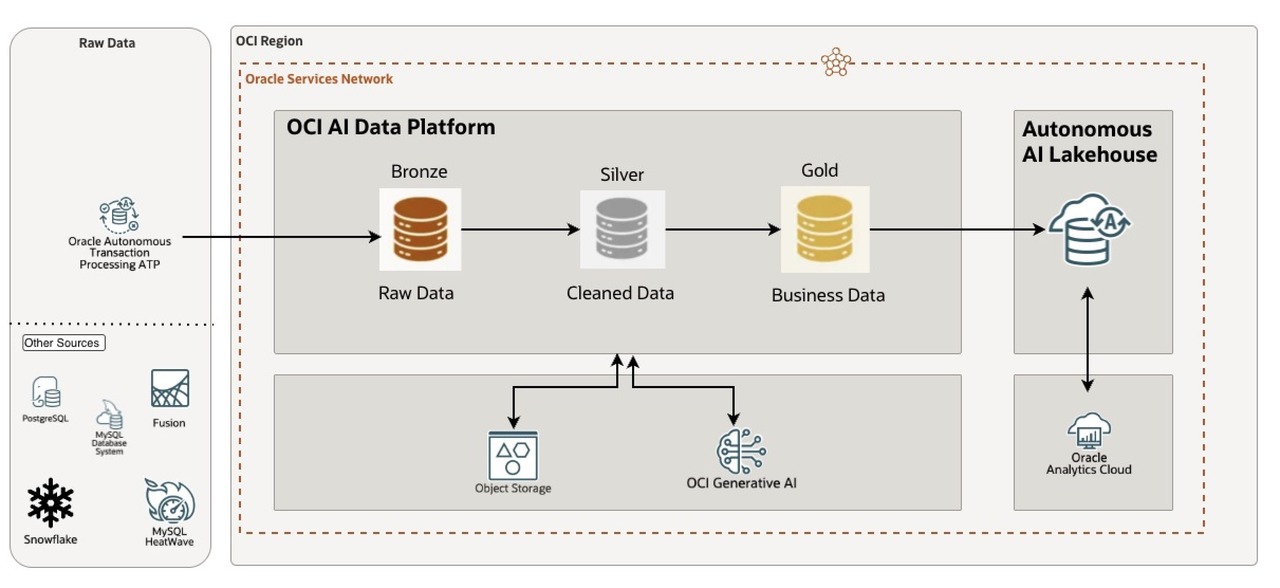
본 Hands-on 의 주요 흐름은 다음과 같습니다.
- ATP(Autonomous Transaction Processing): 항공 운항 원천 데이터 저장
- AI Data Platform: ATP External Catalog 연결, Spark Notebook, Delta Lake 처리
- Object Storage: Bronze/Silver/Gold Delta 파일 저장
- Autonomous AI Lakehouse: 분석용 Gold Schema 및 Gold Table 저장
- Oracle Analytics Cloud: Gold 데이터셋 연결, Workbook 시각화, Assistant 질의
- Generative AI: 리뷰 데이터의 감성 분석 컬럼 생성 예시
주의
- 실제 OCI Console 메뉴명과 서비스 지원 지역은 시점과 Region 에 따라 달라질 수 있습니다.
- 예제의
_XX값은 여러 사용자가 동시에 실습할 때 충돌을 피하기 위한 접미사입니다. 본인 환경에 맞게_01,_02등으로 치환하세요. - AIDP 에서 사용하는 LLM 모델명은 Region 별 지원 여부가 달라질 수 있습니다. 본문 예시는 LiveLabs 예제 흐름을 기준으로 설명합니다.
- 실습 후 사용하지 않는 ATP, Autonomous AI Lakehouse, AIDP, OAC, Object Storage 리소스는 비용 방지를 위해 정리하는 것을 권장합니다.
참고 문서
사전 준비 사항
본 Hands-on 을 수행하기 위해서는 아래 OCI 서비스에 접근할 수 있어야 합니다.
- Oracle Cloud 계정
- Autonomous Transaction Processing(ATP)
- Autonomous AI Lakehouse
- Oracle AI Data Platform(AIDP)
- Oracle Object Storage
- Oracle Analytics Cloud(OAC)
- OCI Generative AI 또는 AIDP 에서 제공하는 모델 카탈로그 접근 권한
실습에서 사용할 대표 리소스명은 아래와 같이 가정합니다.
| 구분 | 예시 이름 |
|---|---|
| Compartment | aidp-lab-xx |
| ATP Display Name | airline-source-atp |
| ATP DB Name | AIRLINESOURCEXX |
| Source Schema | SOURCE_XX |
| Autonomous AI Lakehouse Display Name | aidp-db |
| Autonomous AI Lakehouse DB Name | aidpdbxx |
| Gold Schema | GOLD_XX |
| AIDP Instance | aidp-test-xx |
| AIDP Workspace | airline-workspace_xx |
| Object Storage Bucket | aidp-demo-bucket_xx |
| Object Storage Folder | delta |
| OAC Instance | aidpoacxx |
| ATP External Catalog | atp_external_catalog_xx |
| AIDP Internal Catalog | airlines_data_catalog_xx |
| Lakehouse External Catalog | airlines_external_adb_gold_xx |
STEP-1. Hands-on 아키텍처와 Medallion 레이어 이해
이번 실습의 핵심은 데이터가 원천 시스템에서 분석 대시보드까지 이동하는 과정을 Lakehouse 패턴으로 구성하는 것입니다.
데이터 처리 흐름은 아래와 같습니다.
- ATP 의
SOURCE_XX.AIRLINE_SAMPLE테이블에 항공 운항 샘플 데이터를 저장합니다. - AIDP 에서 ATP 를 External Catalog 로 연결합니다.
- AIDP Notebook 에서 Spark 로 데이터를 읽어 Object Storage 의 Bronze Delta 영역에 저장합니다.
- Bronze 데이터를 정제하여 Silver Delta 영역으로 저장합니다.
- 평균 지연 시간, 평균 거리, 리뷰, 감성 분석 결과를 추가하여 Gold 데이터를 만듭니다.
- Gold 데이터를 Autonomous AI Lakehouse 의
GOLD_XX.AIRLINE_SAMPLE_GOLD테이블에 적재합니다. - OAC 에서 Gold 테이블을 Dataset 으로 연결하고 Workbook 과 Assistant 를 구성합니다.
Medallion Architecture 관점에서 보면 다음과 같이 정리할 수 있습니다.
- Bronze: 원천 시스템에서 추출한 Raw 에 가까운 Delta 데이터
- Silver: 결측/이상치를 제거하고 분석 가능한 형태로 정리한 데이터
- Gold: 대시보드와 비즈니스 분석에 바로 사용할 수 있도록 집계, 파생 컬럼, AI 분석 결과를 포함한 데이터
STEP-2. Compartment 및 ATP Source Database 구성
2-1. Compartment 생성
OCI Console 에서 Identity & Security -> Compartments 로 이동하여 실습용 Compartment 를 생성합니다.
- Name:
aidp-lab-xx - Description:
AIDP Lab
실습에서 생성하는 ATP, Autonomous AI Lakehouse, AIDP, Object Storage, OAC 리소스는 모두 이 Compartment 에 생성하면 관리와 삭제가 편리합니다.
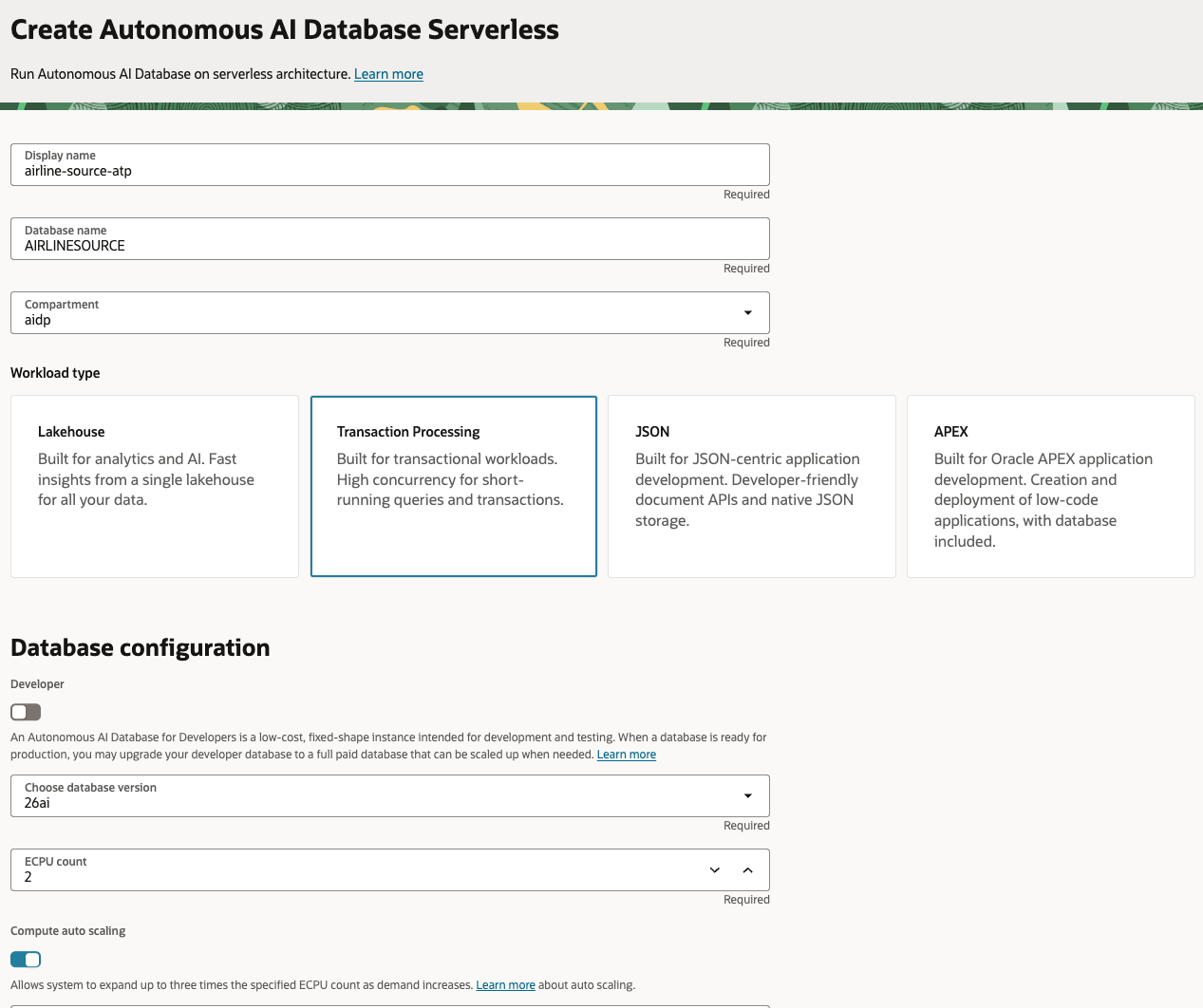
2-2. ATP 인스턴스 생성
OCI Console 에서 Oracle AI Database -> Autonomous AI Database 로 이동하여 ATP 인스턴스를 생성합니다.
- Display Name:
airline-source-atp - Database Name:
AIRLINESOURCEXX - Workload Type:
Transaction Processing - Database Version:
26ai - Access Type: 실습 편의를 위해
Secure access from everywhere선택
주의
- 실제 운영 환경에서는 네트워크 접근 범위를 최소화해야 합니다.
- Private endpoint 로 구성하는 경우 SQL Developer Web 접속을 위한 Database Tools Connection 등 추가 구성이 필요할 수 있습니다.
2-3. SOURCE_XX Schema 생성
ATP 생성이 완료되면 Database Actions -> SQL 로 이동하여 ADMIN 사용자로 접속합니다. 아래 SQL 로 원천 Schema 를 생성합니다.
CREATE USER source_xx IDENTIFIED BY "strong_password";
GRANT CONNECT, RESOURCE TO source_xx;
GRANT CREATE SESSION TO source_xx;
GRANT CREATE TABLE TO source_xx;
GRANT CREATE VIEW TO source_xx;
GRANT CREATE SEQUENCE TO source_xx;
GRANT CREATE PROCEDURE TO source_xx;
GRANT UNLIMITED TABLESPACE TO source_xx;
GRANT EXECUTE ON DBMS_CLOUD TO source_xx;
GRANT READ, WRITE ON DIRECTORY DATA_PUMP_DIR TO source_xx;
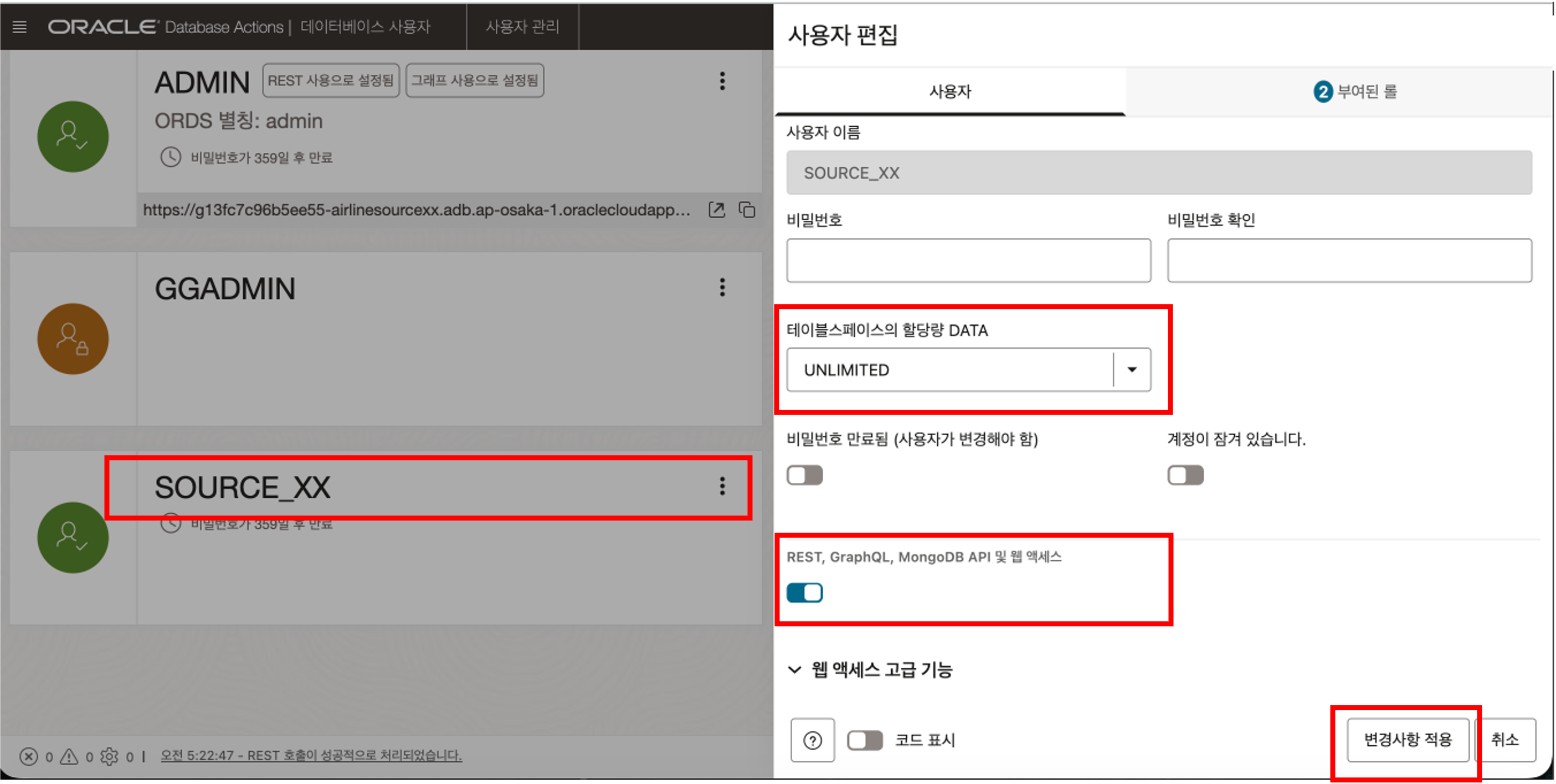
SQL Developer Web 에서 SOURCE_XX 사용자로 직접 로그인되지 않는 경우, Database Actions 의 Database Users 메뉴에서 해당 사용자의 “REST 접근” 을 활성화하고 Quota 를 “Unlimited” 로 설정합니다.
2-4. AIRLINE_SAMPLE 테이블 생성 및 샘플 데이터 입력
SOURCE_XX 사용자로 SQL Developer Web 에 로그인한 뒤 아래 테이블을 생성합니다.
CREATE TABLE airline_sample (
flight_id NUMBER,
airline VARCHAR2(30),
origin VARCHAR2(3),
dest VARCHAR2(3),
dep_delay NUMBER,
arr_delay NUMBER,
distance NUMBER
);
아래 SQL 로 실습용 항공 운항 데이터를 생성해 줍니다.
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1001, 'Skynet Airways', 'JFK', 'LAX', 10, 5, 2475);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1002, 'Sunwind Lines', 'ORD', 'SFO', -3, -5, 1846);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1003, 'BlueJet', 'ATL', 'SEA', 0, 15, 2182);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1004, 'Quantum Flyers', 'DFW', 'MIA', 5, 20, 1121);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1005, 'Nebula Express', 'BOS', 'DEN', 12, 8, 1754);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1006, 'Skynet Airways', 'SEA', 'ORD', -5, -2, 1721);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1007, 'Sunwind Lines', 'MIA', 'ATL', 7, 4, 595);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1008, 'BlueJet', 'SFO', 'BOS', 22, 18, 2704);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1009, 'Quantum Flyers', 'LAX', 'JFK', -1, 0, 2475);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1010, 'Nebula Express', 'DEN', 'DFW', 14, 20, 641);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1011, 'Skynet Airways', 'PHX', 'SEA', 3, -2, 1107);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1012, 'BlueJet', 'ORD', 'ATL', -7, -10, 606);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1013, 'Quantum Flyers', 'BOS', 'JFK', 9, 11, 187);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1014, 'Sunwind Lines', 'LAX', 'DFW', 13, 15, 1235);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1015, 'Nebula Express', 'SFO', 'SEA', 0, 3, 679);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1016, 'Skynet Airways', 'ATL', 'DEN', 6, 5, 1199);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1017, 'BlueJet', 'DFW', 'PHX', -2, 1, 868);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1018, 'Quantum Flyers', 'ORD', 'BOS', 8, -1, 867);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1019, 'Sunwind Lines', 'JFK', 'MIA', 10, 16, 1090);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1020, 'Nebula Express', 'DEN', 'ORD', -4, 0, 888);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1021, 'Skynet Airways', 'SEA', 'ATL', 16, 12, 2182);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1022, 'BlueJet', 'MIA', 'LAX', 5, 7, 2342);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1023, 'Quantum Flyers', 'DEN', 'BOS', 2, -2, 1754);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1024, 'Sunwind Lines', 'SFO', 'JFK', -6, -8, 2586);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1025, 'Nebula Express', 'ORD', 'MIA', 11, 13, 1197);
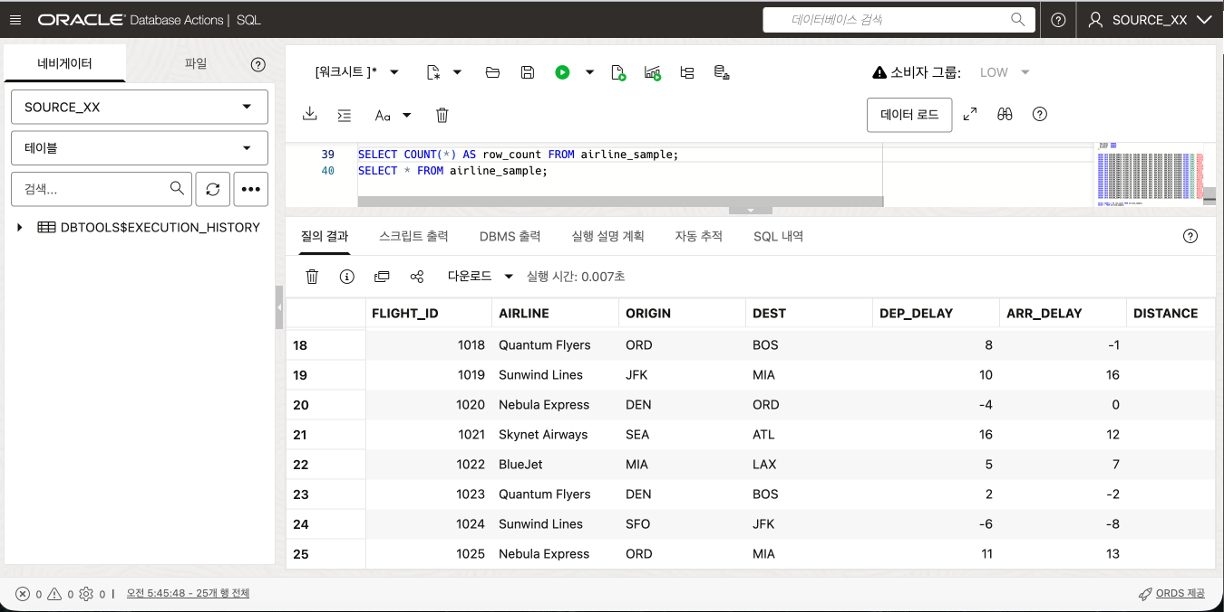
데이터 입력 후 아래와 같이 확인합니다.
SELECT COUNT(*) AS row_count FROM airline_sample;
SELECT * FROM airline_sample FETCH FIRST 10 ROWS ONLY;
STEP-3. Autonomous AI Lakehouse 및 Gold Schema 구성
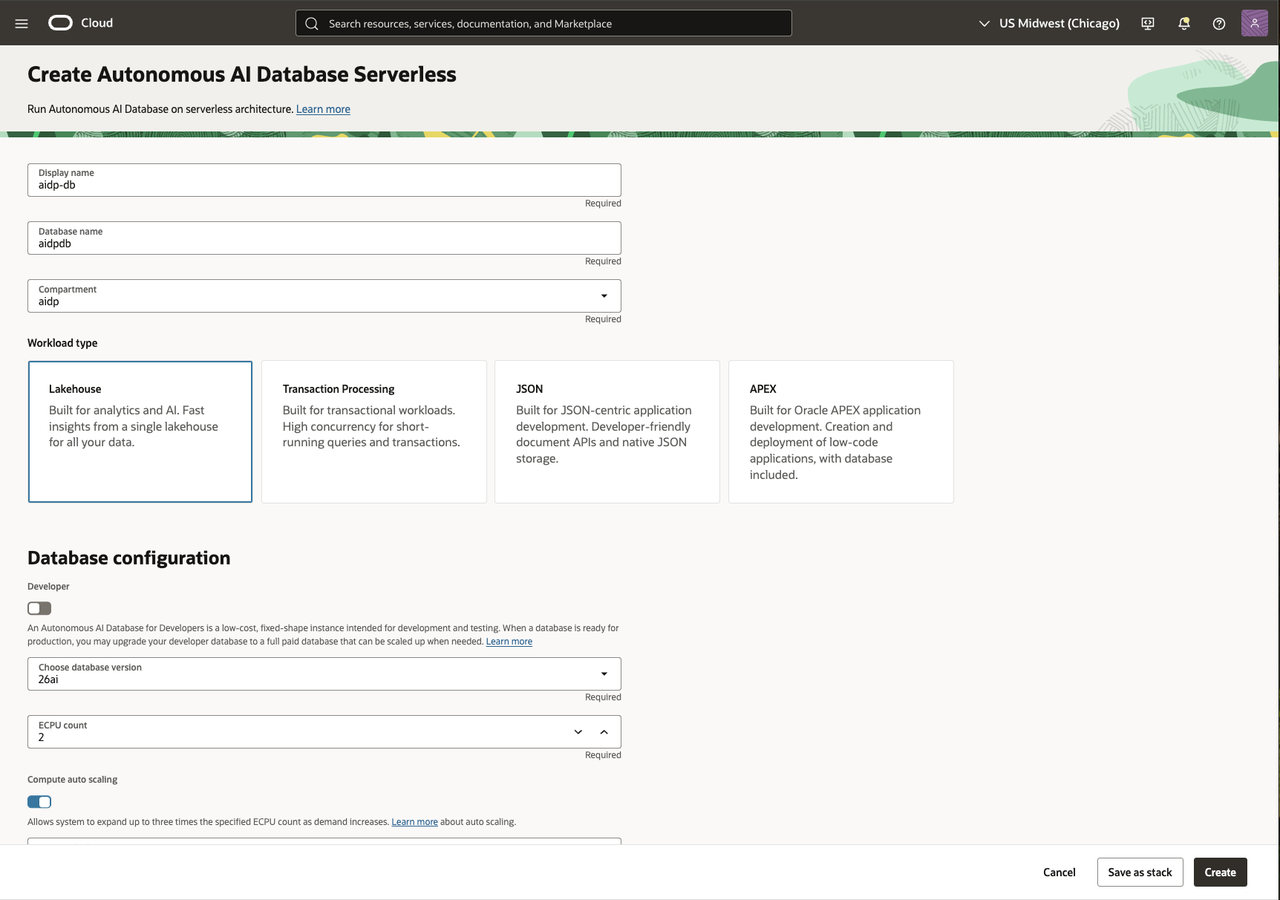
3-1. Autonomous AI Lakehouse 생성
OCI Console 에서 Oracle AI Database -> Autonomous AI Database 로 이동하여 Lakehouse 용 Autonomous AI Database 를 생성합니다.
- Display Name:
aidp-db - Database Name:
aidpdbxx - Workload Type:
Lakehouse - Database Version:
26ai - Access Type: 실습 편의를 위해
Secure access from everywhere선택
3-2. GOLD_XX Schema 생성
Autonomous AI Lakehouse 생성이 완료되면 Database Actions -> SQL 로 이동하여 ADMIN 사용자로 접속합니다. 아래 SQL 로 Gold Schema 를 생성합니다.
CREATE USER gold_xx IDENTIFIED BY "strong_password";
GRANT CONNECT, RESOURCE TO gold_xx;
GRANT CREATE SESSION TO gold_xx;
GRANT CREATE TABLE TO gold_xx;
GRANT CREATE VIEW TO gold_xx;
GRANT CREATE SEQUENCE TO gold_xx;
GRANT CREATE PROCEDURE TO gold_xx;
GRANT UNLIMITED TABLESPACE TO gold_xx;
GRANT EXECUTE ON DBMS_CLOUD TO gold_xx;
GRANT READ, WRITE ON DIRECTORY DATA_PUMP_DIR TO gold_xx;
ATP 의 SOURCE_XX 사용자와 마찬가지로 GOLD_XX 사용자도 SQL Developer Web 에서 로그인할 수 있도록 “REST 접근 활성화” 와 Quota “Unlimited” 설정을 확인합니다.
STEP-4. AI Data Platform, Object Storage, OAC 구성
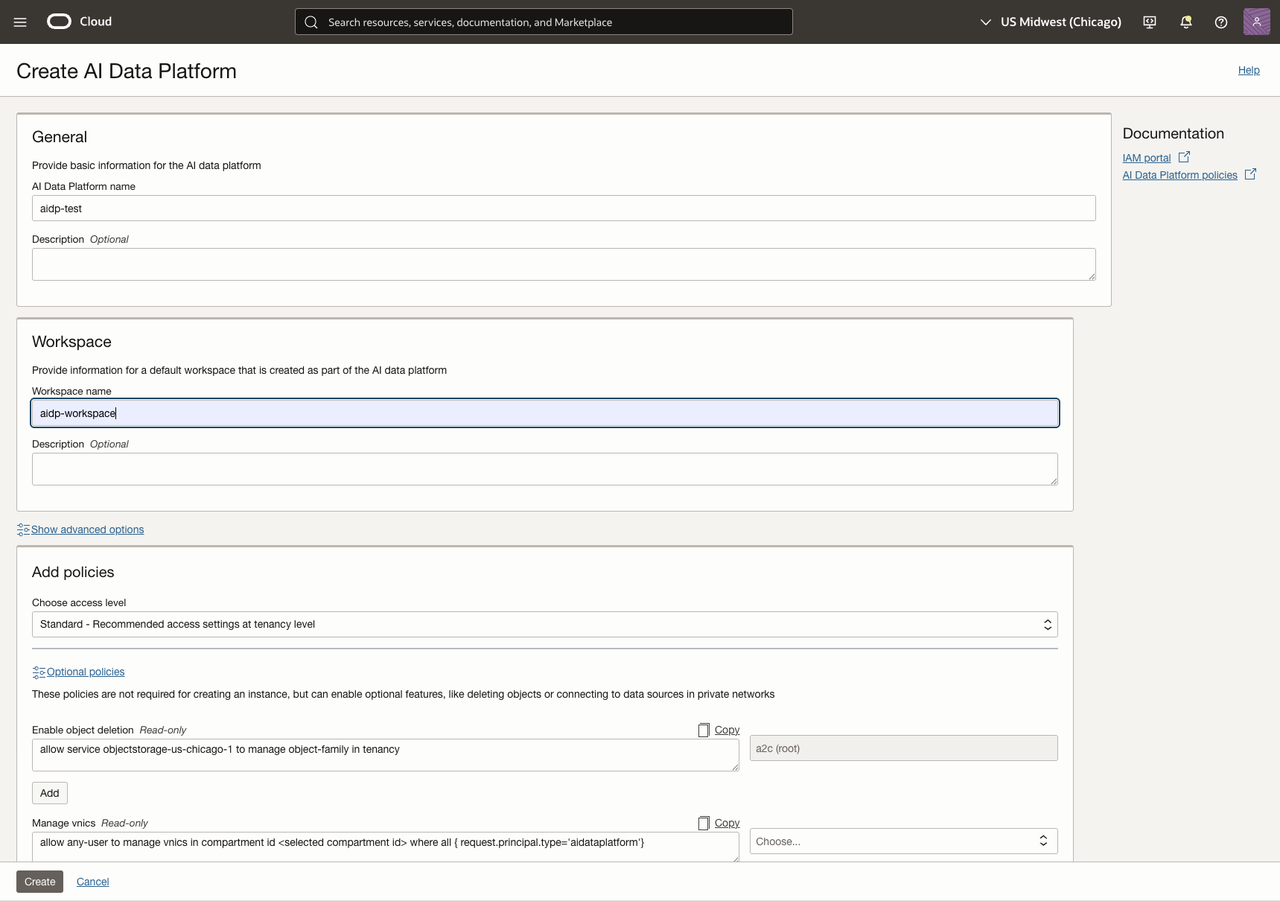
4-1. AI Data Platform 인스턴스 생성
OCI Console 에서 Analytics & AI -> Data Lake -> AI Data Platform 으로 이동하여 AIDP 인스턴스를 생성합니다.
- AIDP Instance Name:
aidp-test-xx - Workspace Name:
aidp-workspace - Access Level:
Standard - Optional Policy: Object 삭제가 필요한 실습 흐름에서는 Object 삭제 권한도 추가
중요
- AIDP 생성 화면의
Add policies단계에서 Standard Policy 를 추가하지 않으면 인스턴스 생성 또는 이후 데이터 접근이 실패할 수 있습니다. - 여러 명이 같은 Tenancy 에서 실습하는 경우 인스턴스명, Workspace 명, Catalog 명이 충돌하지 않도록
_XX접미사를 반드시 변경합니다.
4-2. Object Storage Bucket 생성
OCI Console 에서 Storage -> Buckets 로 이동하여 Bucket 을 생성합니다.
- Bucket Name:
aidp-demo-bucket - Storage Tier:
Standard - Folder:
delta
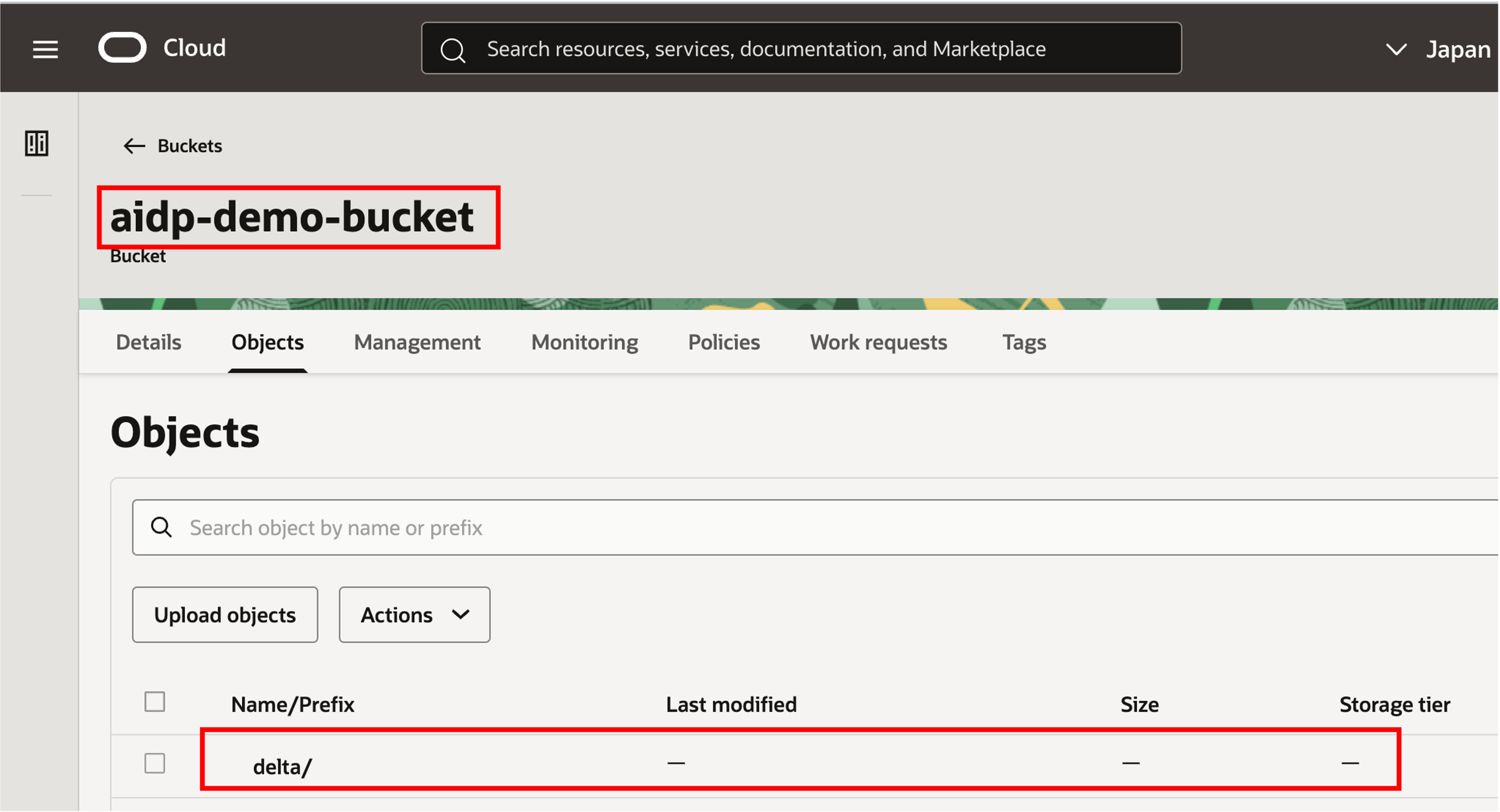
AIDP Notebook 에서 Object Storage 경로를 지정할 때 Namespace 가 필요합니다. Bucket 상세 화면에서 Namespace 값을 확인해 둡니다.
Object Storage 경로는 아래와 같은 형식을 사용합니다.
oci://aidp-demo-bucket@your-os-namespace/delta/airline_sample
4-3. Oracle Analytics Cloud 생성
OCI Console 에서 Analytics & AI -> Analytics Cloud 로 이동하여 OAC 인스턴스를 생성합니다.
- Name:
aidpoacxx - 나머지 옵션은 실습 목적이라면 기본값 사용
OAC 생성은 수 분 정도 소요될 수 있습니다.
STEP-5. AIDP 에서 ATP Source 연결 및 Bronze Layer 생성
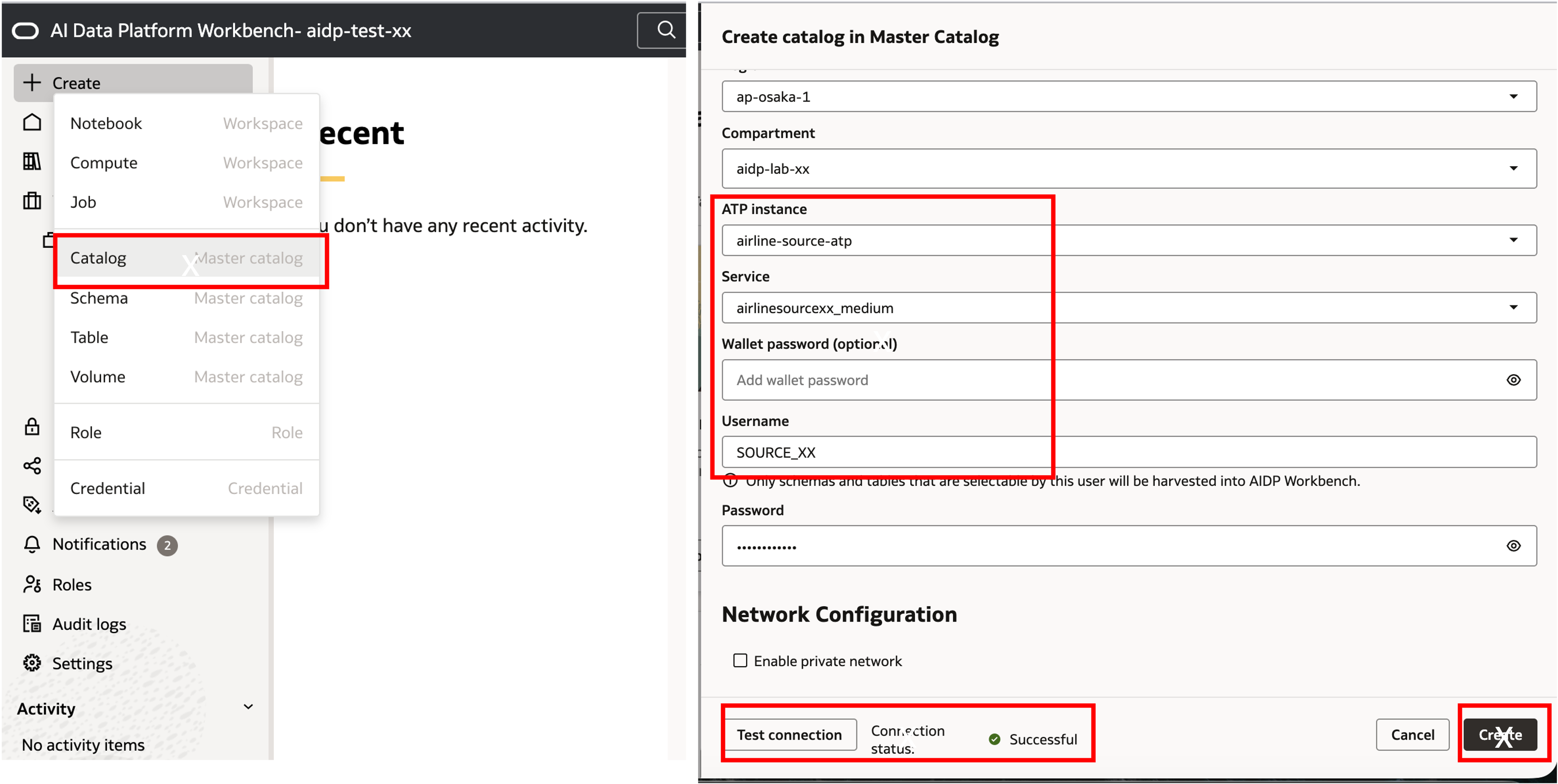
5-1. ATP External Catalog 생성
AIDP Console 을 열고 Create -> Catalog 를 선택합니다.
- Catalog Name:
atp_external_catalog_xx - Catalog Type:
External Catalog - External Source Type:
Oracle Autonomous Transaction Processing - ATP Instance:
airline-source-atp - Connection Type:
airlinesource_medium - User:
SOURCE_XX
Test Connection 을 수행하여 성공 여부를 확인한 뒤 Catalog 를 생성합니다.
5-2. Workspace, Notebook, Cluster 생성
AIDP 에서 아래의 이름으로 Workspace, Folder, Notebook 과 Spark Runtime 을 위한 Cluster 를 아래와 같은 이름으로 생성합니다.
- Workspace Name:
airline-workspace_xx - Default Catalog:
atp_external_catalog_xx - Folder:
demo - Notebook Name:
airlines-notebook - Cluster Name:
my_workspace_cluster_xx
먼저, 아래 화면과 같이 Workspace 명과 Default Catalog 를 선택하여 Workspace 를 생성합니다.
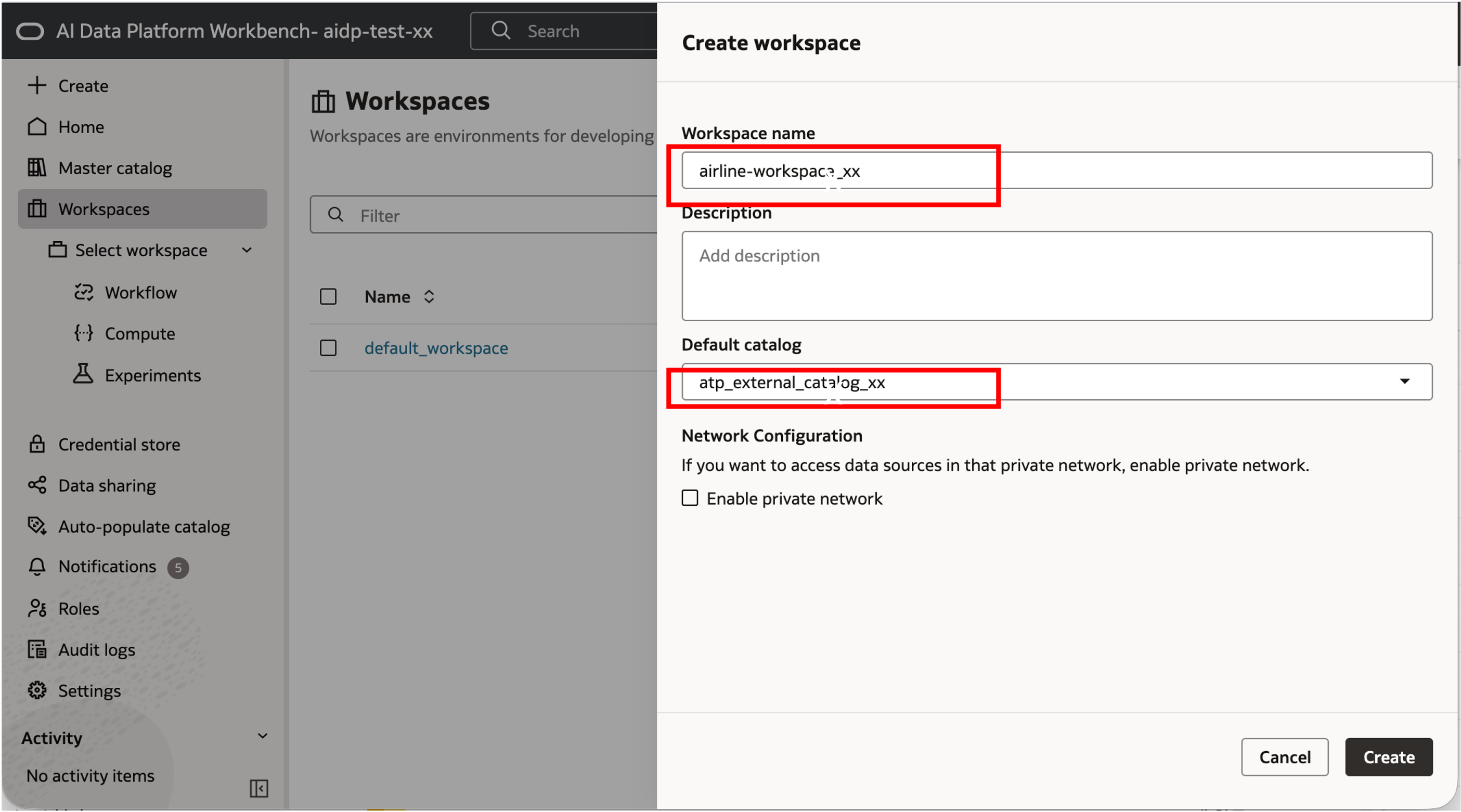
아래 화면과 같이 ‘+’ 버튼을 클릭하여 Workspace 안에서 사용할 ‘demo’ 폴더를 생성합니다.
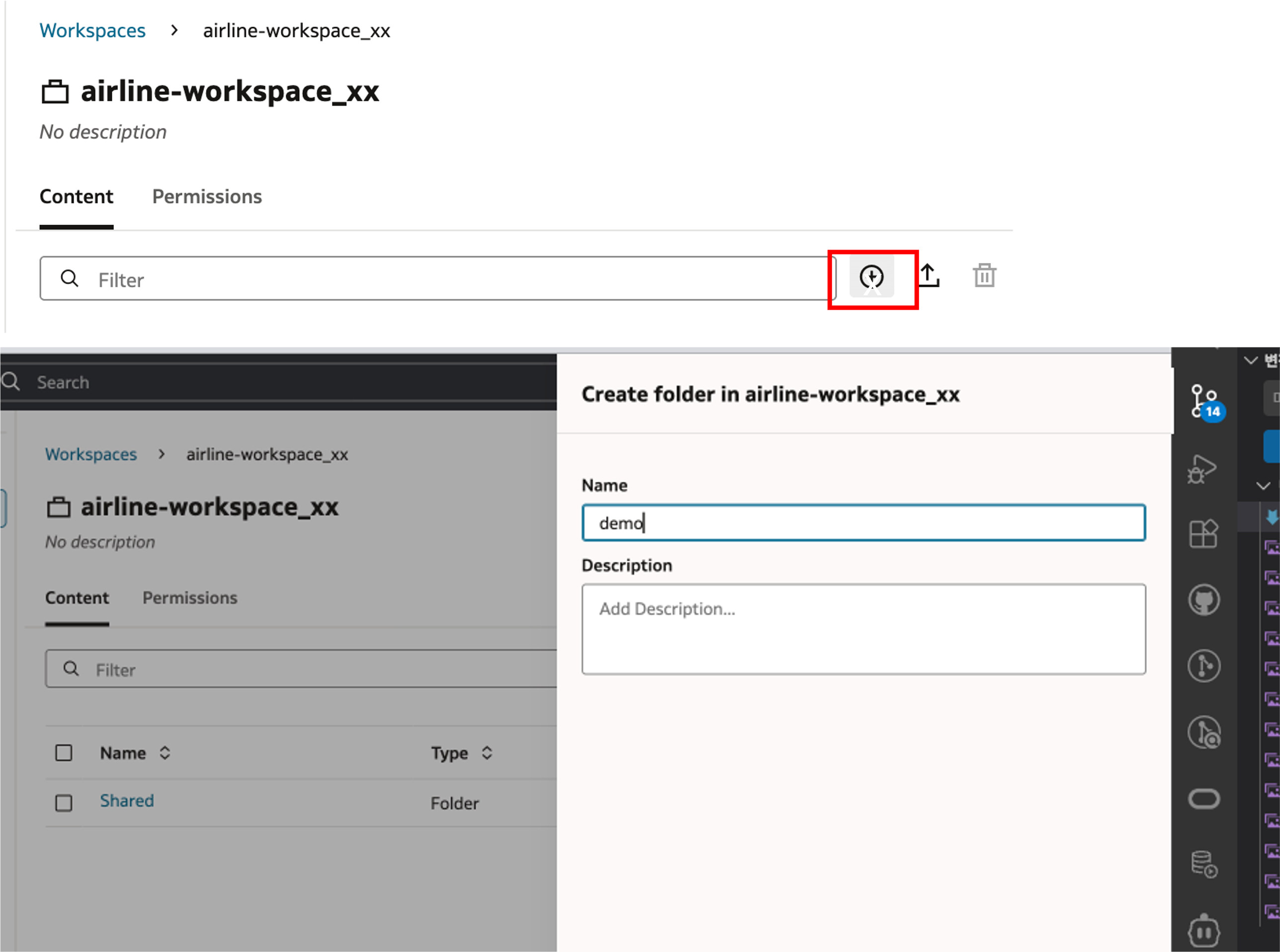
아래 화면과 같이 ‘+’ 버튼을 클릭하여 ‘demo’ 폴더 안에 ‘airlines-notebook.ipynb’ 파일을 생성합니다.
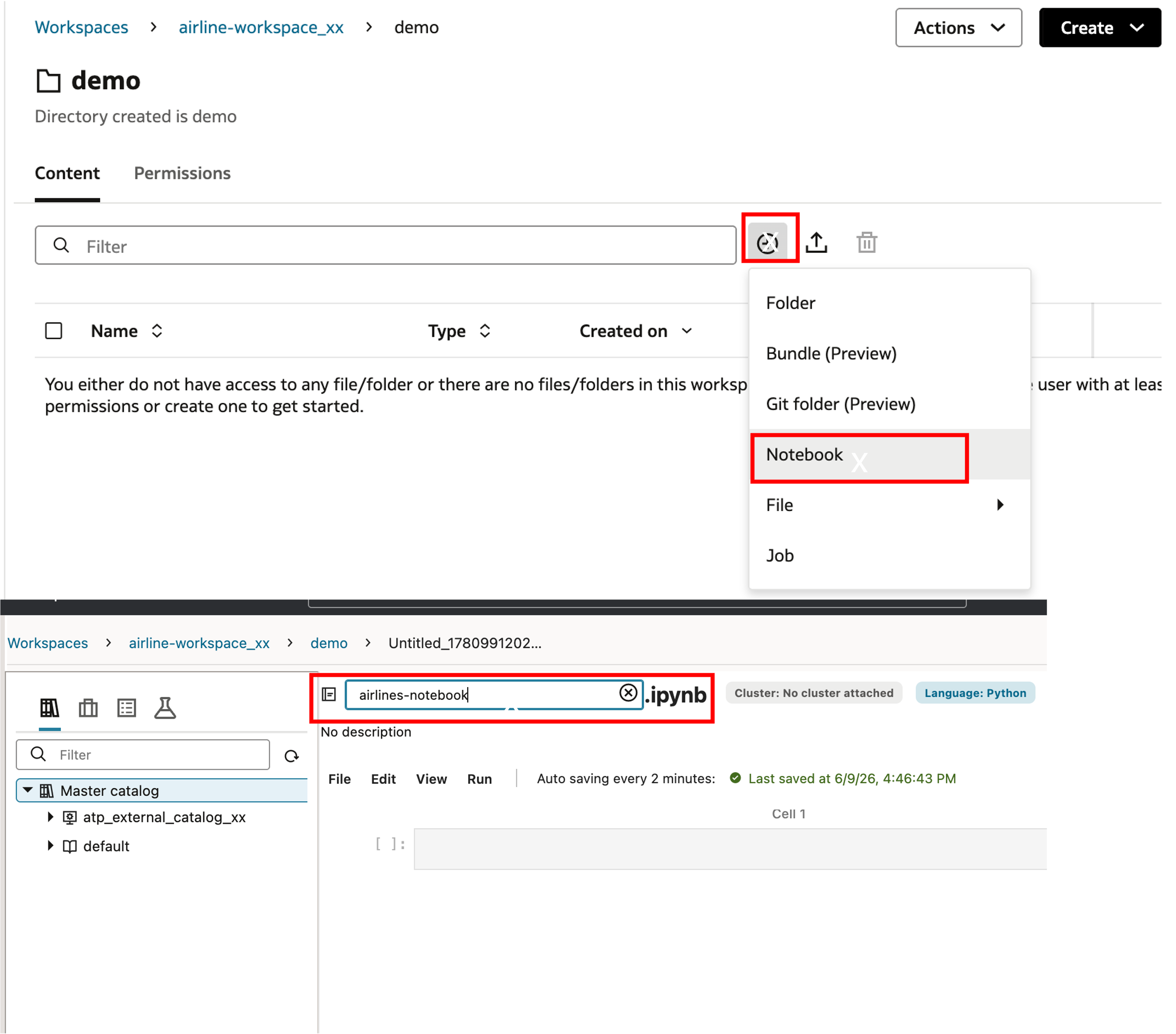
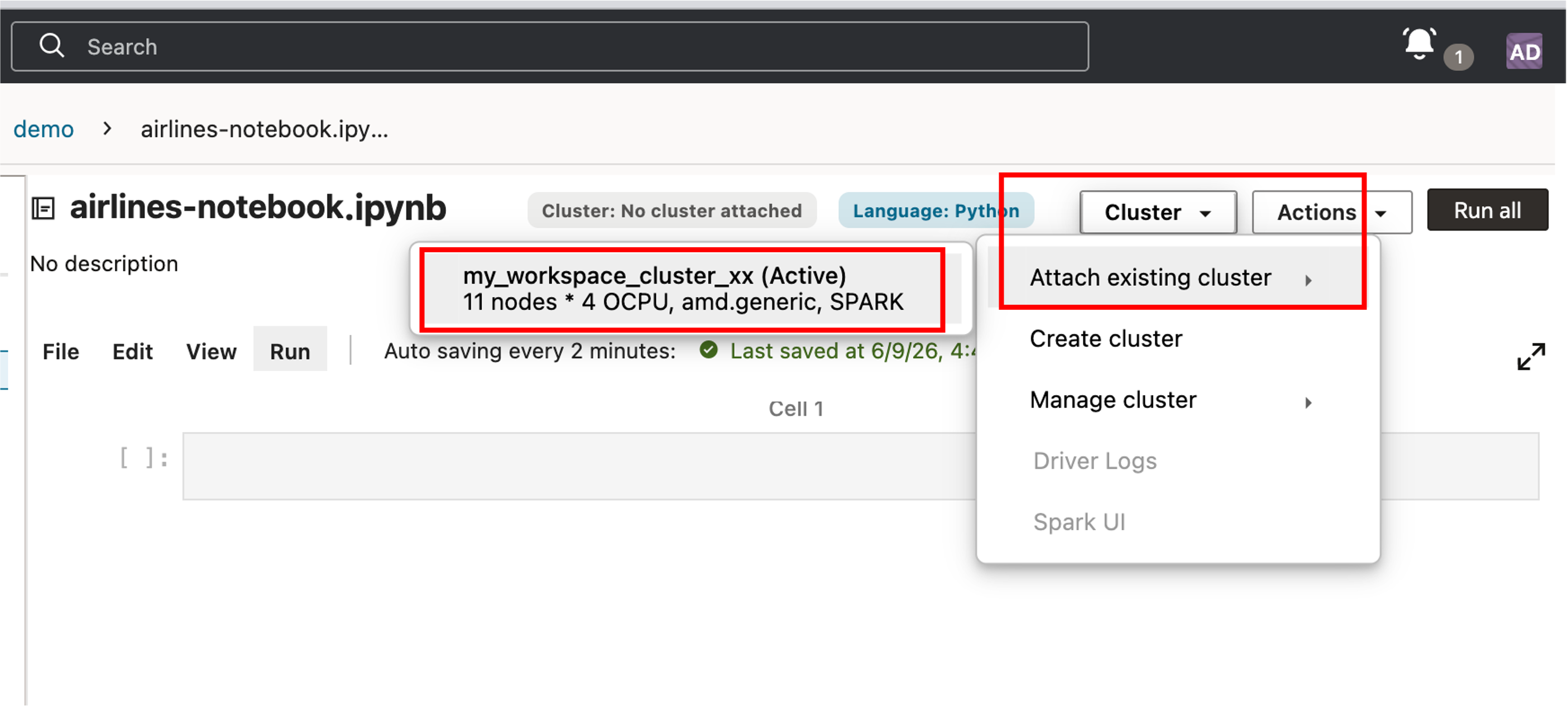
아래 화면과 같이 노트북 상단의 ‘Actions’ 버튼을 클릭하여 ‘Create Cluster’ 를 선택 후, ‘my_workspace_cluster_xx’ 라는 이름으로 클러스터를 생성합니다.
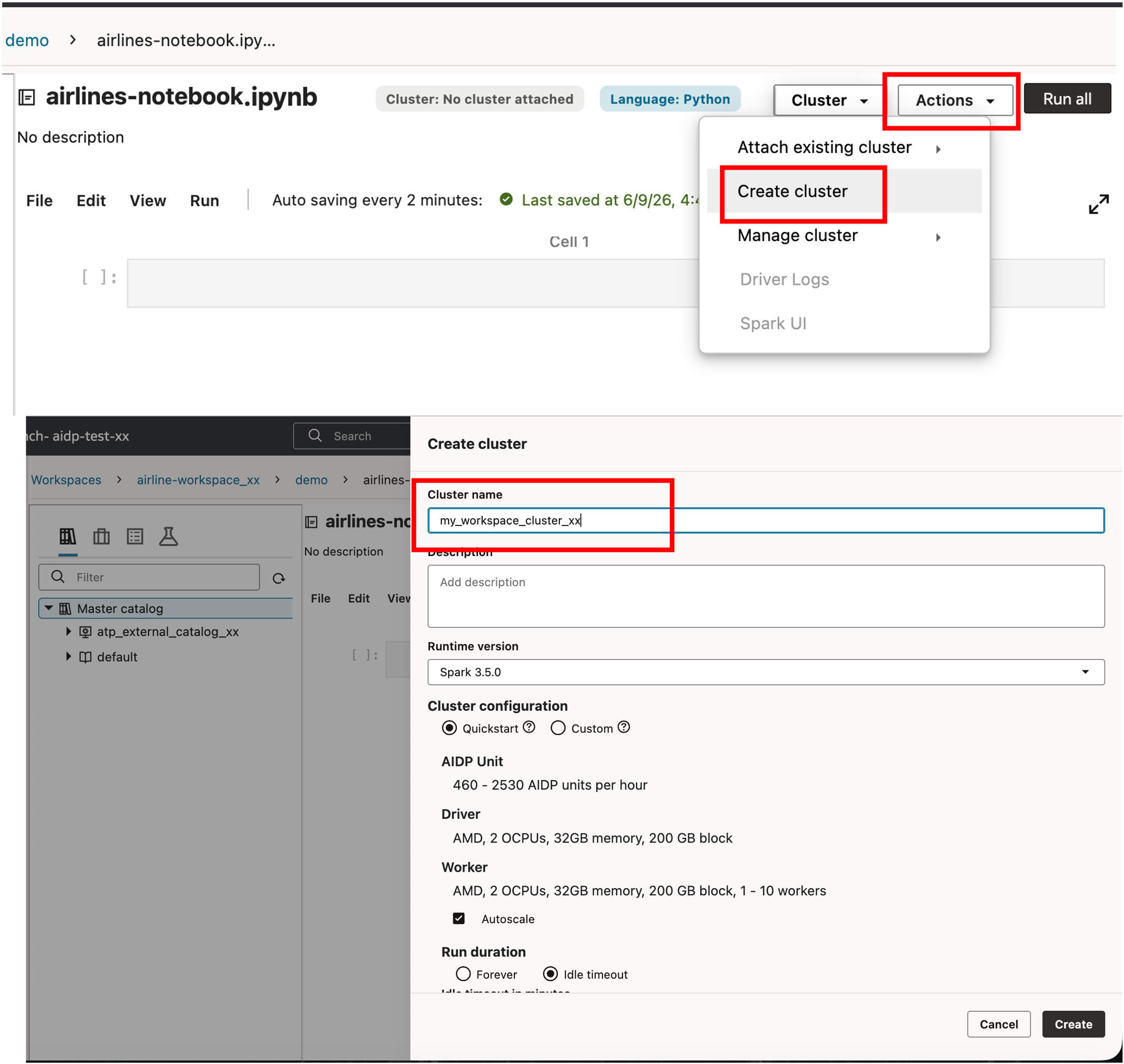
Notebook 을 열고 생성한 Cluster 를 Attach 합니다.
5-3. ATP Source Table 확인
Notebook 에서 앞서 생성한 airlines-notebook.ipynb 파일의 Python 셀을 생성하고 아래 코드를 수행합니다.
airlines_sample_table = "atp_external_catalog_xx.source_xx.AIRLINE_SAMPLE"
spark.sql("SHOW TABLES IN atp_external_catalog_xx.source_xx").show(truncate=False)
df = spark.table(airlines_sample_table)
df.show()
정상적으로 연결되면 ATP 의 AIRLINE_SAMPLE 데이터가 Spark DataFrame 으로 조회됩니다.

5-4. Object Storage 에 Bronze Delta 저장
계속해서 airlines-notebook.ipynb 파일의 Python 셀을 생성해서 Object Storage Namespace 값을 반영하여 Delta 경로를 지정합니다.
delta_path = "oci://aidp-demo-bucket@your-os-namespace/delta/airline_sample"
df.write.format("delta").mode("overwrite").save(delta_path)
이후 아래 코드를 추가하여 AIDP 내부 Catalog 와 Bronze Schema/Table 을 생성합니다.
bronze_table = "airlines_data_catalog_xx.bronze.airline_sample_delta"
spark.sql("CREATE CATALOG IF NOT EXISTS airlines_data_catalog_xx")
spark.sql("CREATE SCHEMA IF NOT EXISTS airlines_data_catalog_xx.bronze")
spark.sql(f"DROP TABLE IF EXISTS {bronze_table}")
spark.sql(f"""
CREATE TABLE {bronze_table}
USING DELTA
LOCATION '{delta_path}'
""")
5-5. Bronze 데이터 정제 및 Delta Version 확인
앞서 생성한 Bronze 라벨의 항공 운항 데이터에서 거리 (DISTANCE) 값이 비정상인 레코드를 제거하는 예시입니다.
spark.sql(f"""
DELETE FROM {bronze_table}
WHERE DISTANCE IS NULL OR DISTANCE < 0
""")
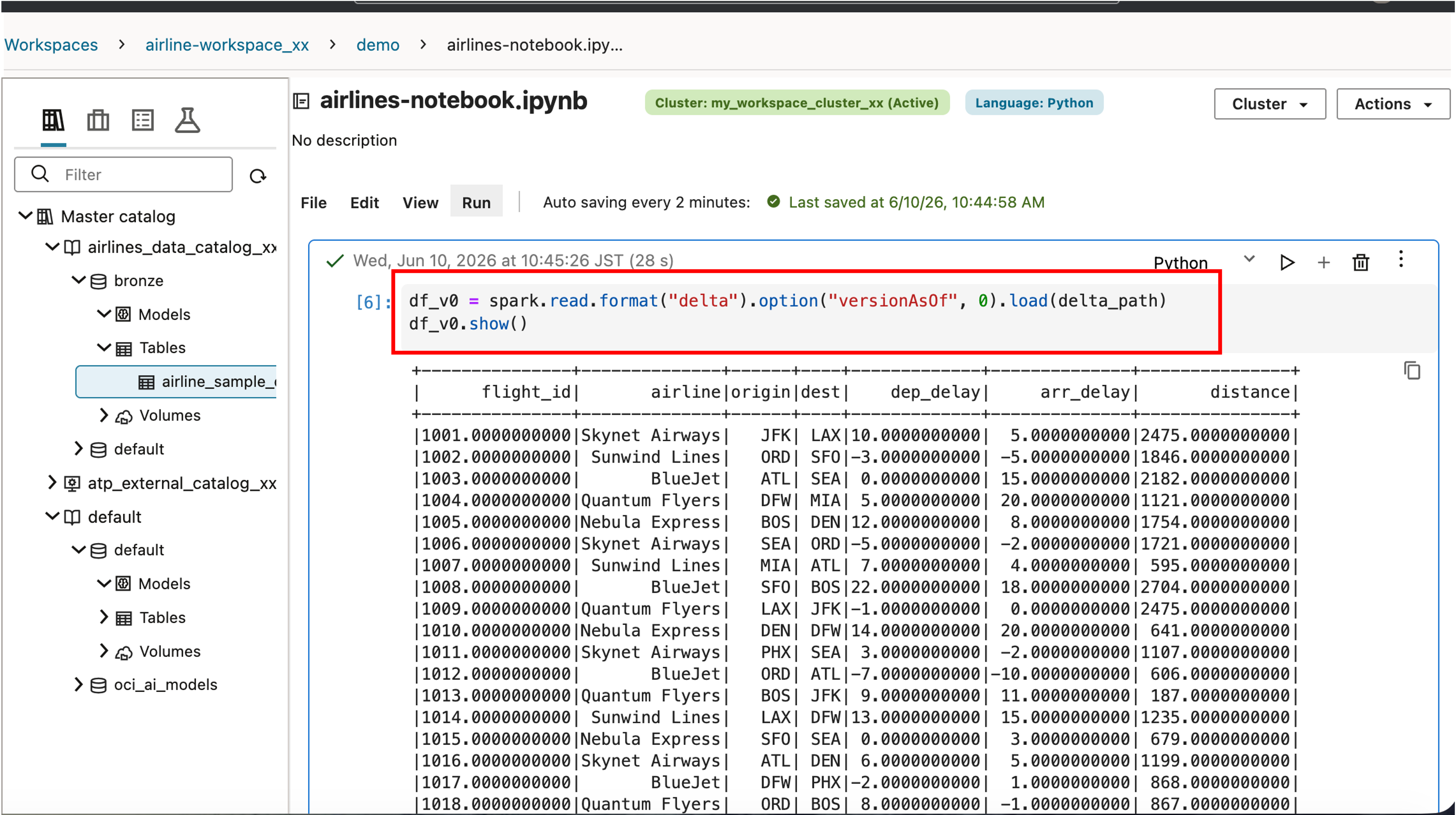
Delta Lake 의 Versioning 기능을 확인하기 위해 이전 버전을 조회합니다.
df_v0 = spark.read.format("delta").option("versionAsOf", 0).load(delta_path)
df_v0.show()
STEP-6. Silver Layer 생성 및 Generative AI 기반 데이터 보강
6-1. Silver Delta Table 생성
Bronze Table 을 읽어 Silver Delta 경로에 저장합니다.
df_clean = spark.table(bronze_table)
silver_path = "oci://aidp-demo-bucket@your-os-namespace/delta/silver/airline_sample"
silver_table = "airlines_data_catalog_xx.silver.airline_sample_delta"
spark.sql("CREATE SCHEMA IF NOT EXISTS airlines_data_catalog_xx.silver")
df_clean.write.format("delta").mode("overwrite").save(silver_path)
spark.sql(f"DROP TABLE IF EXISTS {silver_table}")
spark.sql(f"""
CREATE TABLE {silver_table}
USING DELTA
LOCATION '{silver_path}'
""")
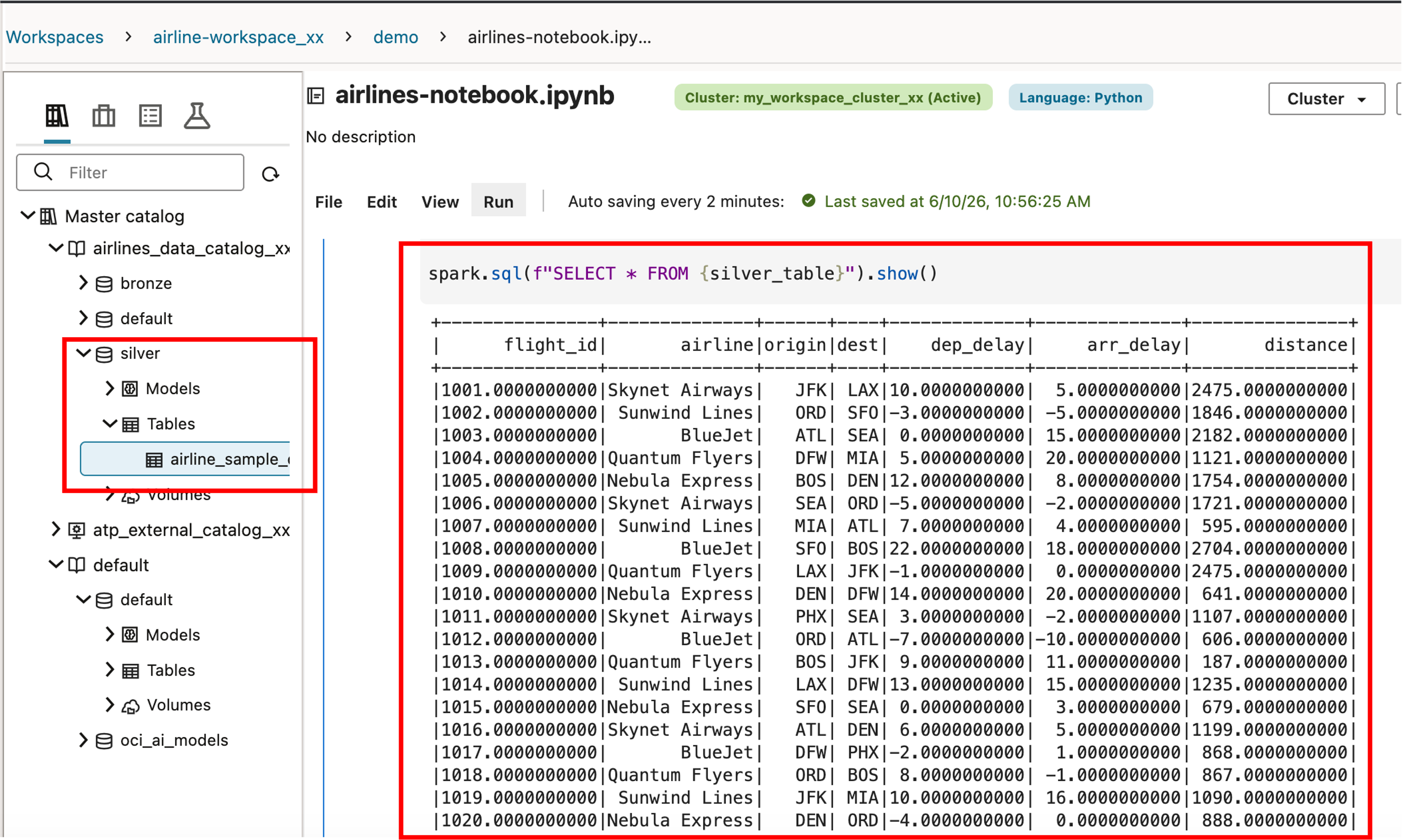
spark.sql(f"SELECT * FROM {silver_table}").show()
Catalog 에 Silver 레벨의 데이터가 추가되었고 추가된 Silver Data 가 조회되는 것을 확인할 수가 있습니다.
6-2. 항공사별 평균 지연 및 평균 거리 계산
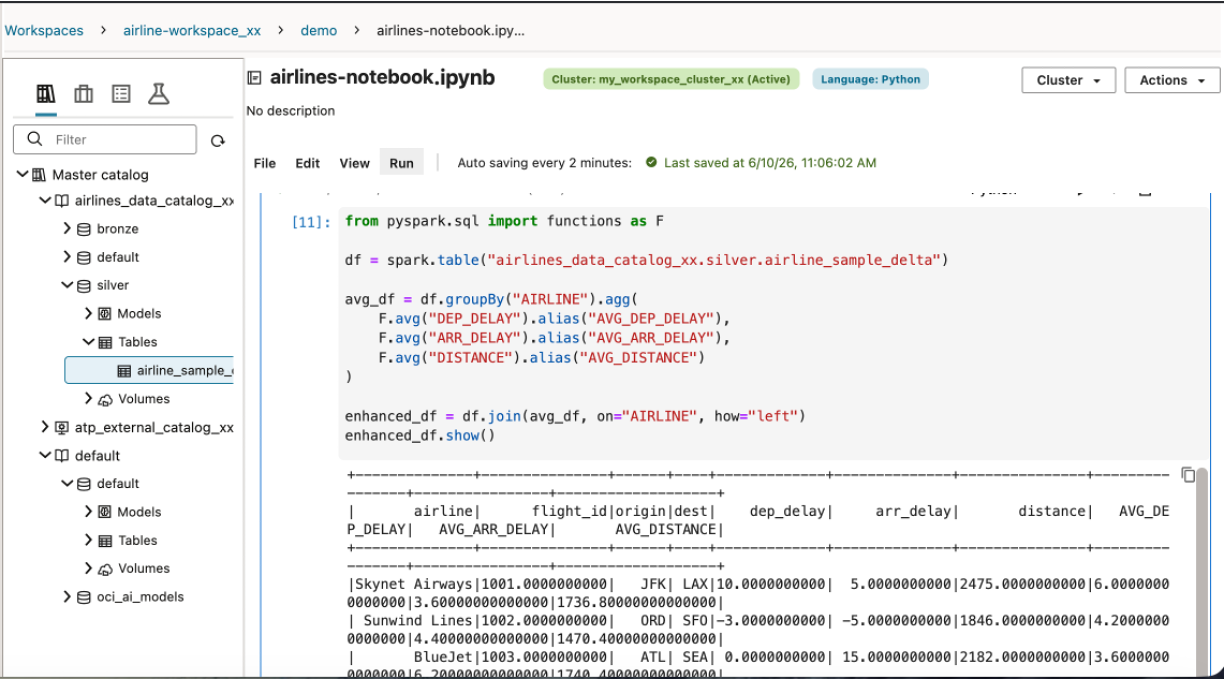
Silver 데이터를 기준으로 항공사별 평균 출발 지연, 도착 지연, 평균 거리를 계산한 뒤 원본 상세 데이터와 Join 합니다.
from pyspark.sql import functions as F
df = spark.table("airlines_data_catalog_xx.silver.airline_sample_delta")
avg_df = df.groupBy("AIRLINE").agg(
F.avg("DEP_DELAY").alias("AVG_DEP_DELAY"),
F.avg("ARR_DELAY").alias("AVG_ARR_DELAY"),
F.avg("DISTANCE").alias("AVG_DISTANCE")
)
enhanced_df = df.join(avg_df, on="AIRLINE", how="left")
enhanced_df.show()
6-3. 리뷰 컬럼과 감성 분석 컬럼 추가
감정 분석을 위해 먼저 아래와 같이 샘플 리뷰들을 작성하고, 데이터에 저장할 컬럼을 추가합니다.
import random
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
sample_reviews = [
"비행기는 정시에 출발했고 편안했습니다.",
"대기 시간이 길고 직원들이 불친절했습니다.",
"빠른 탑승과 편안한 비행이었습니다.",
"짐을 잃어버려서 기분이 안 좋아요.",
"훌륭한 서비스와 맛있는 간식에 만족합니다."
]
random_review_udf = udf(lambda: random.choice(sample_reviews), StringType())
df_with_review = enhanced_df.withColumn("REVIEW", random_review_udf())
df_with_review.show()
상기 Python Code 를 notebook 에서 실행하면 아래 그림처럼 Review Column 이 추가된 것을 확인할 수 있습니다.
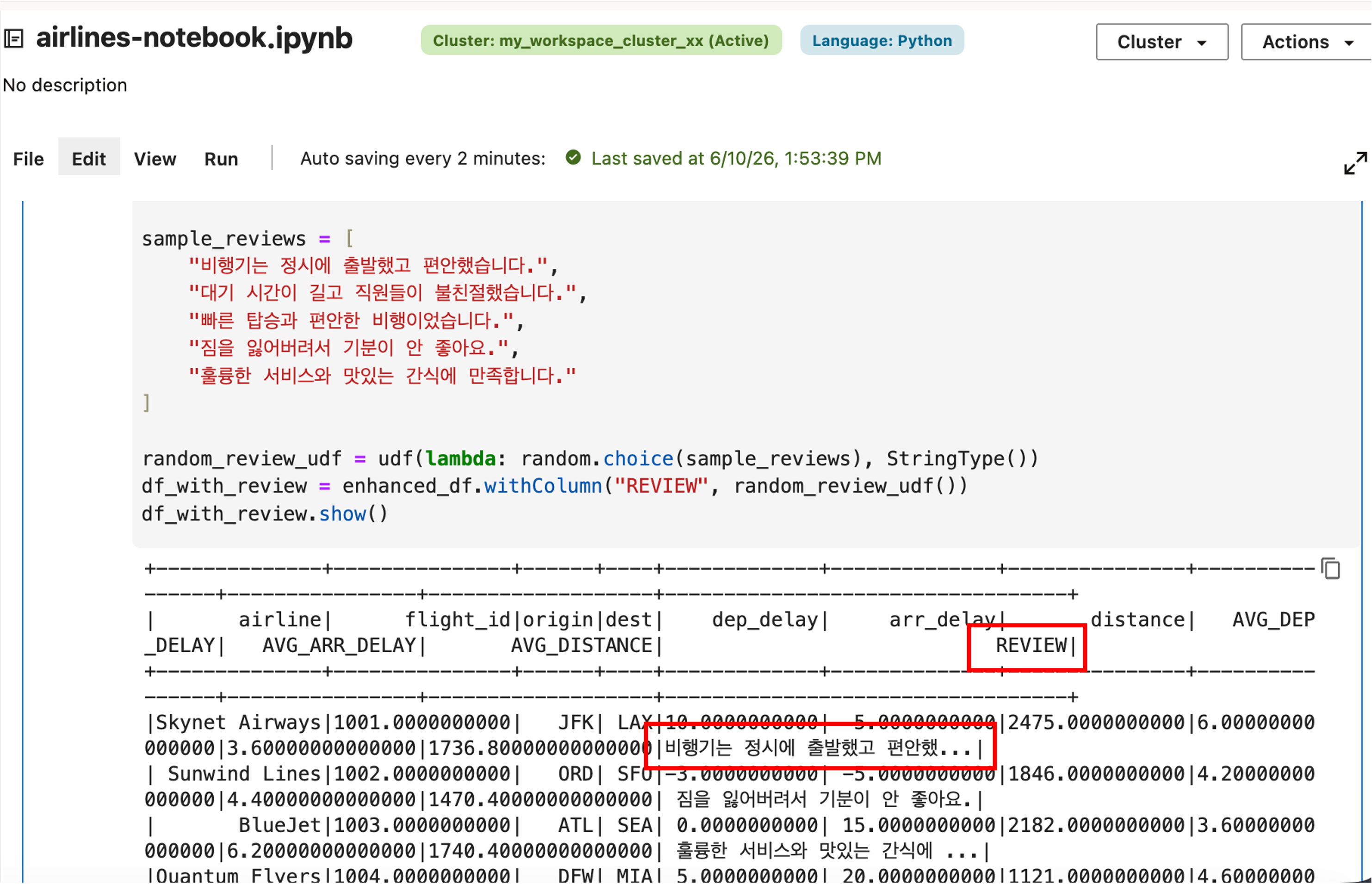
AIDP 에서 제공되는 LLM 생성형 Gen AI 모델을 이용해 리뷰 감성을 분석합니다. 아래 예시는 LiveLabs 워크숍 흐름에 맞춘 예시이며, 실제 사용 가능한 모델명은 Region 과 서비스 설정에 따라 달라질 수 있습니다. 현재 사용하고 있는 Region 에서 사용 가능한 LLM 모델은 AIDP Master Catalog 의 “oci_ai_models” 메뉴에서 확인하실 수 있습니다.
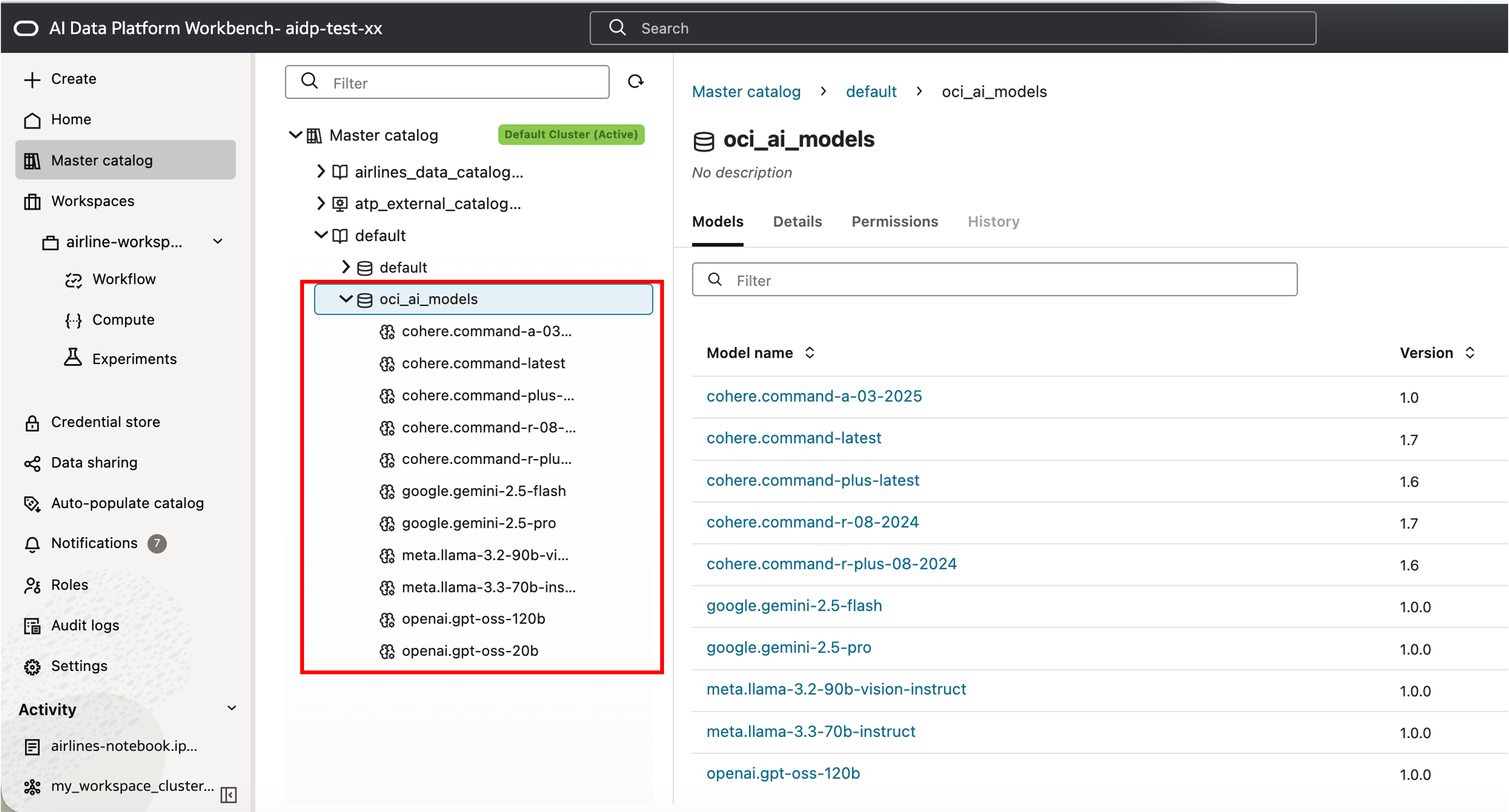
이번 실습에서는 감정 분석을 위해 상기 모델 중에서 ‘google.gemini-2.5-flash’ 모델을 이용하여 AI 에게 평가 의견을 받아 저장해 보도록 하겠습니다.
from pyspark.sql.functions import expr
enhanced_df = df_with_review.withColumn(
"SENTIMENT",
expr("query_model('google.gemini-2.5-flash', concat('이 리뷰에 대한 평가는 어떻습니까?: ', REVIEW))")
)
enhanced_df.show(10, False)
상기 Python Code 를 실행하면 아래와 같이 사용한 Gen AI LLM 모델을 통해 전달 받은 감정 분석 결과가 SENTIMENT 컬럼에 추가되어 저장된 것을 확인할 수 있습니다.
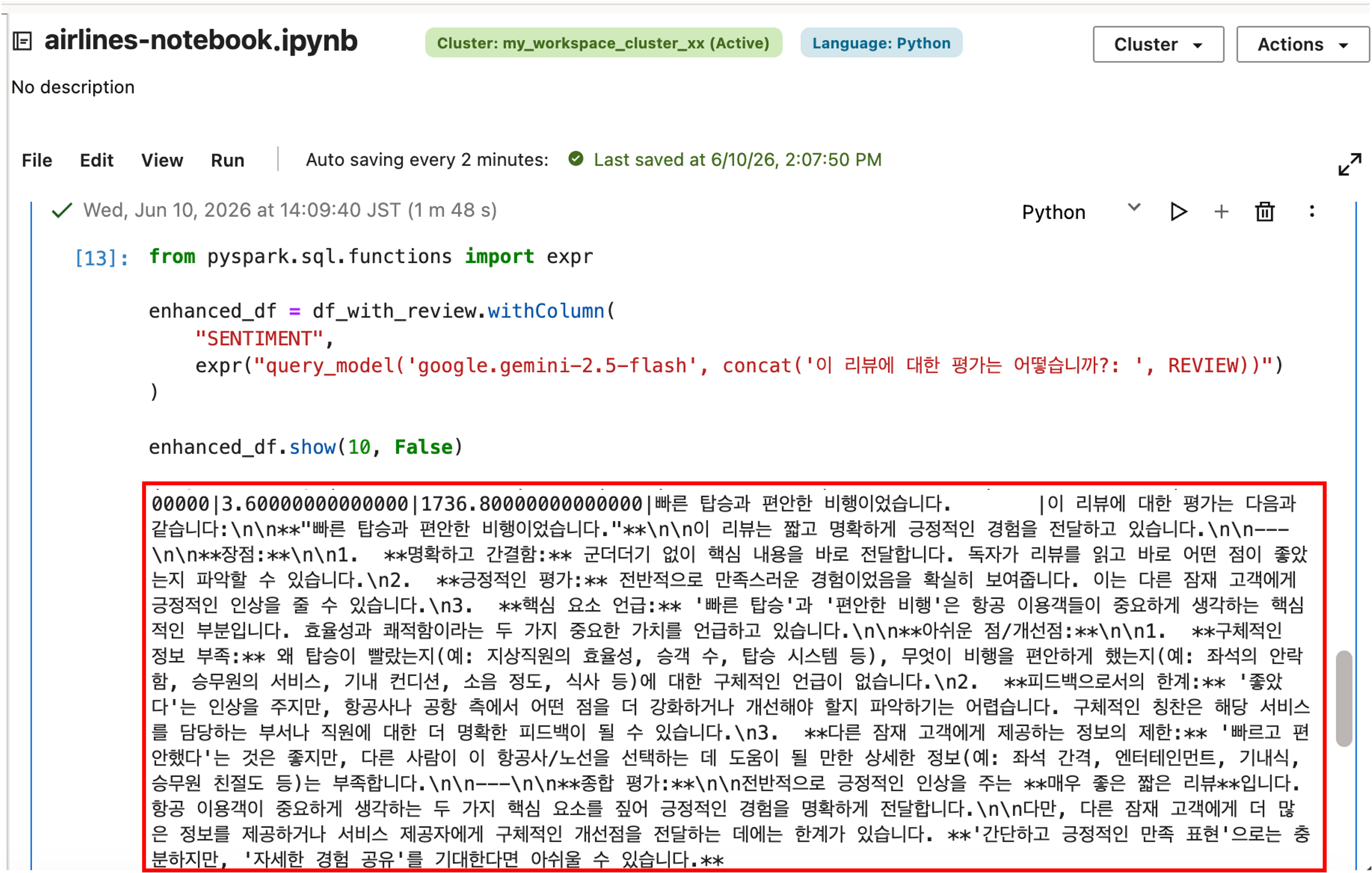
팁
- 모델을 찾을 수 없다는 오류가 발생하면 AIDP 모델 카탈로그에서 해당 Region 에서 사용 가능한 모델명을 반드시 확인합니다.
- LiveLabs 예시에서는
xai.grok-4,cohere.command-latest같은 모델을 언급하지만, 지원 Region 과 모델명은 변경될 수 있습니다. 본 실습에서는 오사카 리전에서 사용 가능한google.gemini-2.5-flash모델을 사용했습니다.
STEP-7. Gold Layer 생성 및 Autonomous AI Lakehouse 적재
7-1. AIDP 에서 Autonomous AI Lakehouse External Catalog 생성
최종적으로 분석에 활용할 Gold Layer 의 데이터를 저장하기 위해 AI Lakehouse 데이터베이스를 External Catalog 로 등록합니다.
AIDP Console 에서 Create -> Catalog 를 선택합니다.
- Catalog Name:
airlines_external_adb_gold_xx - Catalog Type:
External Catalog - External Source Type:
Oracle Autonomous Data Warehouse - Target Instance:
aidp-db - Connection Type:
aidpdb_medium - User:
GOLD_XX
Test Connection 이 성공하면 Catalog 를 생성합니다.
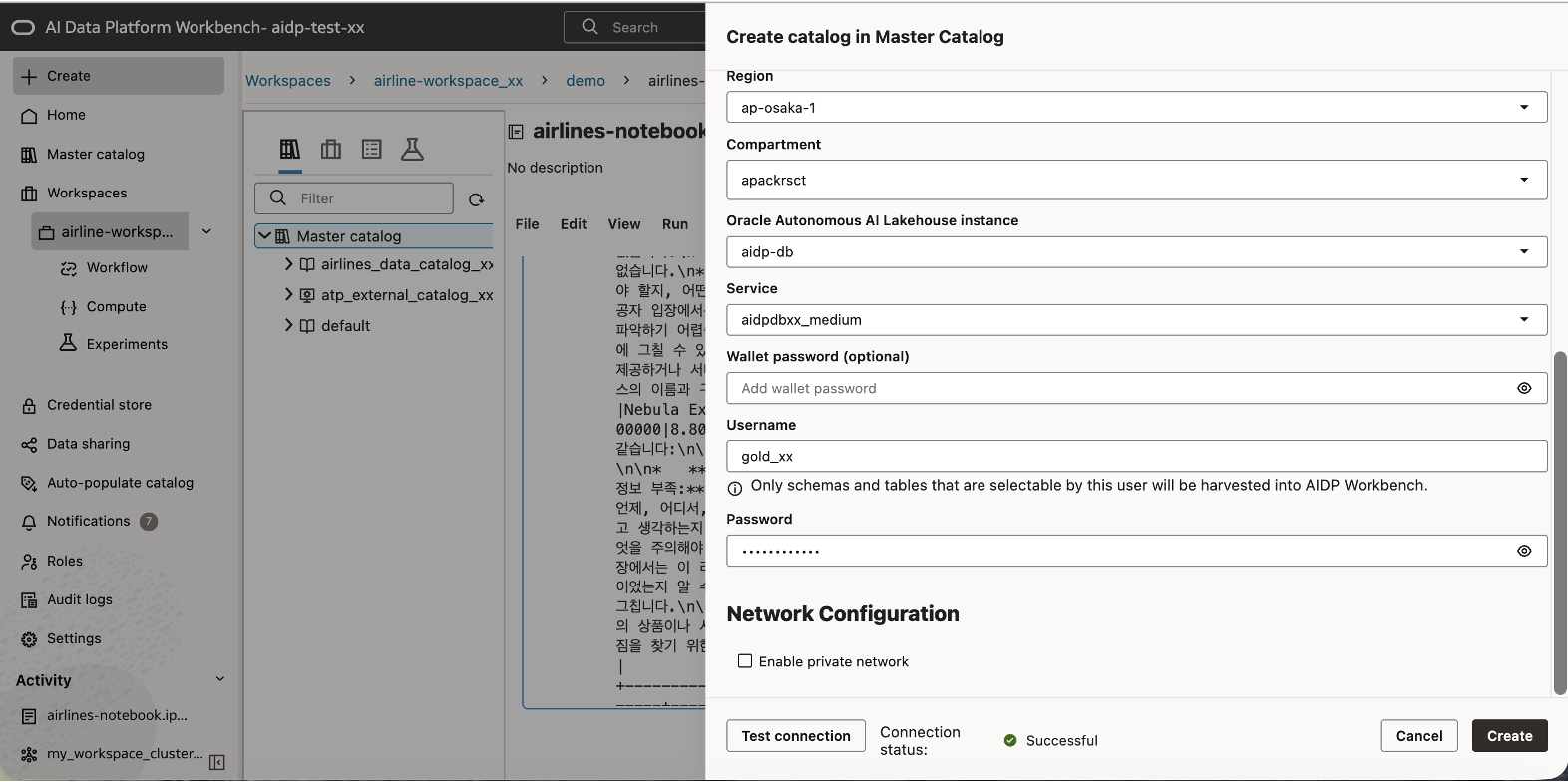
7-2. AIDP Gold Delta Table 생성
AIDP ‘airlines-notebook.ipynb’ Notebook 으로 돌아와 Gold Delta Table 을 생성합니다.
gold_path = "oci://aidp-demo-bucket_xx@your-os-namespace/delta/gold/airline_sample_avg"
gold_table = "airlines_data_catalog_xx.gold.airline_sample_avg"
spark.sql("CREATE SCHEMA IF NOT EXISTS airlines_data_catalog_xx.gold")
enhanced_df.write.format("delta") \
.option("mergeSchema", "true") \
.mode("overwrite") \
.save(gold_path)
spark.sql(f"DROP TABLE IF EXISTS {gold_table}")
spark.sql(f"""
CREATE TABLE {gold_table}
USING DELTA
LOCATION '{gold_path}'
""")
df_gold = spark.table(gold_table)
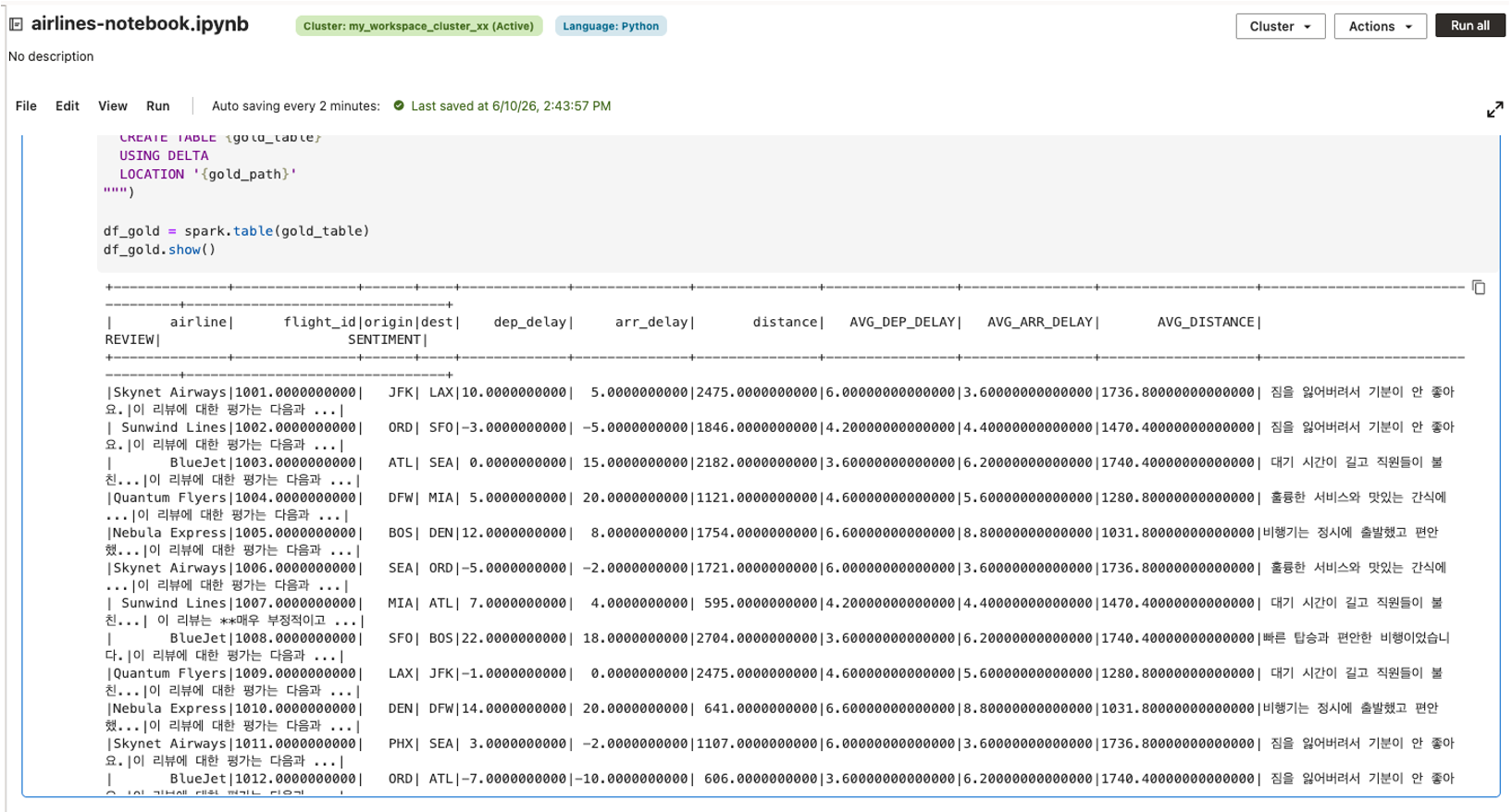
df_gold.show()
아래는 AIDP Notebook 에서 Gold 데이터가 생성된 예시 화면입니다.
7-3. OAC 시각화를 위해 컬럼명 대문자 처리
OAC 에서 컬럼명 대소문자 문제로 시각화 오류가 발생할 수 있으므로, Lakehouse 로 적재하기 전 컬럼명을 대문자로 맞춥니다.
for col_name in df_gold.columns:
df_gold = df_gold.withColumnRenamed(col_name, col_name.upper())
df_gold.show()
데이터 타입도 Autonomous AI Lakehouse 의 Target Table 정의에 맞춥니다.
from pyspark.sql.functions import col
from pyspark.sql.types import DecimalType, StringType
df_gold_typed = (
df_gold
.withColumn("FLIGHT_ID", col("FLIGHT_ID").cast(DecimalType(38, 10)))
.withColumn("DEP_DELAY", col("DEP_DELAY").cast(DecimalType(38, 10)))
.withColumn("ARR_DELAY", col("ARR_DELAY").cast(DecimalType(38, 10)))
.withColumn("DISTANCE", col("DISTANCE").cast(DecimalType(38, 10)))
.withColumn("AVG_DEP_DELAY", col("AVG_DEP_DELAY").cast(DecimalType(38, 10)))
.withColumn("AVG_ARR_DELAY", col("AVG_ARR_DELAY").cast(DecimalType(38, 10)))
.withColumn("AVG_DISTANCE", col("AVG_DISTANCE").cast(DecimalType(38, 10)))
.withColumn("AIRLINE", col("AIRLINE").cast(StringType()))
.withColumn("ORIGIN", col("ORIGIN").cast(StringType()))
.withColumn("DEST", col("DEST").cast(StringType()))
.withColumn("REVIEW", col("REVIEW").cast(StringType()))
.withColumn("SENTIMENT", col("SENTIMENT").cast(StringType()))
)
col_order = [
"FLIGHT_ID", "AIRLINE", "ORIGIN", "DEST",
"DEP_DELAY", "ARR_DELAY", "DISTANCE",
"AVG_DEP_DELAY", "AVG_ARR_DELAY", "AVG_DISTANCE",
"REVIEW", "SENTIMENT"
]
df_gold_typed = df_gold_typed.select(col_order)
df_gold_typed.createOrReplaceTempView("df_gold")
7-4. Autonomous AI Lakehouse 에 Gold Table 생성
Autonomous AI Lakehouse 의 SQL Developer Web 에 GOLD_XX 사용자로 접속한 뒤 아래 테이블을 생성합니다.
CREATE TABLE airline_sample_gold (
flight_id NUMBER,
airline VARCHAR2(30),
origin VARCHAR2(3),
dest VARCHAR2(3),
dep_delay NUMBER,
arr_delay NUMBER,
distance NUMBER,
avg_dep_delay NUMBER,
avg_arr_delay NUMBER,
avg_distance NUMBER,
review VARCHAR2(4000),
sentiment VARCHAR2(10000)
);
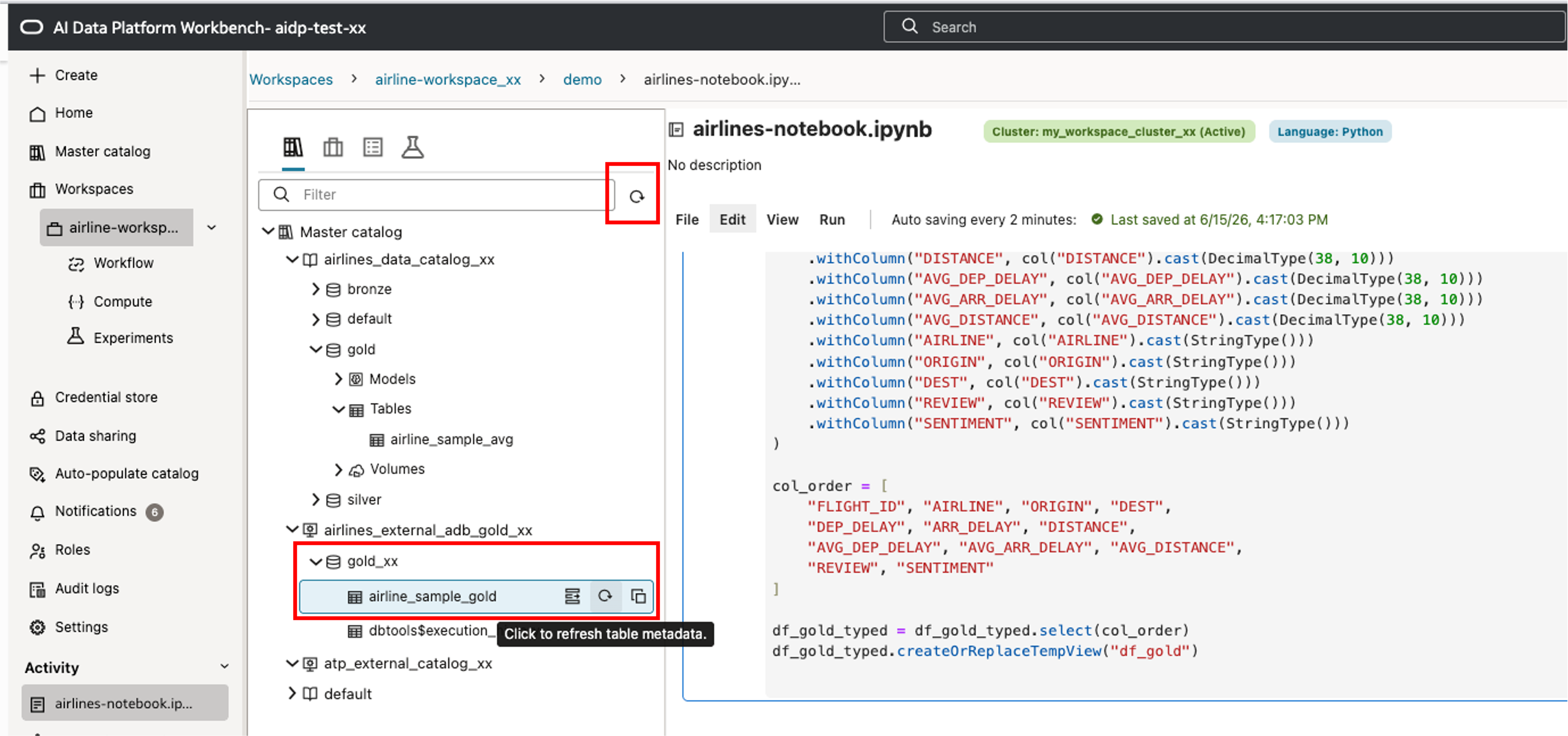
테이블 생성 후 반드시 AIDP 의 airlines_external_adb_gold_xx External Catalog 를 Refresh 하여 새 테이블이 보이도록 합니다.
7-5. Gold 데이터를 Lakehouse Table 에 Insert
AIDP Notebook 에서 SQL 셀을 생성하고 아래 SQL 을 수행합니다.
%sql
INSERT INTO airlines_external_adb_gold_xx.gold_xx.airline_sample_gold
SELECT * FROM df_gold
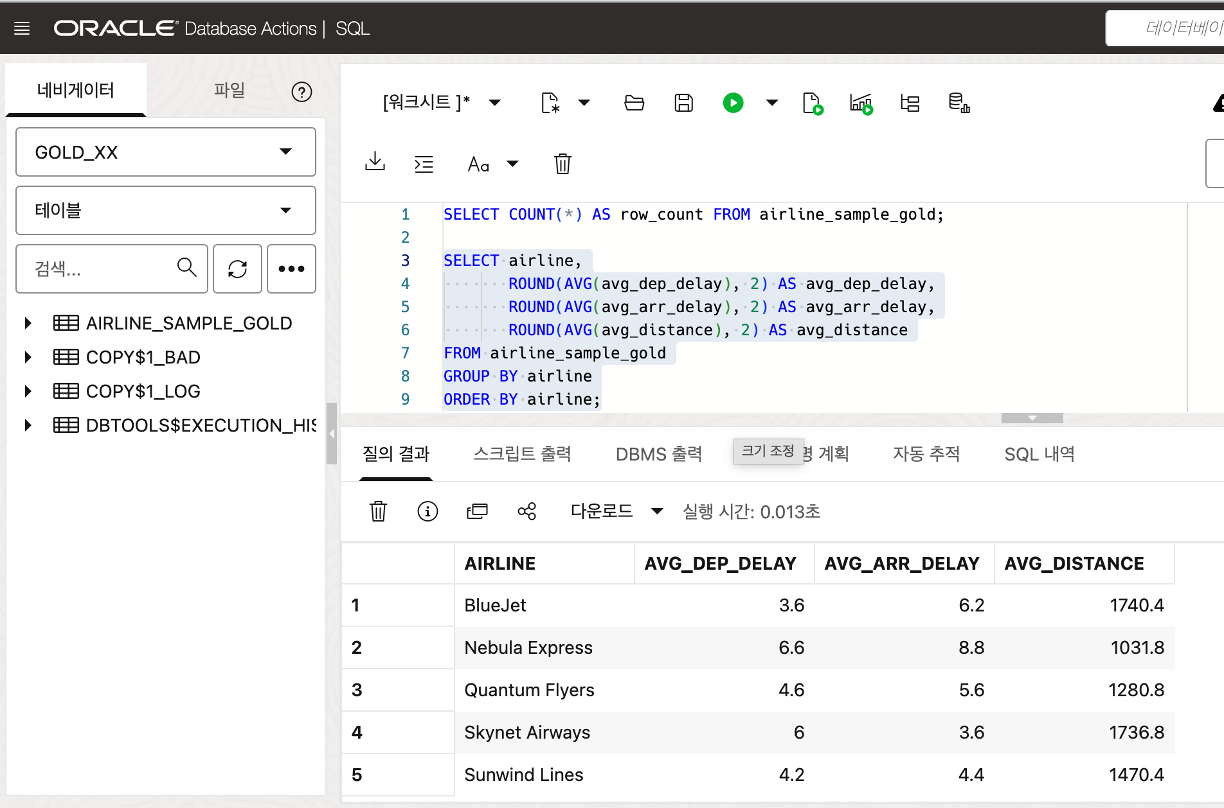
적재 후 Autonomous AI Lakehouse 에서 아래와 같이 데이터를 확인합니다.
SELECT COUNT(*) AS row_count FROM airline_sample_gold;
SELECT airline,
ROUND(AVG(avg_dep_delay), 2) AS avg_dep_delay,
ROUND(AVG(avg_arr_delay), 2) AS avg_arr_delay,
ROUND(AVG(avg_distance), 2) AS avg_distance
FROM airline_sample_gold
GROUP BY airline
ORDER BY airline;
중요
- Spark native insert 방식으로 적재할 때 컬럼명이 소문자로 밀려 OAC 시각화에 문제가 생길 수 있습니다.
- 본 Hands-on 에서는 SQL
INSERT INTO ... SELECT방식으로df_goldTemp View 를 적재하는 흐름을 사용합니다. - Lakehouse External Catalog 에 방금 생성한 Table 이 보이지 않으면 Catalog Refresh 를 먼저 수행합니다.
STEP-8. Oracle Analytics Cloud 에서 Gold 데이터 분석
이번 STEP 에서는 Gold Layer 로 정제된 데이터를 기반으로 시각화하여 분석할 수 있는 Oracle Analytics Cloud 기반으로 Gen AI 를 연동하여 분석을 실습해 보는 단계입니다.
8-1. Autonomous AI Lakehouse Wallet 다운로드
분석을 수행할 Gold Layer 데이터가 저장된 DB 인 AI Lakehouse 타입으로 생성했던 ‘aidp-db’ 의 Autonomous AI Lakehouse 상세 화면에서 Database connection 메뉴로 이동하여 Instance Wallet 을 다운로드합니다. OAC 에서 Autonomous AI Lakehouse Connection 을 생성할 때 Wallet 파일을 사용합니다.
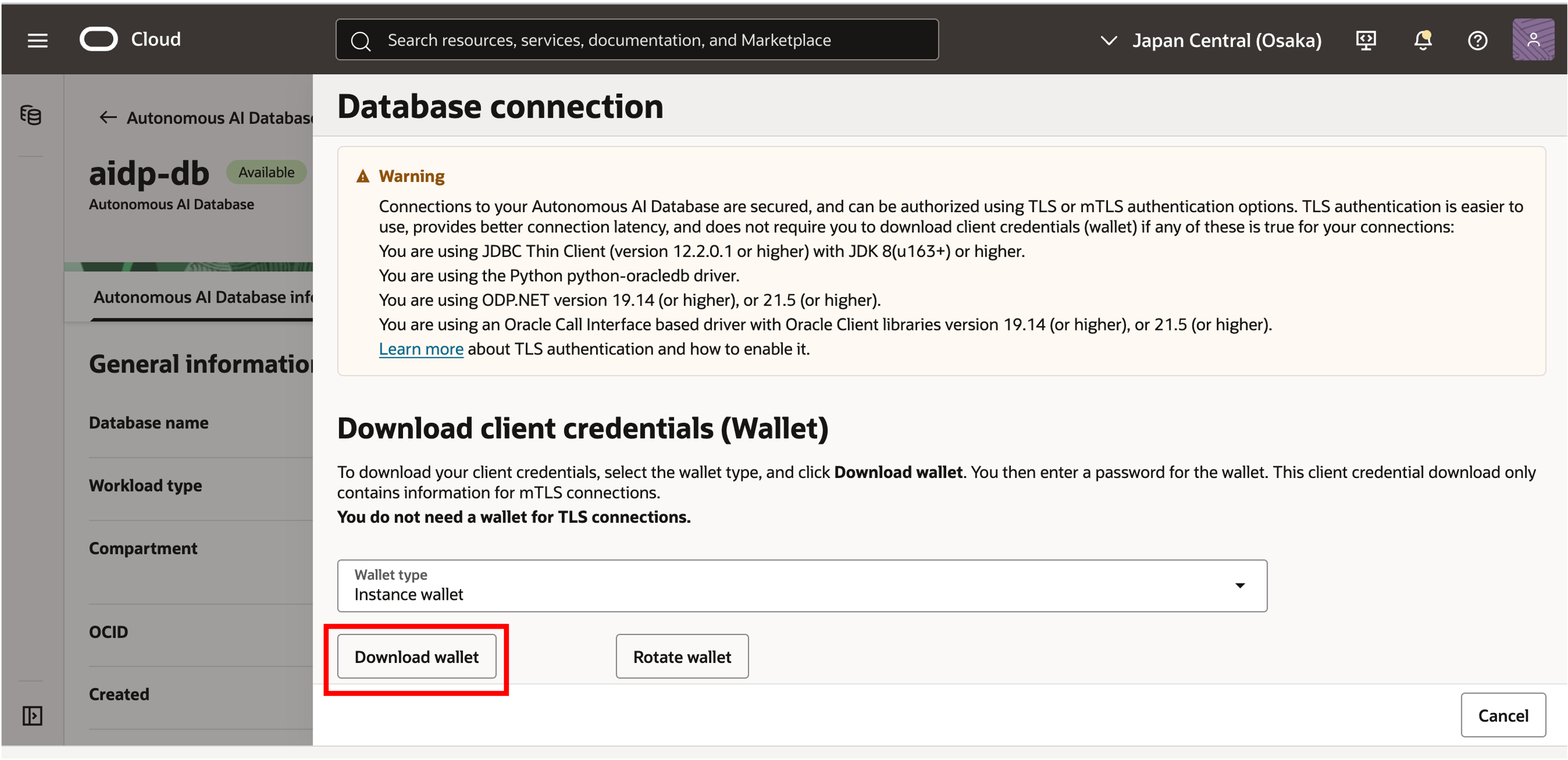
Wallet 에 대한 Password 도 입력하여 Wallet 파일을 다운로드 받습니다.
8-2. OAC Connection 및 Dataset 생성
OAC 인스턴스의 Analytics Home Page 를 엽니다.
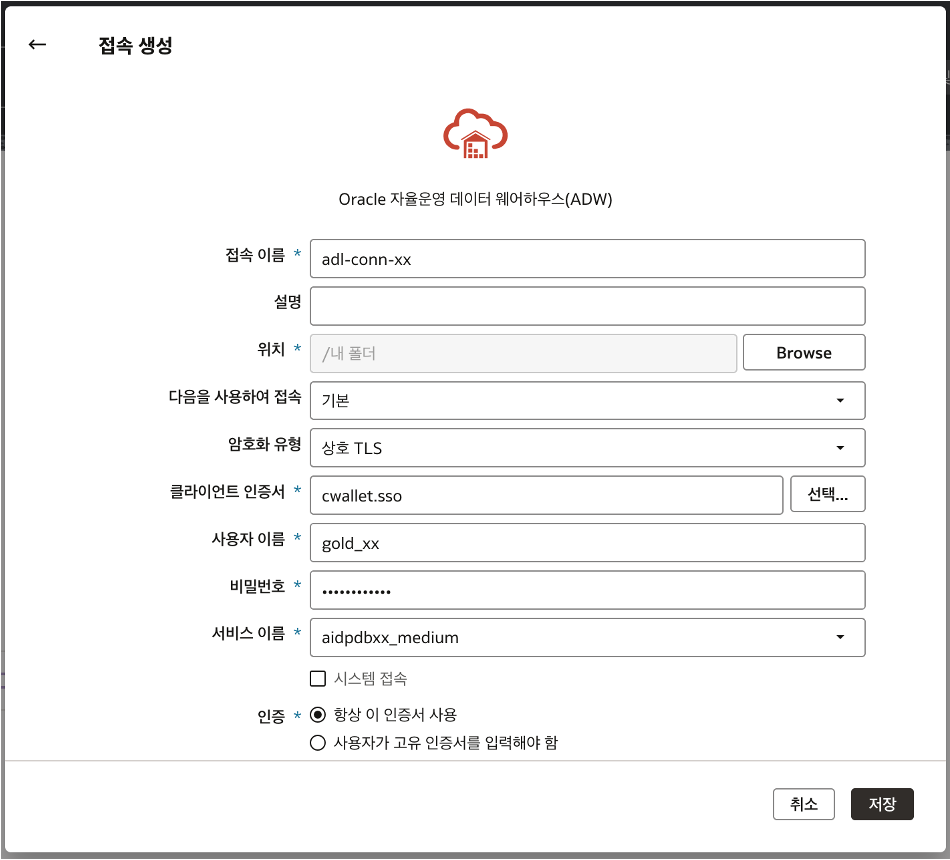
Create->Connection선택Oracle Autonomous Warehouse선택- Connection Name:
adl-conn-xx - Wallet 파일 업로드
- User:
GOLD_XX - Password:
GOLD_XX사용자 패스워드
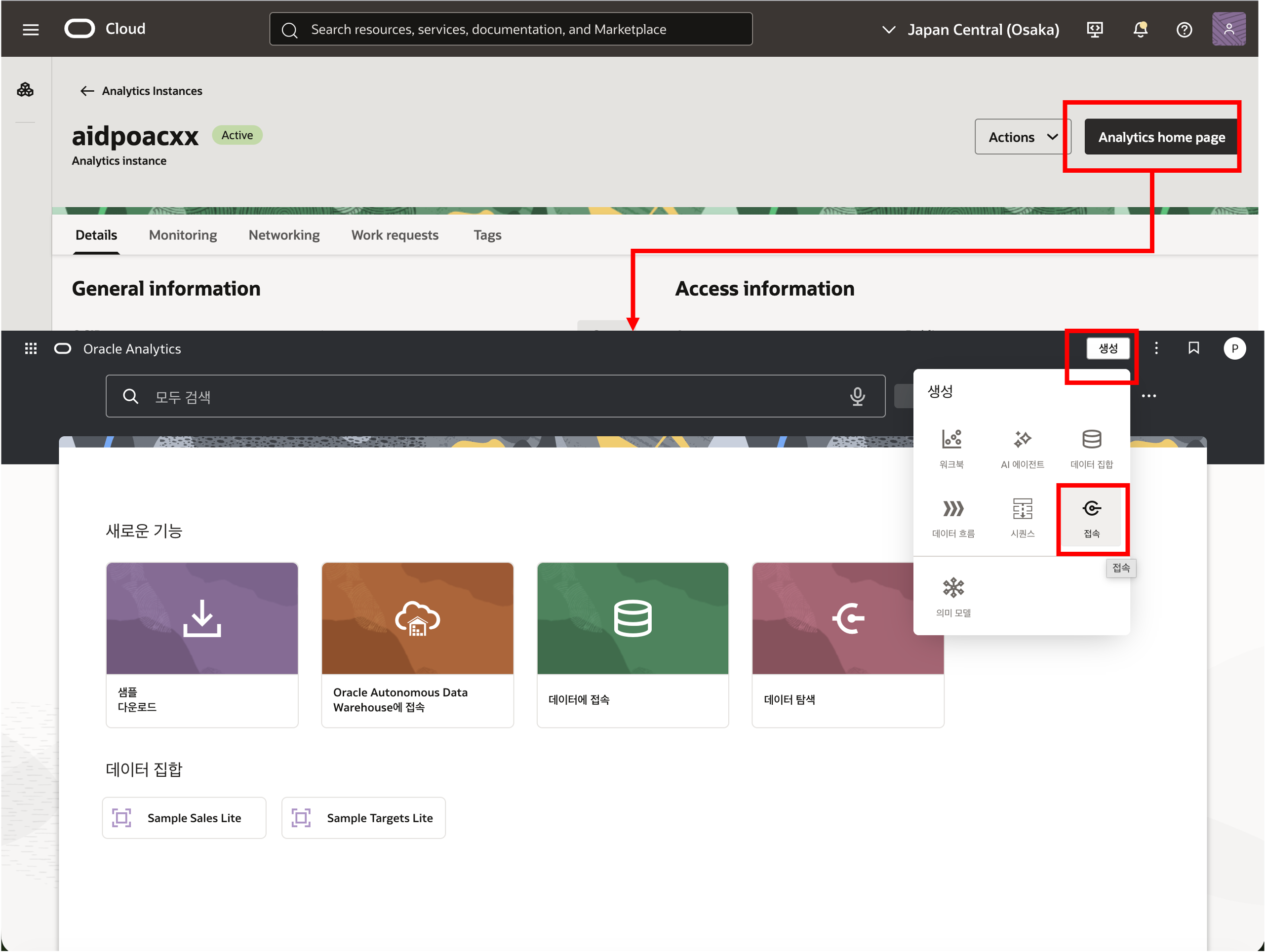
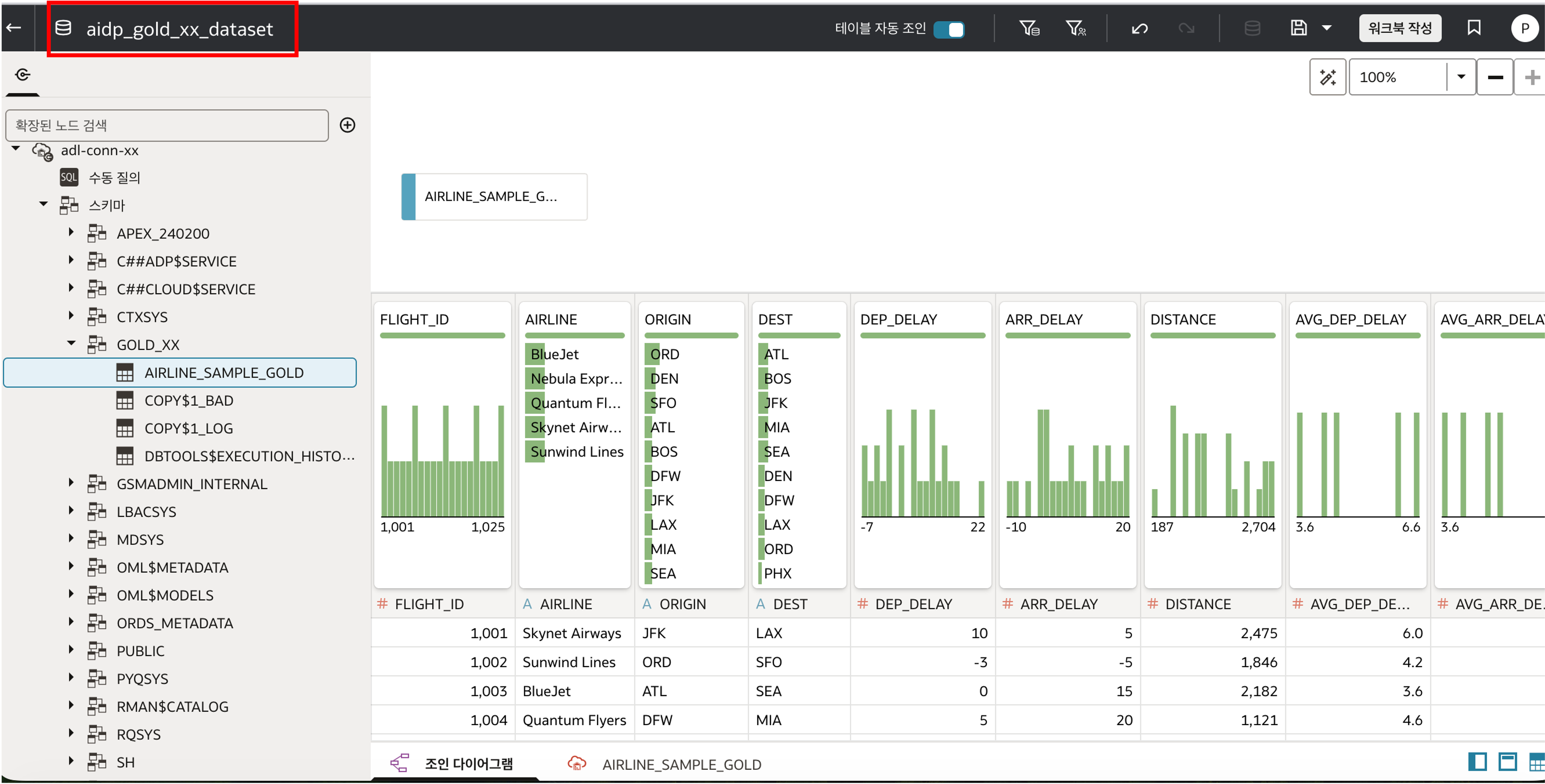
Connection 생성 후 Create -> Dataset 을 선택하고 adl-conn-xx 연결을 이용하여 GOLD_XX.AIRLINE_SAMPLE_GOLD 테이블을 Dataset 으로 저장합니다.
- Dataset Name:
aidp_gold_xx_dataset
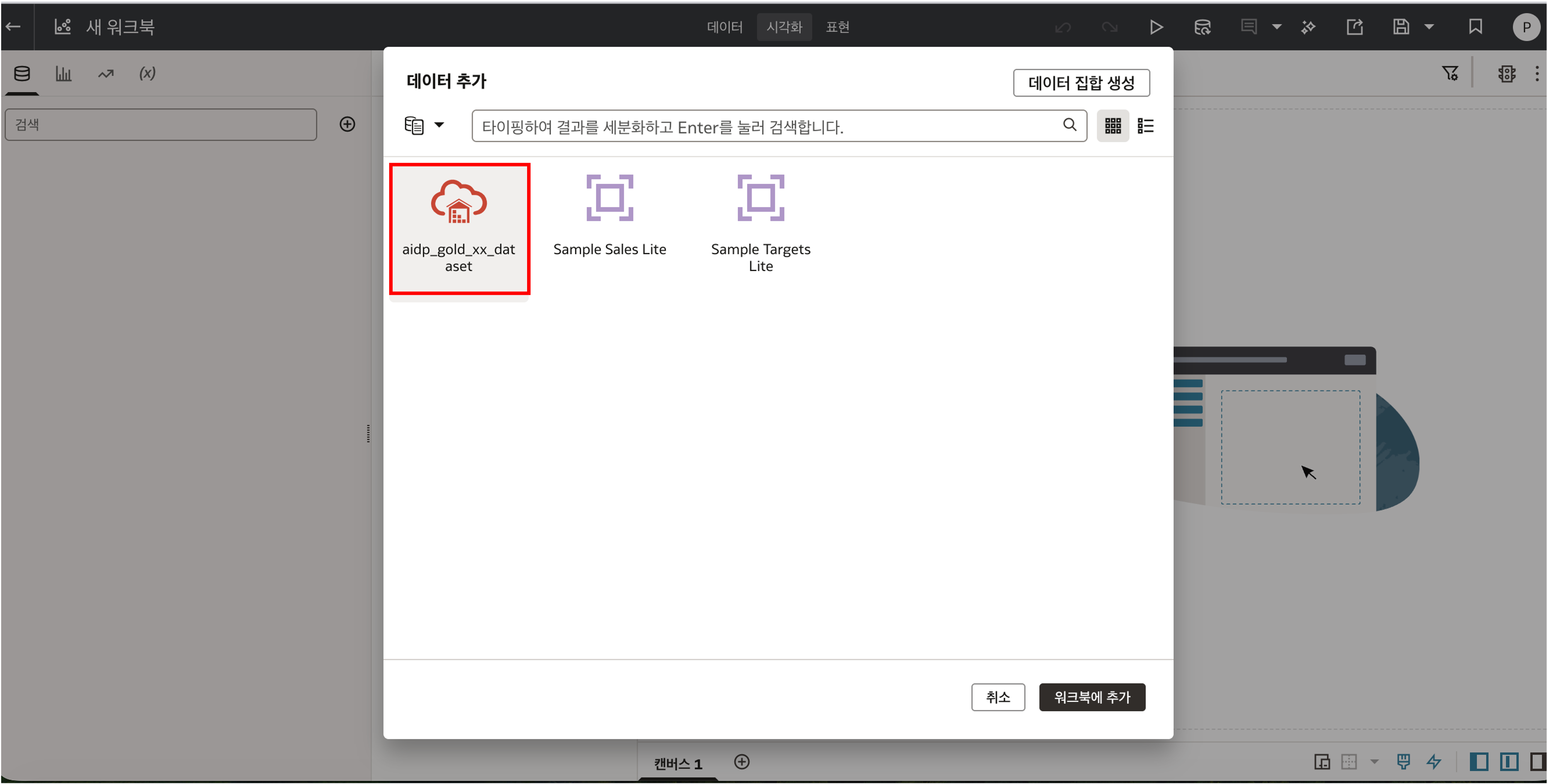
8-3. OAC Workbook 생성
OAC 에서 Create -> Workbook 을 선택하고 방금 만든 Dataset 을 추가합니다.
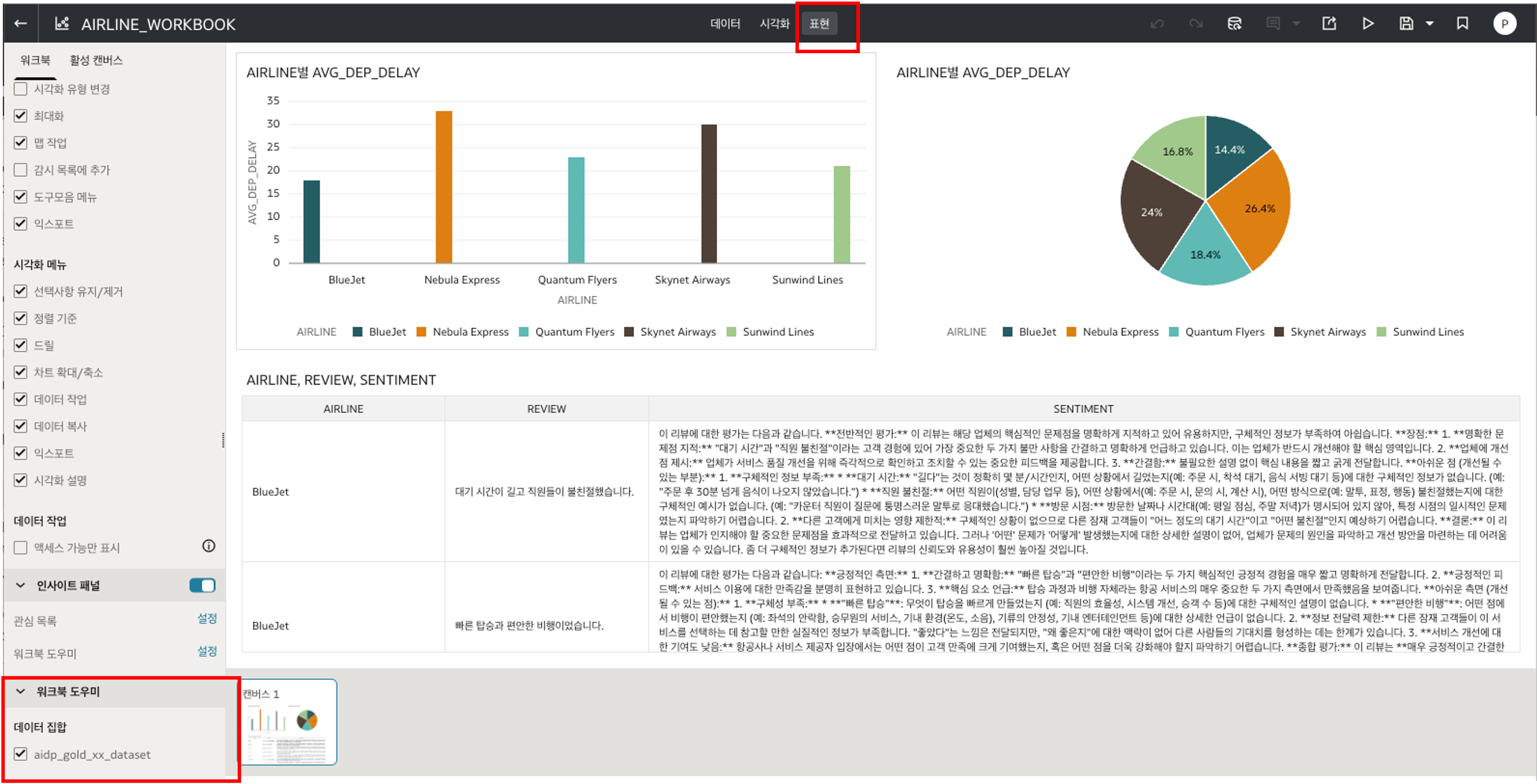
예시로 아래 시각화를 구성합니다. OAC 의 캔버스에 Drag 를 해서 Pie Chart, Bar Chart, Table 형태로 화면을 구성합니다.
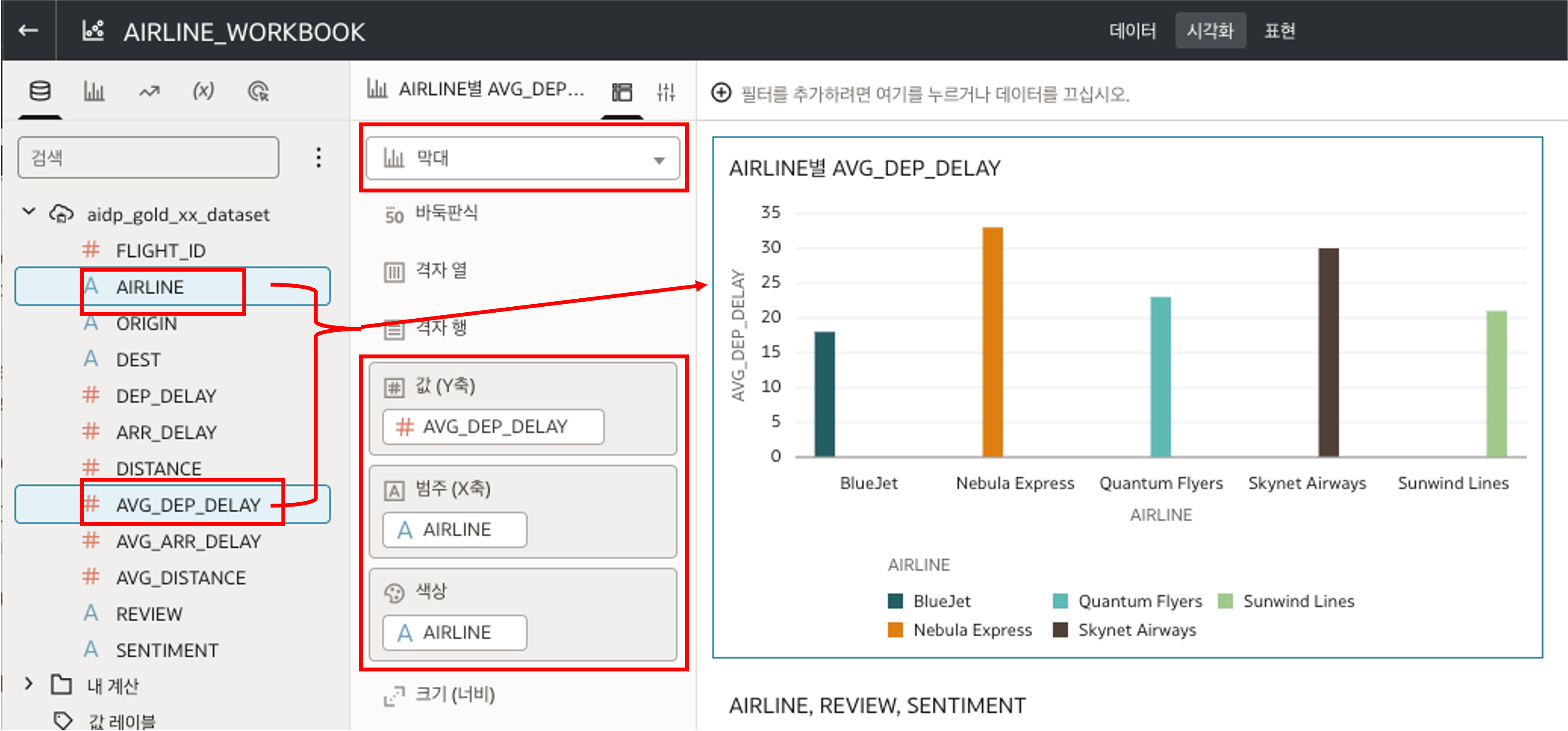
- Bar Chart:
AVG_DEP_DELAYbyAIRLINE
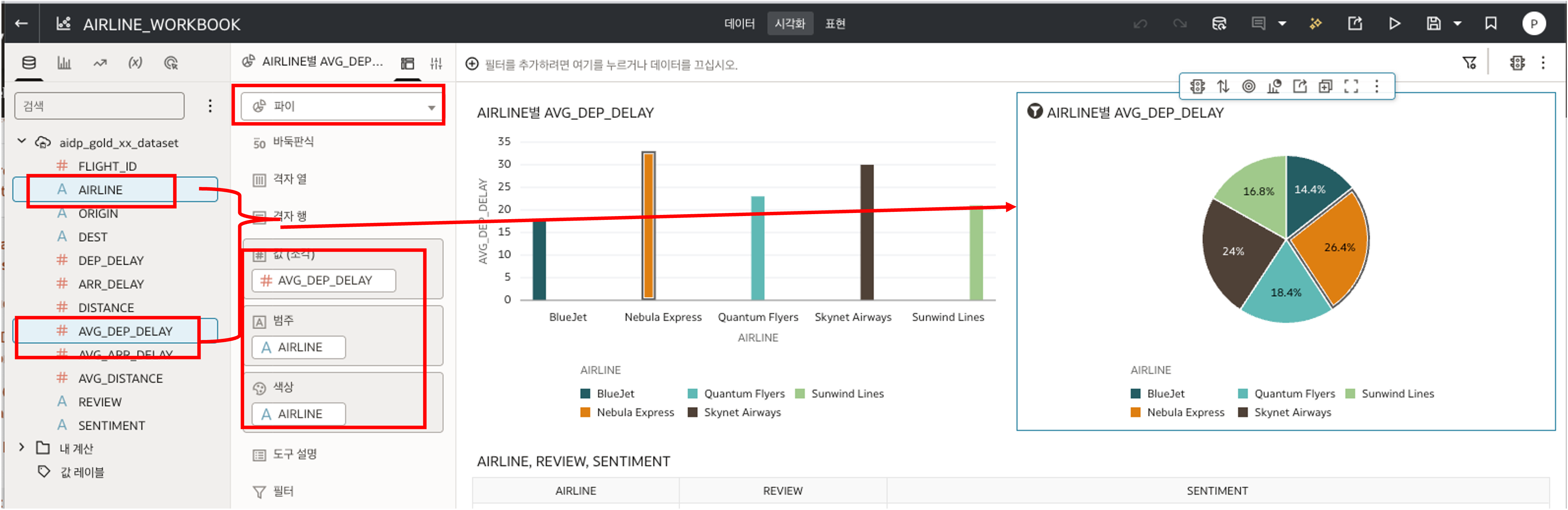
- Pie Chart:
AVG_DEP_DELAYbyAIRLINE
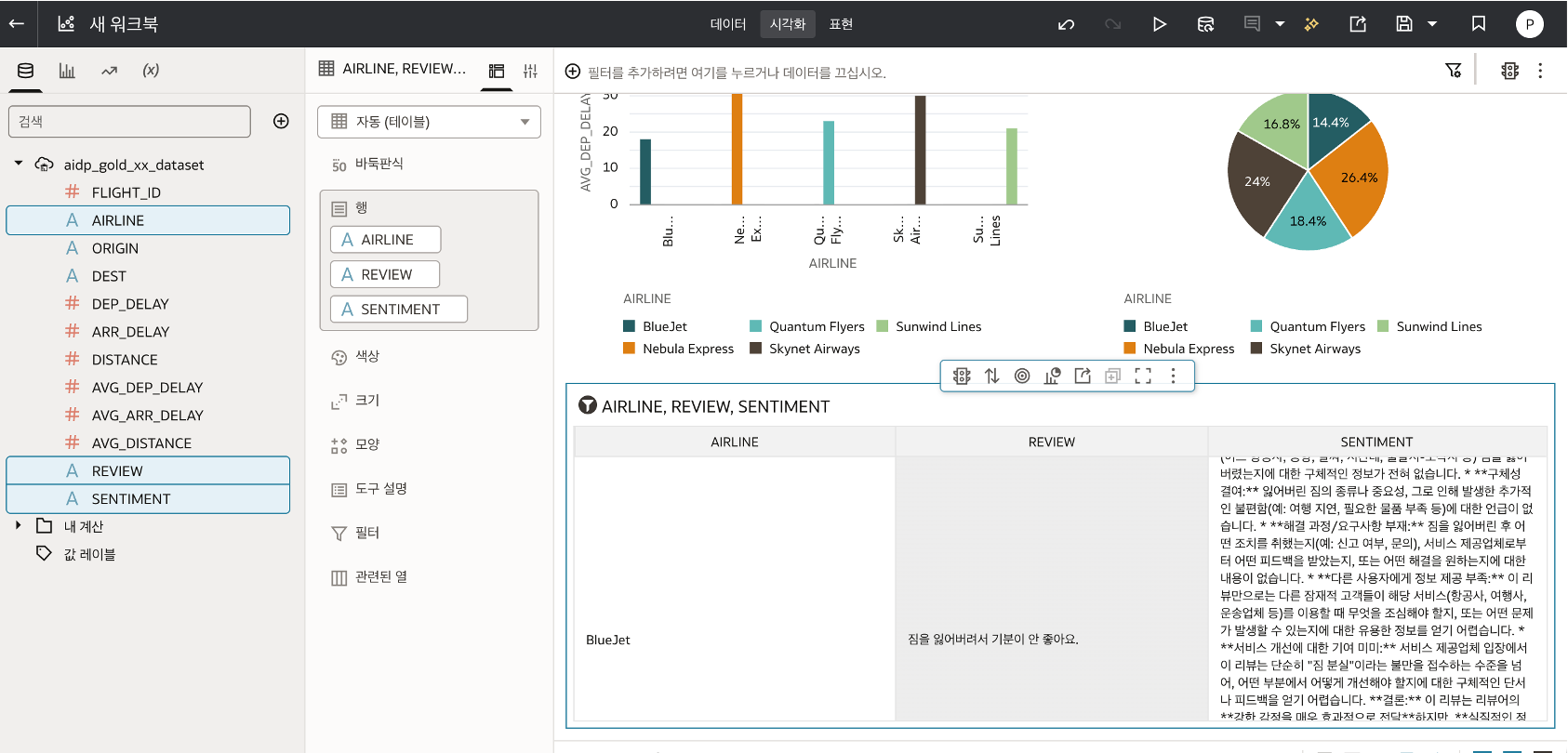
- Table:
AIRLINE,REVIEW,SENTIMENT
구성이 완료되면 아래와 같이 항공사별 지연 시간과 감성 분석 결과를 하나의 Workbook 에서 확인할 수 있습니다.
8-4. OAC Assistant 활성화 및 Dataset Indexing
OAC 의 Console -> Generative AI 메뉴에서 Assistant 관련 기능이 활성화되어 있는지 확인합니다.
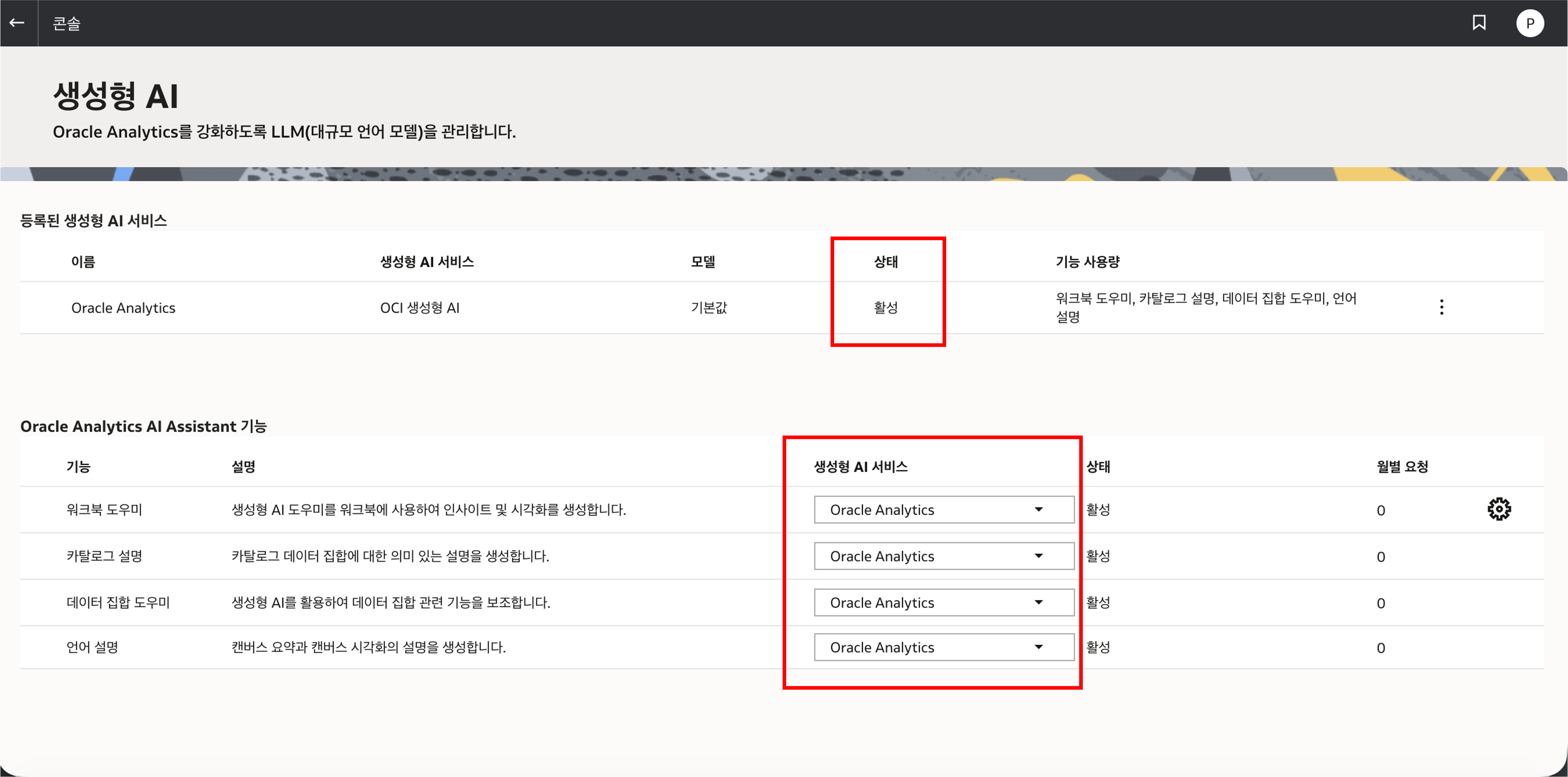
이후 Data 메뉴에서 Dataset 을 Inspect 하고, Search 설정에서 Assistant 와 Homepage Search 를 위한 Index 를 생성합니다.
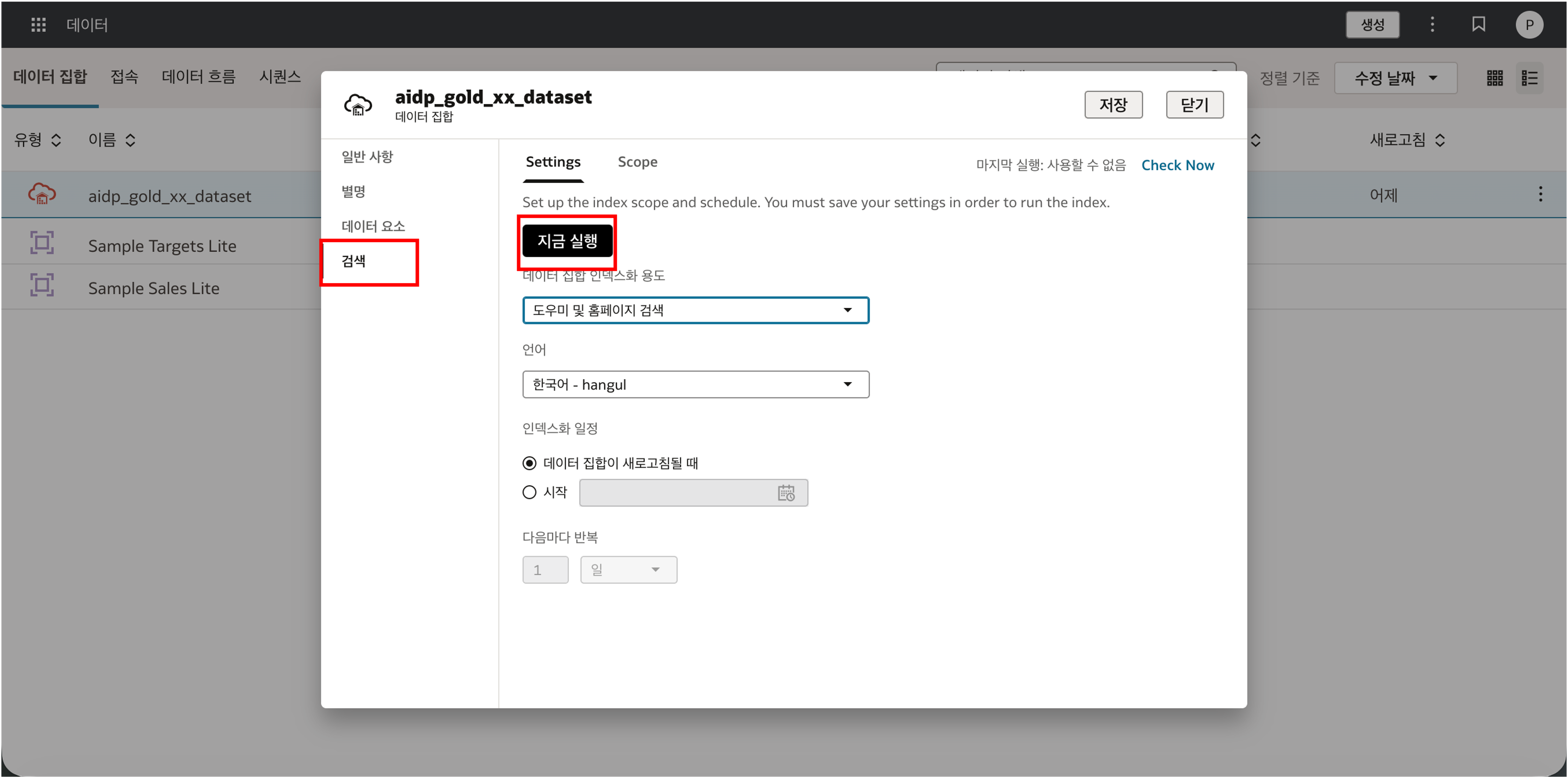
Indexing 이 완료되면 자연어로 질의가 가능하게 됩니다.
Workbook 의 Present 설정에서 Workbook Assistant 를 켜고 aidp_gold_xx_dataset 이 선택되어 있는지 확인합니다. 선택이 되어 있지 않을 경우 Workbook Assistant 의 해당 데이터 셋을 체크합니다.
이제 상단의 자동 인사이트 버튼을 클릭하면 Workbook 에서 아래 화면과 같이 Assistant 를 열고 자연어로 질문할 수 있습니다.
예시 질문:
항공사별 평균 출발 지연 시간을 보여줘.
아래와 같이 OAC Assistant 가 GenAI LLM 과 연동하여 자연어 질의를 기반으로 분석 결과를 생성합니다.
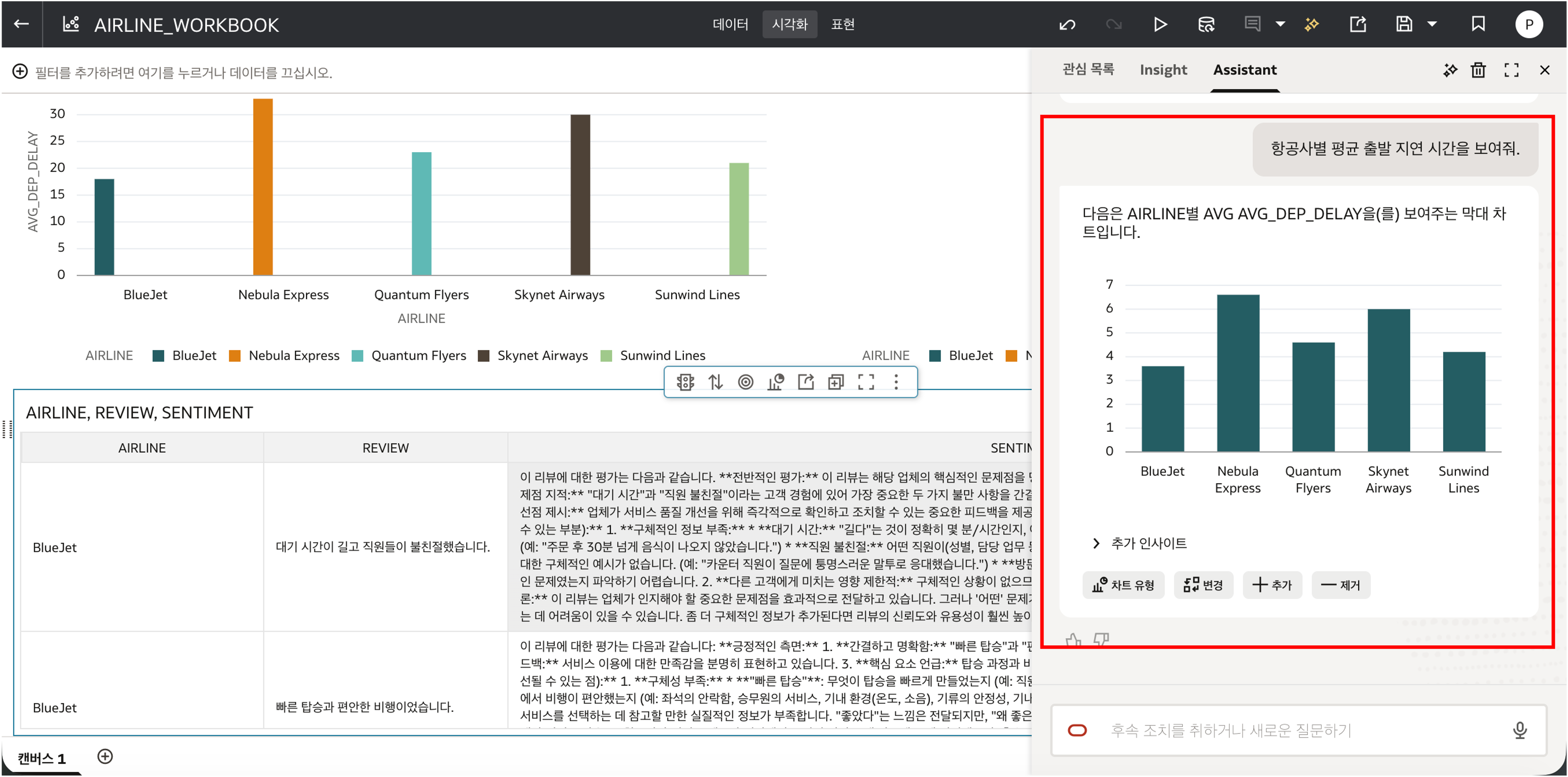
상기 화면과 같이 정상적으로 자연어 기반의 분석 화면이 제대로 표현이 되었다면, 이 Hands-On Lab 의 모든 과정이 정상적으로 수행된 것입니다. 수고하셨습니다.
문제 해결(트러블슈팅) 체크리스트
- AIDP External Catalog 연결 실패
- ATP 또는 Autonomous AI Lakehouse 의 Access Type, 사용자 패스워드, Wallet/Connection Type 을 확인합니다.
SOURCE_XX,GOLD_XX사용자에 REST 접근과 Quota Unlimited 설정이 되어 있는지 확인합니다.
- Object Storage 경로 오류
oci://bucket@namespace/path형식의 Bucket Name 과 Namespace 를 확인합니다.aidp-demo-bucket_xx에서 하이픈(-)과 언더스코어(_)를 혼동하지 않았는지 확인합니다.- 일시적인
Unable to determine if path is a directory오류는 동일 셀 재실행 또는 Cluster 재시작으로 해결되는 경우가 있습니다.
- Delta Table 생성 오류
- 하나의 Delta 경로를 여러 Table 에 중복 등록하지 않았는지 확인합니다.
- 테스트를 반복하는 경우
DROP TABLE IF EXISTS후 다시 생성합니다.
- Generative AI 모델 오류
query_model의 모델명이 현재 Region 에서 지원되는지 AIDP Model Catalog 에서 확인합니다.- 모델 경로에 불필요한 prefix 가 붙어 있다면 실제 사용 가능한 모델명만 지정합니다.
- Gold Table Insert 오류
- Autonomous AI Lakehouse 에
AIRLINE_SAMPLE_GOLD테이블을 먼저 생성했는지 확인합니다. - AIDP 의
airlines_external_adb_gold_xxExternal Catalog 를 Refresh 했는지 확인합니다. df_goldTemp View 가 생성되어 있는지 확인합니다.
- Autonomous AI Lakehouse 에
- OAC 시각화 오류
- Gold 데이터 적재 전 컬럼명이 모두 대문자인지 확인합니다.
- OAC Dataset 을 다시 로드하거나 Dataset 캐시를 갱신합니다.
- Wallet, Connection 사용자, Schema 권한을 확인합니다.
리소스 정리
Hands-on 후 더 이상 사용하지 않는 경우 아래 리소스를 정리합니다.
- OAC 인스턴스
aidpoacxx - AIDP 인스턴스
aidp-test-xx - Autonomous AI Lakehouse
aidp-db - ATP 인스턴스
airline-source-atp - Object Storage Bucket
aidp-demo-bucket_xx - Compartment
aidp-lab-xx
주의
- Object Storage Bucket 을 삭제하기 전, 내부 Object 와 Folder 를 먼저 삭제해야 합니다.
- 공유 Tenancy 에서 실습한 경우 본인이 생성한
_XX접미사의 리소스만 삭제합니다.
마무리
이번 블로그에서는 Oracle AI Data Platform 을 중심으로 ATP 원천 데이터, Object Storage 기반 Delta Lake, Autonomous AI Lakehouse Gold Table, Oracle Analytics Cloud Workbook 과 Assistant 까지 연결하는 Lakehouse 분석 Hands-on 을 정리했습니다.
이 흐름을 응용하면 운영성 데이터베이스의 데이터를 AIDP 에서 Spark/Delta 기반으로 정제하고, AI 분석 결과를 추가한 뒤, Autonomous AI Lakehouse 와 OAC 를 통해 분석 사용자에게 빠르게 제공할 수 있습니다. 특히 Bronze/Silver/Gold 레이어를 명확히 나누면 데이터 품질 관리, 재처리, 분석 재사용성이 좋아지므로 실제 프로젝트에서도 유용한 패턴으로 활용할 수 있습니다.
이 글은 개인적으로 얻은 지식과 경험을 작성한 글로 내용에 오류가 있을 수 있습니다. 또한 글 속의 의견은 개인적인 의견으로 특정 회사를 대변하지 않습니다.
Phillsoo Lim DATAPLATFORM
oci ai-data-platform aidp autonomous-ai-lakehouse oac lakehouse spark delta-lake