Generative AI
OCI Generative AI 서비스 살펴보기
Table of Contents
OCI Generative AI 서비스 살펴보기
Oracle Cloud Infrastructure Generative AI (베타)는 텍스트 생성을 위한 광범위한 사용 사례를 포괄하는 맞춤형 최첨단 LLM(대형 언어 모델) 세트를 제공하는 완전 관리형 서비스입니다. 플레이그라운드 를 사용하여 즉시 사용 가능한 사전 훈련된 모델을 시험해 보거나 전용 AI 클러스터의 자체 데이터를 기반으로 미세 조정된 사용자 지정 모델을 생성하고 호스팅하세요.
OCI Generative AI의 기본 모델
OCI Generative AI 서비스 에는 다음과 같은 기본 모델이 포함되어 있습니다.
생성(Generation) 모델
cohere.command- 강력한 성능의 생성(generation) 모델로 텍스트 추출 및 감정 분석과 같은 정확성이 요구되는 작업에 이 모델을 사용합니다.
- 이 모델을 사용하여 마케팅 Copy, 이메일, 블로그 포스트, 제품 설명의 초안을 작성하여 검토하고 사용할 수 있습니다.
cohere.command-light- 빠르고 가벼운 생성(generation) 모델로, 속도와 비용이 중요할 때 이 모델을 사용합니다.
- 이 모델은 가벼운 모델이기 때문에 최상의 결과물을 도출하기 위해서는 모델에 명확한 프롬프트를 제공해야 하며, 더 구체적일수록 이 모델의 성능을 더 잘 활용할 수 있습니다.
- 예를 들어, “이 제품 리뷰의 톤은 무엇입니까?”라는 프롬프트 대신 “이 제품 리뷰의 톤은 무엇입니까? 좋다 또는 싫다라는 단어로 대답하십시오.”라고 적습니다.
- 예시 (Examples)
- Copy 생성(generation) : 마케팅 Copy 초안, 이메일, 블로그 포스트, 제품 설명서, 문서 등을 생성합니다.
- 채팅 : 브레인스토밍, 문제 해결, 질문에 대답할 수 있는 챗봇을 만들거나 검색 시스템과 통합하여 자료에 기초를 둔 정보 검색을 시스템을 만듭니다.
- 스타일 변환 : 입력한 컨텐츠를 다른 스타일이나 언어로 다시 작성합니다.
요약(Summarization) 모델
사전에 학습된 cohere.command 모델은 텍스트 요약을 위해 특별히 매개변수를 지정할 수 있는 텍스트 생성 모델 중 하나로, 플레이그라운드에서 이용 가능합니다. 이 모델은 아래와 같은 다양한 텍스트에서 중요 정보를 추출하고자 할 때 유용하게 활용할 수 있습니다.
- 뉴스 기사
- 블로그 글
- 채팅 대화 기록
- 과학 논문
- 회의록
- 제품 리뷰
Embedding 모델
텍스트의 숫자 표현은 텍스트 조각, 문장 또는 하나 이상의 단락일 수 있는 텍스트를 숫자로 변환한 것입니다. Generative AI 임베딩 모델은 입력한 각 구절, 문장 또는 단락을 1024개의 숫자로 이루어진 배열로 변환합니다. 이러한 임베딩은 입력 텍스트 내에서 의미나 맥락이 유사한 구문을 찾는 데 사용할 수 있으며, 주로 키워드가 아닌 텍스트의 의미에 중점을 둔 의미 검색에 사용됩니다. 다음 미리 학습된 모델은 텍스트 임베딩을 생성하기 위해 사용할 수 있습니다:
embed-english-light-v2.0
임베딩 출력을 시각화하려면 출력 벡터를 두 차원으로 투영하고 콘솔에서 점으로 표시됩니다. 서로 가까이 있는 점들은 모델이 유사한 것으로 간주하는 구문을 나타냅니다. “출력 내보내기”를 클릭하여 각 임베딩에 대한 1024개의 벡터 배열을 JSON 파일로 저장할 수 있습니다.
다음과 같은 사용 사례에 대해 텍스트 임베딩이 이상적으로 활용됩니다:
- 의미 검색: 통화 트랜스크립트, 내부 지식 소스 등을 검색합니다.
- 텍스트 분류: 고객 채팅 로그와 지원 티켓에서 의도를 분류하는 데 텍스트 임베딩을 사용합니다.
- 텍스트 클러스터링: 고객 리뷰나 새로운 데이터에서 중요한 주제를 식별합니다.
- 추천 시스템: 예를 들어 팟캐스트 설명을 숫자 특징으로 나타내어 추천 모델에서 사용합니다.
OCI 콘솔 살펴보기
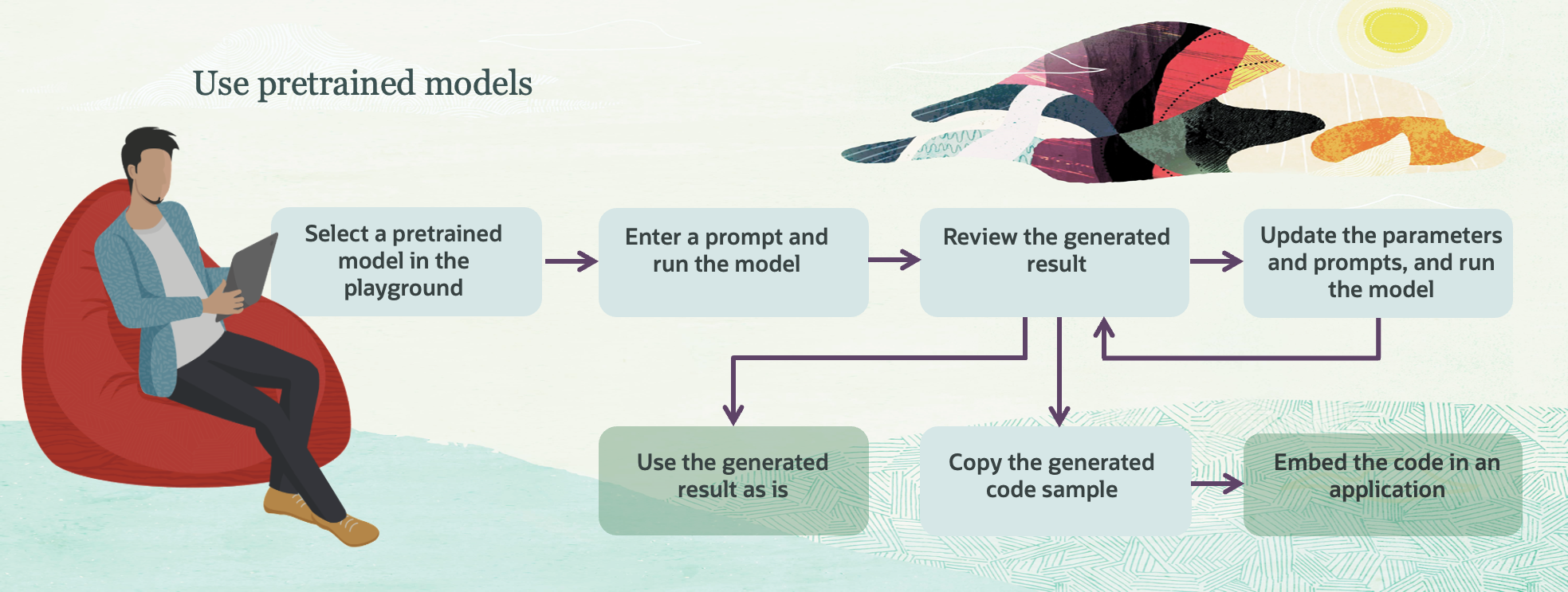
사전 학습된 모델 사용하기
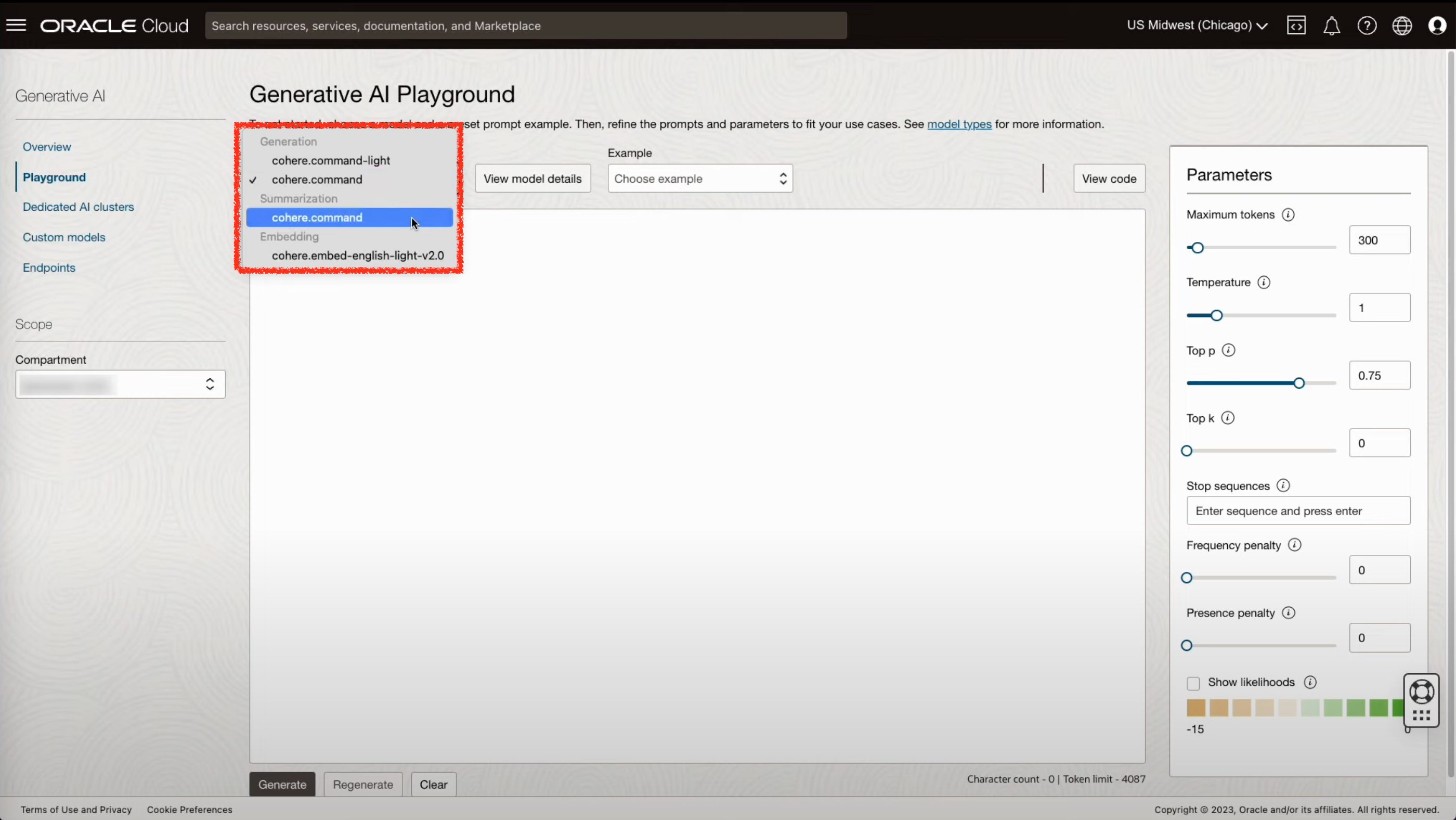
- 사전 학습된 모델을 사용해보려면 Playground 기능을 통해서 사용할 수 있습니다. Model을 선택할 수 있는 드롭다운 리스트를 클릭하여 사전학습된 모델 중 실습하고자 하는 모델을 선택할 수 있습니다.
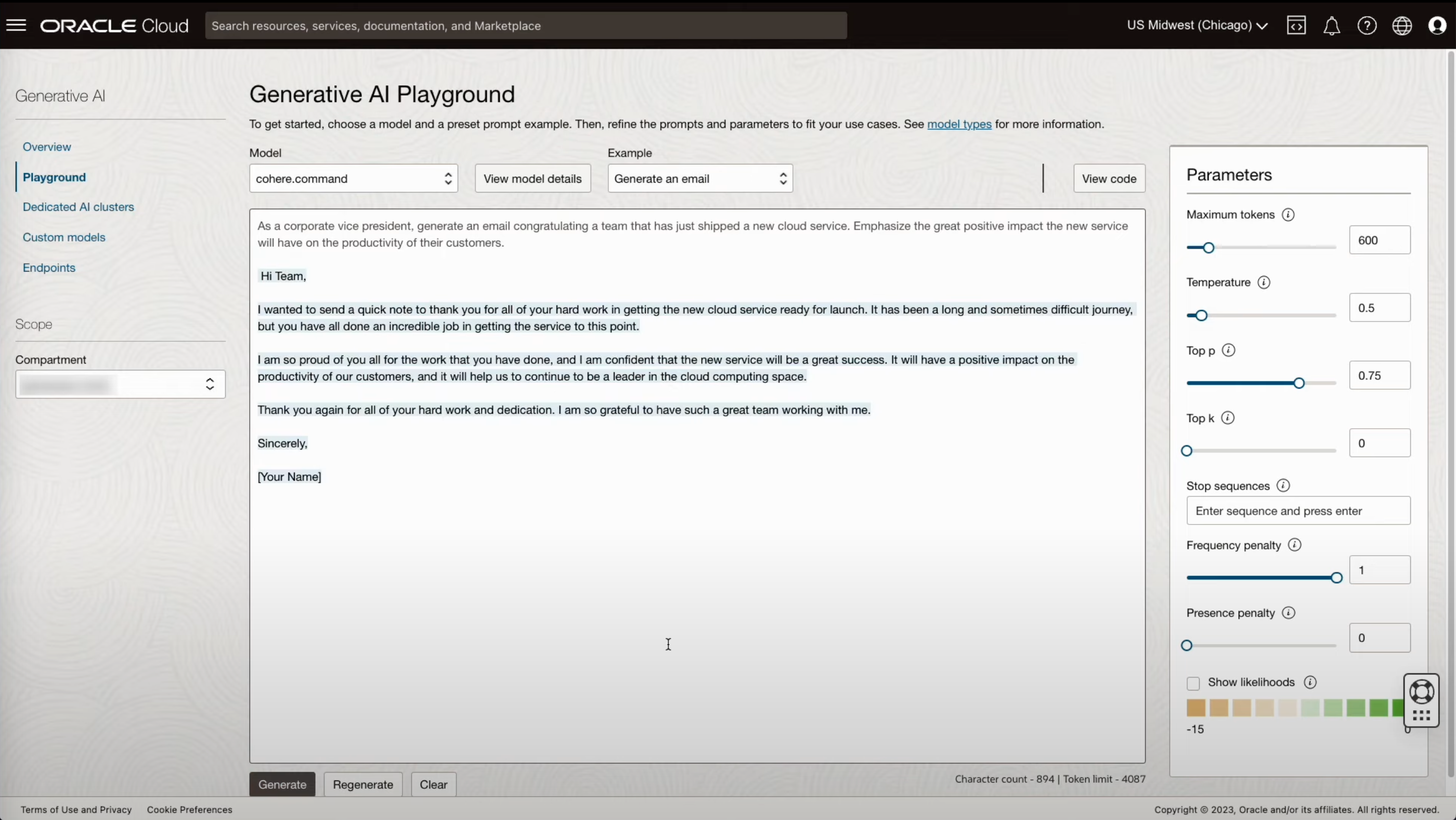
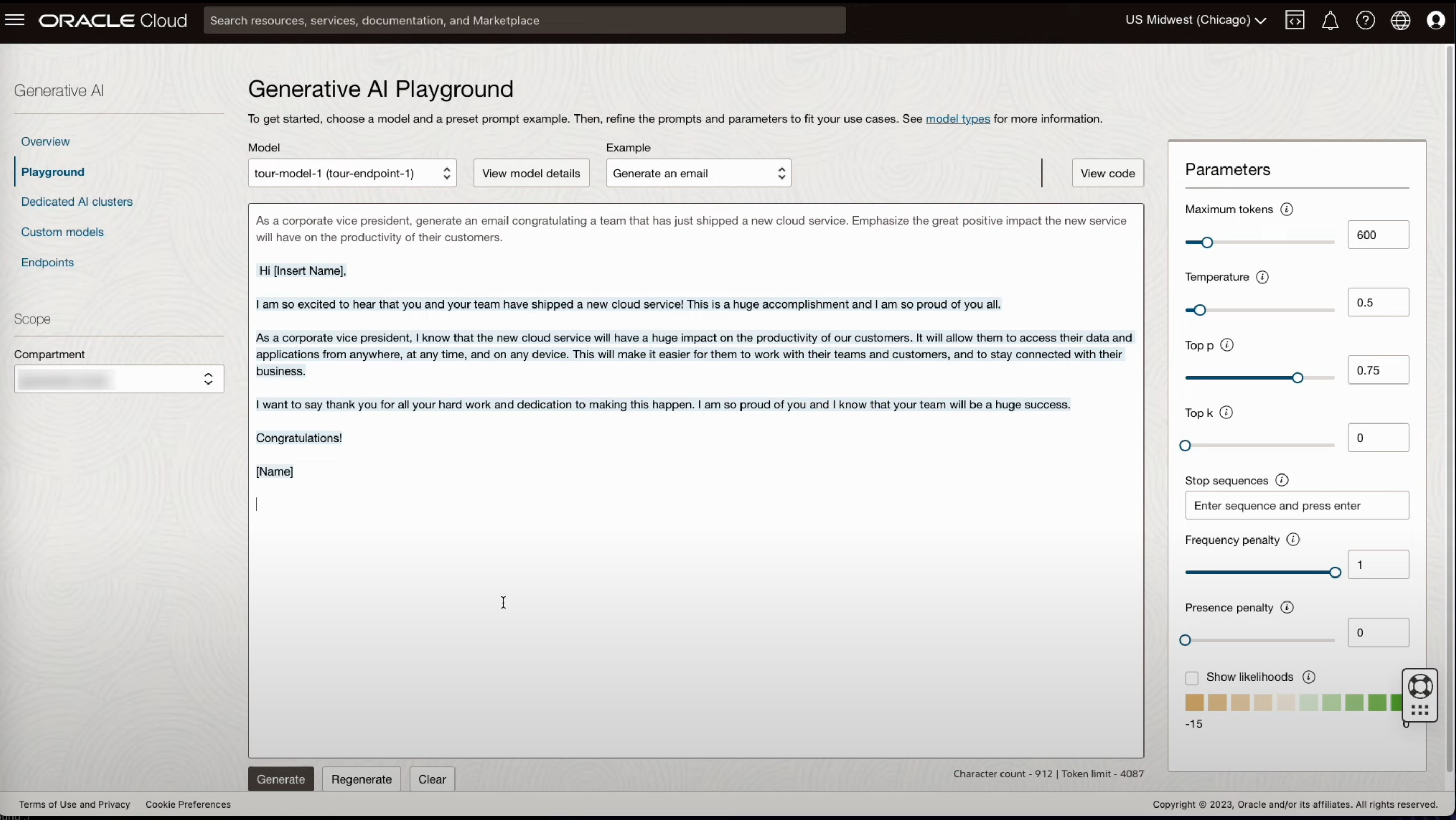
- 생성(Generation) 모델을 활용하여 이메일 초안을 작성하는 예시 입니다.
- “View Code” 버튼을 클릭하면 Playground에서 선택한 모델과 파라미터를 기반으로 소스코드 예시를 생성해줍니다.
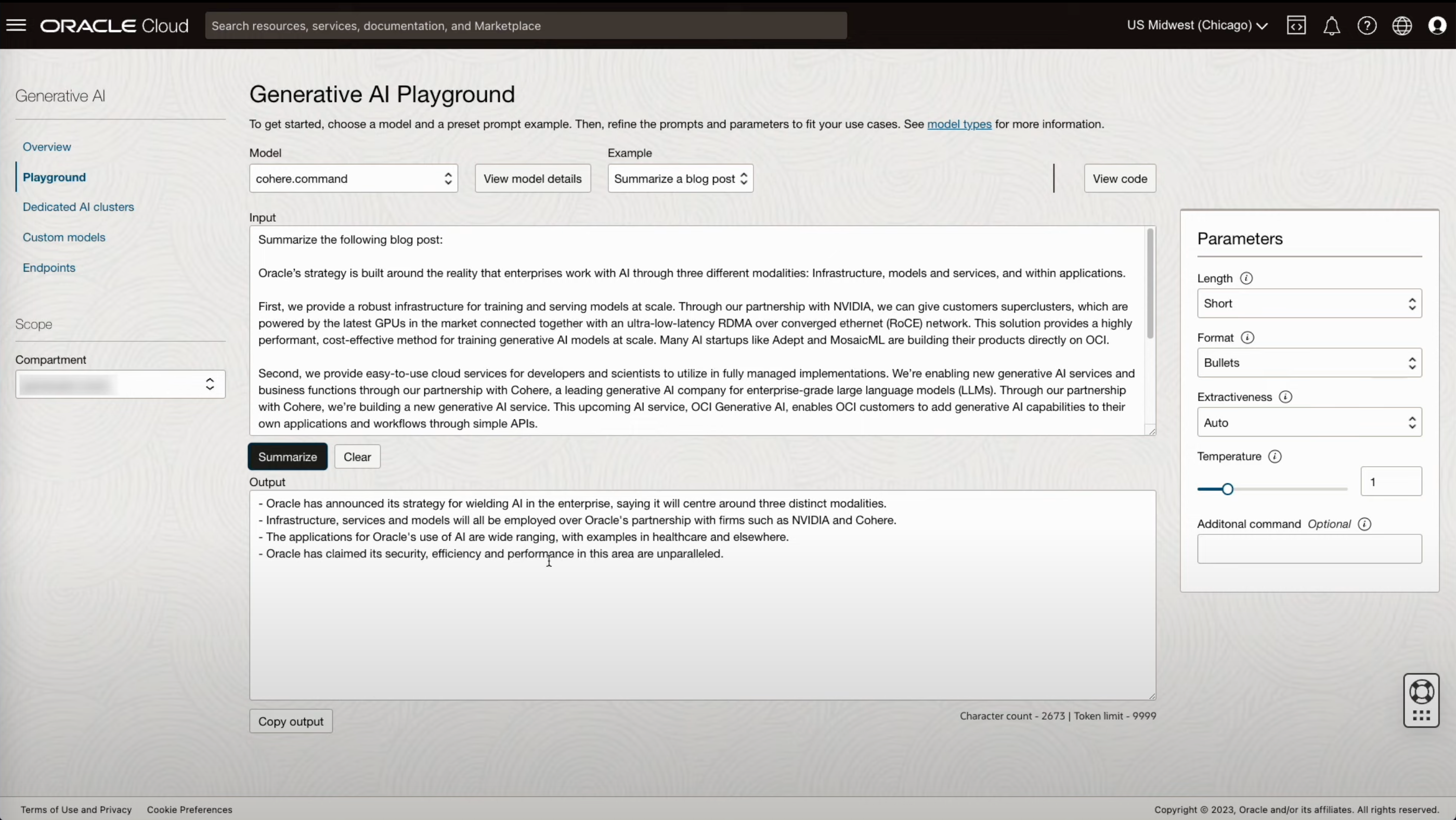
- 요약(Summarization) 모델을 활용하여 블로그 포스트의 내용을 요약하는 예시 입니다.
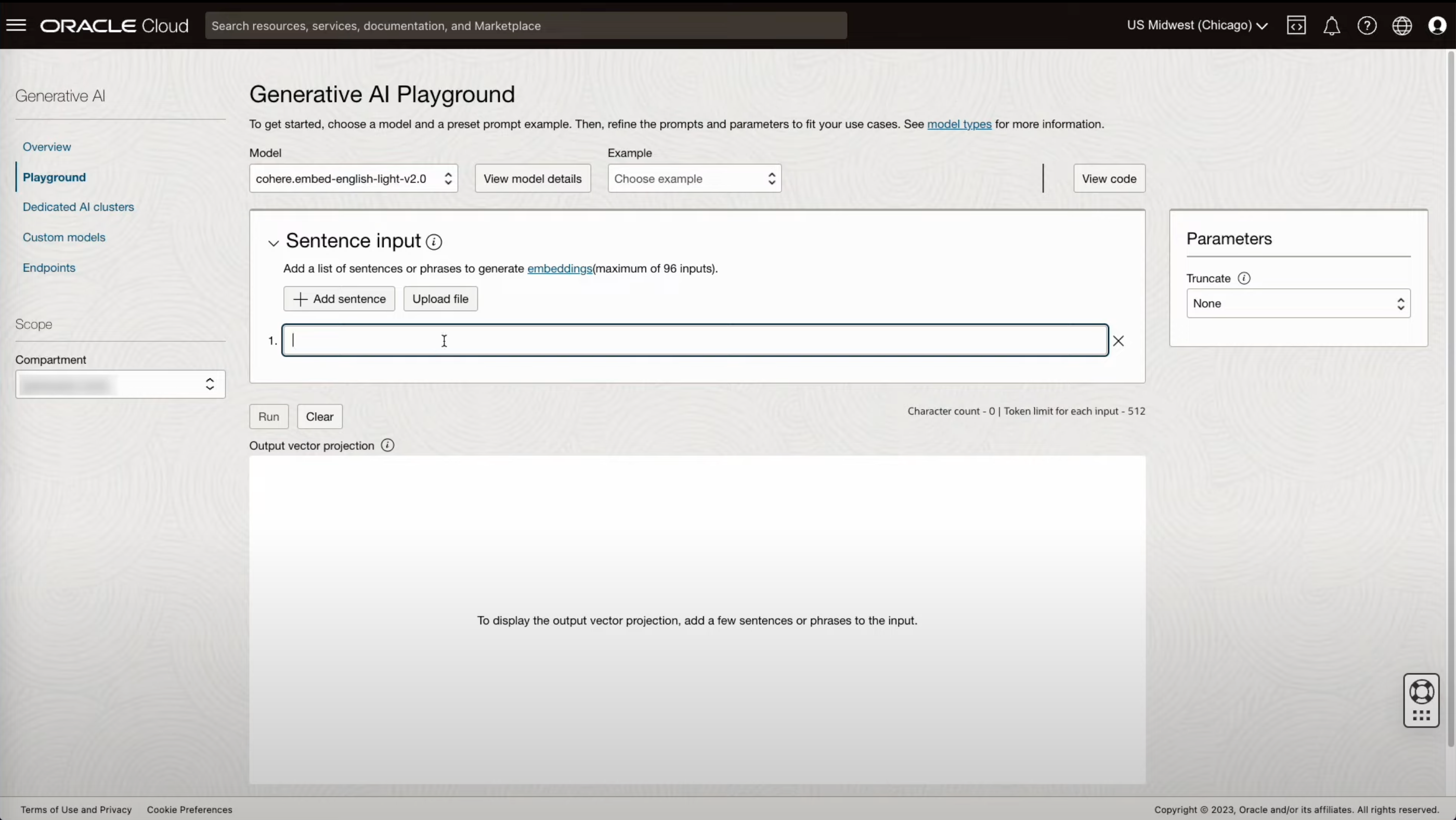
- Embedding 모델을 활용하여 제공된 질문들간의 연관성에 대해 확인하는 예시 입니다.
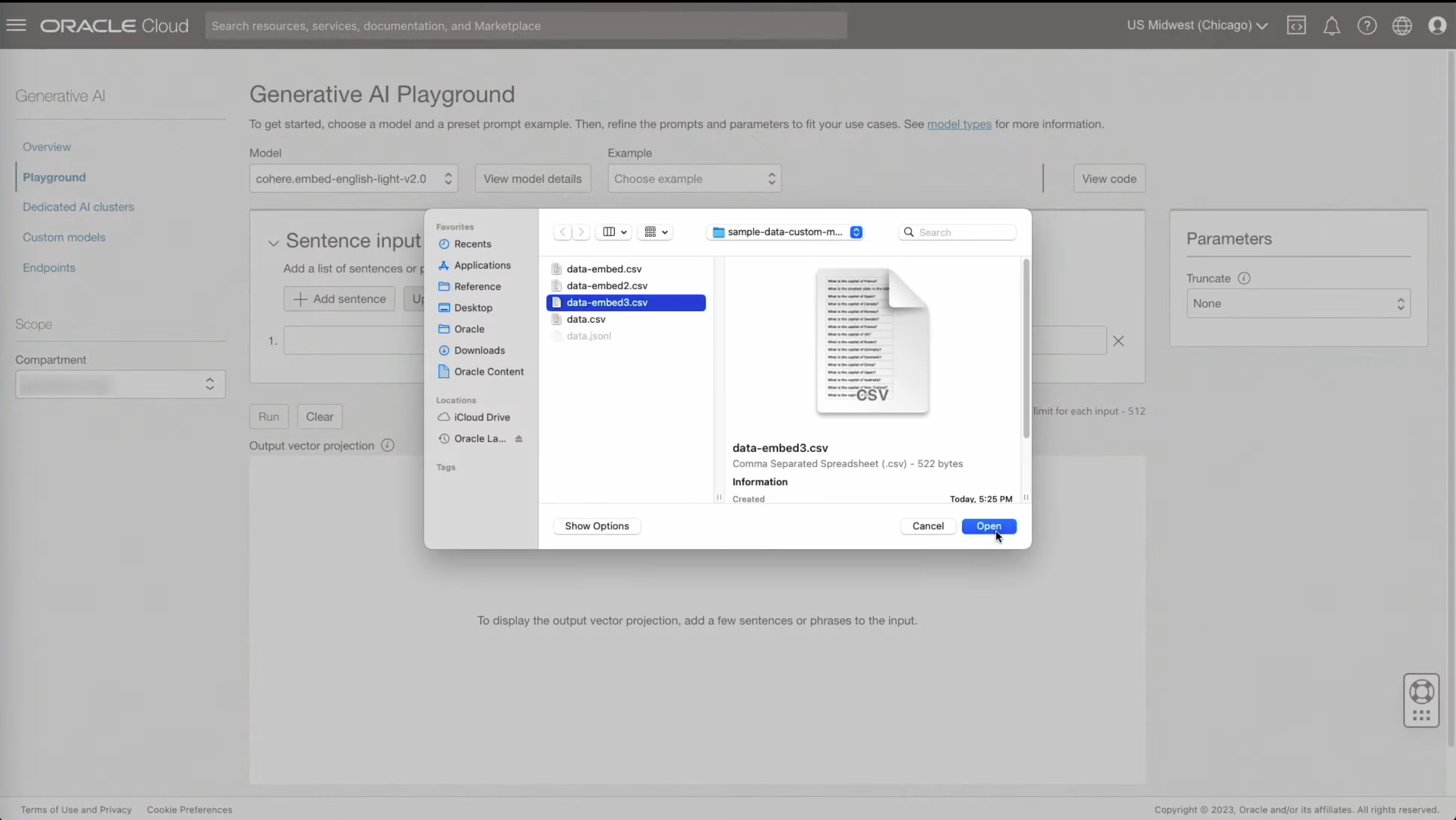
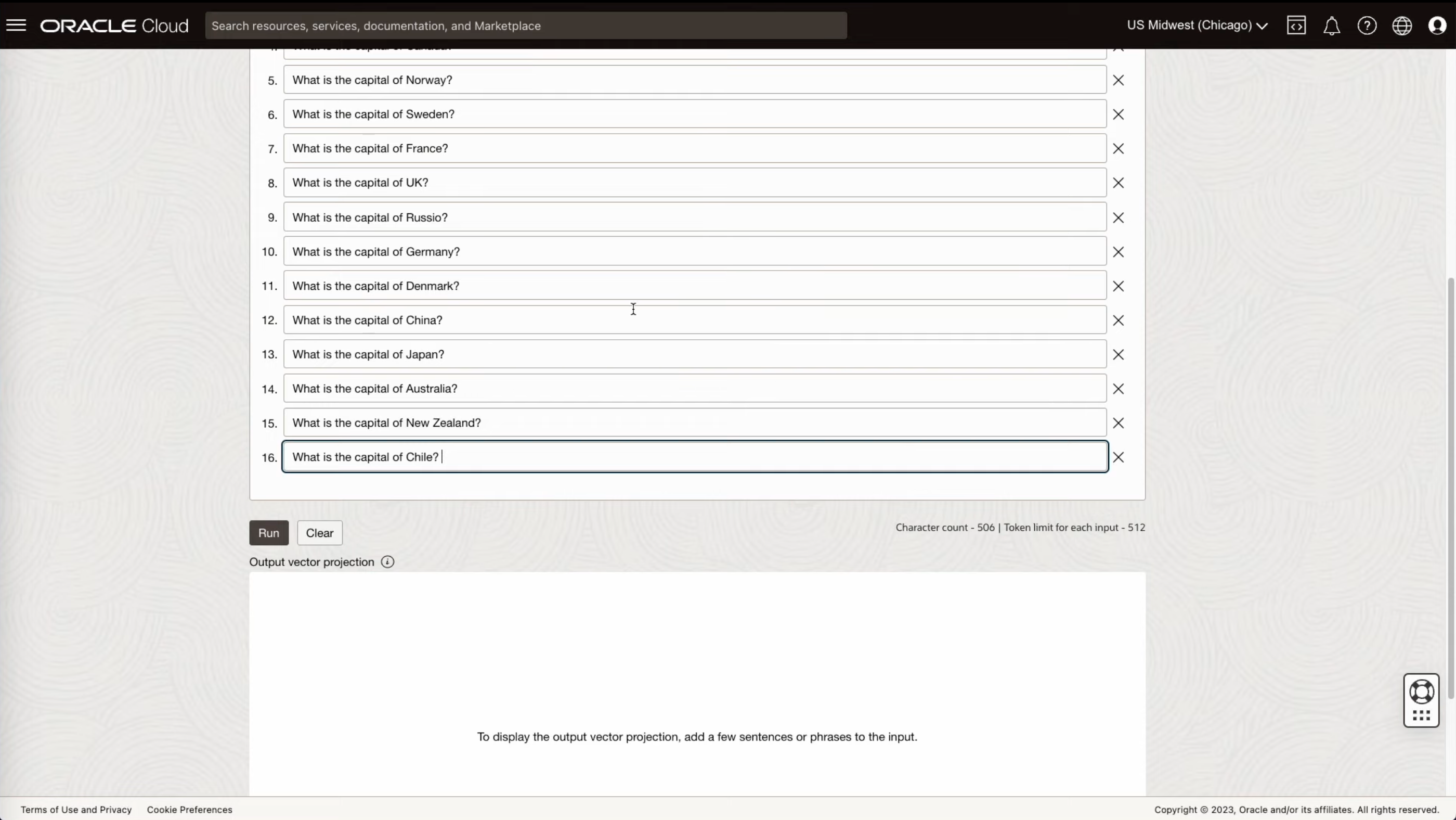
- 파일 업로드 기능을 통해서 문장 데이터를 업로드 합니다.
- 업로드된 질문을 살펴보면 모두 특정 나라의 수도를 물어보는 질문이지만, 한가지 질문은 미국에서 가장 작은 주가 어디인지에 대한 질문입니다.
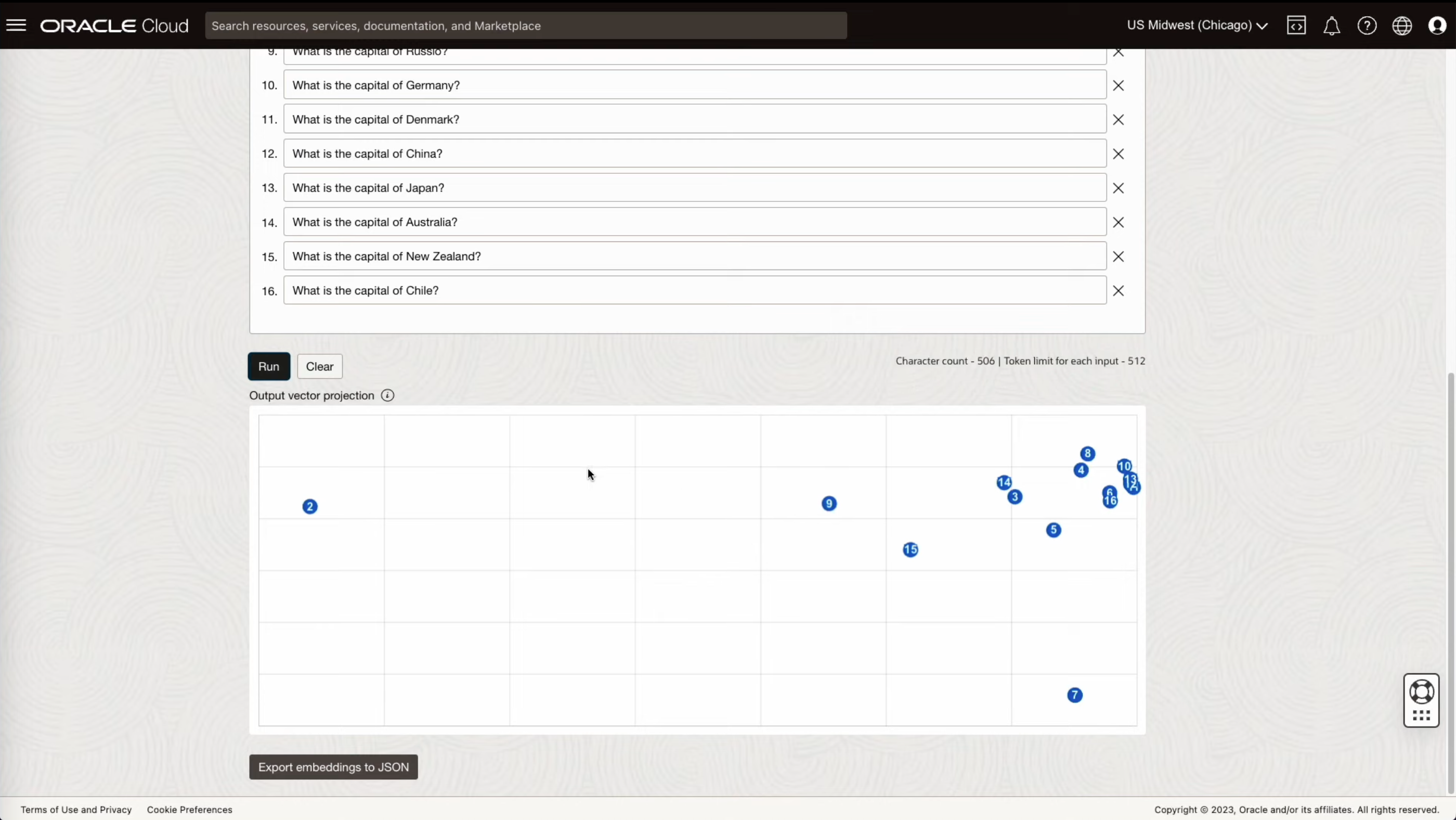
- “Run” 버튼을 클릭하여 실행해보면 2D 그래프로 질문들간의 연관성이 보여지며, 한가지 질문만 유독 떨어져 있는것을 확인할 수 있습니다.
- 파일 업로드 기능을 통해서 문장 데이터를 업로드 합니다.
사전 학습된 모델 미세 조정해보기
사전 학습된 모델을 미세 조정하기 위해서는 먼저 Dedicated AI Cluster가 필요합니다. 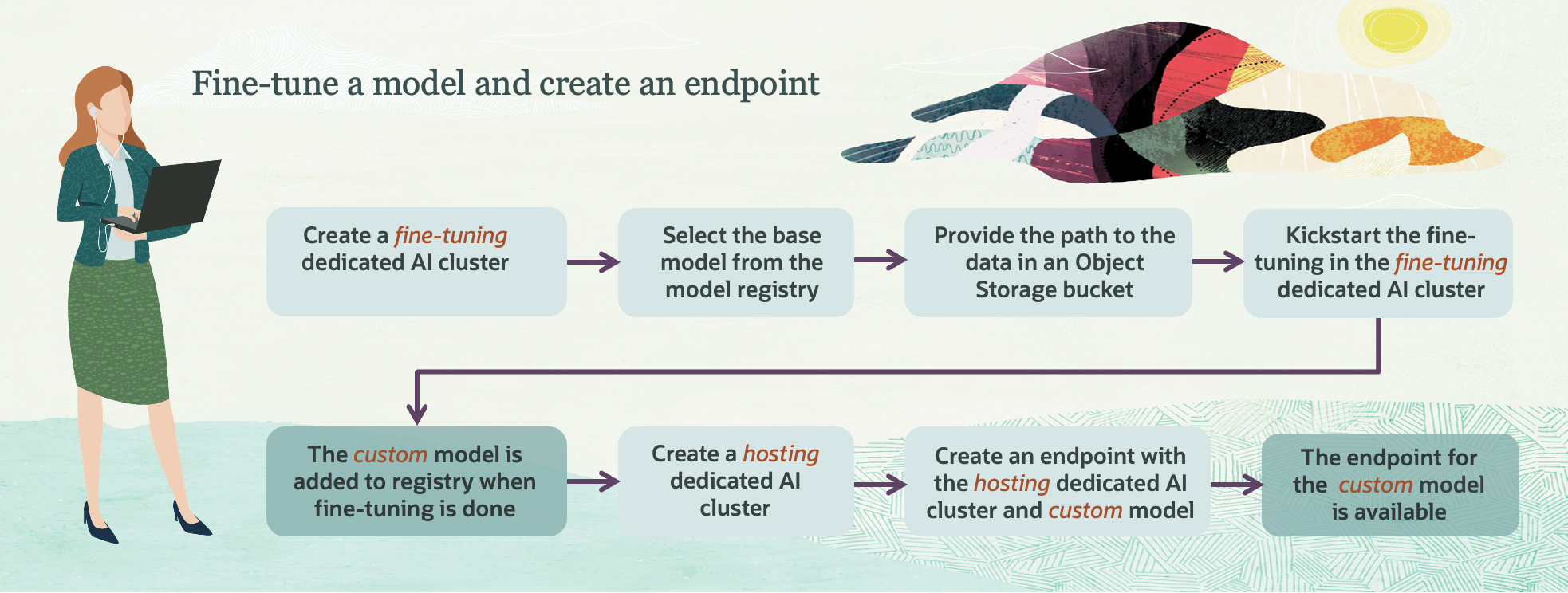
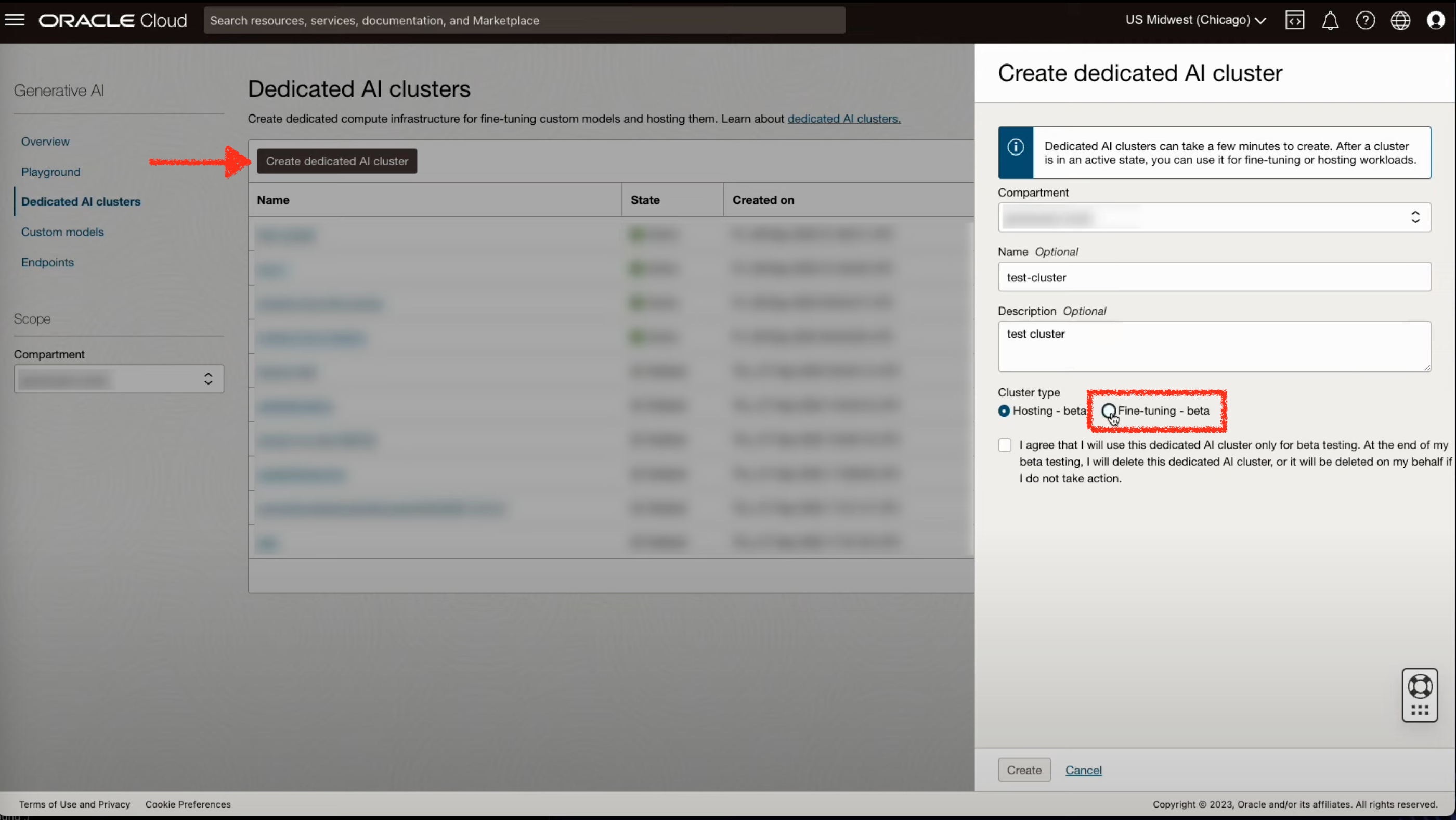
- Deticated AI Clusters 화면에서 Fine tuning을 위한 클러스터를 생성합니다.
- Custom models 화면에서 기본 제공되는 모델을 활용하여 미세 조정할 모델을 생성합니다.
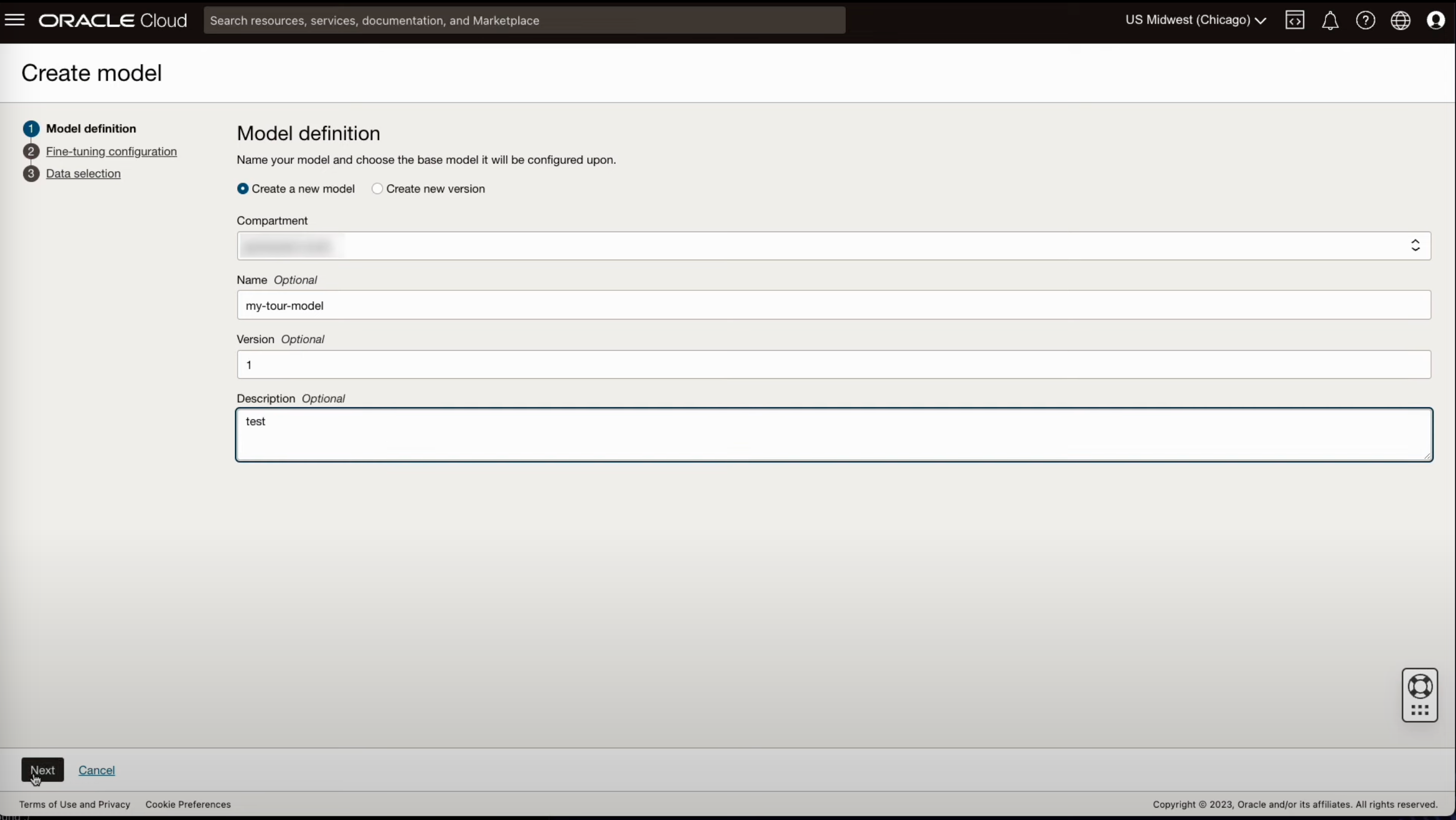
- 생성할 모델 이름과 버전을 입력합니다.
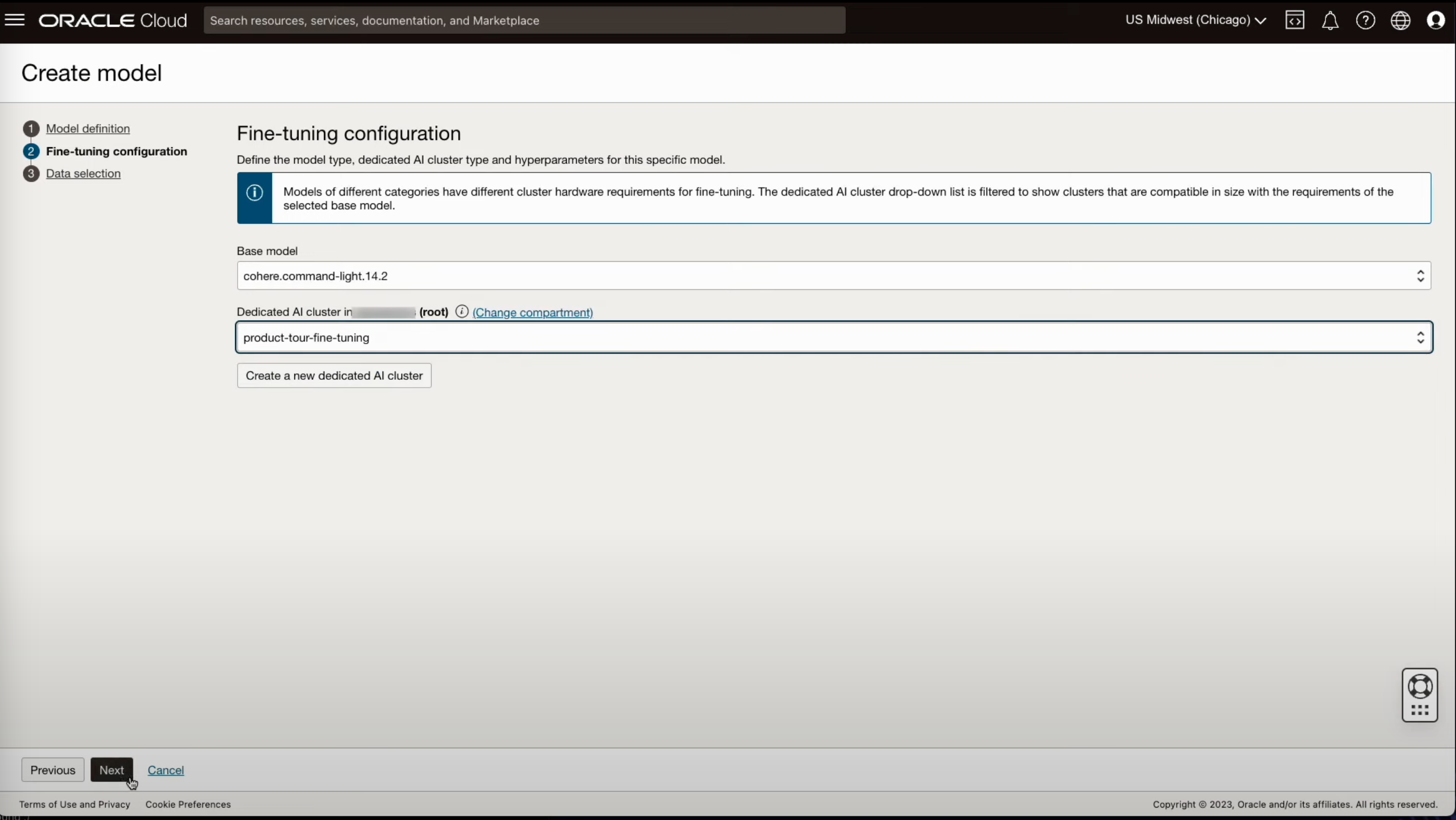
- 기본이될 모델을 선택하고 튜닝에 사용할 클러스터를 지정합니다.
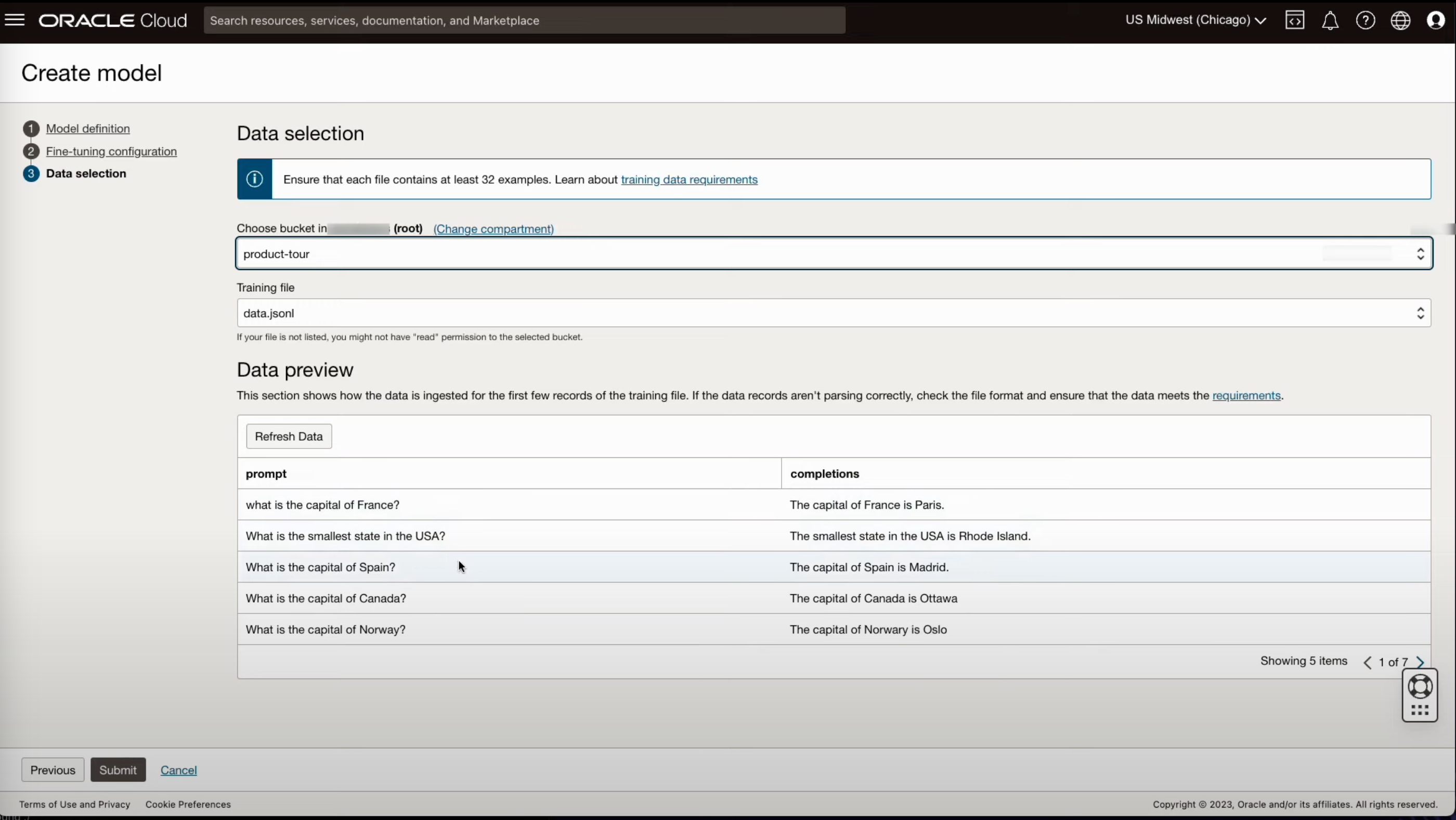
- 데이터가 저장되어 있는 버킷을 선택하고 훈련에 사용될 데이터 파일을 선택하여 모델을 생성합니다.
- 생성할 모델 이름과 버전을 입력합니다.
- 생성한 모델을 배포하기 위한 End Point를 생성합니다.
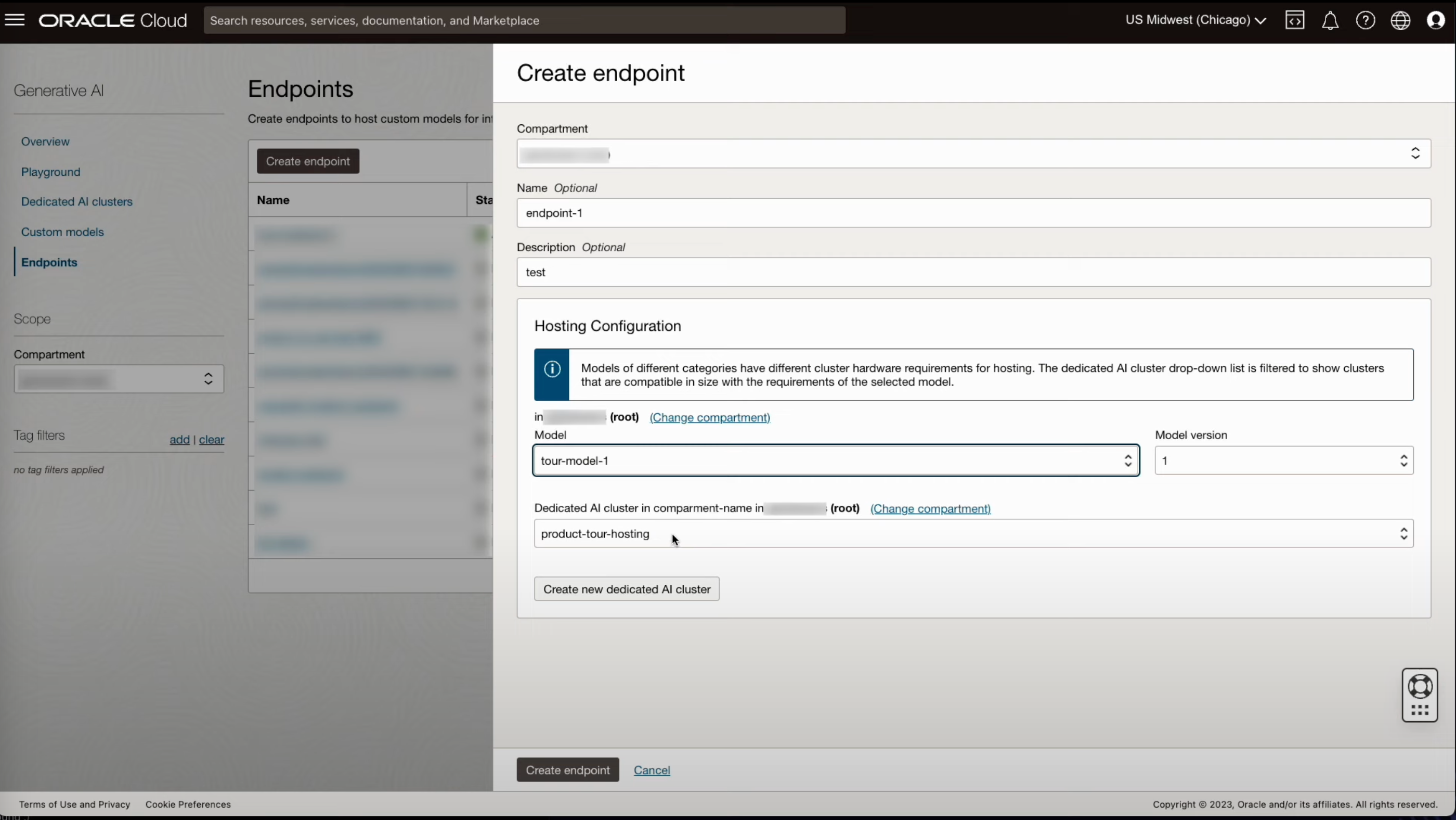
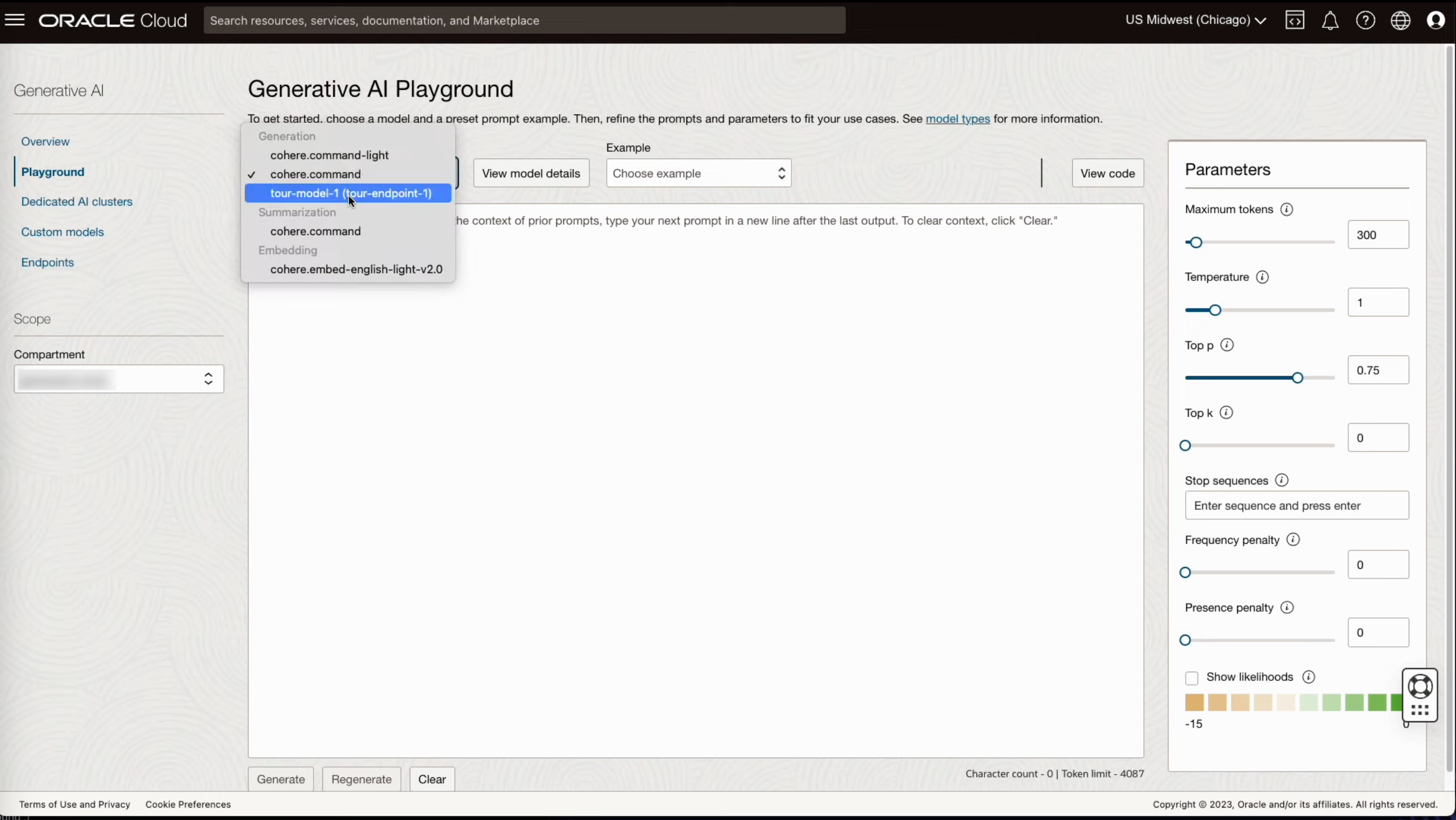
- 배포한 모델을 Playground에서 확인해 봅니다.
이 글은 개인적으로 얻은 지식과 경험을 작성한 글로 내용에 오류가 있을 수 있습니다. 또한 글 속의 의견은 개인적인 의견으로 특정 회사를 대변하지 않습니다.
Younghwan Cho AIML
oci data science generative ai gen ai 생성 ai