CloudNative
OKE Generic VNIC Attachment로 Pod Density 테스트
Table of Contents
소개
OKE(Oracle Kubernetes Engine)는 OCI VCN-Native Pod Networking CNI를 통해 Pod가 OCI VCN의 IP를 직접 사용할 수 있습니다. 이 방식은 Pod IP가 VCN 네트워크 안에서 직접 라우팅되기 때문에 OCI Load Balancer, Security List, NSG, Route Table 같은 네트워크 기능과 자연스럽게 연동되는 장점이 있습니다.
하지만 대규모 Pod를 한 노드에 배치하려는 경우에는 Worker Node가 확보할 수 있는 Pod IP 수가 중요한 제약이 됩니다. 기존 OKE VCN-Native Pod Networking에서는 Pod 네트워킹이 사실상 단일 Secondary VNIC 중심이었고, 노드당 가능한 Pod 수는 110개였습니다. 더 많은 Pod를 수용하기 위해서는 노드 수를 늘리는 방법을 사용해야 했는데, 이는 노드 관리 비용, 시스템 Pod 오버헤드, 업그레이드/패치 범위, IP 운영 복잡도도 함께 증가했습니다.
2026년 5월 발표된 OKE의 Generic VNIC Attachment(GVA) 기능은 하나의 Node Pool에 여러 Secondary VNIC Profile을 연결할 수 있게 해주는 기능입니다. 각 Secondary VNIC Profile은 독립적인 Subnet, NSG, IP Count를 가질 수 있고, 노드당 최대 256개의 Pod를 수용할 수 있어 적은 노드로도 더 많은 Pod를 운영할 수 있습니다. 또한 Application Resource를 활용하면 Kubernetes Scheduler 단계에서 특정 Pod가 특정 Secondary VNIC Profile을 사용하도록 제어할 수도 있습니다.
이번 포스팅에서는 OKE Cluster를 구성하고, Worker Node 한 대에 8개의 Secondary VNIC를 연결한 뒤, 각 VNIC마다 32개 IP를 할당하여 총 256개 Pod Capacity를 확보하는 과정을 테스트합니다. 마지막으로 Pause Pod 252개(System Pod 4개)를 실제 배포하여 노드당 Pod 수용량을 확인합니다.
GVA는 OCI VCN-Native Pod Networking CNI에서 지원됩니다. Flannel CNI 기반 Cluster에서는 여러 Secondary VNIC을 Pod Networking 용도로 사용할 수 없습니다. 또한 Worker Node Shape의 VNIC 한계, Subnet의 가용 IP, NSG/Security List Rule도 함께 확인해야 합니다.
테스트 구성
이번 테스트의 주요 구성은 다음과 같습니다.
| 항목 | 값 |
|---|---|
| Cluster type | OKE Cluster, VCN-Native Pod Networking |
| System Node Pool | system-pool |
| Application Node Pool | largescale-pool1 |
| Worker Shape | VM.Standard.E5.Flex |
| Application Node Pool OCPU / Memory | 12 OCPU / 24 GB |
| Application Node Count | 1 |
| GVA Secondary VNIC Profile Count | 8 |
| IP Count per VNIC Profile | 32 |
| Application Resource | pause |
| Target Pod Capacity | 256 |
| Test Deployment Replicas | 252 |
1. Resource Manager로 기본 네트워크 구성
OKE Large Cluster 테스트를 위해 먼저 VCN, Subnet, Route Table, Security Rule 등 기본 네트워크 리소스를 구성합니다. 여기서는 테스트 편의를 위해 Resource Manager Stack 파일을 사용합니다.
Stack 파일은 아래 링크에서 다운로드할 수 있습니다.
OCI Console에서 Developer Services > Resource Manager > Stacks로 이동한 후 Create stack을 클릭합니다. Terraform configuration source는 .Zip file을 선택하고, 앞에서 다운로드한 oke-vcn-stack.zip 파일을 업로드합니다.
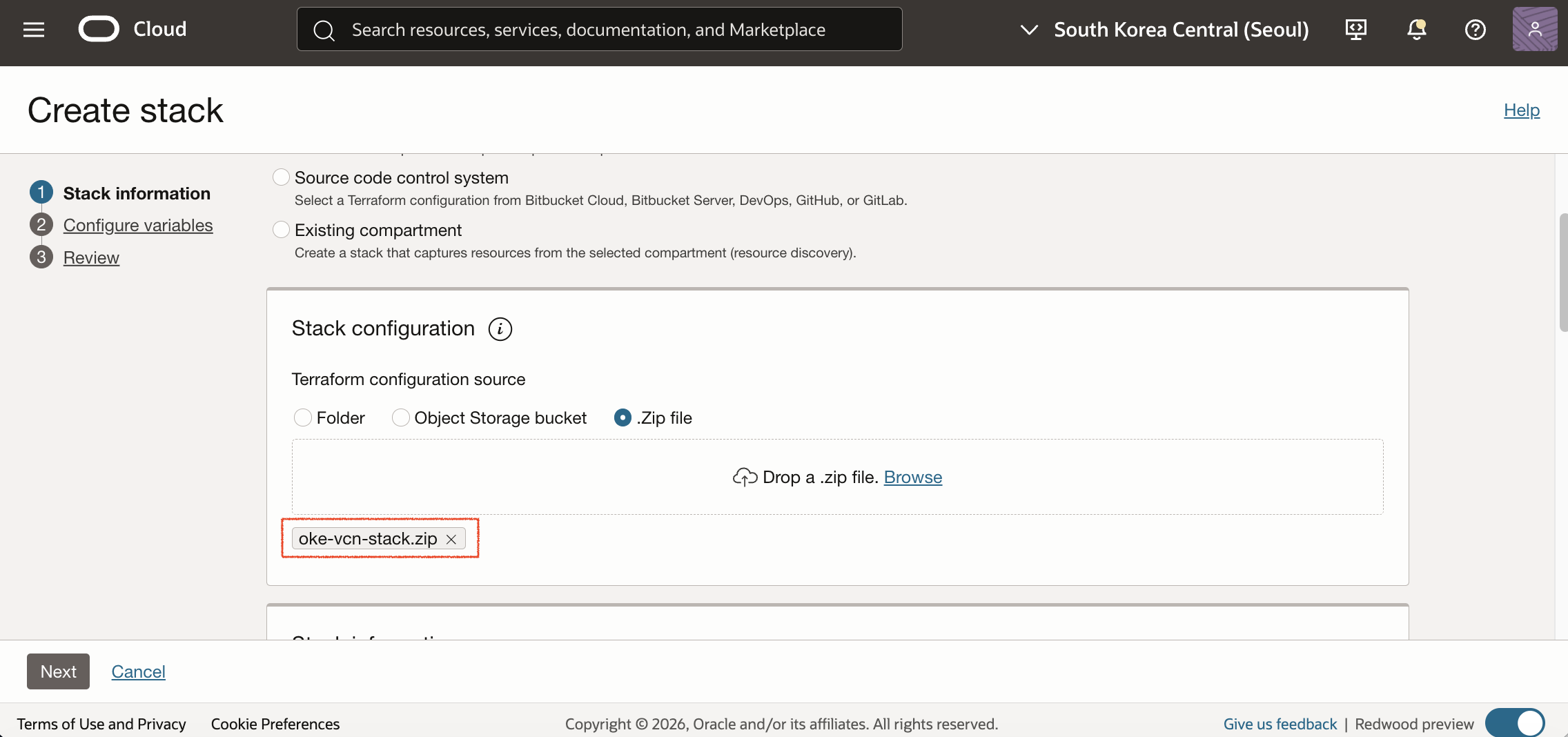
Stack 생성과 함께 바로 실행을 위해 Review 단계 하단에서 Run apply를 체크한 후 Create를 클릭합니다.
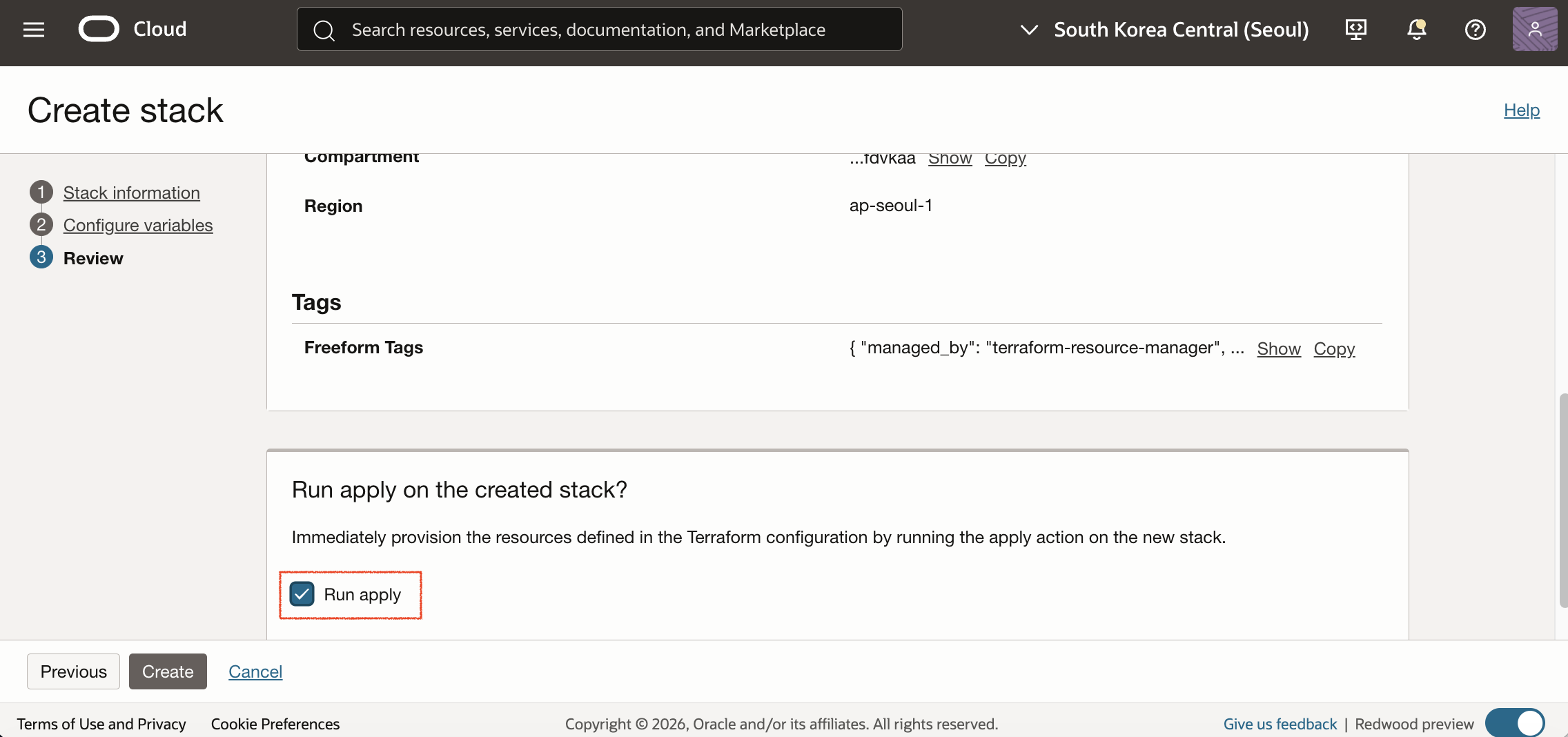
Apply Job의 Logs 탭에서 VCN 리소스가 정상 생성되었는지 확인합니다.
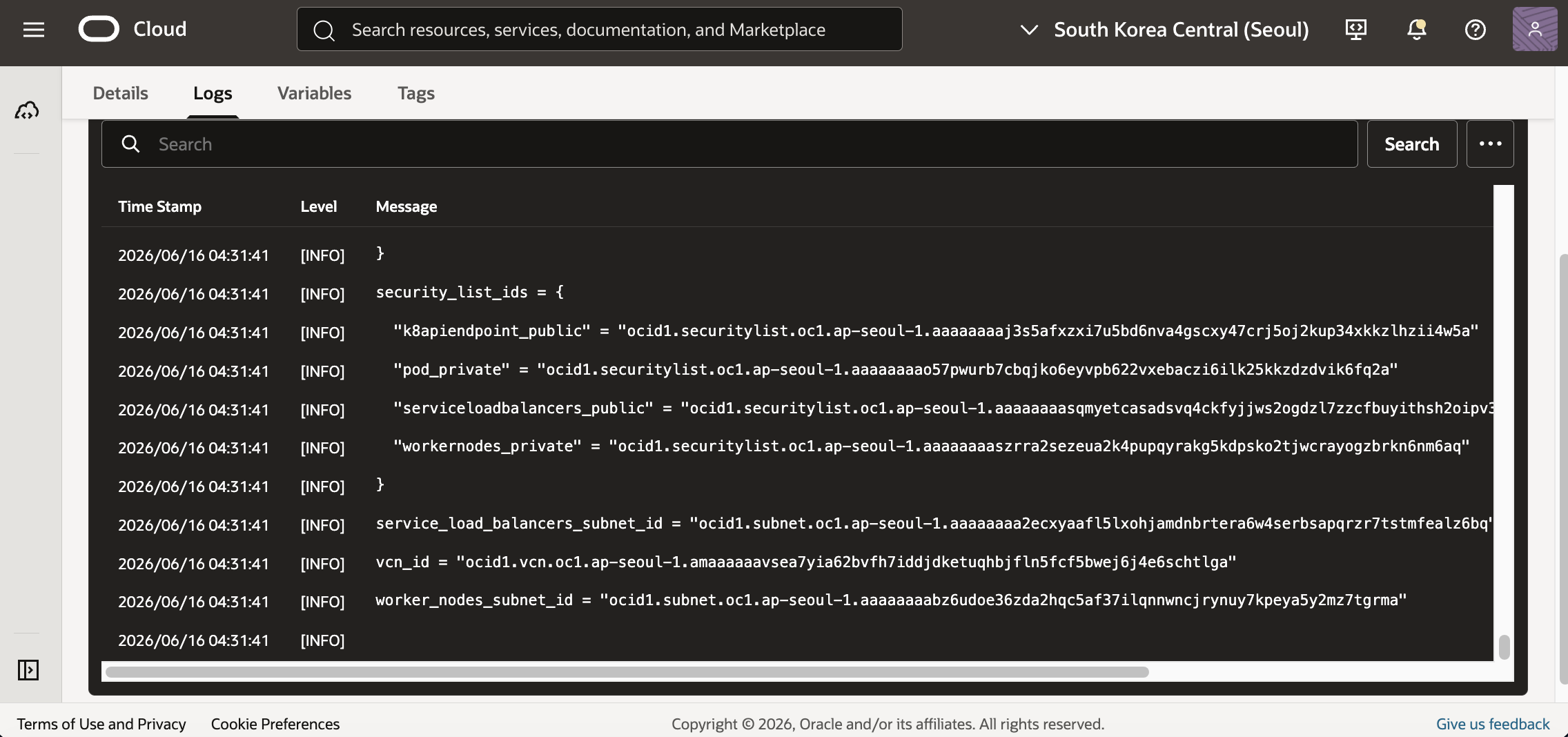
배포가 끝난 뒤 VCN의 Subnets 탭에서 생성된 Subnet을 확인합니다.
Routing 탭에서는 각 Subnet에 연결될 Route Table이 생성된 것을 확인합니다.
마지막으로 Security 탭의 Security List가 생성된 것을 확인합니다. 여기까지 확인되면 OKE Cluster 생성을 위한 기본 네트워크 준비가 끝납니다.
2. OKE Cluster와 system-pool 생성
이제 OKE Cluster를 생성합니다. 앞서 생성한 VCN을 활용할 것이기 때문에 Custom Create 방식으로 생성합니다. Cluster 생성 시 Network Type은 VCN-native pod networking을 사용합니다. 기본 Node Pool은 system-pool이라는 이름으로 생성합니다.
이번 테스트에서 system-pool은 CoreDNS, kube-dns-autoscaler 같은 Cluster System Pod가 배포될 전용 Node Pool 역할을 합니다. 뒤에서 생성할 largescale-pool1은 Application Resource가 설정된 Node Pool이며, 해당 노드에는 oci.oraclecloud.com/application-resource-only:NoSchedule 계열의 Taint가 적용됩니다. 따라서 일반 System Pod(특히 CoreDNS)가 largescale-pool1에 스케줄링되지 않도록 system-pool을 분리해서 구성합니다.
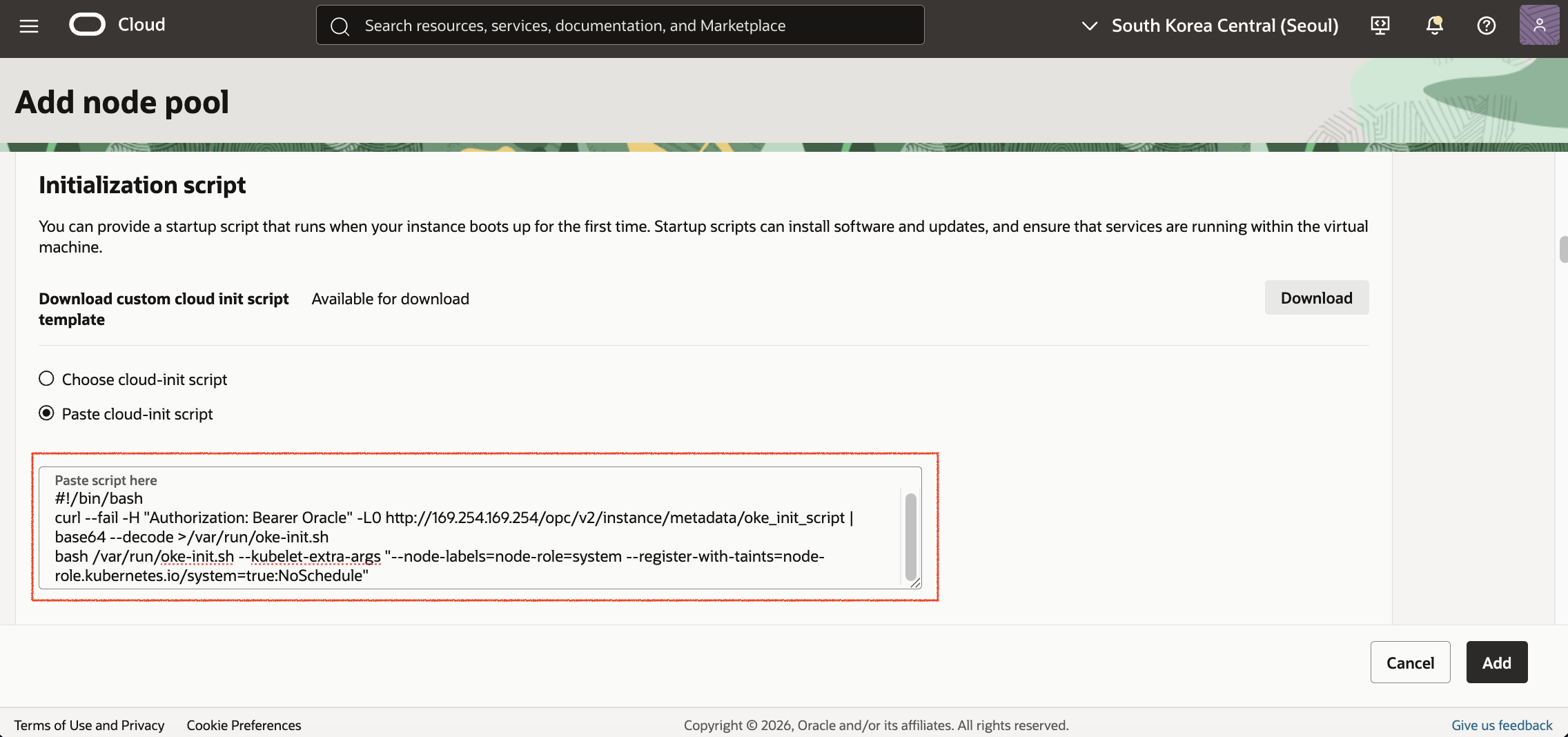
system-pool 노드는 System 용도로만 사용하기 위해 Cloud-init Script에 Label과 Taint를 추가합니다.
#!/bin/bash
curl --fail -H "Authorization: Bearer Oracle" -L0 http://169.254.169.254/opc/v2/instance/metadata/oke_init_script | base64 --decode >/var/run/oke-init.sh
bash /var/run/oke-init.sh --kubelet-extra-args "--node-labels=node-role=system --register-with-taints=node-role.kubernetes.io/system=true:NoSchedule"
3. CoreDNS Pending 상태 해결
Cluster 생성 직후 kube-system Namespace의 Pod 상태를 확인하면 CoreDNS 관련 Pod가 Pending 상태인 것을 볼 수 있습니다.
kubectl get po -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7949666f46-frvx4 0/1 Pending 0 6m35s
csi-oci-node-shmgq 1/1 Running 0 5m20s
kube-dns-autoscaler-9b5569b69-ddqbr 0/1 Pending 0 6m35s
kube-proxy-bxb2r 1/1 Running 0 5m20s
proxymux-client-rhn65 1/1 Running 0 5m20s
vcn-native-ip-cni-5tpzp 2/2 Running 0 5m20s
앞에서 system-pool에 node-role.kubernetes.io/system=true:NoSchedule Taint를 설정했기 때문에 CoreDNS가 해당 노드에 배포되려면 Toleration이 필요합니다. 또한 CoreDNS가 Application Resource 전용 Node Pool이 아니라 system-pool에 배포되도록 Node Selector도 함께 설정합니다.
OCI Console에서 Cluster 상세 화면으로 이동한 후 Add-ons 탭을 클릭합니다. Manage add-ons에서 CoreDNS를 선택하고 Edit을 클릭합니다. Add configuration을 통해 다음 값을 추가합니다.
| 항목 | 값 |
|---|---|
| tolerations | [{"key": "node-role.kubernetes.io/system","operator": "Exists","effect": "NoSchedule"}] |
| node selectors | {"name": "system-pool"} |
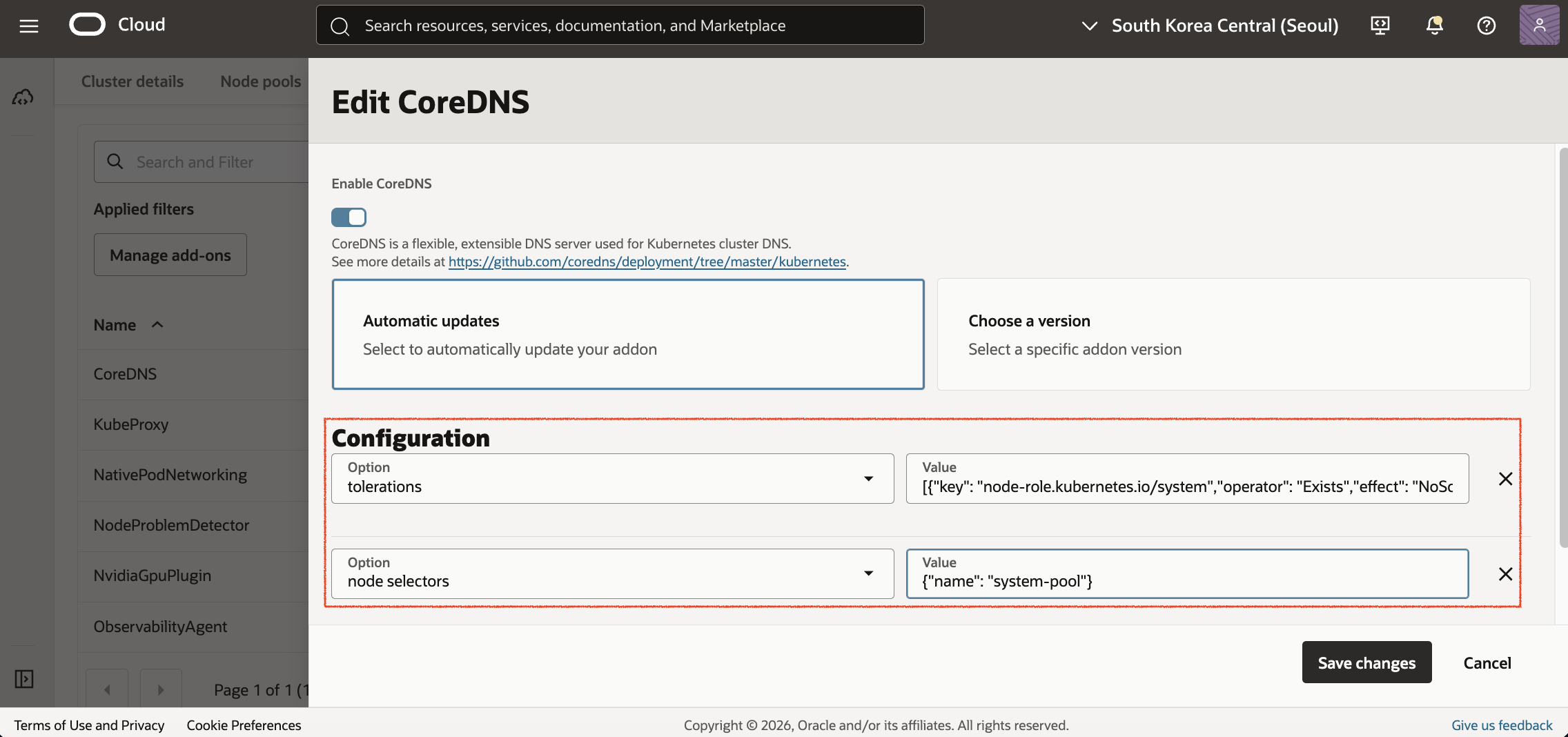
설정 변경 후 다시 kube-system Pod 상태를 확인하면 CoreDNS와 kube-dns-autoscaler가 Running 상태로 변경됩니다.
kubectl get po -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-58975fffdb-f6x8f 1/1 Running 0 13s
csi-oci-node-shmgq 1/1 Running 0 10m
kube-dns-autoscaler-f5ff6c8d4-9g97r 1/1 Running 0 13s
kube-proxy-bxb2r 1/1 Running 0 10m
proxymux-client-rhn65 1/1 Running 0 10m
vcn-native-ip-cni-5tpzp 2/2 Running 0 10m
4. GVA Application Node Pool 생성
이제 실제 테스트 Pod가 배포될 Application Node Pool을 생성합니다. Node Pool 이름은 largescale-pool1입니다.
주요 설정은 다음과 같습니다.
| 항목 | 값 |
|---|---|
| Node Pool name | largescale-pool1 |
| Shape | VM.Standard.E5.Flex |
| OCPU / Memory | 12 OCPU / 24 GB |
| Node count | 1 |
| GVA Secondary VNIC Profile count | 8 |
| IP count per VNIC | 32 |
| Application Resource | pause |
Node Pool 생성 화면에서 Configure Secondary VNICs for nodes를 Enable하고, GVA에서 사용할 8개의 Secondary VNIC Profile을 추가합니다.
각 VNIC Profile은 다음과 같은 형식으로 입력합니다.
| 항목 | 값 |
|---|---|
| VNIC Attachment Display Name | largescale-pool1-vnic-attach-01 ~ largescale-pool1-vnic-attach-08 |
| VNIC Display Name | largescale-pool1-vnic-01 ~ largescale-pool1-vnic-08 |
| VNIC Subnet | pod_private_subnet |
| # of IP addresses | 32 |
| Application Resources | pause |
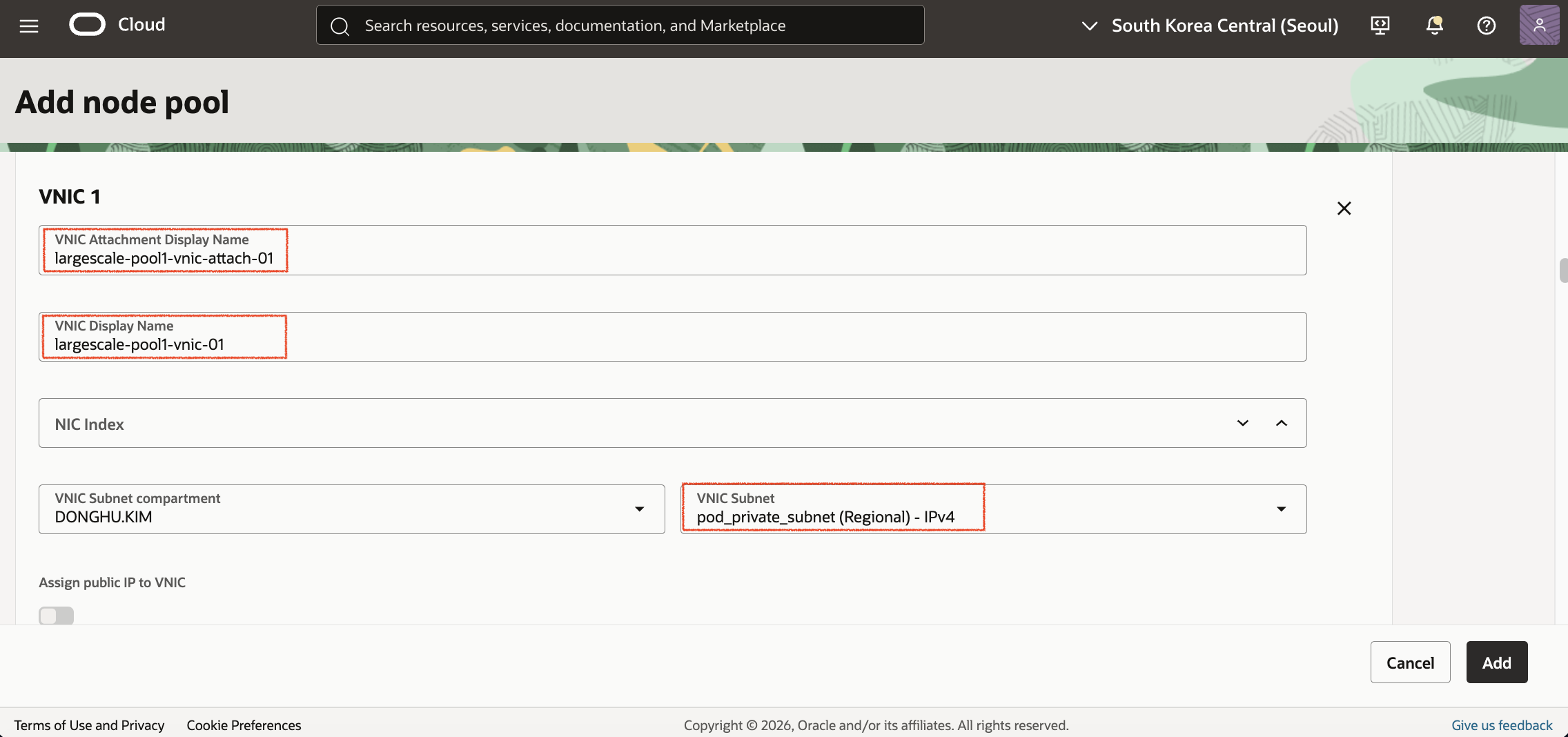
Oracle 문서에서는 VNIC Display Name이 Optional로 표시되지만, 이번 테스트에서는 이 값을 입력하지 않으면 노드 생성 과정에서 Attach 대상 VNIC를 찾지 못하는 문제가 발생했습니다. 따라서 Node Pool 생성 시 VNIC Attachment Display Name뿐 아니라 VNIC Display Name도 명시적으로 입력하는 것을 권장합니다.
생성된 Node Pool 정보입니다.
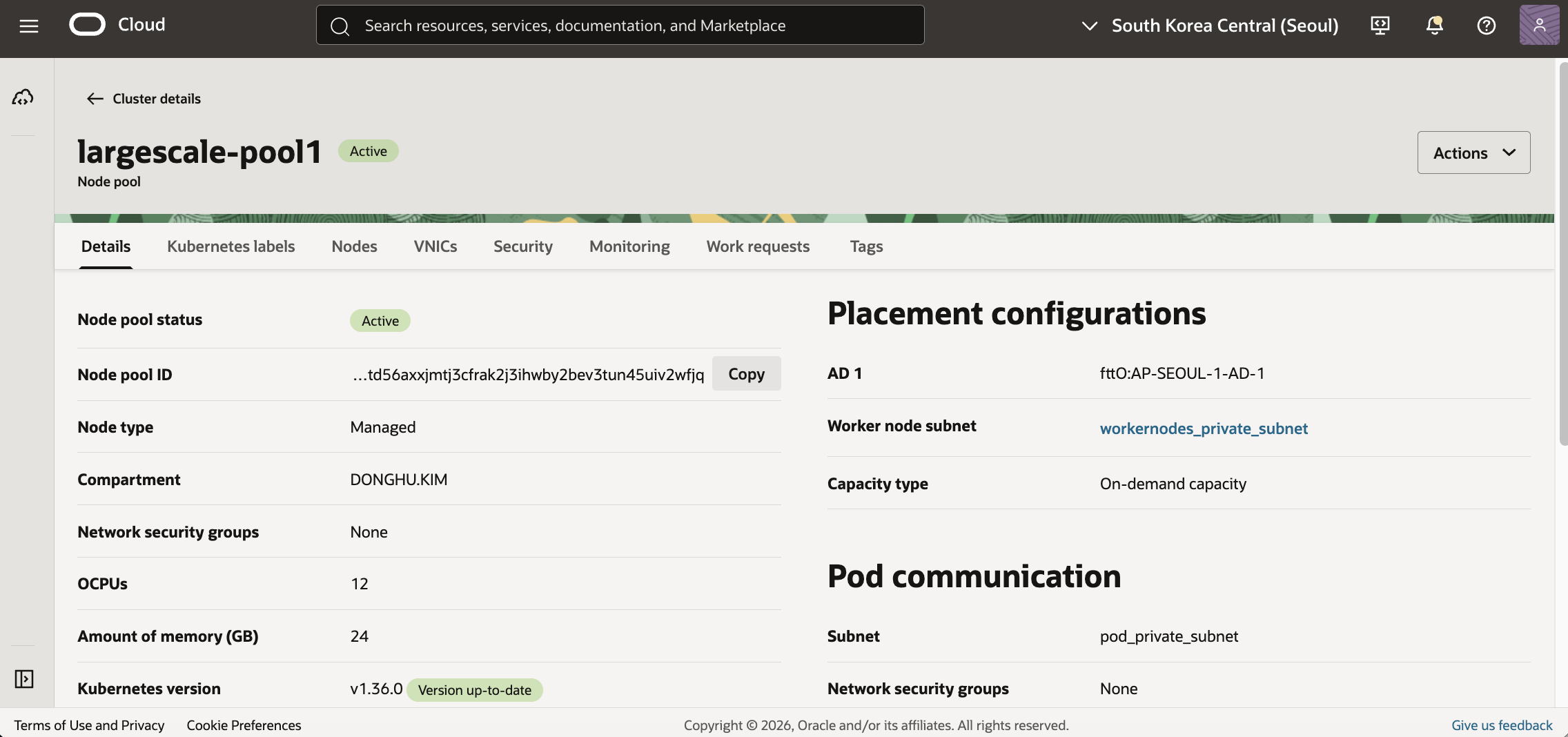
VNIC 목록에서도 largescale-pool1-vnic-01부터 largescale-pool1-vnic-08까지 생성된 것을 확인할 수 있습니다.
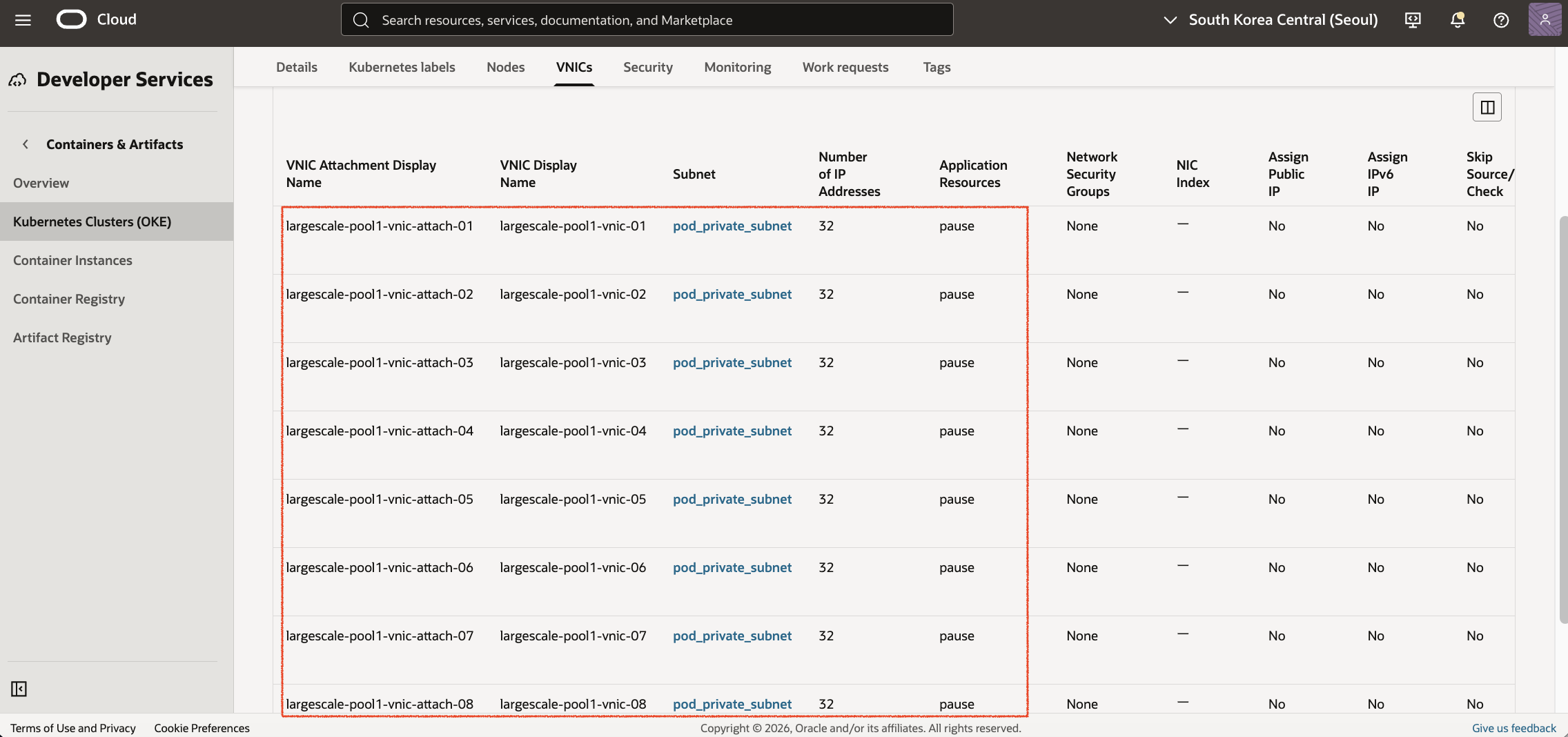
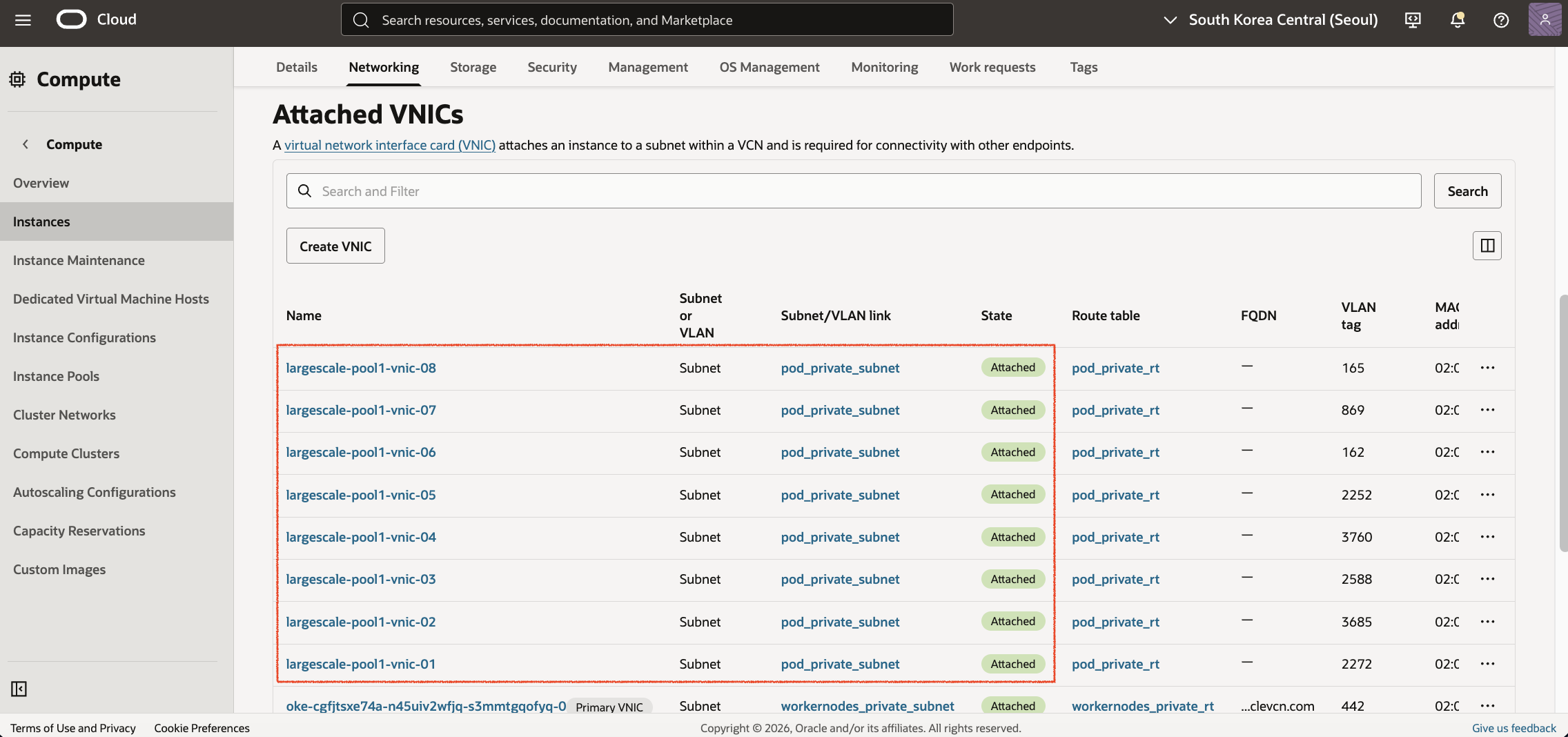
Worker Node 상세 화면에서도 GVA에서 정의한 Secondary VNIC들이 정상적으로 Attach된 것을 확인할 수 있습니다.
Node에서 Capacity를 확인하면 pause Application Resource와 Pod Capacity가 256으로 표시됩니다.
$ kubectl describe node 10.0.1.17
Capacity:
cpu: 24
ephemeral-storage: 37206272Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 24298008Ki
oke-application-resource.oci.oraclecloud.com/pause: 256
pods: 256
Allocatable:
cpu: 23763m
ephemeral-storage: 34289300219
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 20947480Ki
oke-application-resource.oci.oraclecloud.com/pause: 256
pods: 256
8개의 Secondary VNIC에 각각 32개의 IP를 할당했으므로 Application Resource pause 기준으로 총 256개 Capacity가 노드에 노출됩니다.
5. Pause Pod 배포 테스트
이제 실제 Pod를 배포하여 Pod Density를 확인합니다. 노드마다 기본 System Pod가 일부 배포되므로, 이번 테스트에서는 Pause Pod를 252개 배포합니다.
아래 내용을 pause-for-256ip-test.yaml 파일로 저장합니다. 참고로 Application Resource는 Pod를 특정 Secondary VNIC Profile에 스케쥴러 수준에서 연결하는데 이때 이 리소스가 노출된 노드에는 oci.oraclecloud.com/application-resource-only:NoSchedule Taint가 설정됩니다. 따라서 해당 노드에 배치될 Pod는 이를 위한 toleration이 필요합니다. 또한 oke-application-resource.oci.oraclecloud.com/pause에 대한 request, limit을 1로 설정함으로서 Pod가 해당 Application Resource 1개를 사용하도록 예약할 수 있습니다. (다만 여기서는 8개의 VNIC 모두 Application Resource를 pause로 적용했기 때문에 특정 VNIC Profile로의 고정 효과는 크지 않습니다.)
apiVersion: apps/v1
kind: Deployment
metadata:
name: pause-for-256ip-test
spec:
replicas: 252
selector:
matchLabels:
app: pause-for-256ip-test
template:
metadata:
labels:
app: pause-for-256ip-test
spec:
nodeSelector:
name: largescale-pool1
containers:
- name: pause
image: registry.k8s.io/pause:3.10
resources:
requests:
oke-application-resource.oci.oraclecloud.com/pause: "1"
limits:
oke-application-resource.oci.oraclecloud.com/pause: "1"
tolerations:
- key: "oci.oraclecloud.com/application-resource-only"
operator: "Exists"
effect: "NoSchedule"
이제 Deployment를 생성합니다.
kubectl apply -f pause-for-256ip-test.yaml
largescale-pool1의 Worker Node에서 Running 상태인 Pause Pod 수를 확인합니다.
kubectl get pods \
-l app=pause-for-256ip-test \
-o wide \
--field-selector spec.nodeName=10.0.1.17,status.phase=Running \
--no-headers \
| wc -l
252
총 252개의 Pause Pod가 정상적으로 Running 상태인 것을 확인할 수 있습니다.
이번에는 Replica 수를 253개로 늘려 봅니다.
kubectl scale deployment pause-for-256ip-test --replicas=253
이 경우 추가 Pod는 Pending 상태가 되며, Scheduler Event에서 다음과 같이 Too many pods 문제가 발생합니다.
Warning FailedScheduling 3m53s default-scheduler 0/2 nodes are available: 1 Too many pods, 1 node(s) had untolerated taint(s). no new claims to deallocate, preemption: 0/2 nodes are available: 1 No preemption victims found for incoming pod, 1 Preemption is not helpful for scheduling.
이 결과는 largescale-pool1 Worker Node의 Pod Capacity가 256이고, 해당 노드에 이미 System Pod가 일부 배포되어 있기 때문에 Application Pod를 253개까지 수용할 수 없다는 것을 보여줍니다. 반면 system-pool은 System Node Pool Taint가 설정되어 있어 Pause Pod가 스케줄링되지 않습니다.
마무리
OKE의 Generic VNIC Attachment 기능을 사용하면 하나의 Worker Node에 여러 Secondary VNIC Profile을 연결하고, 각 Profile별로 Pod IP 수를 제어할 수 있습니다. 이번 테스트에서는 Worker Node 한 대에 8개의 Secondary VNIC를 연결하고 각 VNIC마다 32개 IP를 할당하여, Kubernetes Node Capacity 기준 256 Pod를 확인했습니다.
기존에는 더 많은 Pod를 수용하기 위해 노드를 늘리는 방식이 일반적이었지만, 이 방식은 노드 운영 비용과 시스템 오버헤드를 함께 증가시킵니다. GVA를 사용하면 노드당 Pod Density를 높일 수 있고, Application Resource를 통해 특정 워크로드가 특정 VNIC Profile을 사용하도록 제어할 수 있습니다.
참고 문서
- OCI Kubernetes Engine (OKE) support for multiple secondary VNIC attachments
- Attaching Multiple Secondary VNICs for Pod Networking
- Generic VNIC Attachment for OKE Is Now Generally Available
- Large Cluster Best Practices
이 글은 개인적으로 얻은 지식과 경험을 작성한 글로 내용에 오류가 있을 수 있습니다. 또한 글 속의 의견은 개인적인 의견으로 특정 회사를 대변하지 않습니다.
Donghu Kim CLOUDNATIVE
oci oke kubernetes vcn-native-cni generic-vnic-attachment gva pod-density