Data Science
OCI AI Quick Action 서비스 Hands-on
Table of Contents
OCI AI Quick Action 서비스 소개
OCI AQUA 서비 소개는 OCI AI Quick Action 서비스 둘러보기를 참고해주세요.
사전 요구 사항
OCI AI Quick Action을 사용하기 위해서는 몇 가지 사전 작업이 필요합니다. 아래 내용을 순서대로 진행 후 AQUA 서비스를 사용할 수 있습니다.
1. 서비스 한도 요청 (Data Science)
OCI AI Quick Action을 사용하기 위해서는 가용한 Data Science 카테고리의 A10 GPU 리소스 한도가 필요합니다. 아래 정보를 참고하여 서비스 한도 증설 요청을 진행해주셔야 합니다. (요청 후 승인까지 대략 2~3일의 시간이 필요합니다.)
- 서비스 카테고리(Service Category) : Data Science
- 리소스 (Resource) : GPUs for GPU.A10 based VM and BM Instances
- Region Limit : 증설 요청하고자 하는 한도
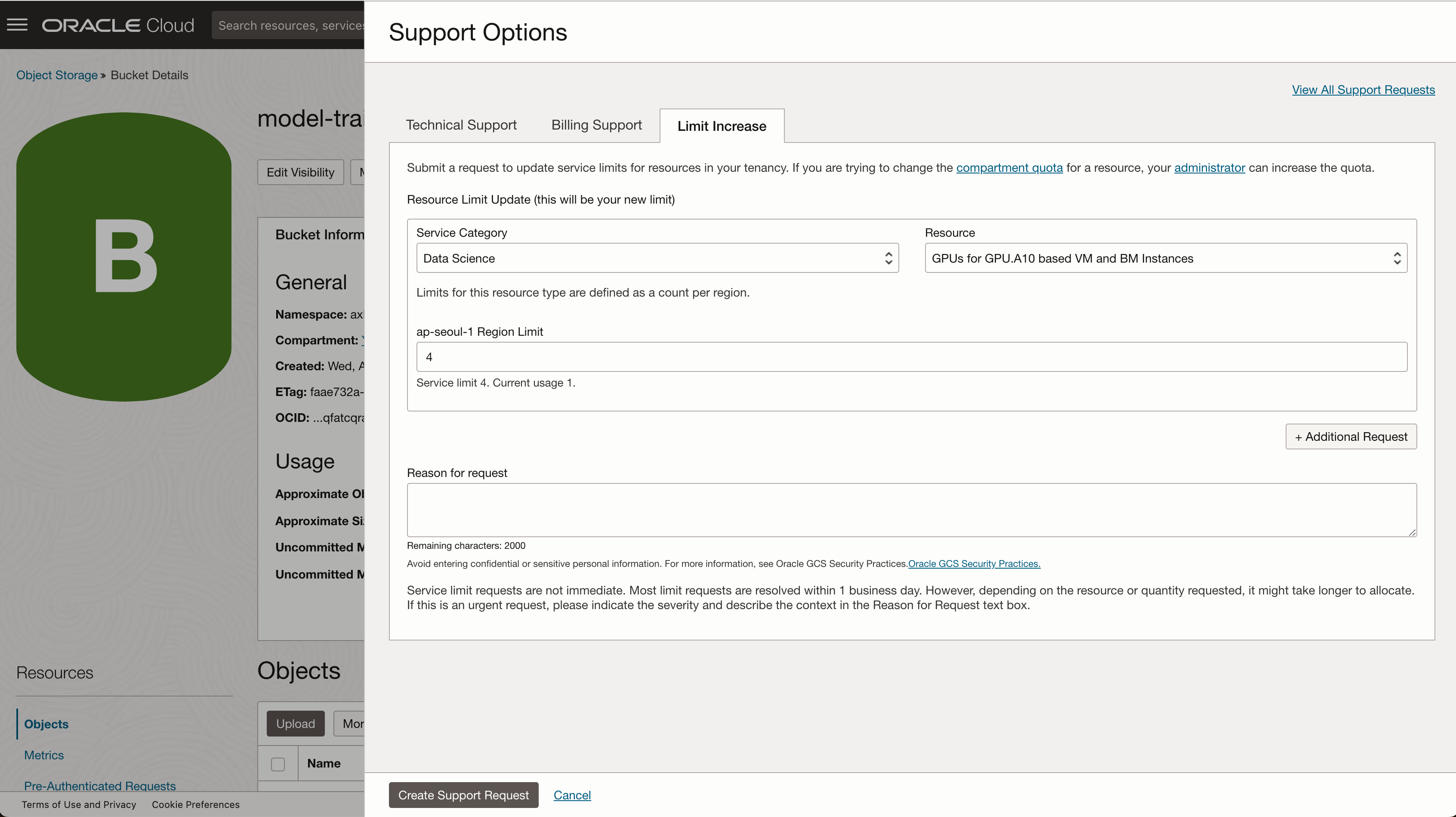
서비스 한도 증설 요청 방법은 아래 포스팅을 참고해주세요 OCI 지원 요청(SR)을 위해 지원 티켓을 오픈하여 지원받는 방법
2. 정책 적용
OCI AI Quick Action(AQUA)를 사용하기 위해서는 동적그룹 및 정책을 생성해야 합니다. OCI 에서는 이러한 작업을 간편하게 수행할 수 있도록 Terraform 스크립트를 제공하고 있습니다. 아래 내용을 순서대로 진행하여 정책을 적용합니다.
2-1. Terraform을 활용한 정책 적용
- ORM 스택 사용을 위한 정책 설정 Terraform 스크립트를 실행하기 전에 다음 권한이 부여되었는지 확인합니다:
Note: 이미 Data Science 서비스를 사용할수 있는 정책이 작성되어 있더라도 Terraform 구성 파일을 사용하여 ORM 스택을 통해 AI Quick Actions에서 사용할 정책을 설정하기 위한 정책이 필요합니다.
allow group <your_admin_group> to manage orm-stacks in TENANCY
allow group <your_admin_group> to manage orm-jobs in TENANCY
allow group <your_admin_group> to manage dynamic-groups in TENANCY
allow group <your_admin_group> to manage policies in TENANCY
allow group <your_admin_group> to read compartments in TENANCY
- Terraform 스크립트 다운로드 테라폼 구성파일 oci-ods-aqua-orm.zip 을 다운로드 받습니다.
- 리소스 매니저(Resource Manager) - 스택(Stacks) 메뉴로 이동합니다.
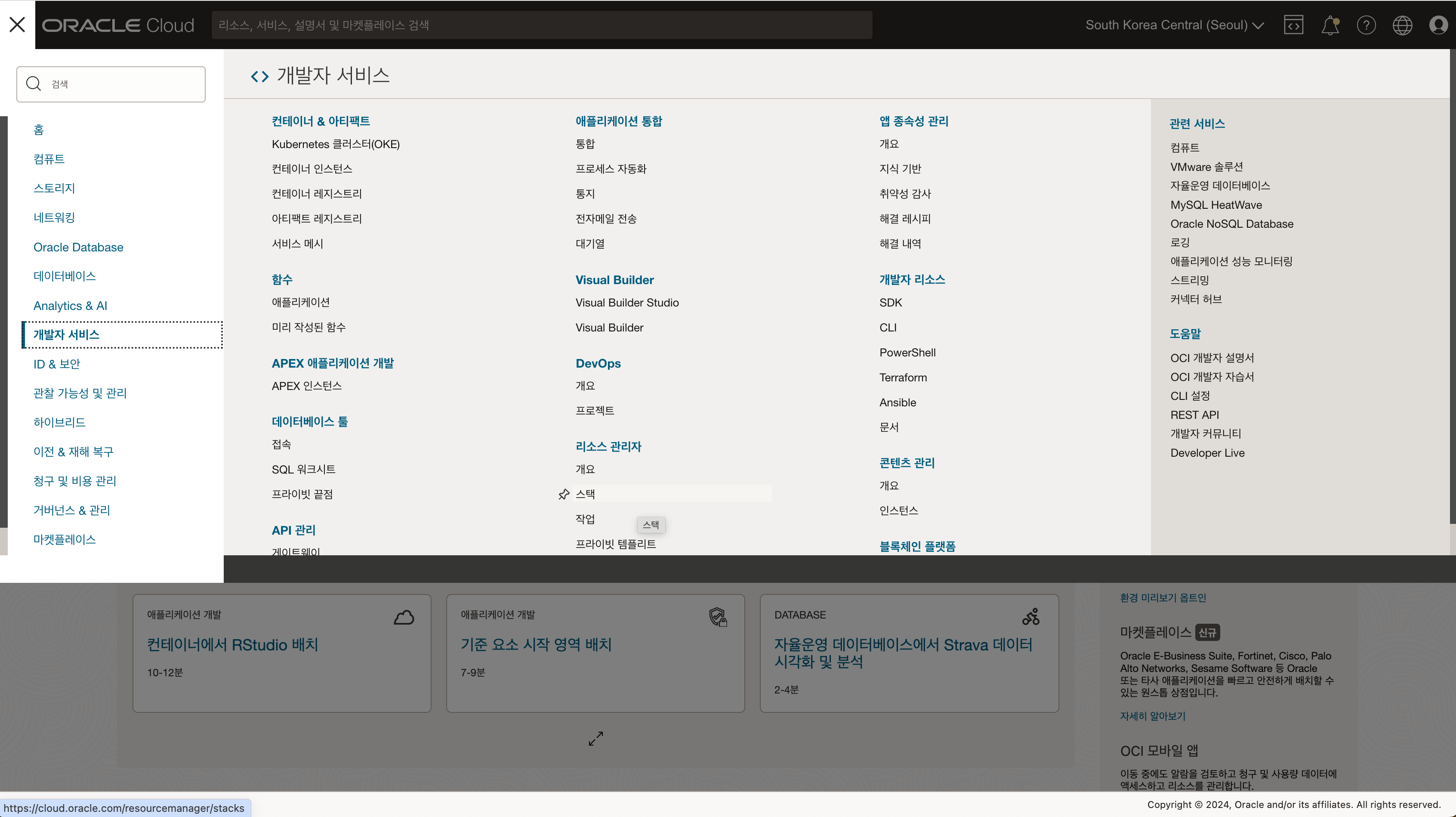
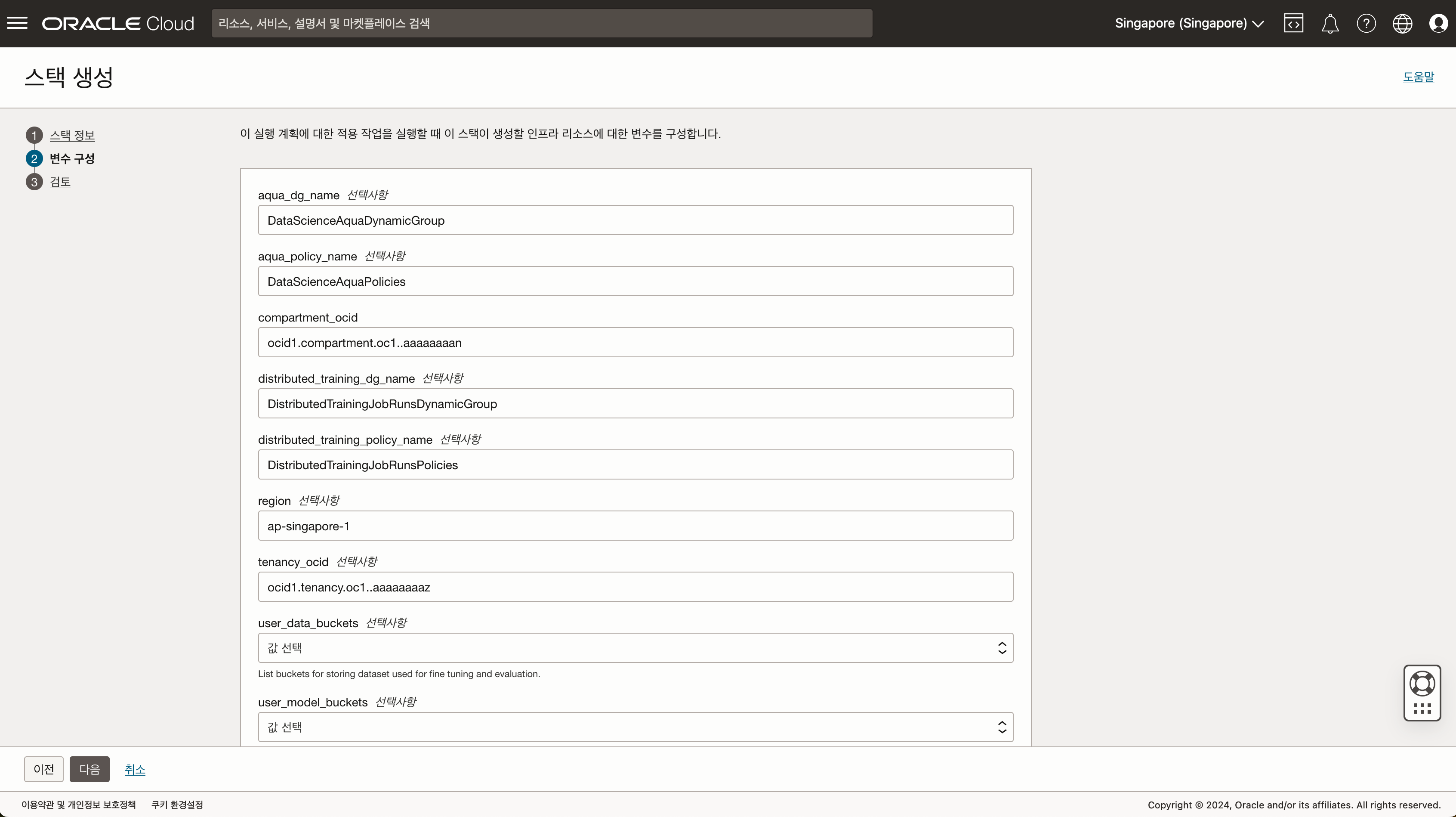
- 실습을 진행할 구획을 선택한 후 스택 생성을 클릭하고, 다운로드 받은 zip 파일을 업로드 합니다.
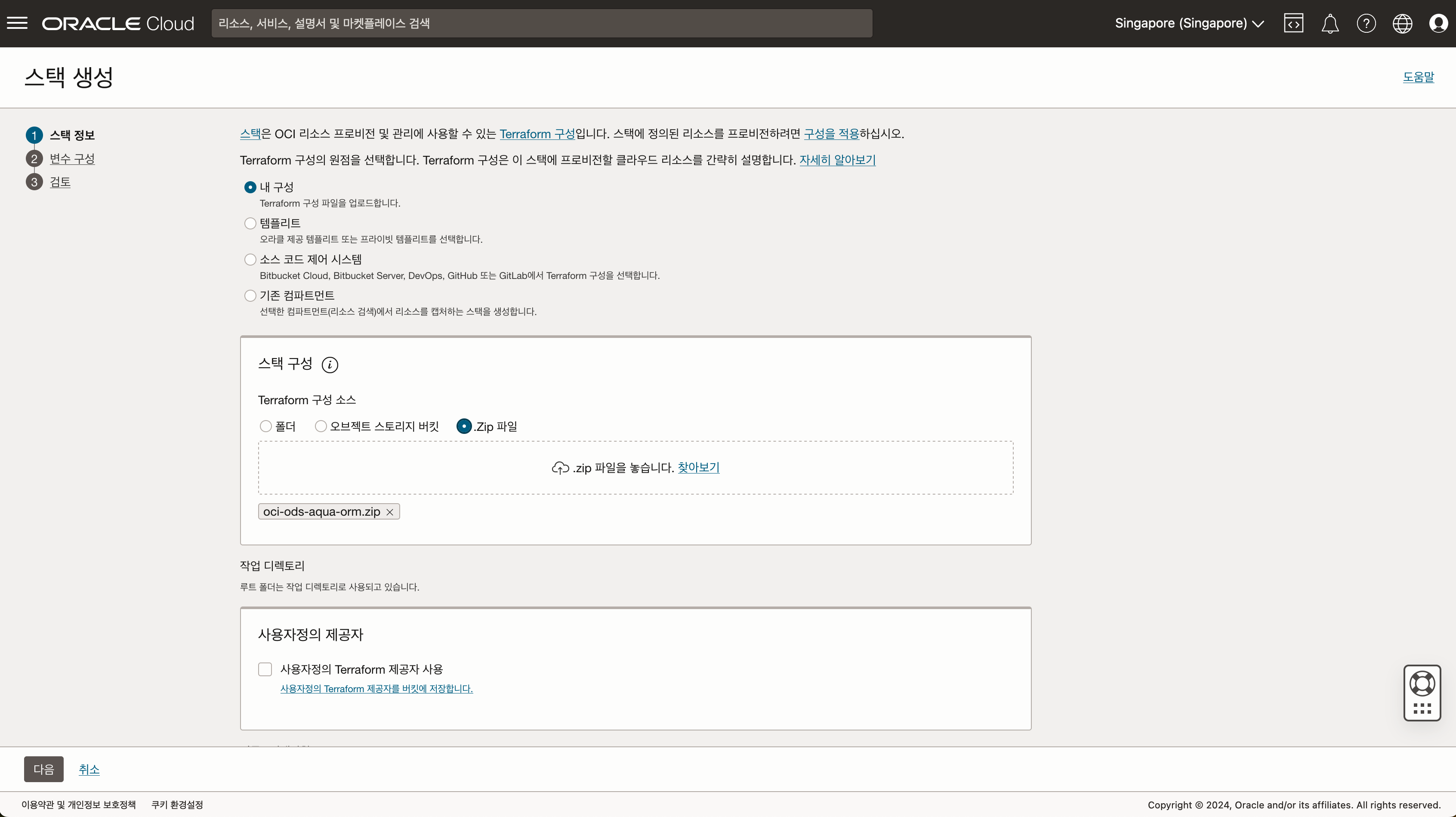
- 설정내용을 확인 후 스택을 생성합니다.
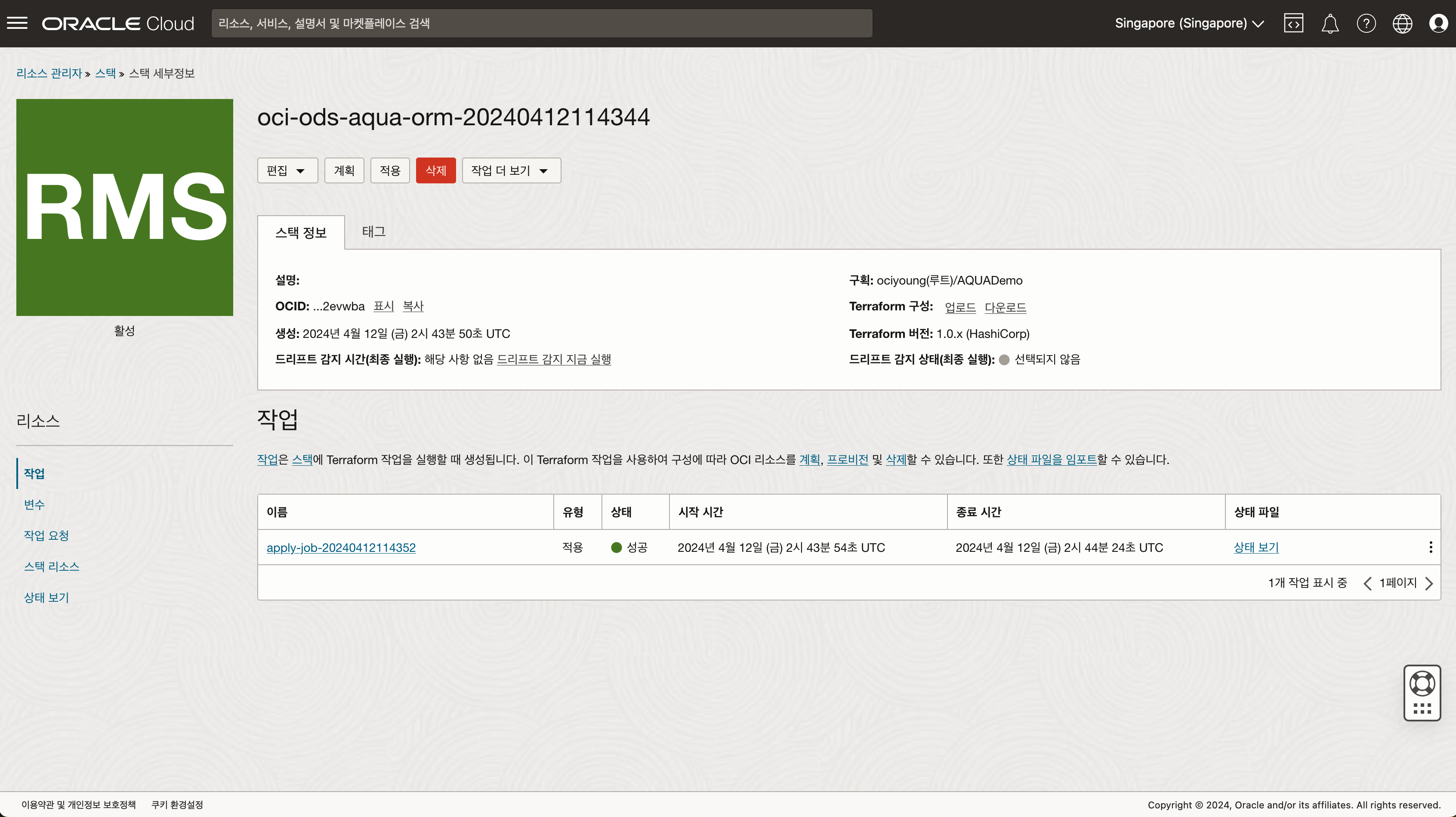
- 생성된 스택에서 적용 작업을 실행합니다.
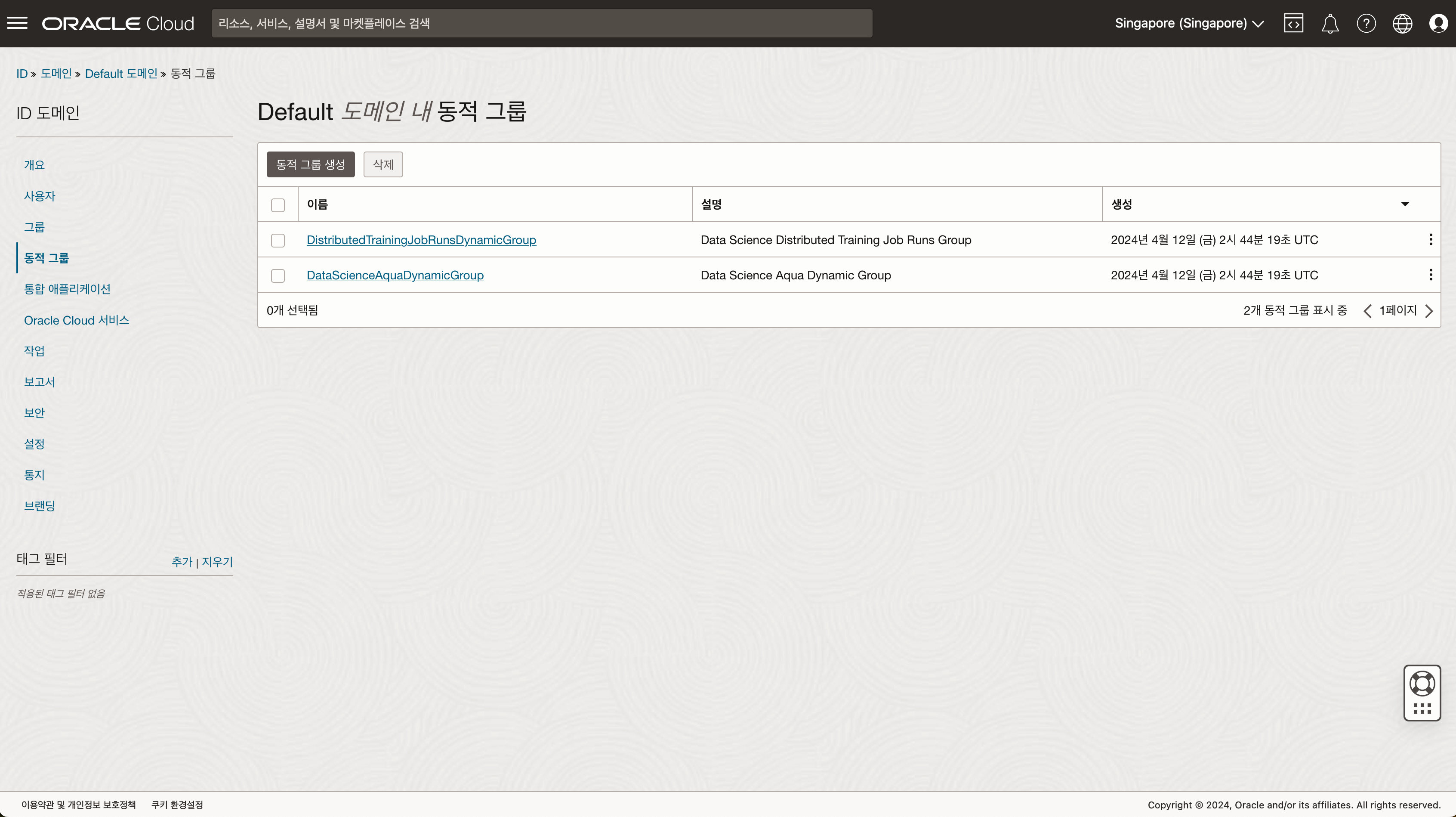
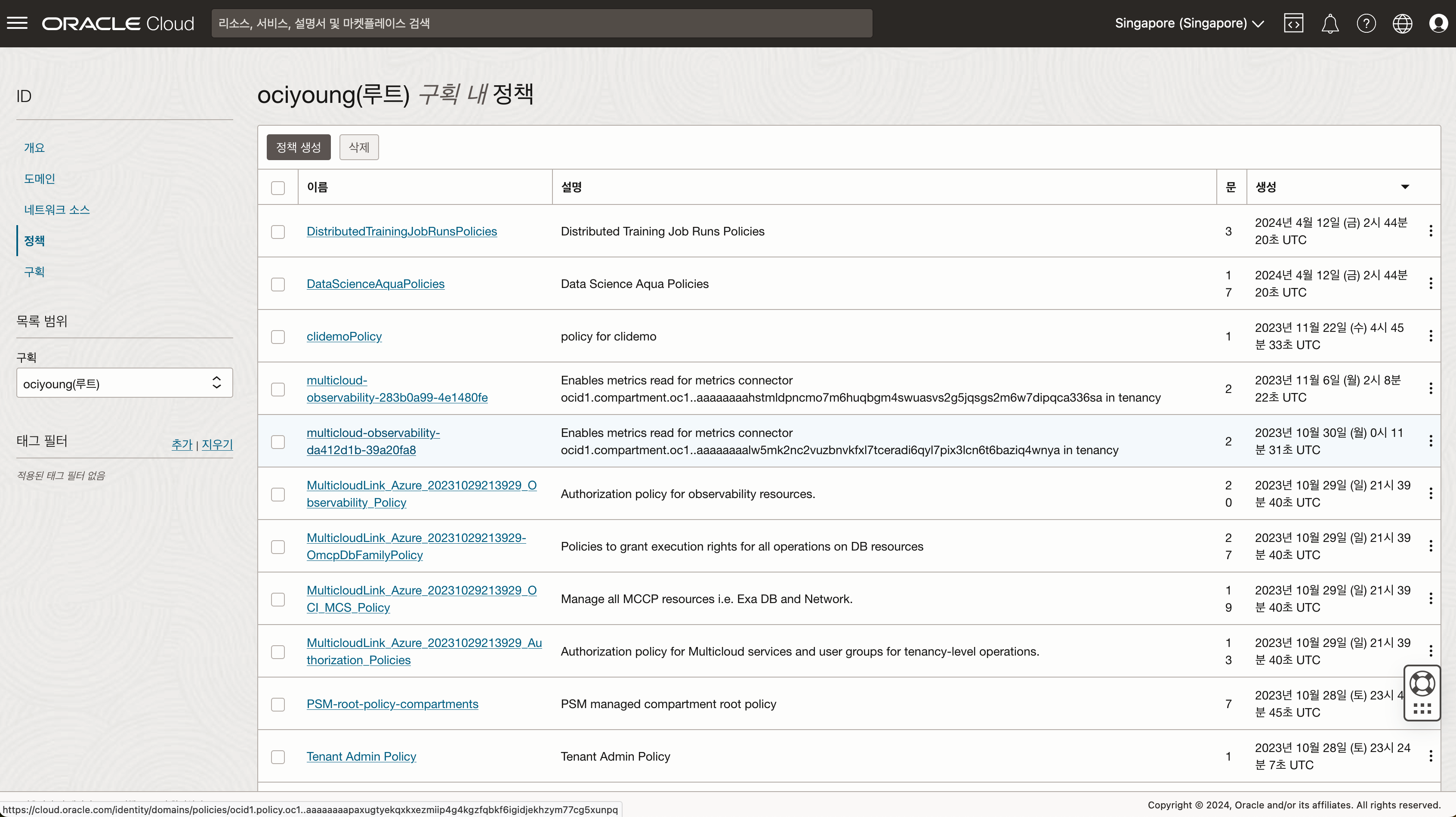
- 생성된 정책을 확인합니다.
2-2. 수작업으로 정책 적용하기
아래 동적 그룹 및 정책을 단계별로 생성 합니다. 이러한 정책과 동적 그룹은 사용자의 OCI 환경 내에서 AI Quick Action을 가능하게 하기 위해 필요한 권한을 설정합니다. “
동적 그룹 (Dynamic Groups) - 도메인 메뉴 하위에서 생성 가능
aqua-dynamic-groupany {all {resource.type='datasciencenotebooksession', resource.compartment.id='<your_compartment_ocid>'}, all {resource.type='datasciencemodeldeployment',resource.compartment.id='<your_compartment_ocid>'}, all {resource.type='datasciencejobrun', resource.compartment.id='<your_compartment_ocid>'}}distributed_training_job_runsany {all {resource.type='datasciencejobrun', resource.compartment.id='<your_compartment_ocid>'}}
정책 (Policies) - ID & 보안 메뉴 하위에서 생성 가능
aqua_policiesDefine tenancy datascience as ocid1.tenancy.oc1..aaaaaaaax5hdic7ya6r5rxsgpifff4l6xdxzltnrncdzp3m75ubbvzqqzn3q Endorse any-user to read data-science-models in tenancy datascience where ALL {target.compartment.name='service-managed-models'} Endorse any-user to inspect data-science-models in tenancy datascience where ALL {target.compartment.name='service-managed-models'} Endorse any-user to read object in tenancy datascience where ALL {target.compartment.name='service-managed-models', target.bucket.name='service-managed-models'} Allow dynamic-group aqua-dynamic-group to manage data-science-model-deployments in compartment <your-compartment-name> Allow dynamic-group aqua-dynamic-group to manage data-science-models in compartment <your-compartment-name> Allow dynamic-group aqua-dynamic-group to use logging-family in compartment <your-compartment-name> Allow dynamic-group aqua-dynamic-group to manage data-science-jobs in compartment <your-compartment-name> Allow dynamic-group aqua-dynamic-group to manage data-science-job-runs in compartment <your-compartment-name> Allow dynamic-group aqua-dynamic-group to use virtual-network-family in compartment <your-compartment-name> Allow dynamic-group aqua-dynamic-group to read resource-availability in compartment <your-compartment-name> Allow dynamic-group aqua-dynamic-group to manage data-science-projects in compartment <your-compartment-name> Allow dynamic-group aqua-dynamic-group to manage data-science-notebook-sessions in compartment <your-compartment-name> Allow dynamic-group aqua-dynamic-group to manage data-science-modelversionsets in compartment <your-compartment-name> Allow dynamic-group aqua-dynamic-group to read buckets in compartment <your-compartment-name> Allow dynamic-group aqua-dynamic-group to read objectstorage-namespaces in compartment <your-compartment-name> Allow dynamic-group aqua-dynamic-group to inspect compartments in tenancy Allow dynamic-group aqua-dynamic-group to manage object-family in compartment <your-compartment-name> where any {target.bucket.name='<your-bucket-name>'}dt_jr_policiesAllow dynamic-group distributed_training_job_runs to use logging-family in compartment <your-compartment-name> Allow dynamic-group distributed_training_job_runs to manage data-science-models in compartment <your-compartment-name> Allow dynamic-group distributed_training_job_runs to read data-science-jobs in compartment <your-compartment-name> Allow dynamic-group distributed_training_job_runs to manage objects in compartment <your-compartment-name> where any {target.bucket.name='<your-bucket-name>'} Allow dynamic-group distributed_training_job_runs to read buckets in compartment <your-compartment-name> where any {target.bucket.name='<your-bucket-name>'}
3. Data Science 노트북 세션
OCI AQUA는 Data Science 노트북 세션을 기반으로 동작합니다. 정책이 모두 작성된 이후 기존 세션을 비활성화/활성화 하거나, 새로운 세션을 생성하여 AI Quick Action을 활성화 할 수 있습니다.
4. 버킷 준비하기 (옵션)
OCI AQUA 에서는 Fine-Tune 작업에 필요한 데이터셋을 Object Storage 또는 노트북 세션에서 불러와서 작업을 생성할 수 있습니다. 만약 Fine-tune 작업을 염두하고 있다면 Output 버킷은 객체 버전 지정 을 활성화 해야 합니다. 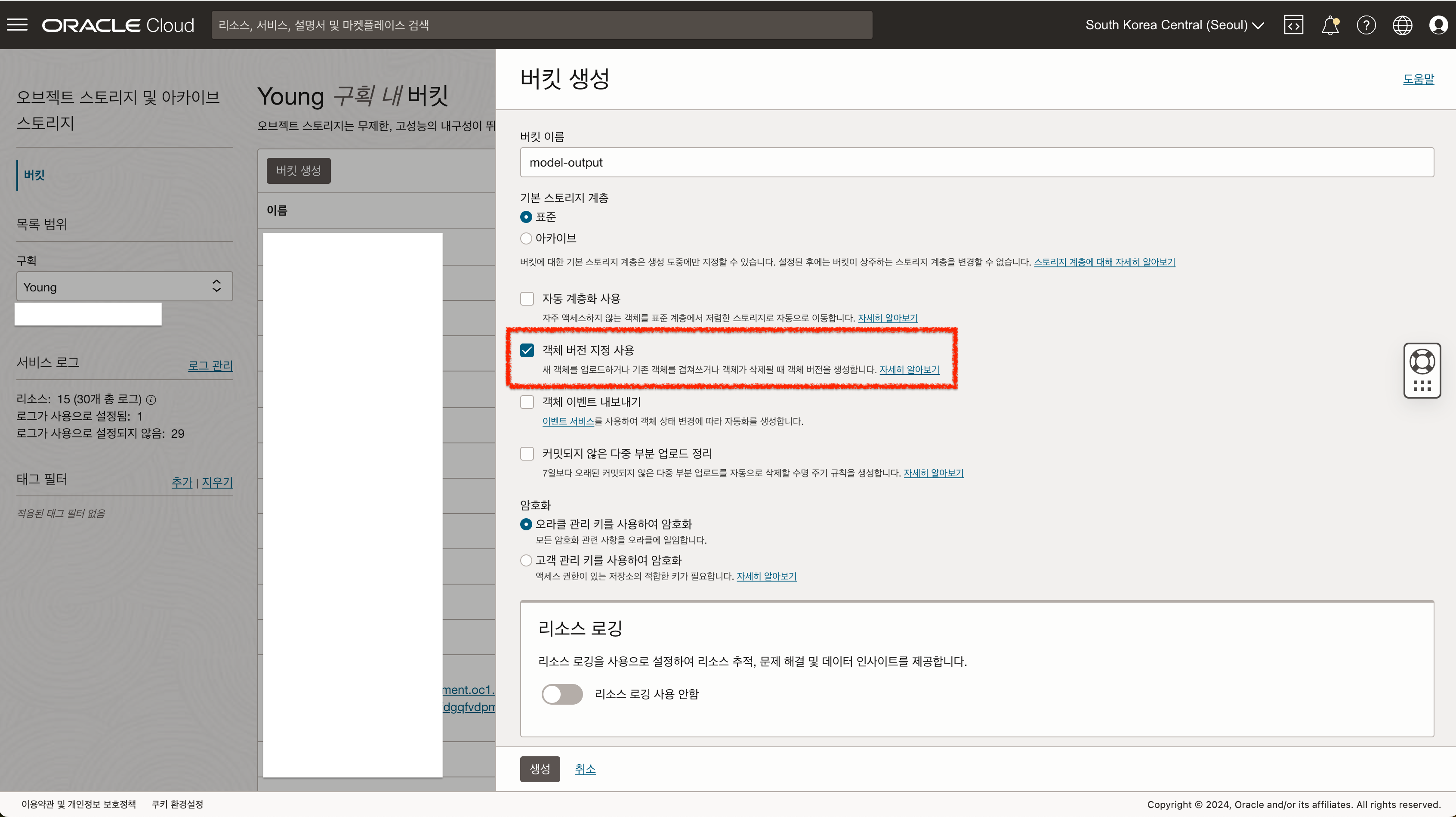
만약 버킷을 이미 생성하였다면 객체 버전 지정 편집 버튼을 통해 활성화 해야 합니다. 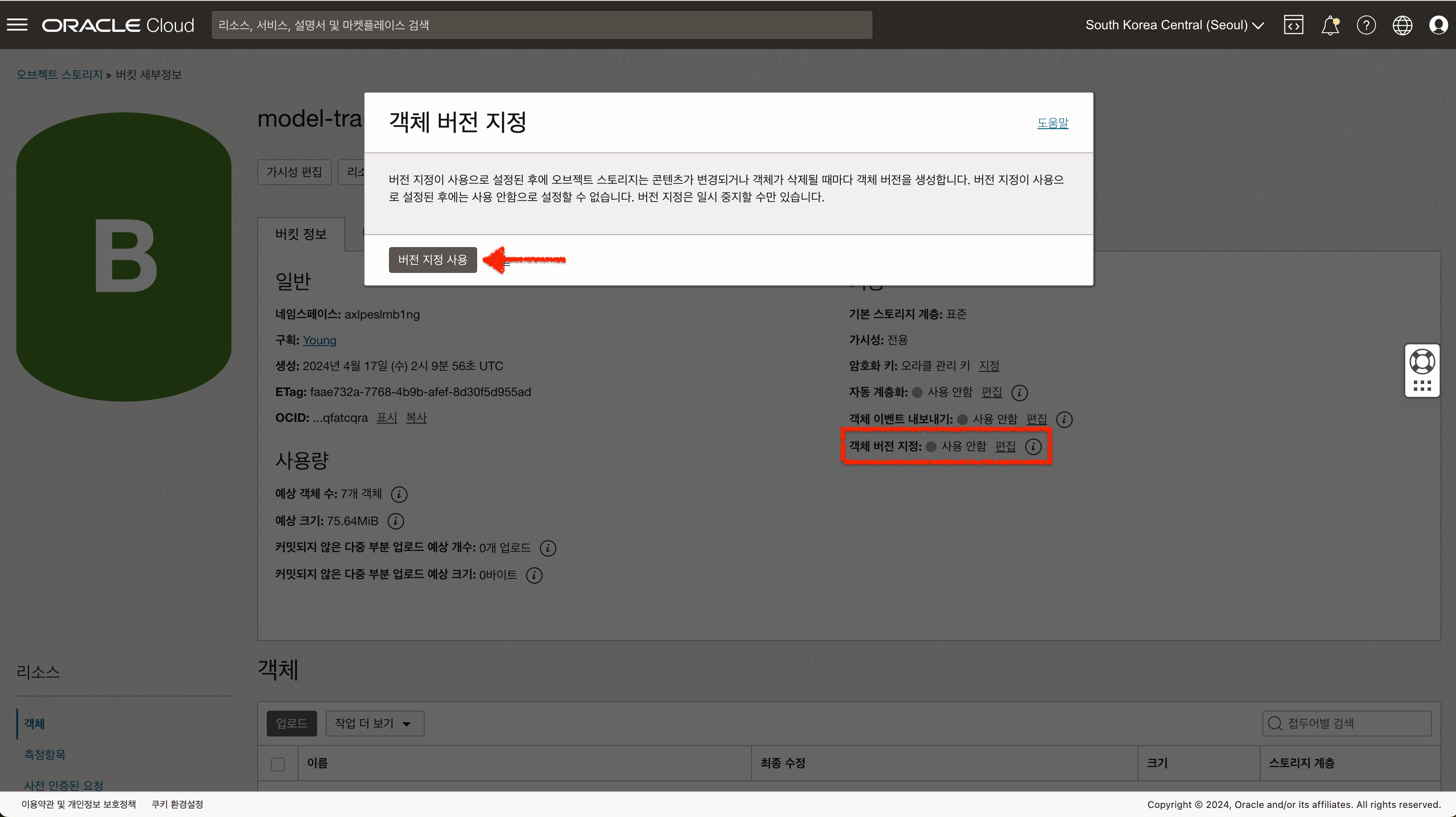
5. 데이터셋 준비하기 (옵션)
OCI AQUA 에서 Fine-Tune 작업을 수행하기 위해서는 학습에 필요한 데이터셋을 준비해야 합니다.
주의 사항
- 학습을 진행하기 위해서는 50개 이상의 데이터가 필요합니다.
- 각각 질문, 답변의 길이가 너무 길 경우 오류가 발생할 수 있습니다. (필자가 테스트를 통해 한글 기준 1000자 까지 가능함을 확인함)
- 파일 포멧 : jsonl 포멧으로 준비
- jsonl 포멧은 json 포멧을 한 줄에 하나의 레코드로 저장하는 방식입니다.
- 학습에 사용될 데이터는 jsonl 포멧으로 준비해야 합니다.
- jsonl 포멧 예시
{"prompt":"<s>[INST]<<SYS>>[모델에게 지시할 내용]<</SYS>>[질문 내용][\/INST]","completion":"[답변 내용]","category": null} {"prompt":"<s>[INST]<<SYS>>당신은 클라우드 전문가입니다. 도움이 되고 상세하며 정확한 답변을 제공합니다.<</SYS>>OCI 가상머신 서비스에 대해서 설명해줘[\/INST]","completion":"가상 머신(VM)은 소규모 개발 프로젝트에서 실시간 통신 플랫폼과 같은 대규모 글로벌 애플리케이션에 이르는 워크로드를 위해 클라우드에서 안전하고 탄력적인 컴퓨팅 용량을 제공합니다. 유연한 모양을 통해 사용자는 가격 대비 성능을 향상시키기 위해 맞춤형 프로세서 및 메모리 값으로 VM 리소스를 최적화할 수 있습니다.","category": null}
AI Quick Action 사용하기
노트북 세션에 접속 후 런처 화면의 AI Quick Action 메뉴를 클릭하여 AQUA 서비스를 사용할 수 있습니다. 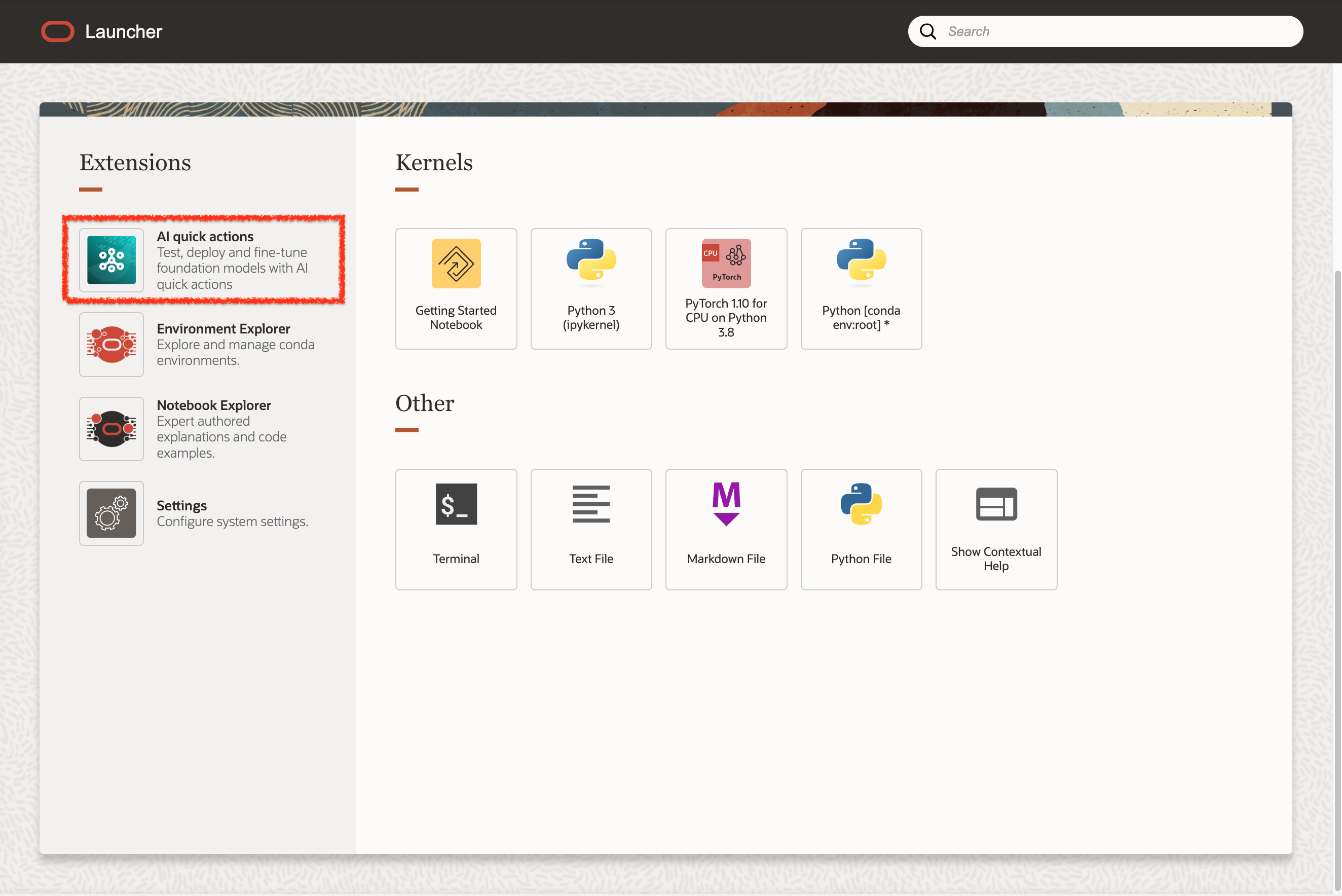
1. Foundation 모델 배포하기
AQUA에서는 GPU A10 자원을 활용하여 모델을 배포합니다. 모델 크기에 따라 A10 GPU를 최소 1장~4장까지 사용할 수 있습니다.
- AI Quick Action 메인 화면에서 배포하고자 하는 모델을 선택합니다.
- 모델 상세 페이지에서
Deploy버튼을 클릭합니다.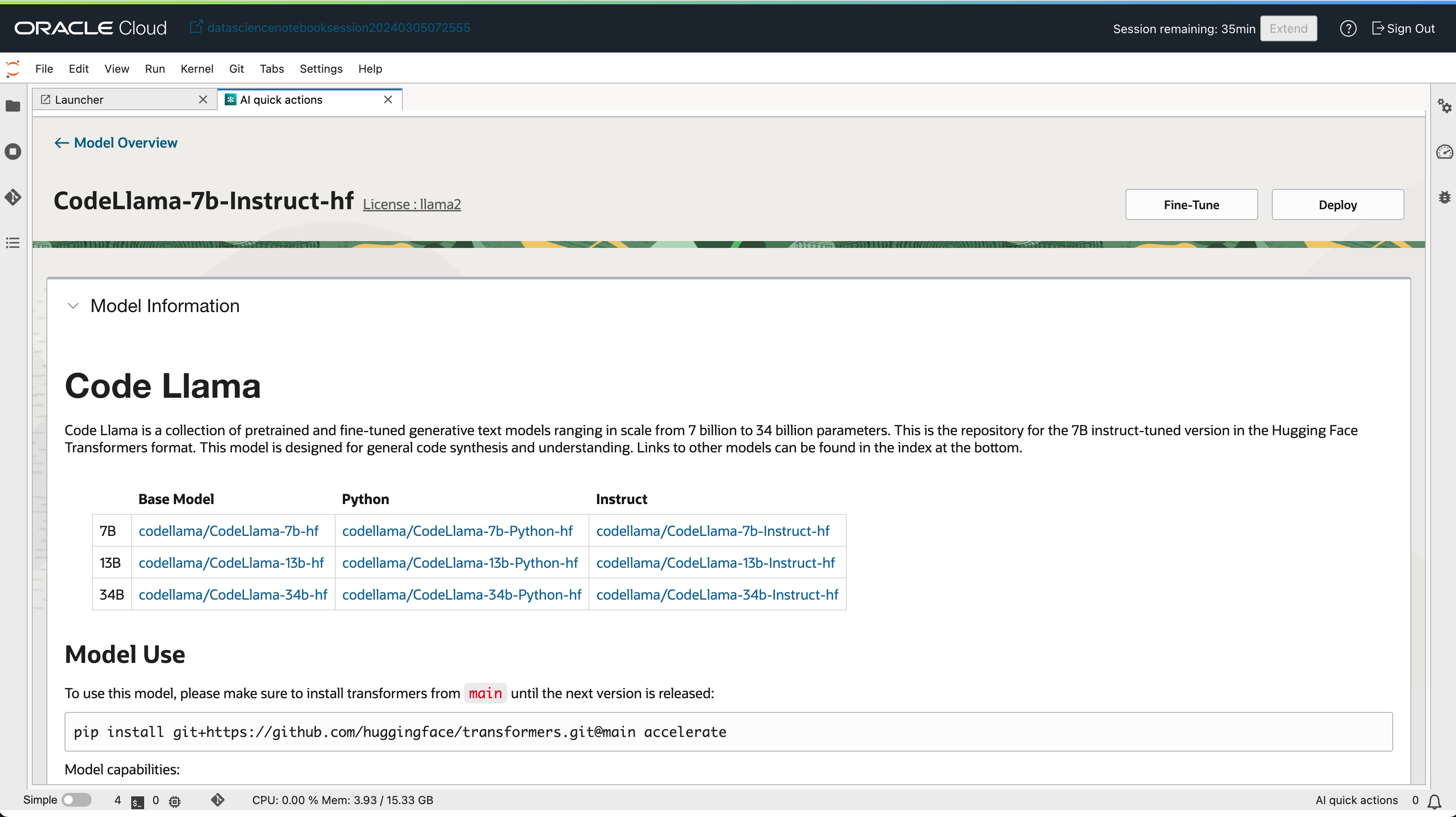
- 모델 배포 이름, Compute Shape 등 간단한 정보만 입력 후 모델을 배포할 수 있습니다.
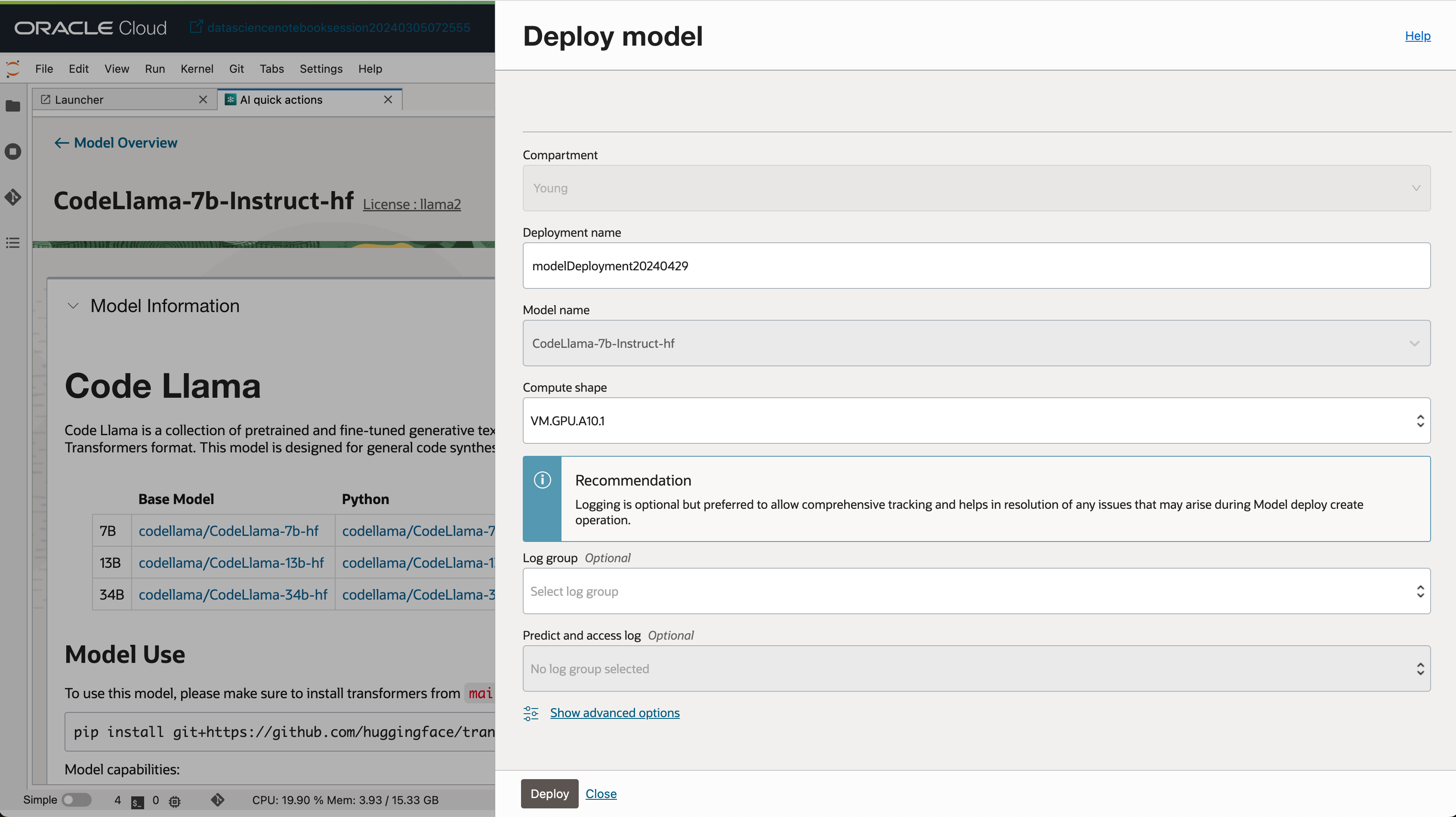
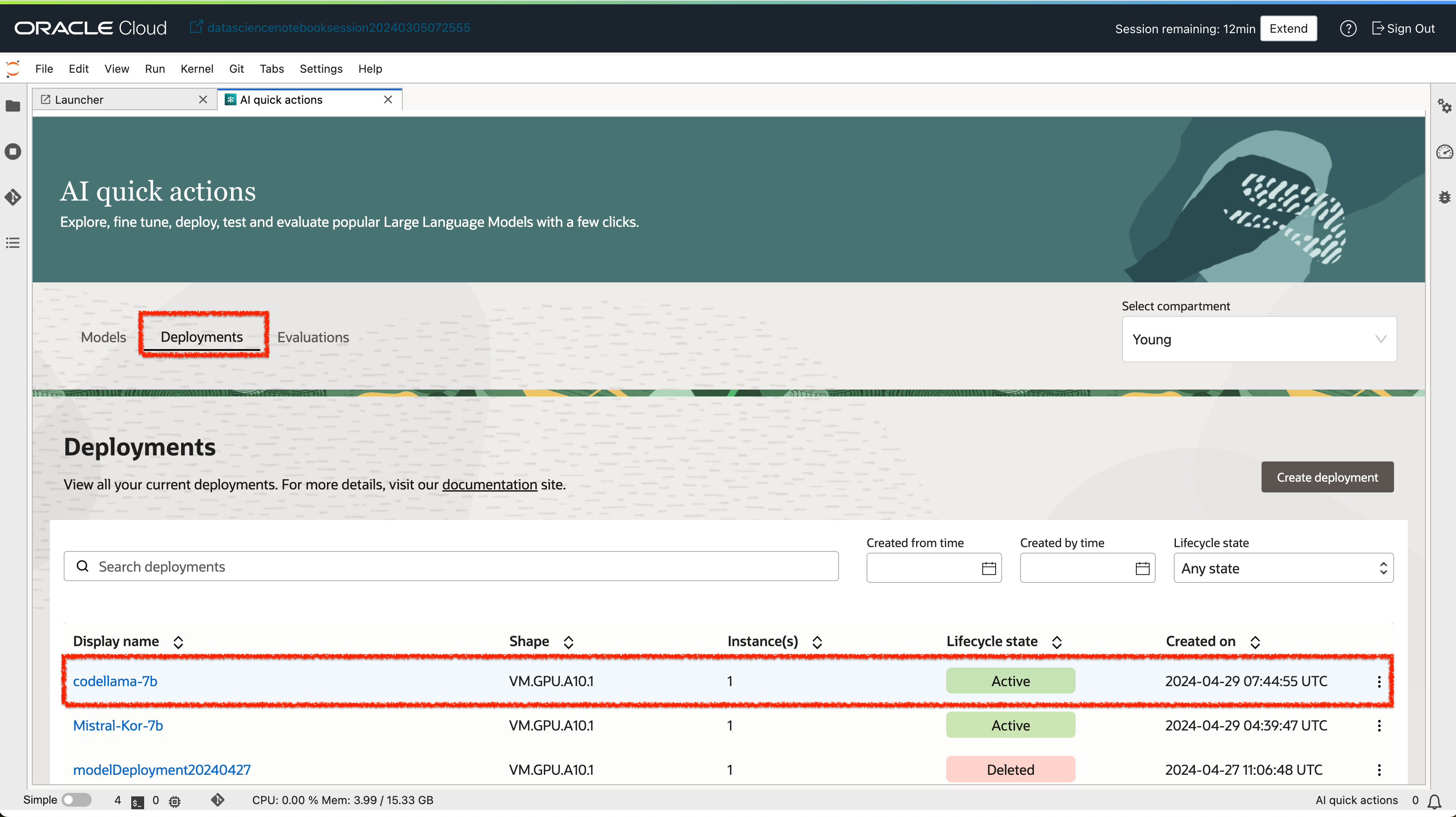
- 배포가 완료된 모델은 Deployment 탭에서 확인할 수 있습니다.
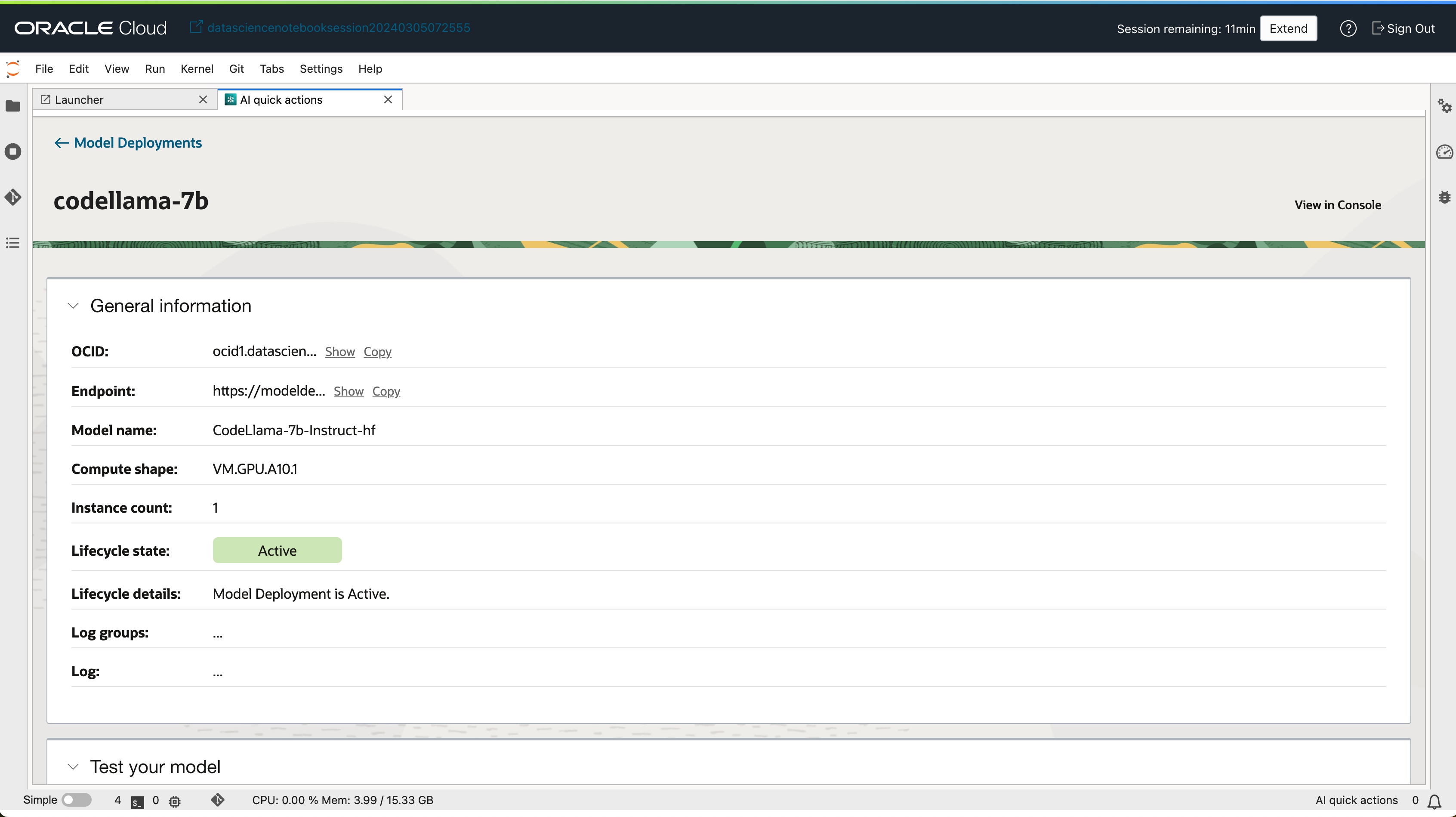
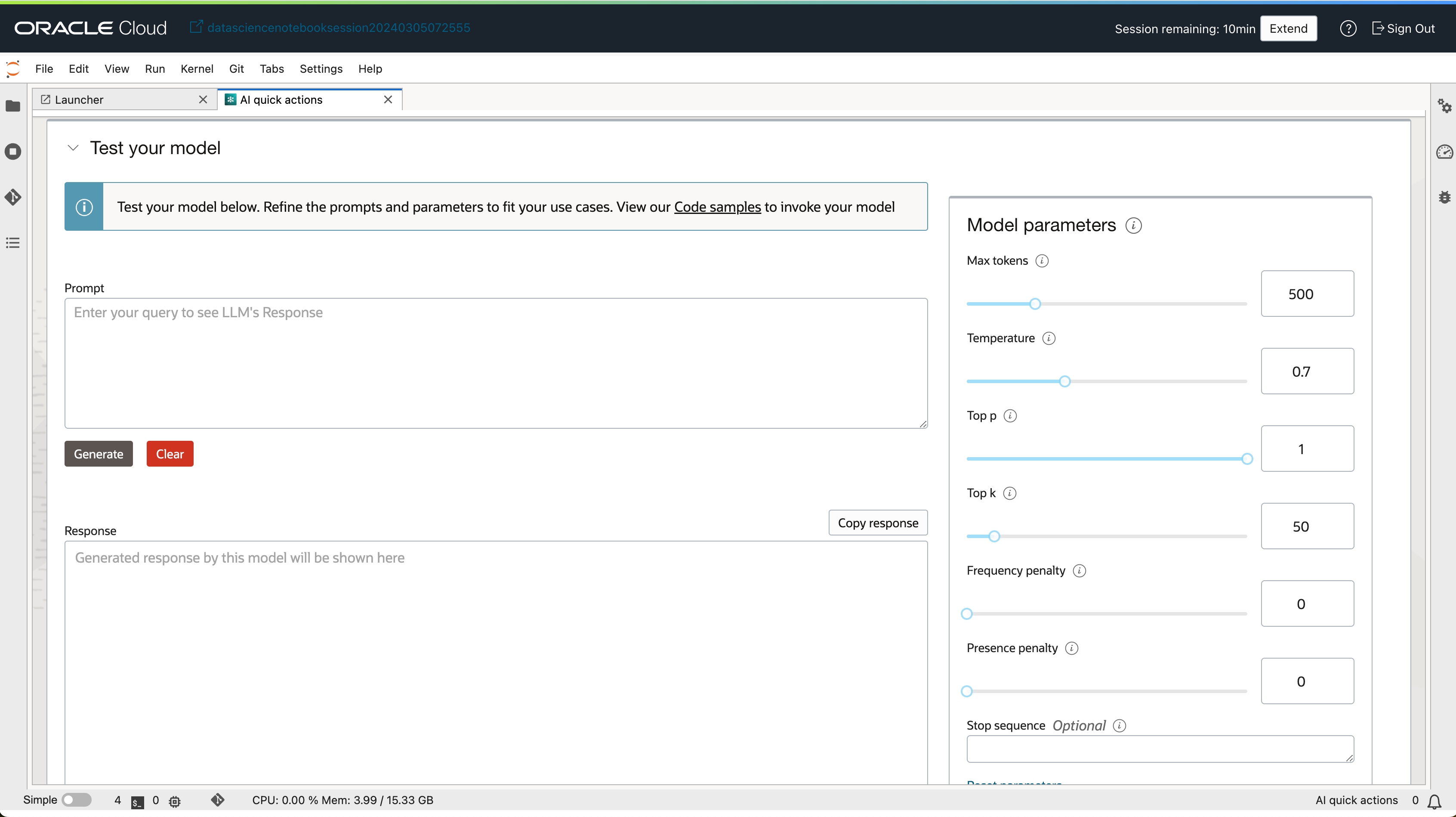
- 배포된 모델 상세보기 화면에서 모델을 테스트할 수 있는 UI도 함께 제공 됩니다.
2. 모델 Fine-tuning 하기
AQUA에서 모델을 미세조정(Fine-tune)하기 위해서는 A10 GPU를 최소 2장~4장까지 사용할 수 있습니다. 충분한 리소스가 있는지 미리 확인이 필요합니다.
Fine-tune 주의사항
- 사전 준비 사항 4,5번 항목을 미리 준비해야 합니다.
- Fine-tune 작업을 생성할 때에는 Networking 옵션을 지정하지 않아야 합니다.
2-1. 모델 Fine-tuning 하기
- AI Quick Action 메인 화면에서 Fine-tune 하고자 하는 모델을 선택합니다.
- 모델 상세 페이지에서
Fine Tune버튼을 클릭합니다.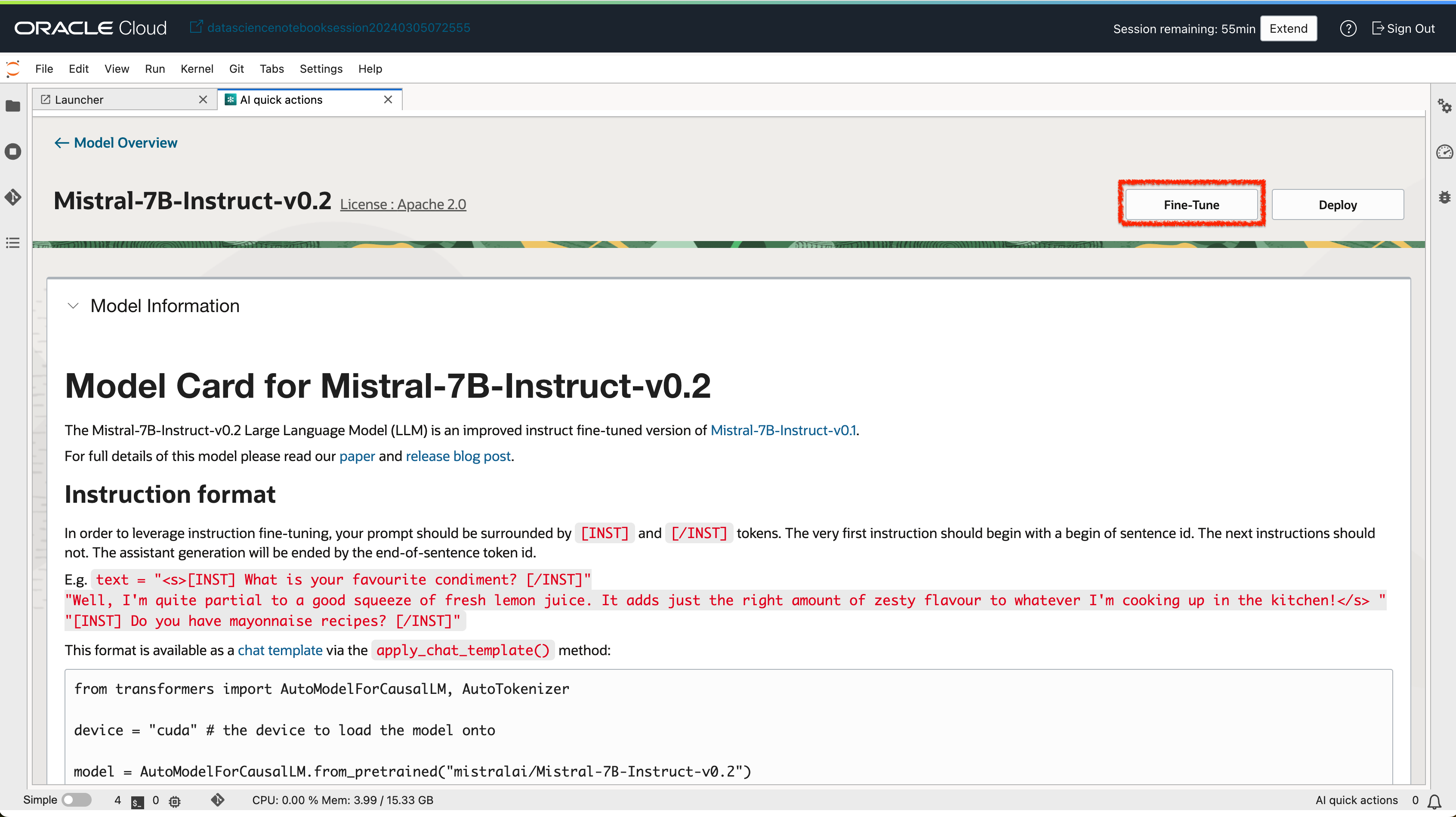
- 튜닝할 모델의 이름을 지정합니다.
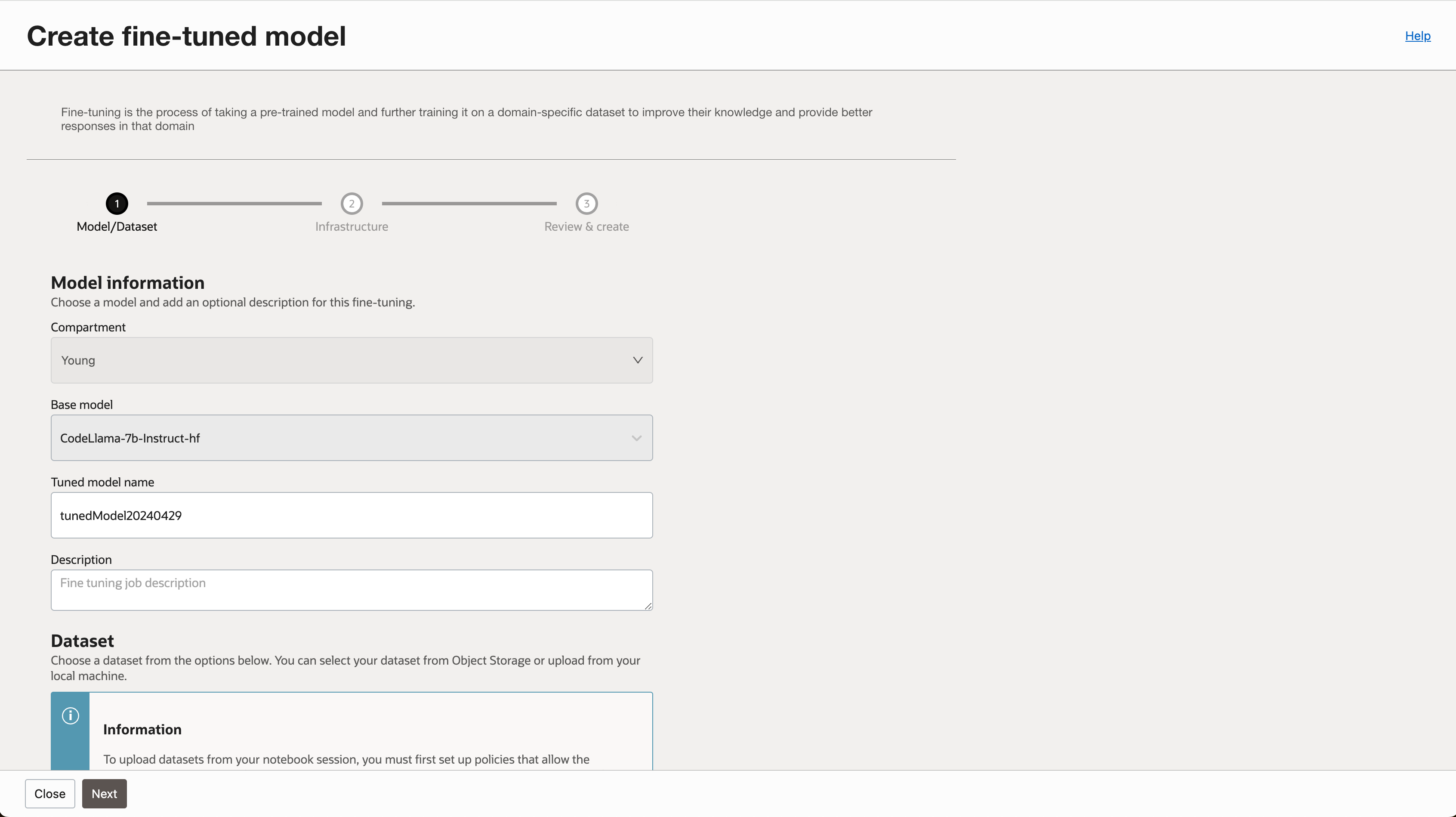
- 학습에 필요한 데이터셋 경로를 지정합니다. (실습에서는 Object Storage 기준으로 진행하였습니다.)
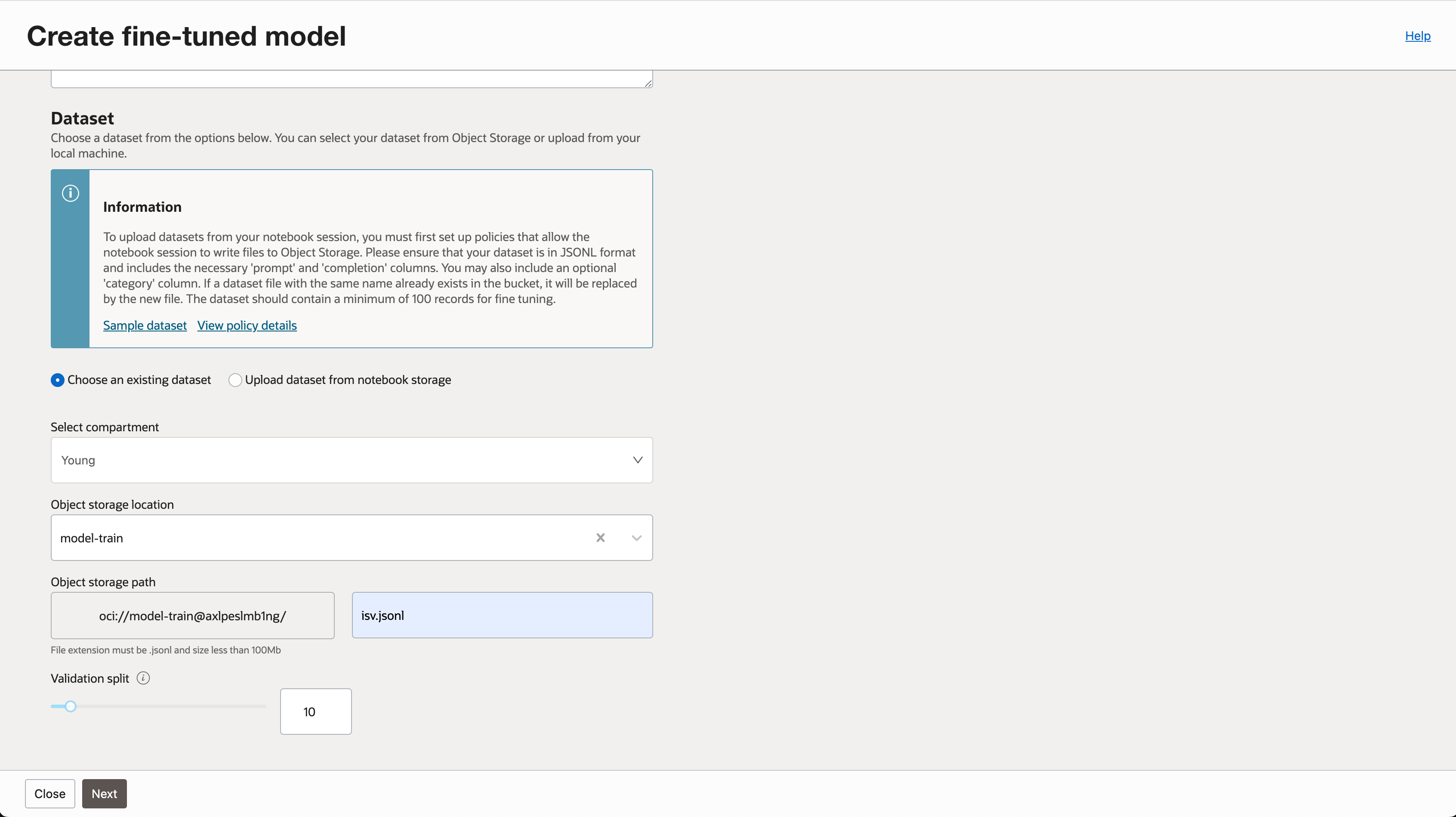
- 학습 결과물을 저장할 버킷을 지정합니다.
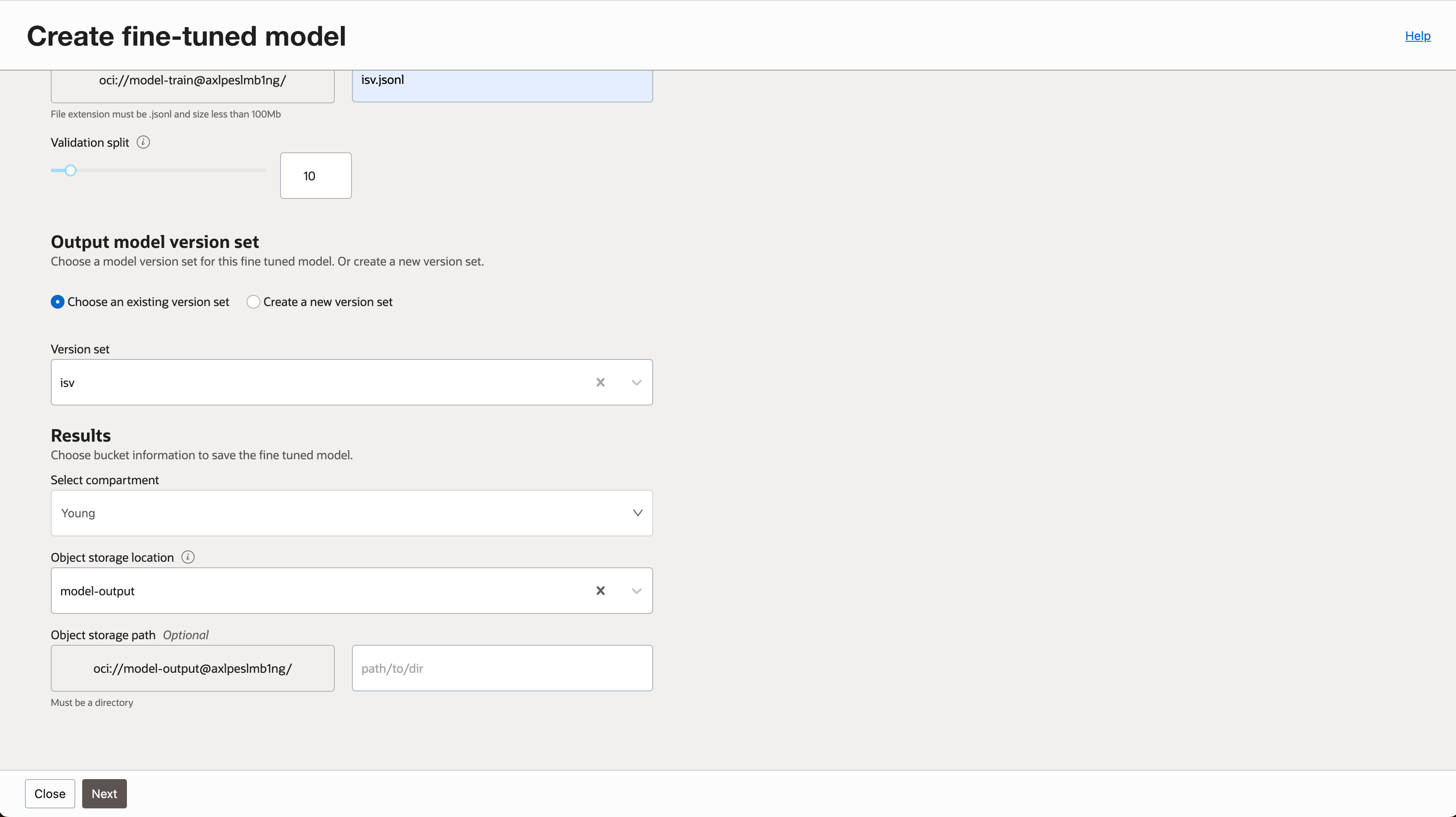
- 학습에 사용될 Instance Shape을 선택합니다. Networking 옵션을 지정하지 않아야 합니다. (지정할 경우 오류 발생함)
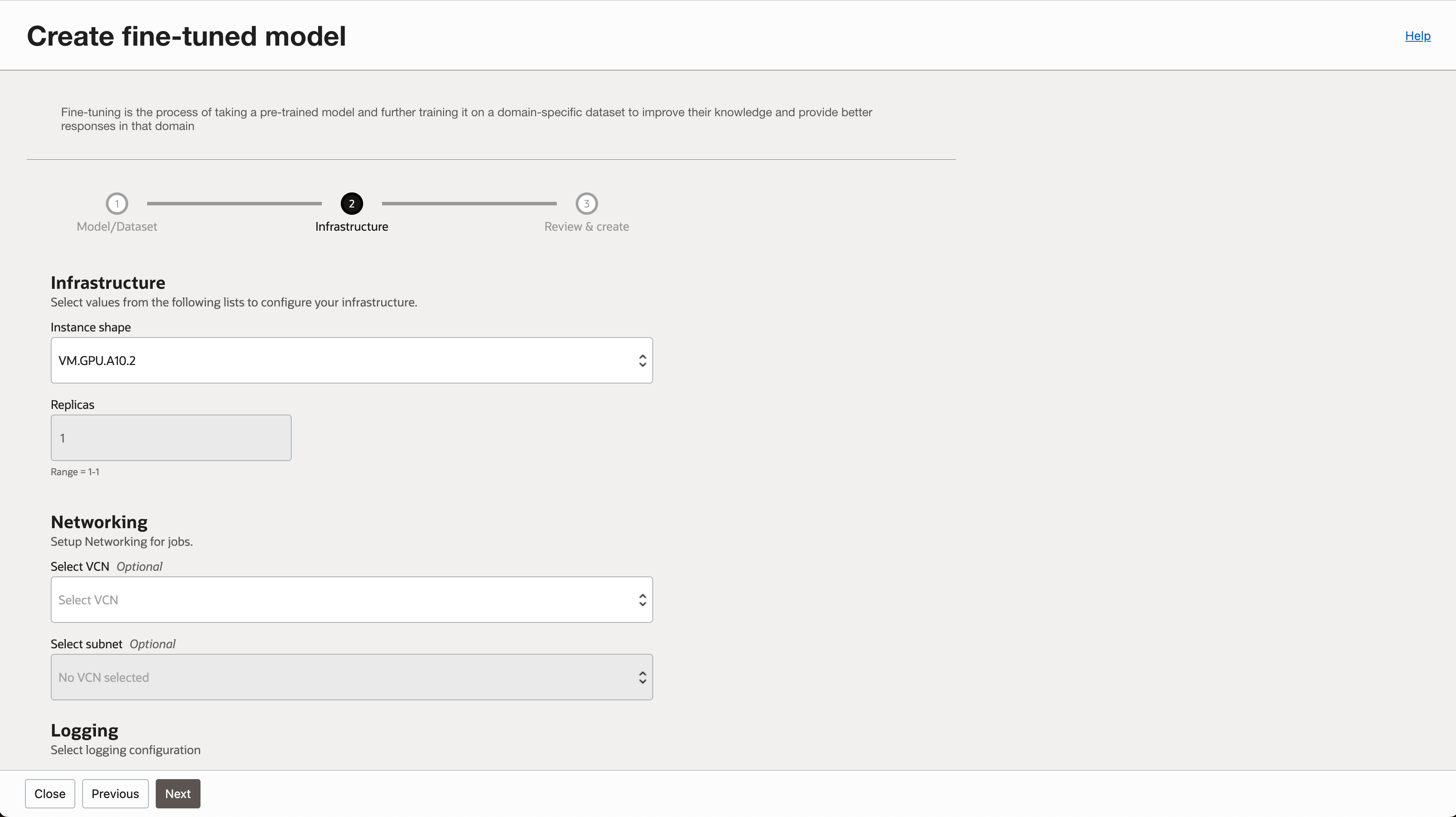
- 필요한 경우 로깅 옵션을 지정 합니다.
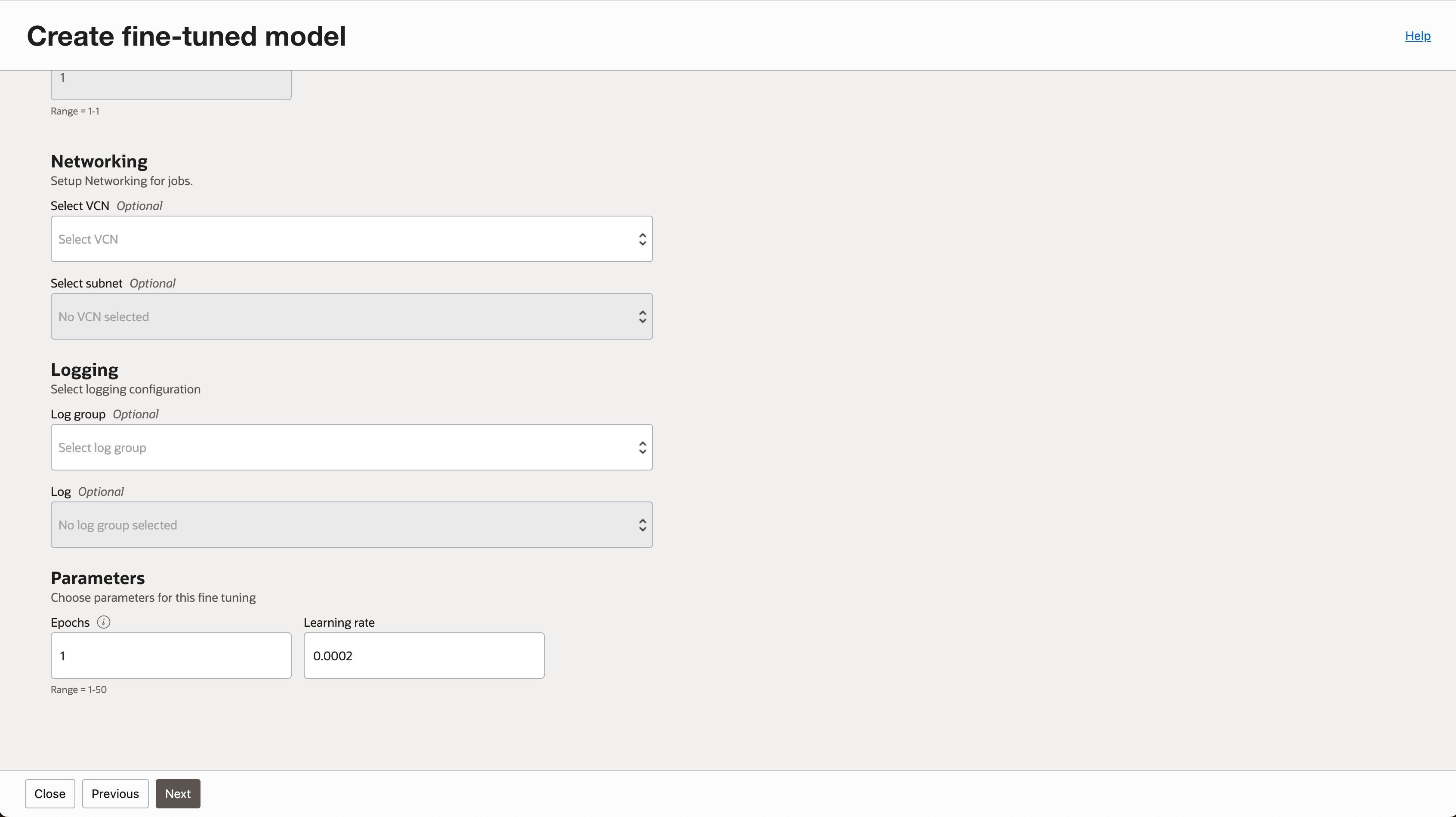
- 입력 내용을 검토하고 작업을 생성합니다.
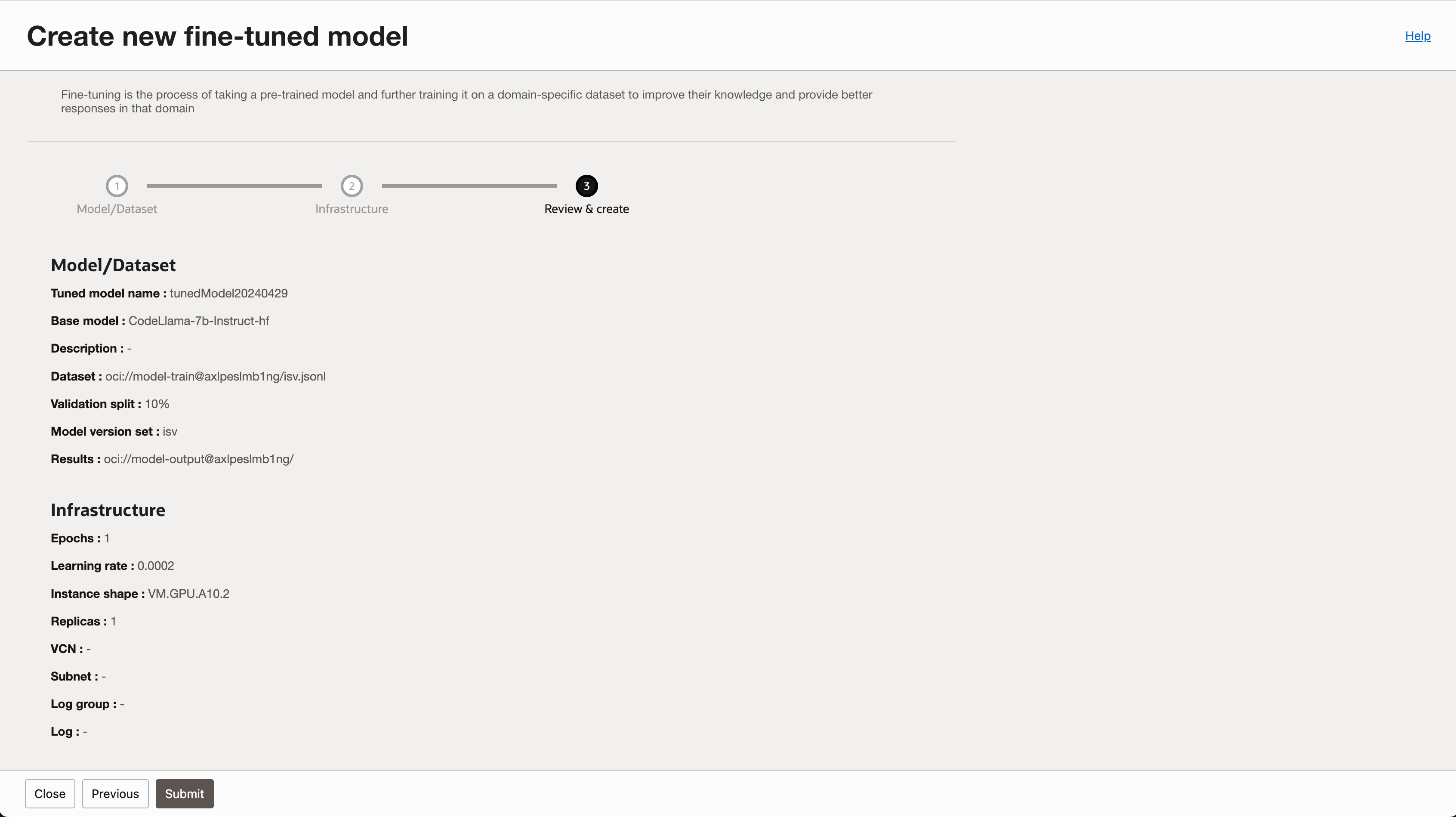
2-2. Fine-tune 완료된 모델 배포하기
미세조정 학습이 완료된 모델은 Fine-tuned models 탭에서 확인할 수 있습니다. 목록의 모델 중 Ready to Deploy 뱃지가 활성화된 모델만 배포할 수 있습니다.
- Fine-tuned models 탭에서 배포하고자 하는 모델을 선택합니다.
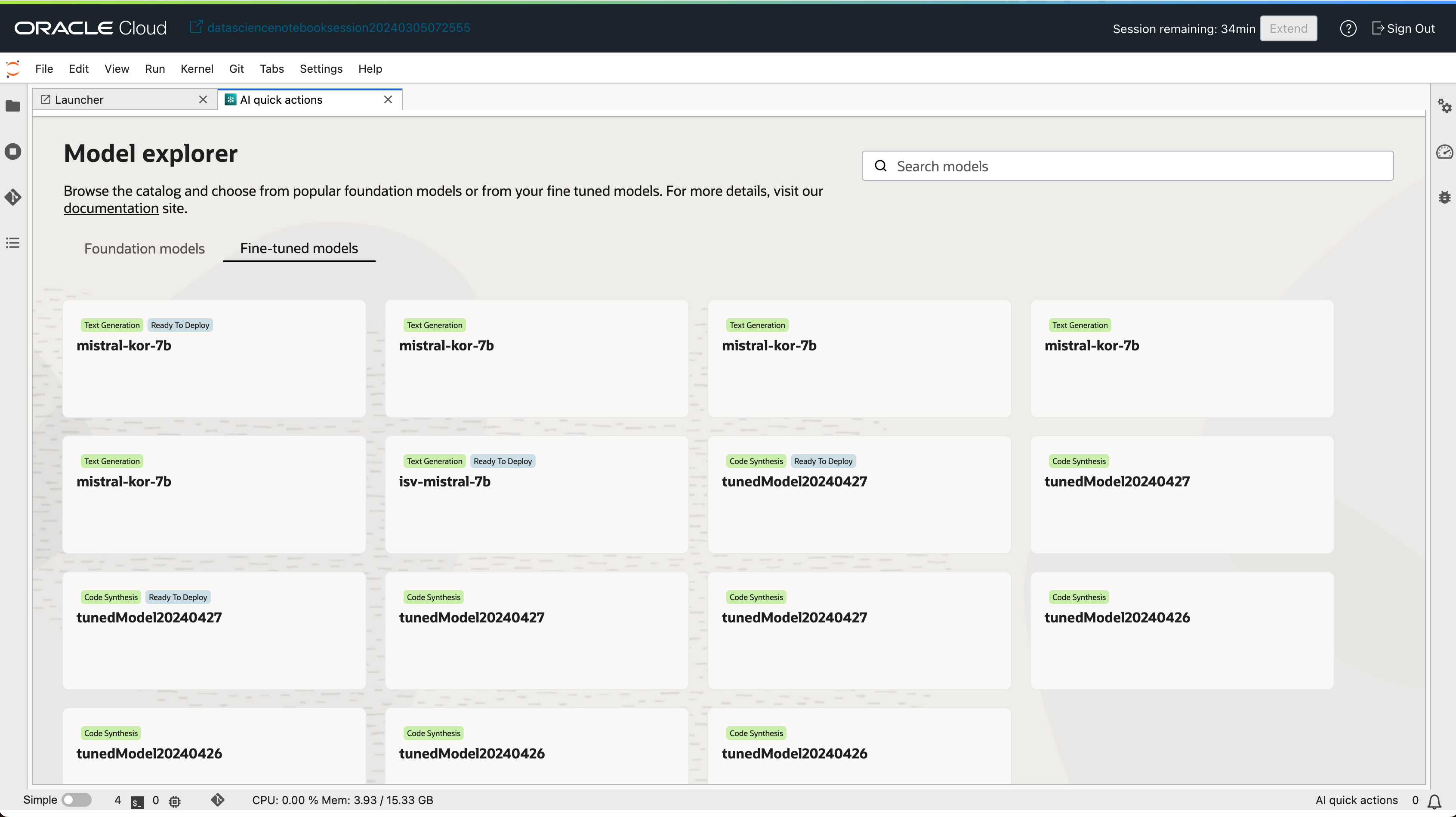
- 모델 상세 페이지에서
Deploy버튼을 클릭합니다.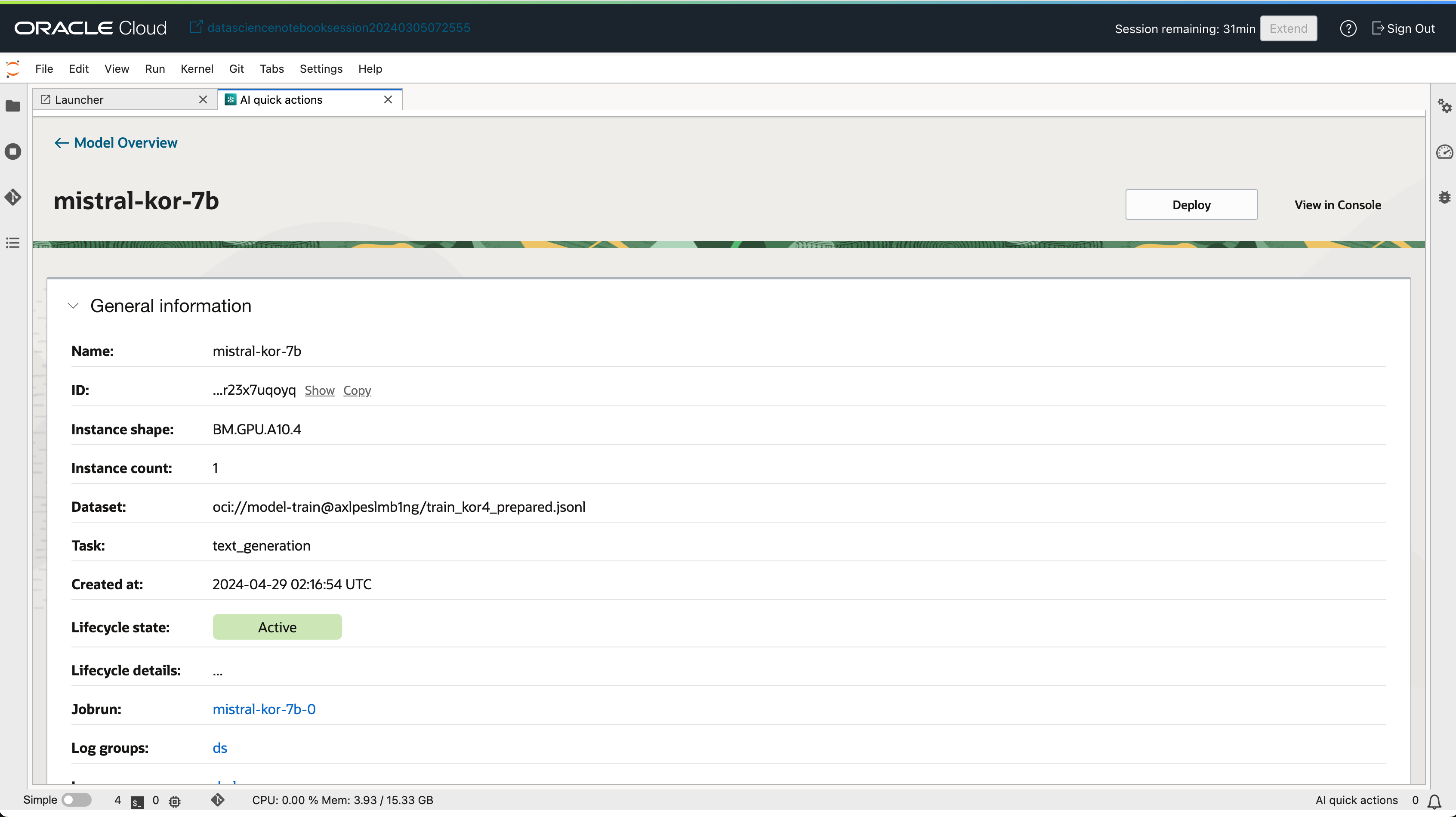
- 모델 배포 이름, Compute Shape 등 간단한 정보만 입력 후 모델을 배포할 수 있습니다.
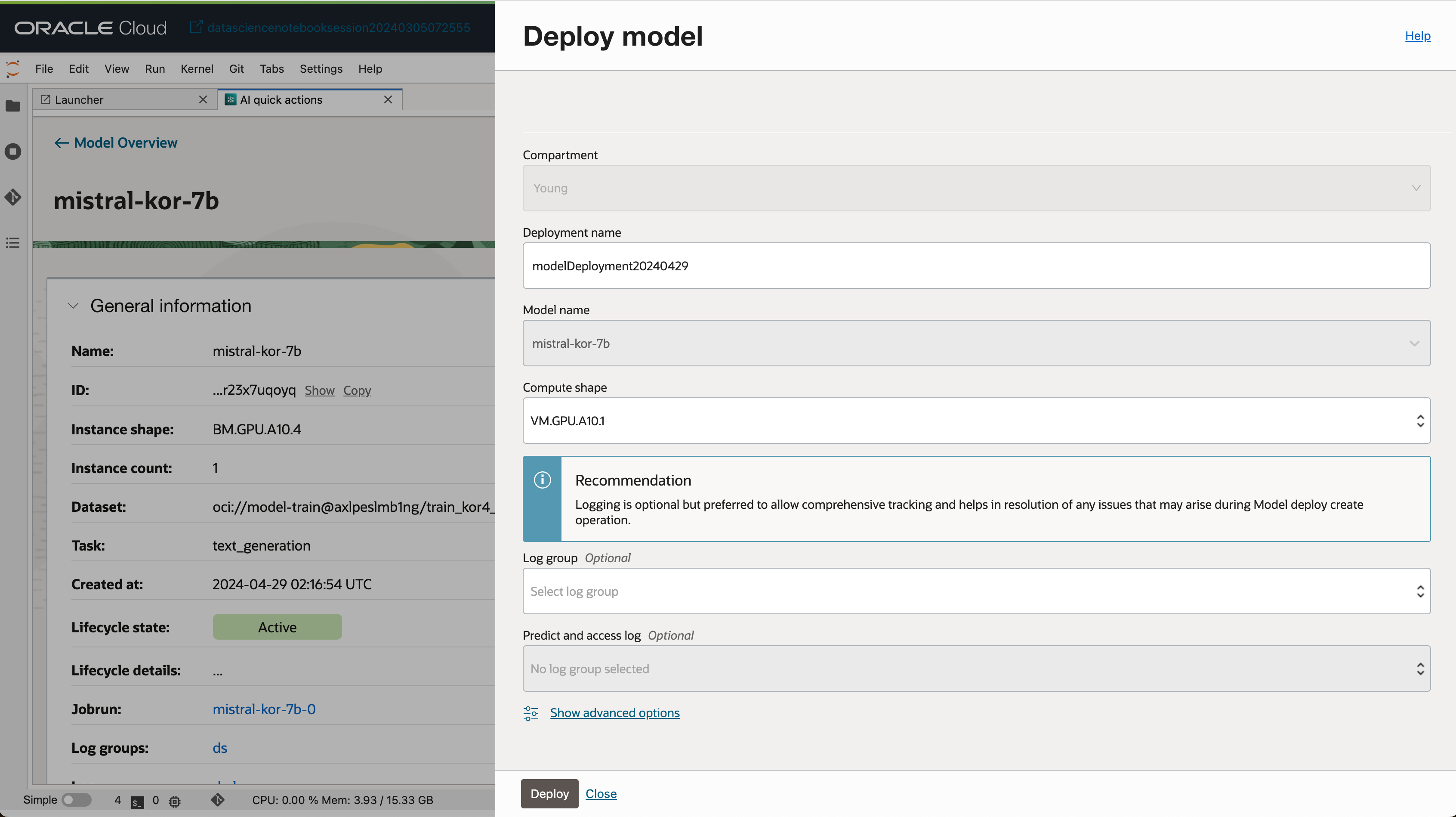
- 배포가 완료된 모델은 Deployment 탭에서 확인할 수 있습니다.
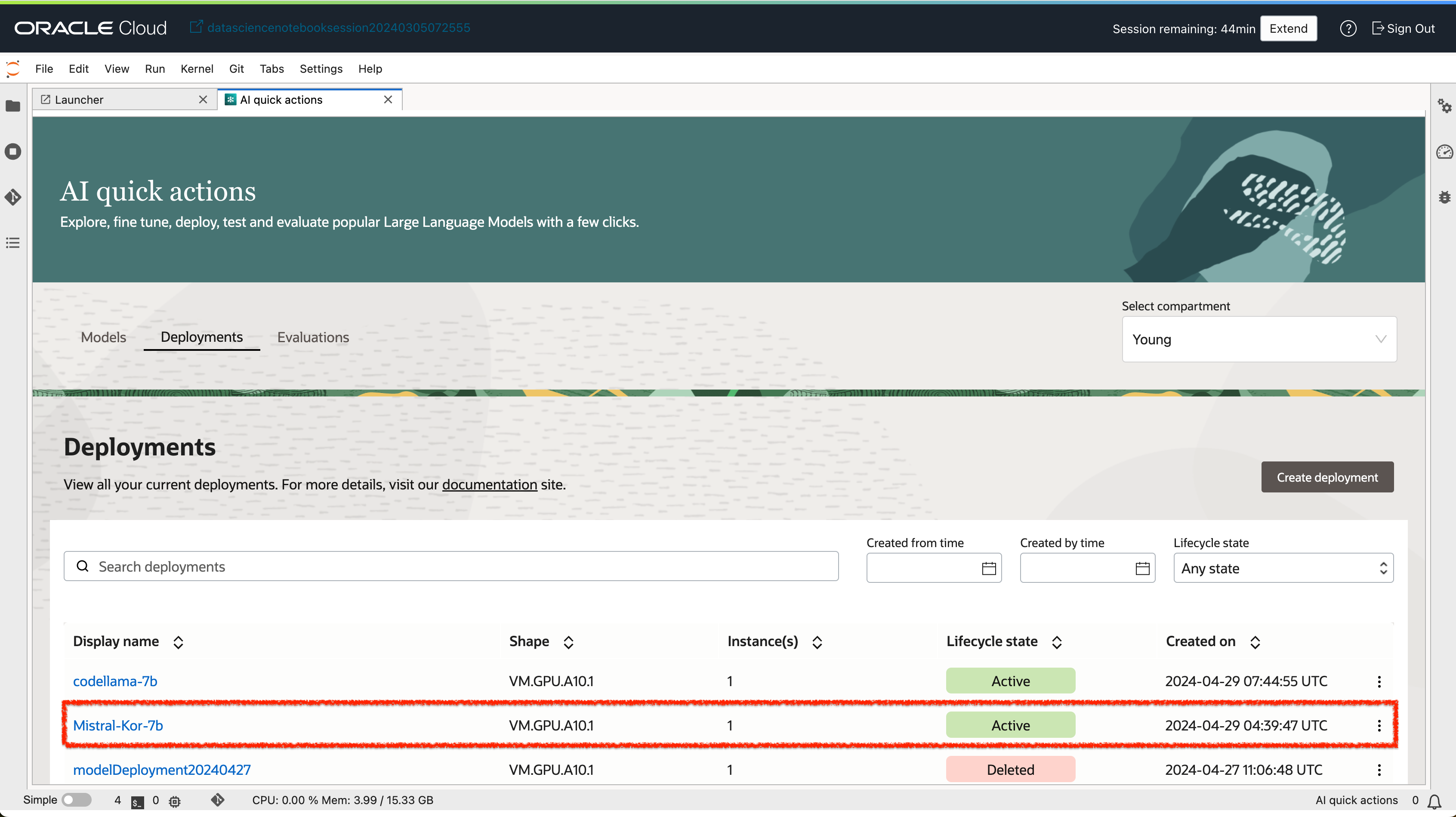
- 배포된 모델 상세보기 화면에서 모델을 테스트할 수 있는 UI도 함께 제공 됩니다.
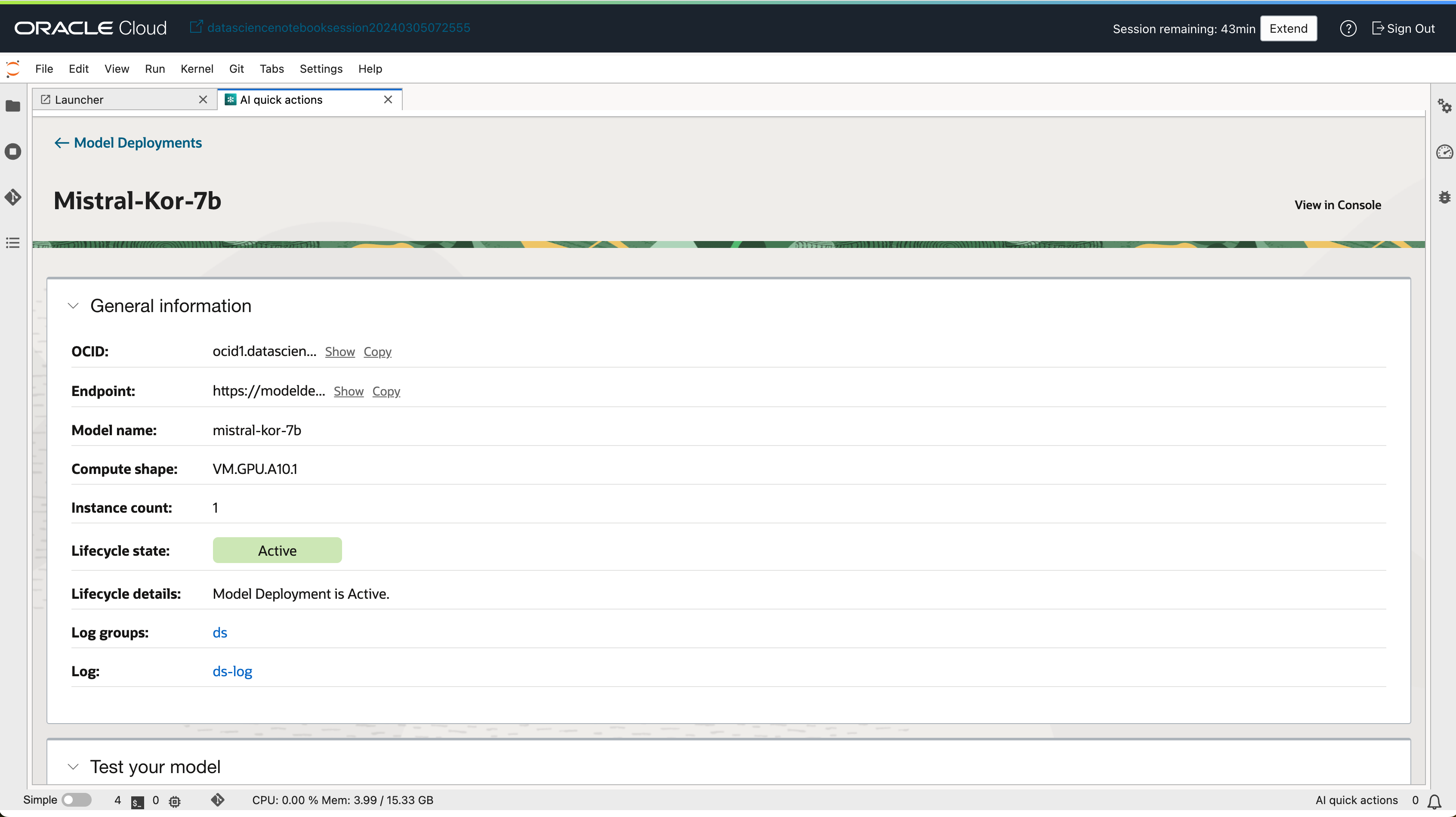
3. 모델 평가하기
배포한 모델이 기대하고 있는 답변을 생성하는지 간편하게 확인할 수 있도록 모델 평가 작업을 생성하여 확인할 수 있습니다. 평가에 필요한 데이터셋은 평가하고자 하는 질문, 답변을 데이터셋 포멧에 맞게 준비하거나, 학습에 사용된 데이터 중 일부 데이터를 샘플링하여 사용할 수 있습니다.
3-1. 평가 작업 생성하기
- Evaluations 탭에서
Create Evaluation버튼을 클릭합니다.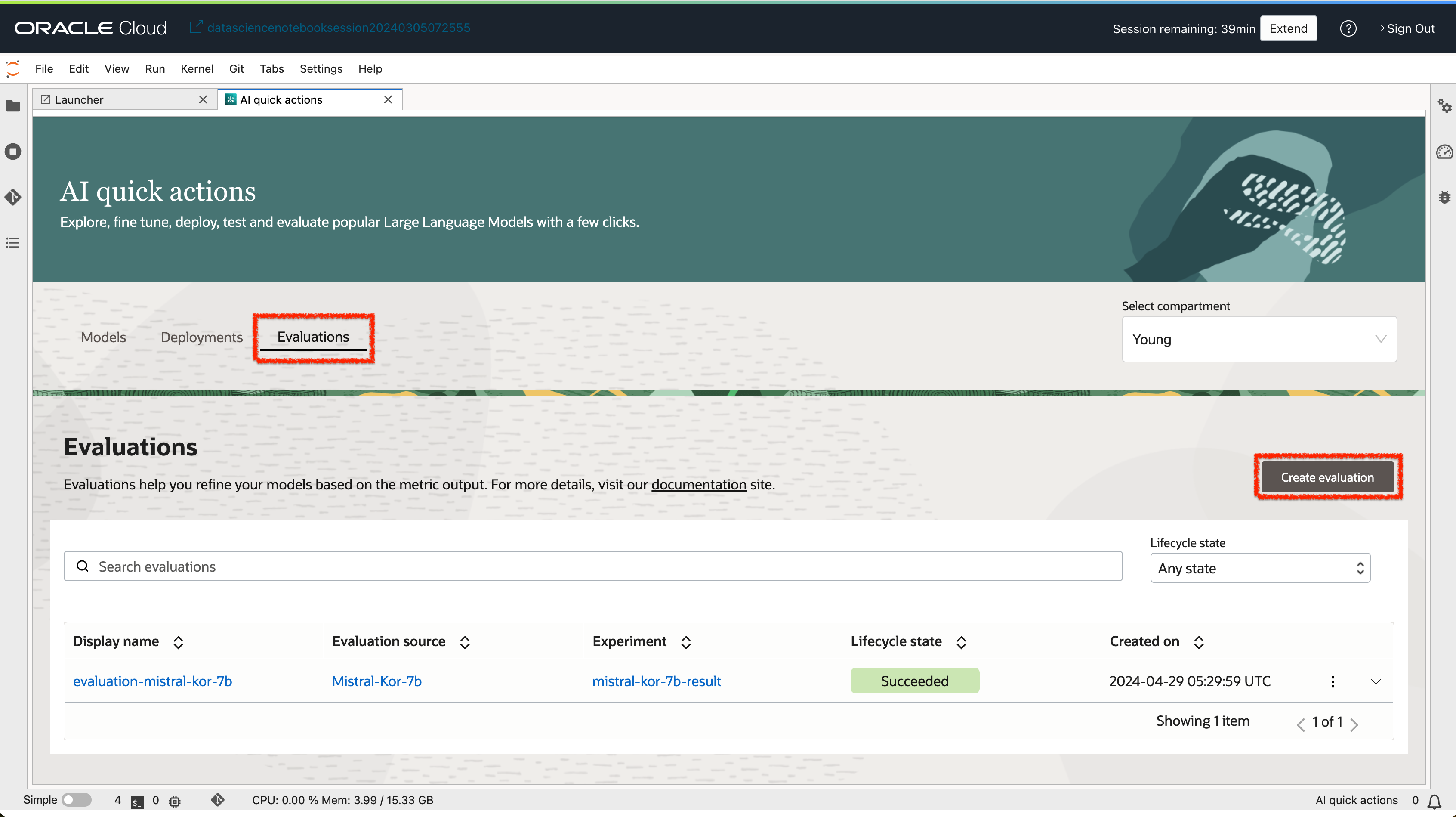
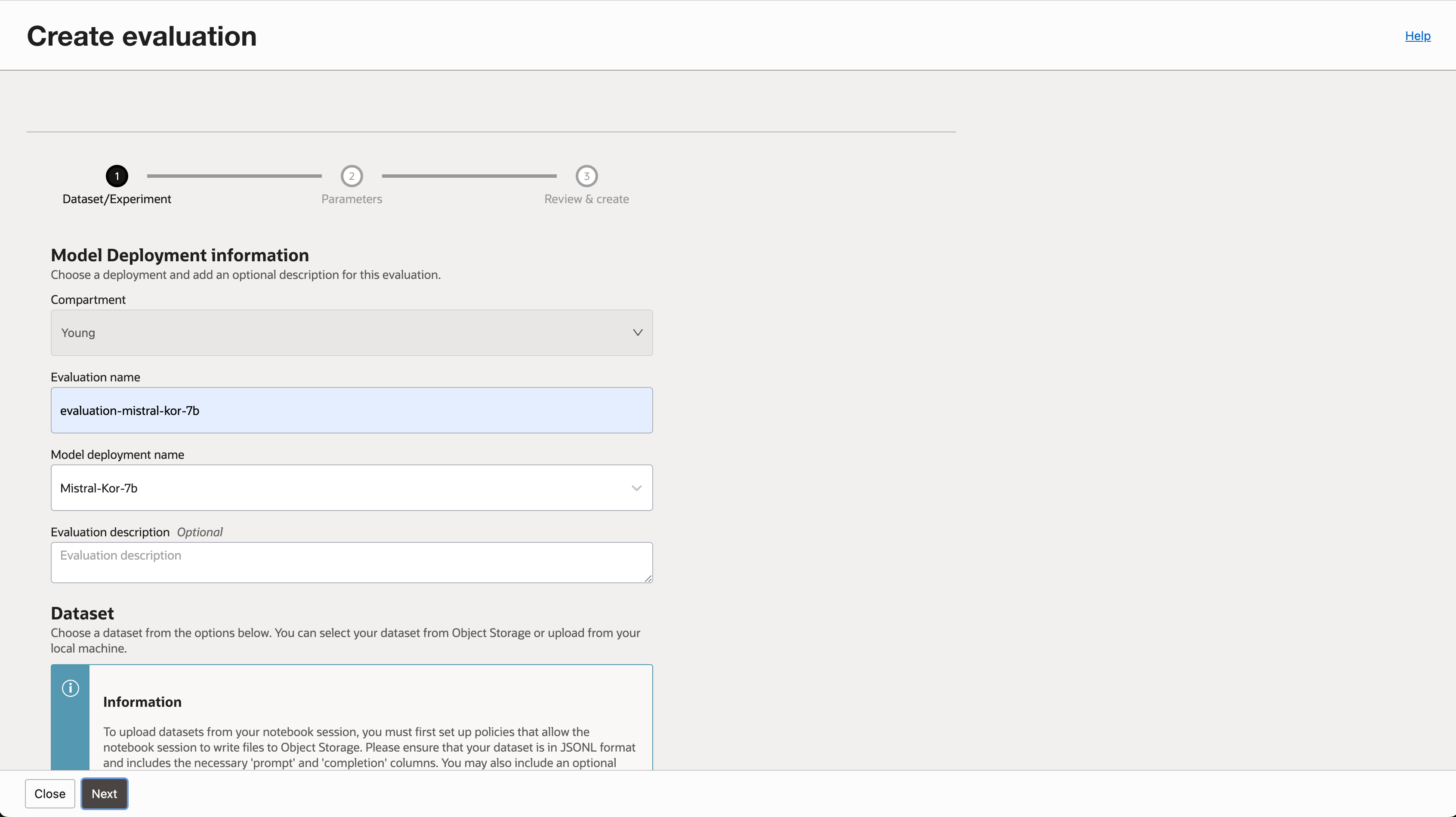
- 평가 작업을 구분하기 위해 이름을 입력하고, 평가하고자 하는 배포된 모델을 선택합니다.
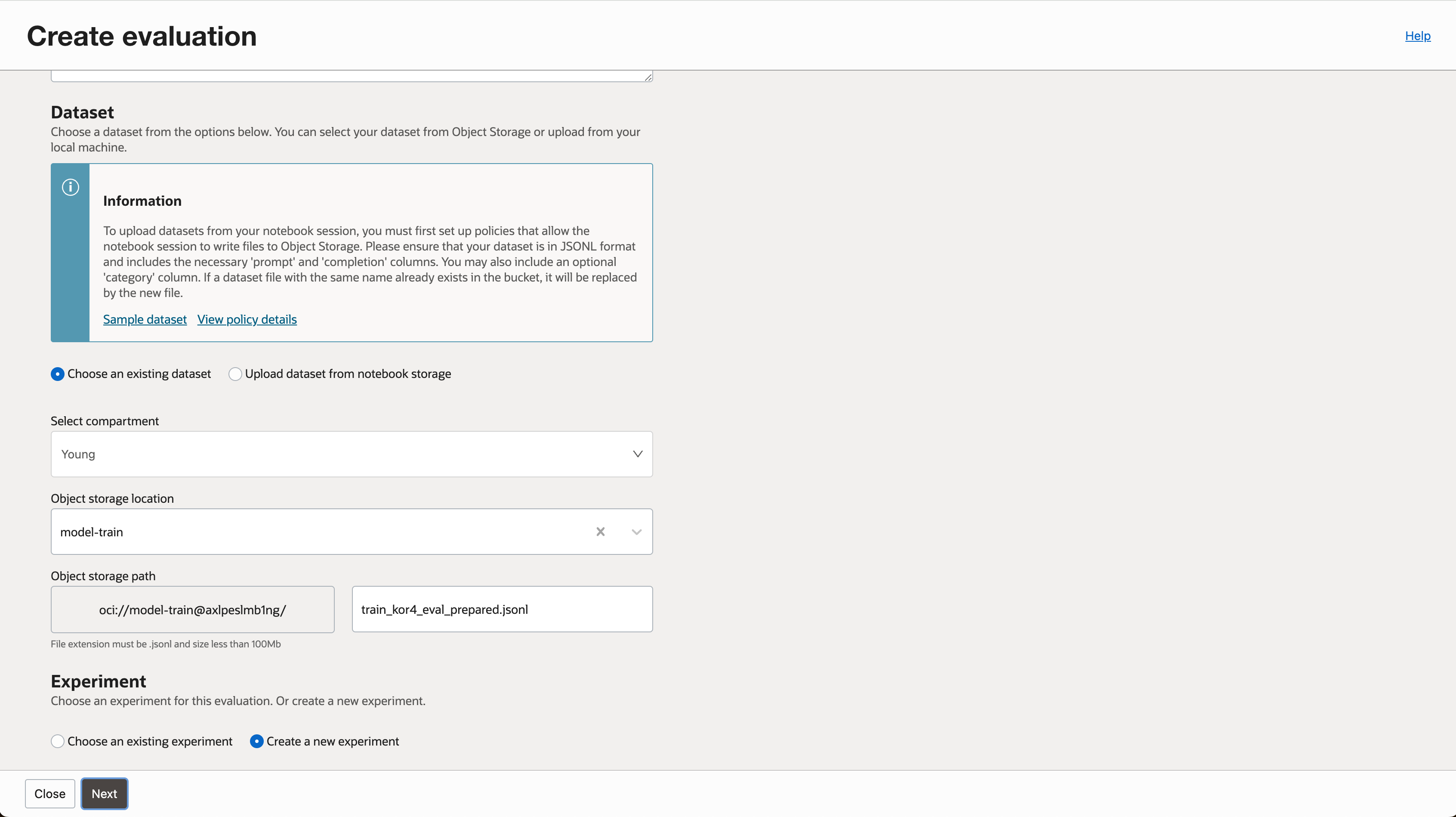
- 평가에 사용될 데이터셋 경로를 지정합니다. (실습에서는 Object Storage 기준으로 진행하였습니다.)
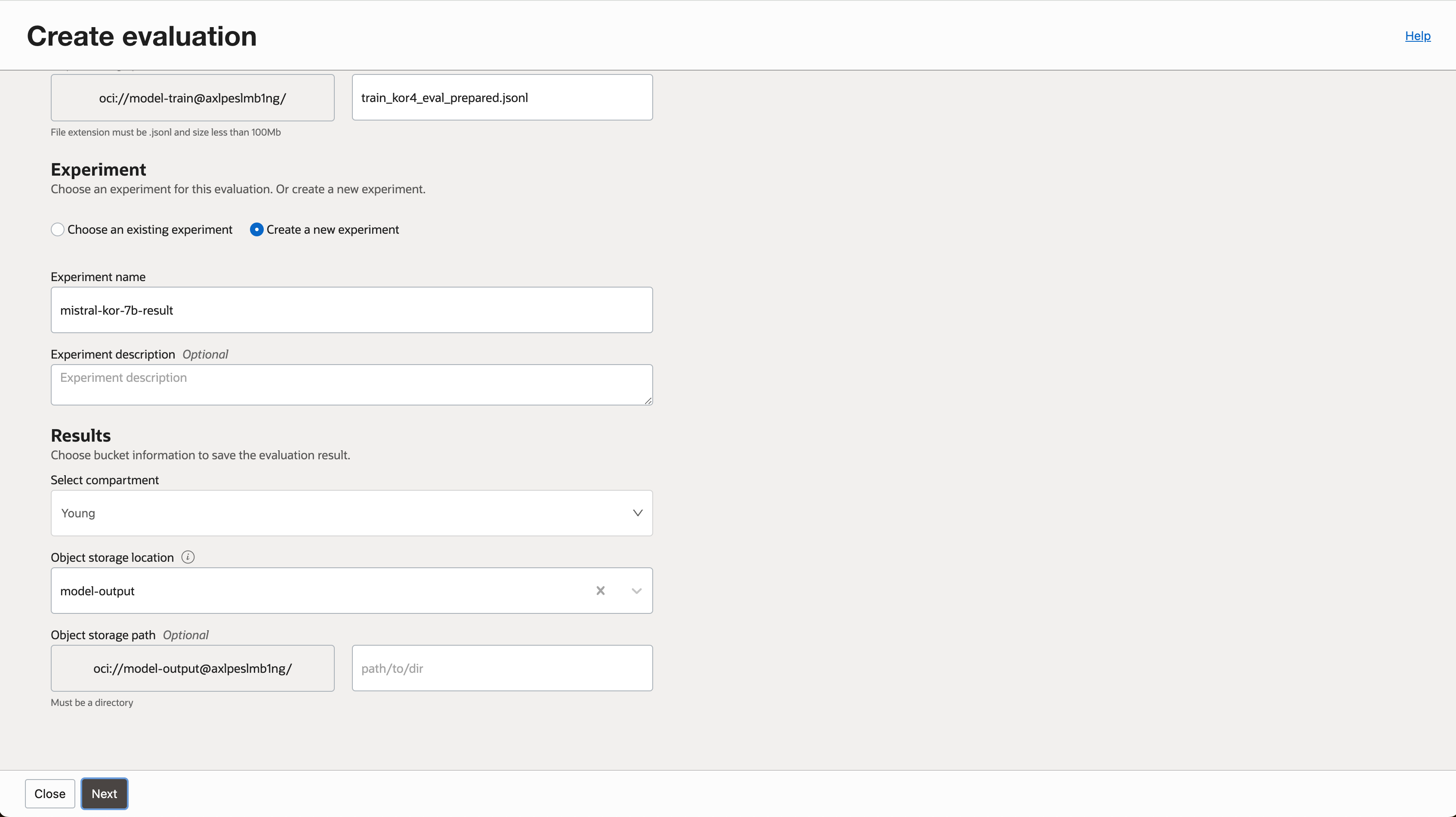
- 평가 결과물을 저장할 버킷, 이름을 지정합니다.
- 평가에 사용될 파라미터를 조정합니다.
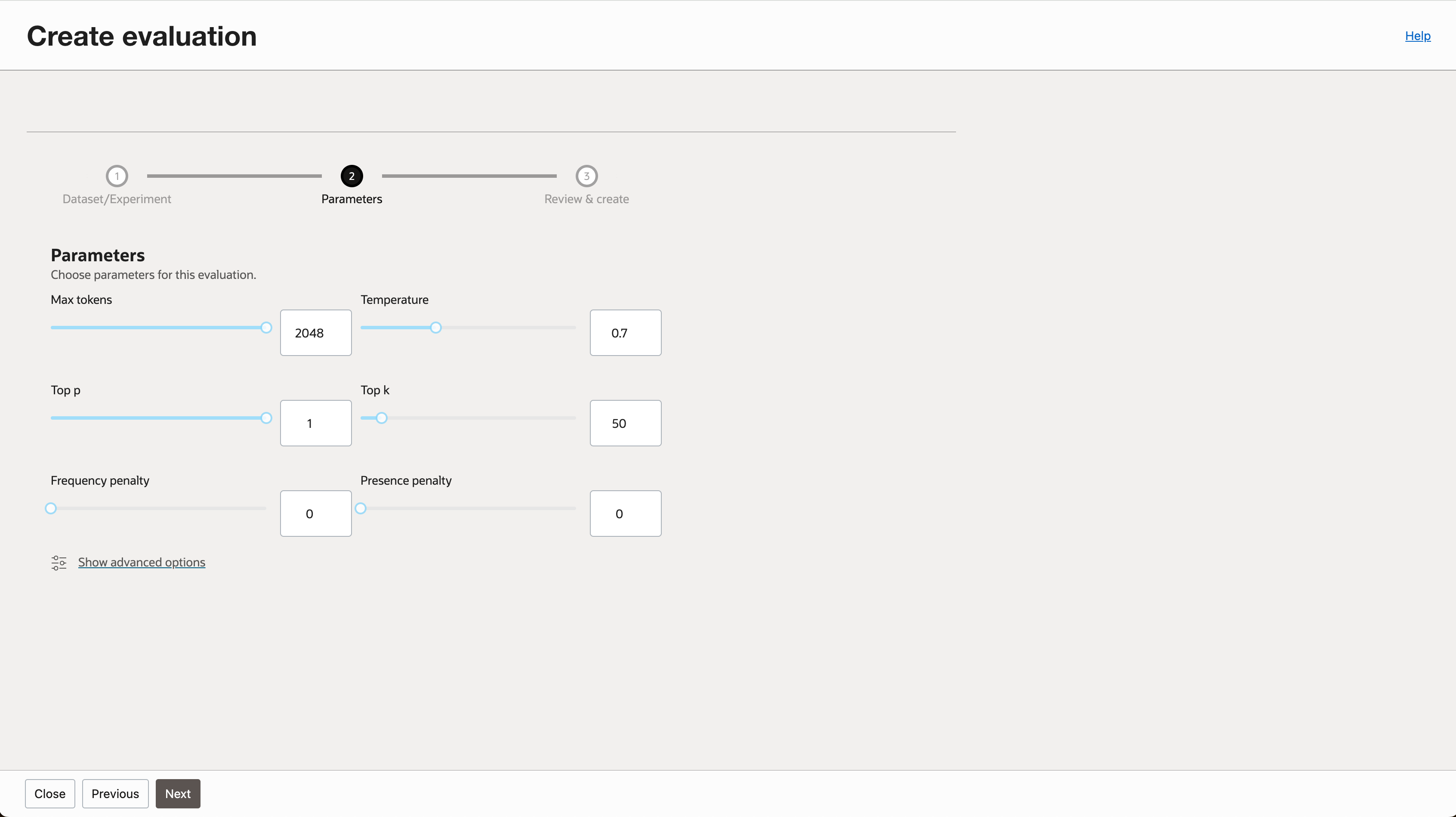
- 고급 옵션을 선택해서 인스턴스 Shape과 로깅 옵션을 조정할 수 있습니다.
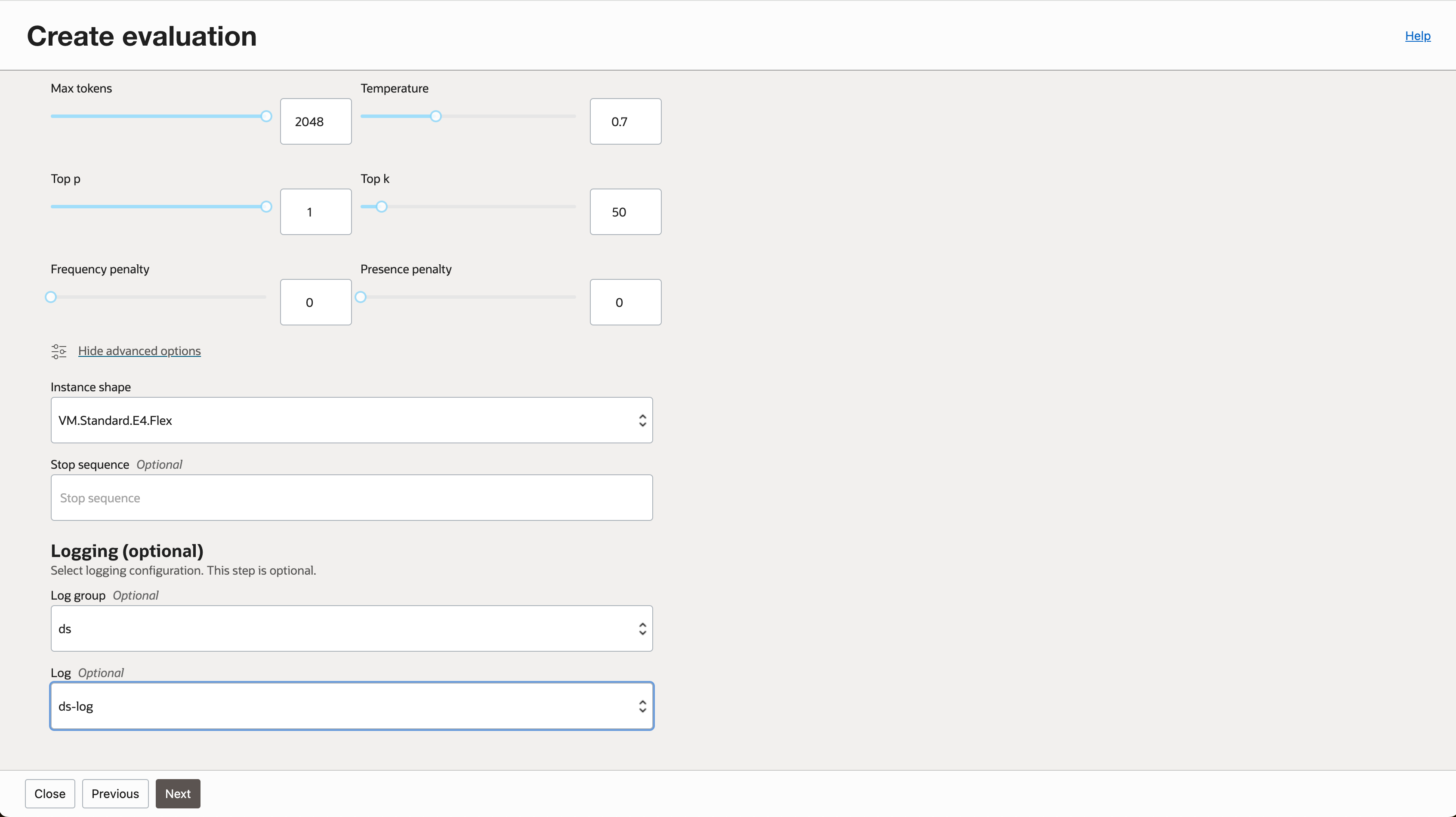
- 입력한 내용을 확인하고 평가 작업을 생성합니다.
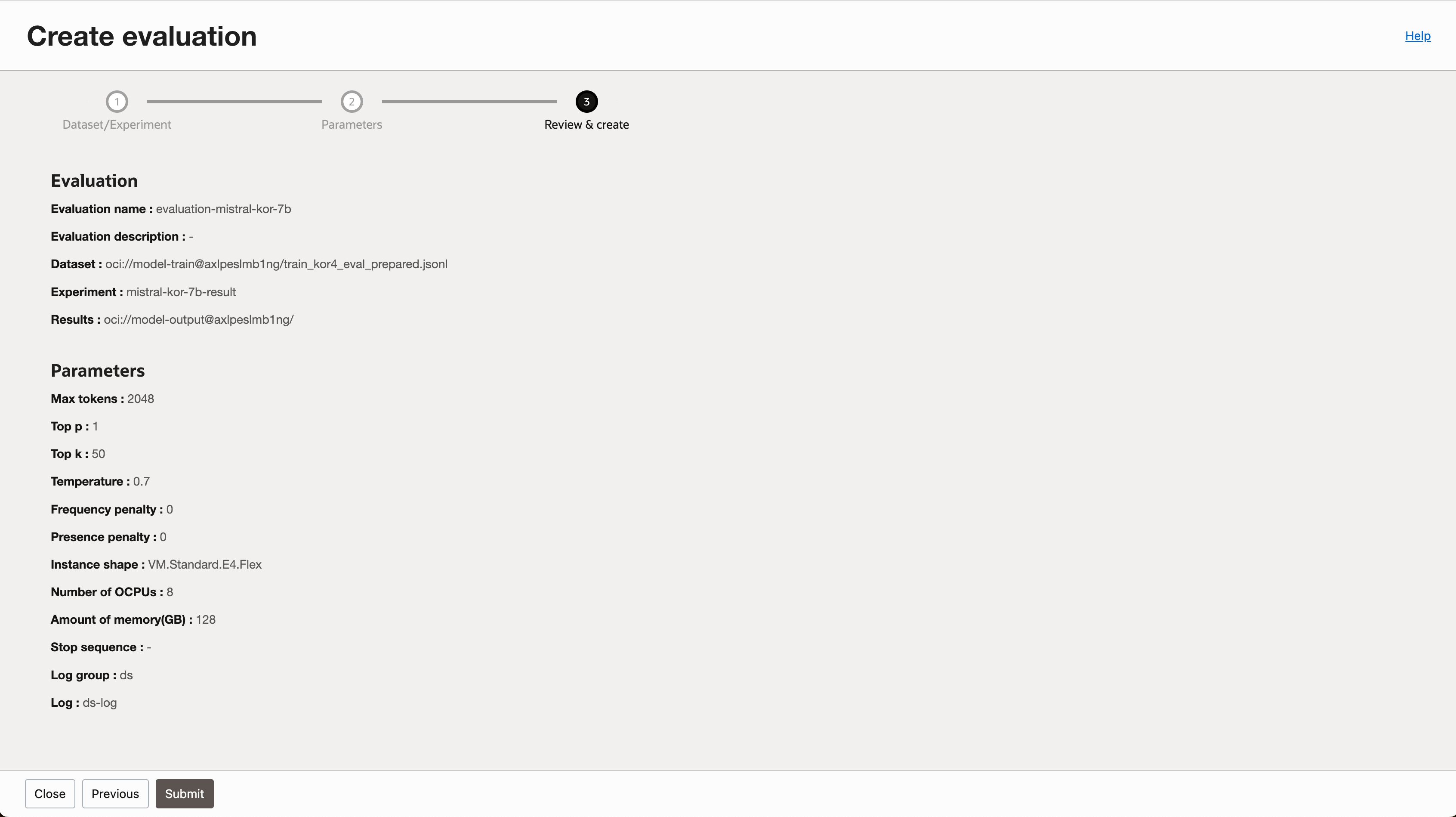
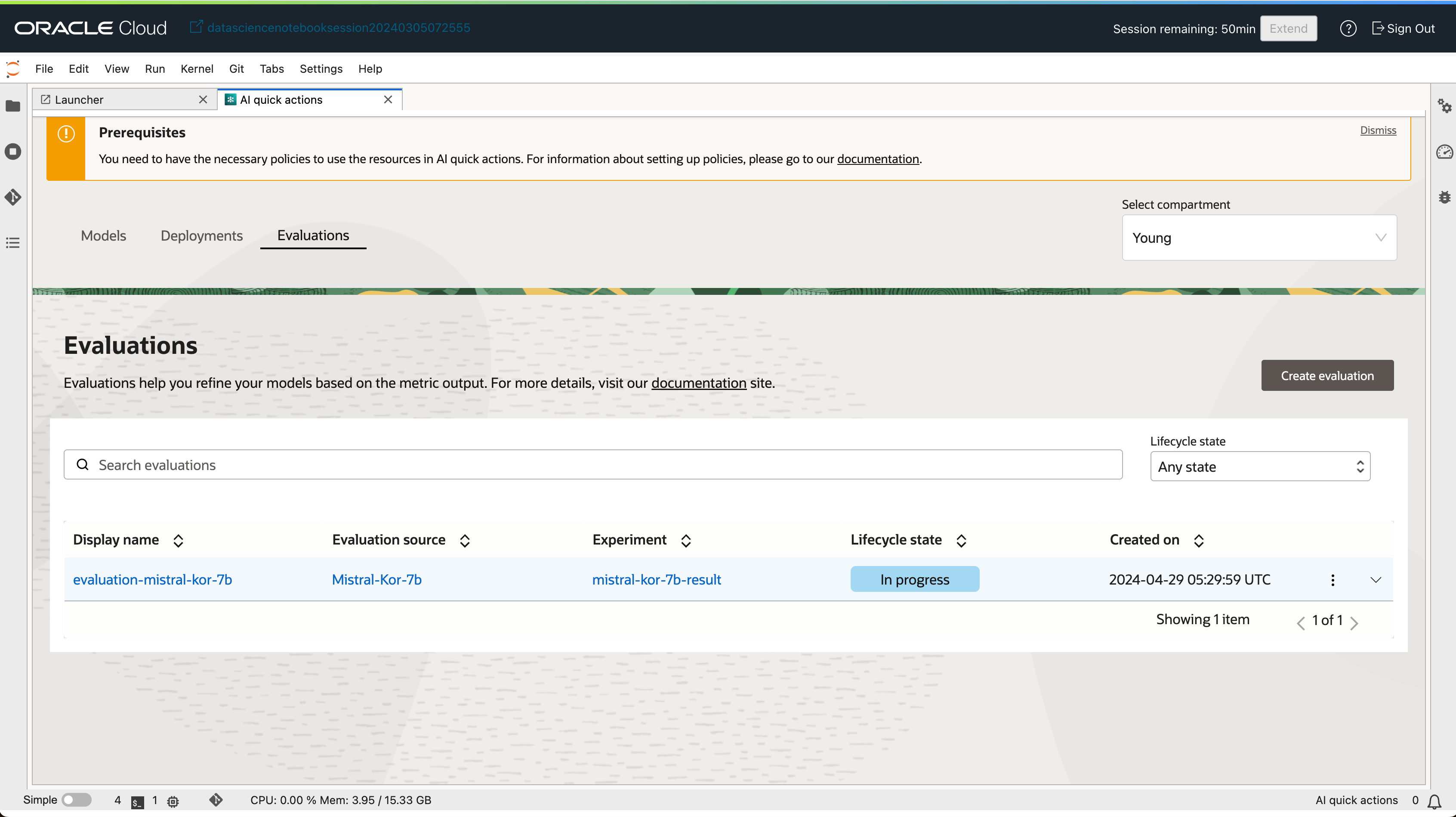
3-2. 평가 결과 확인하기
- 평가 작업이 완료되면 Evaulations 탭에서 평가 결과를 확인할 수 있습니다.
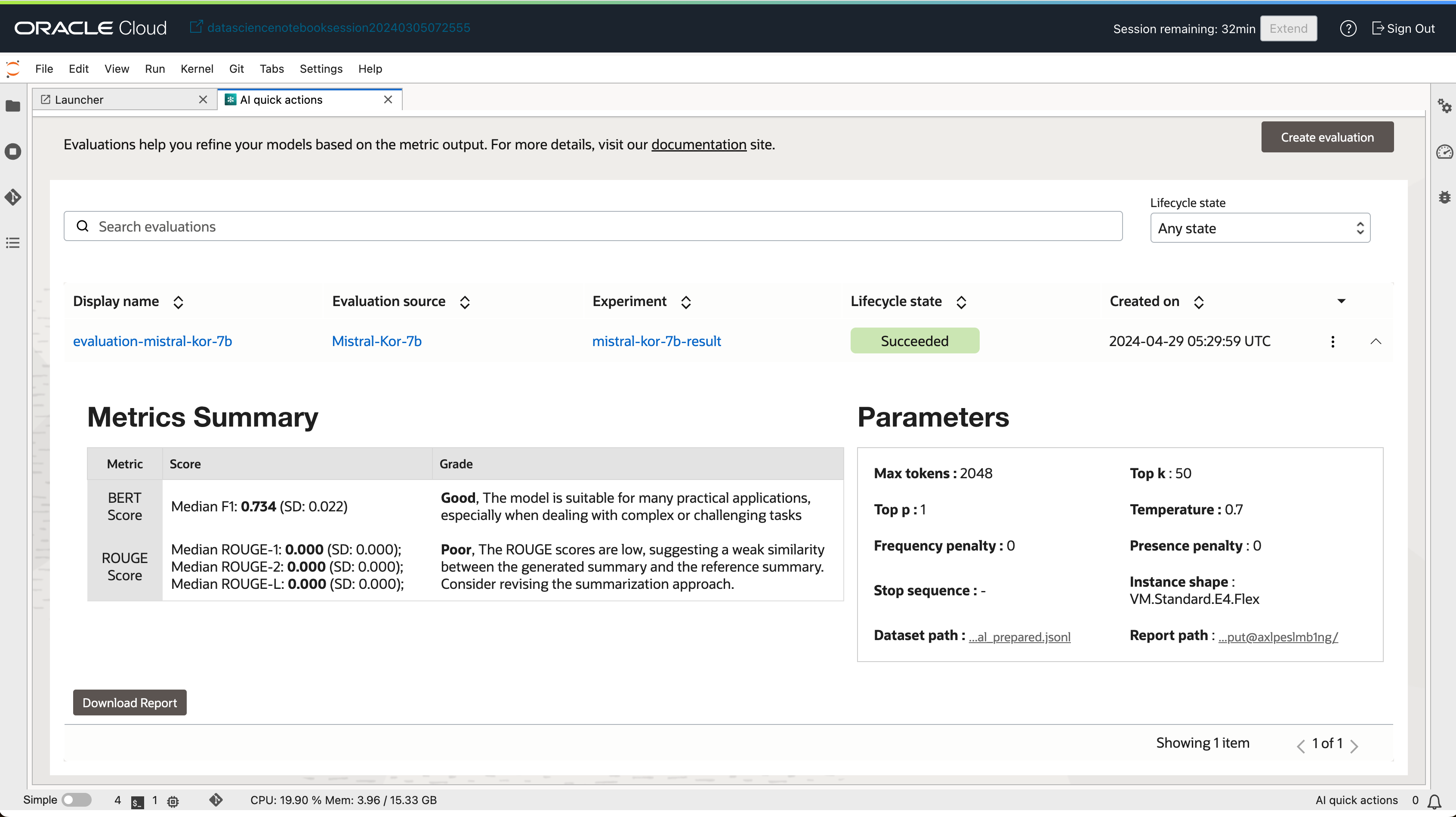
- 상세한 평가 결과를 확인하려면 “Download Report” 버튼을 클릭하여 Report를 다운로드 할 수 있습니다.
- Report 에서는 좀더 상세한 정보를 확인할 수 있습니다.
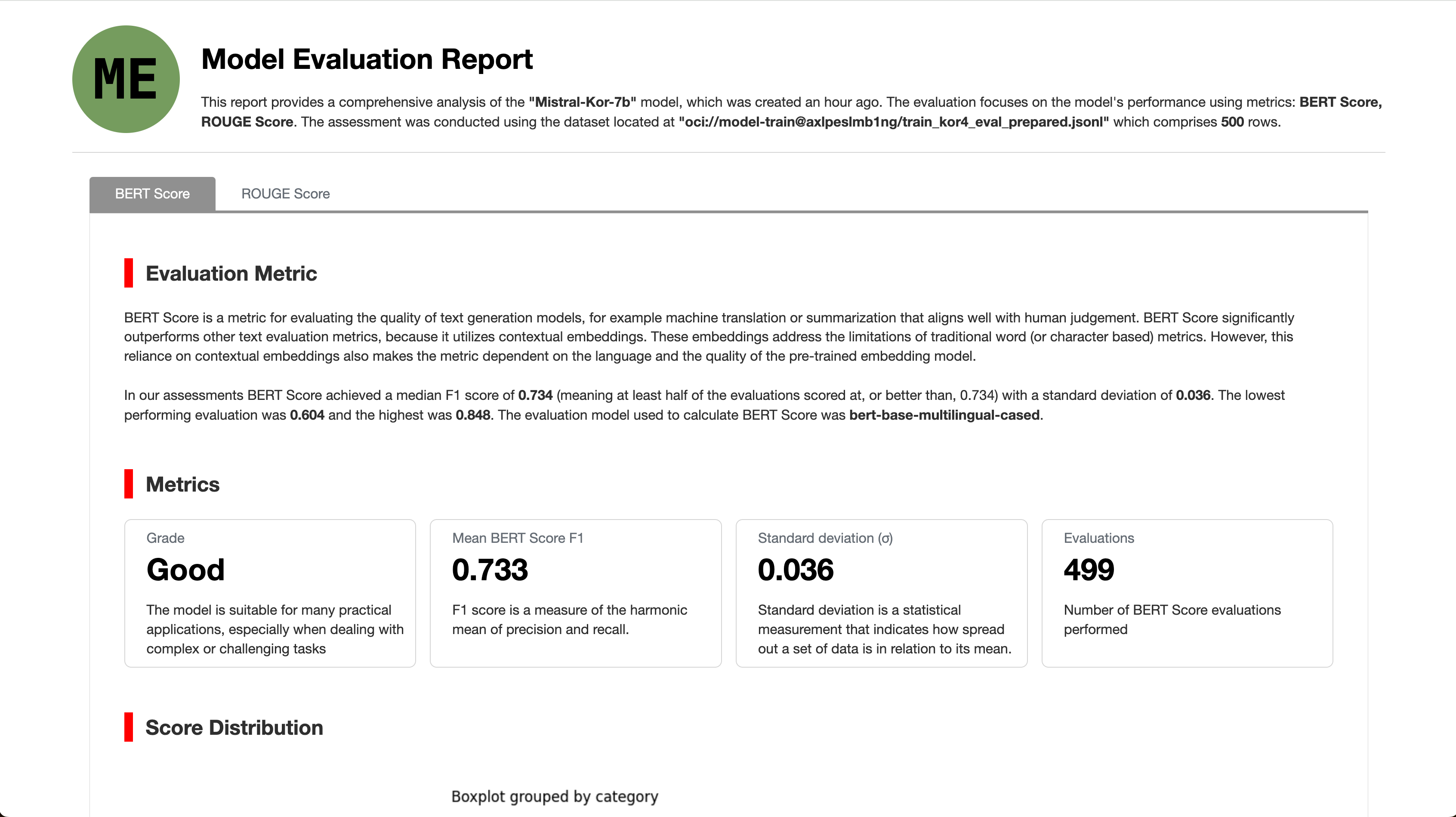
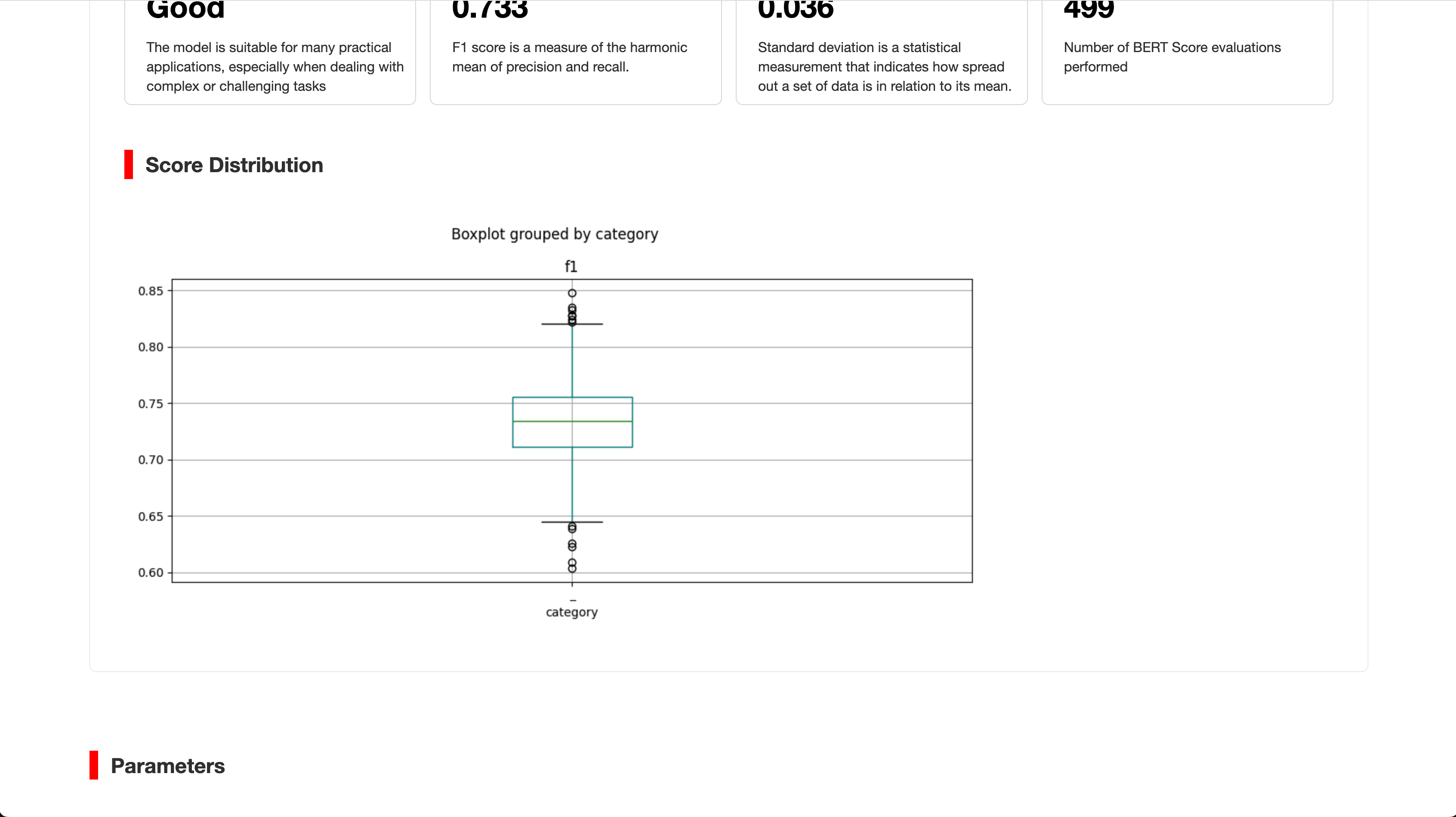



- 평가 작업을 생성할 때 지정했던 버킷에서도 Report를 다운로드 할 수 있습니다.
4. 모델 사용하기 (Application 과 통합)
Using oci-cli
oci raw-request --http-method POST --target-uri https://modeldeployment.us-ashburn-1.oci.oc-test.com/ocid1.datasciencemodeldeployment.oc1.iad.xxxxxxxxx/predict --request-body '{
"model": "odsc-llm",
"prompt":"what are activation functions?",
"max_tokens":250,
"temperature": 0.7,
"top_p":0.8,
}' --auth <auth_method>
Note: Currently oci-cli does not support streaming response, use Python or Java SDK instead.
Using Python SDK (without streaming)
# The OCI SDK must be installed for this example to function properly.
# Installation instructions can be found here: https://docs.oracle.com/en-us/iaas/Content/API/SDKDocs/pythonsdk.htm
import requests
import oci
from oci.signer import Signer
from oci.config import from_file
config = from_file('~/.oci/config')
auth = Signer(
tenancy=config['tenancy'],
user=config['user'],
fingerprint=config['fingerprint'],
private_key_file_location=config['key_file'],
pass_phrase=config['pass_phrase']
)
# For security token based authentication
# token_file = config['security_token_file']
# token = None
# with open(token_file, 'r') as f:
# token = f.read()
# private_key = oci.signer.load_private_key_from_file(config['key_file'])
# auth = oci.auth.signers.SecurityTokenSigner(token, private_key)
endpoint = "https://modeldeployment.us-ashburn-1.oci.oc-test.com/ocid1.datasciencemodeldeployment.oc1.iad.xxxxxxxxx/predict"
body = {
"model": "odsc-llm", # this is a constant
"prompt": "what are activation functions?",
"max_tokens": 250,
"temperature": 0.7,
"top_p": 0.8,
}
res = requests.post(endpoint, json=body, auth=auth, headers={}).json()
print(res)
Using Python SDK (with streaming)
To consume streaming Server-sent Events (SSE), install sseclient-py using pip install sseclient-py.
# The OCI SDK must be installed for this example to function properly.
# Installation instructions can be found here: https://docs.oracle.com/en-us/iaas/Content/API/SDKDocs/pythonsdk.htm
import requests
import oci
from oci.signer import Signer
from oci.config import from_file
import sseclient # pip install sseclient-py
config = from_file('~/.oci/config')
auth = Signer(
tenancy=config['tenancy'],
user=config['user'],
fingerprint=config['fingerprint'],
private_key_file_location=config['key_file'],
pass_phrase=config['pass_phrase']
)
# For security token based authentication
# token_file = config['security_token_file']
# token = None
# with open(token_file, 'r') as f:
# token = f.read()
# private_key = oci.signer.load_private_key_from_file(config['key_file'])
# auth = oci.auth.signers.SecurityTokenSigner(token, private_key)
endpoint = "https://modeldeployment.us-ashburn-1.oci.oc-test.com/ocid1.datasciencemodeldeployment.oc1.iad.xxxxxxxxx/predict"
body = {
"model": "odsc-llm", # this is a constant
"prompt": "what are activation functions?",
"max_tokens": 250,
"temperature": 0.7,
"top_p": 0.8,
"stream": True,
}
headers={'Content-Type':'application/json','enable-streaming':'true', 'Accept': 'text/event-stream'}
response = requests.post(endpoint, json=body, auth=auth, stream=True, headers=headers)
print(response.headers)
client = sseclient.SSEClient(response)
for event in client.events():
print(event.data)
# Alternatively, we can use the below code to print the response.
# for line in response.iter_lines():
# if line:
# print(line)
Using Java (with streaming)
/**
* The OCI SDK must be installed for this example to function properly.
* Installation instructions can be found here: https://docs.oracle.com/en-us/iaas/Content/API/SDKDocs/javasdk.htm
*/
package org.example;
import com.oracle.bmc.auth.AuthenticationDetailsProvider;
import com.oracle.bmc.auth.SessionTokenAuthenticationDetailsProvider;
import com.oracle.bmc.http.ClientConfigurator;
import com.oracle.bmc.http.Priorities;
import com.oracle.bmc.http.client.HttpClient;
import com.oracle.bmc.http.client.HttpClientBuilder;
import com.oracle.bmc.http.client.HttpRequest;
import com.oracle.bmc.http.client.HttpResponse;
import com.oracle.bmc.http.client.Method;
import com.oracle.bmc.http.client.jersey.JerseyHttpProvider;
import com.oracle.bmc.http.client.jersey.sse.SseSupport;
import com.oracle.bmc.http.internal.ParamEncoder;
import com.oracle.bmc.http.signing.RequestSigningFilter;
import javax.ws.rs.core.MediaType;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URI;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.function.Function;
public class RestExample {
public static void main(String[] args) throws Exception {
String configurationFilePath = "~/.oci/config";
String profile = "DEFAULT";
// Pre-Requirement: Allow setting of restricted headers. This is required to allow the SigningFilter
// to set the host header that gets computed during signing of the request.
System.setProperty("sun.net.http.allowRestrictedHeaders", "true");
final AuthenticationDetailsProvider provider =
new SessionTokenAuthenticationDetailsProvider(configurationFilePath, profile);
// 1) Create a request signing filter instance using SessionTokenAuth Provider.
RequestSigningFilter requestSigningFilter = RequestSigningFilter.fromAuthProvider(
provider);
// 1) Alternatively, RequestSigningFilter can be created from a config file.
// RequestSigningFilter requestSigningFilter = RequestSigningFilter.fromConfigFile(configurationFilePath, profile);
// 2) Create a Jersey client and register the request signing filter.
// Refer to this page https://docs.oracle.com/en-us/iaas/Content/API/SDKDocs/javasdkexamples.htm for information regarding the compatibility of the HTTP client(s) with OCI SDK version.
HttpClientBuilder builder = JerseyHttpProvider.getInstance()
.newBuilder()
.registerRequestInterceptor(Priorities.AUTHENTICATION, requestSigningFilter)
.baseUri(
URI.create(
"${modelDeployment.modelDeploymentUrl}/")
+ ParamEncoder.encodePathParam("predict"));
// 3) Create a request and set the expected type header.
String jsonPayload = "{}"; // Add payload here with respect to your model example shown in next line:
// 4) Setup Streaming request
Function<InputStream, List<String>> generateTextResultReader = getInputStreamListFunction();
SseSupport sseSupport = new SseSupport(generateTextResultReader);
ClientConfigurator clientConfigurator = sseSupport.getClientConfigurator();
clientConfigurator.customizeClient(builder);
try (HttpClient client = builder.build()) {
HttpRequest request = client
.createRequest(Method.POST)
.header("accepts", MediaType.APPLICATION_JSON)
.header("content-type", MediaType.APPLICATION_JSON)
.header("enable-streaming", "true")
.body(jsonPayload);
// 5) Invoke the call and get the response.
HttpResponse response = request.execute().toCompletableFuture().get();
// 6) Print the response headers and body
Map<String, List<String>> responseHeaders = response.headers();
System.out.println("HTTP Headers " + responseHeaders);
InputStream responseBody = response.streamBody().toCompletableFuture().get();
try (
final BufferedReader reader = new BufferedReader(
new InputStreamReader(responseBody, StandardCharsets.UTF_8)
)
) {
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
}
} catch (Exception ex) {
throw ex;
}
}
private static Function<InputStream, List<String>> getInputStreamListFunction() {
Function<InputStream, List<String>> generateTextResultReader = entityStream -> {
try (BufferedReader reader =
new BufferedReader(new InputStreamReader(entityStream))) {
String line;
List<String> generatedTextList = new ArrayList<>();
while ((line = reader.readLine()) != null) {
if (line.isEmpty() || line.startsWith(":")) {
continue;
}
generatedTextList.add(line);
}
return generatedTextList;
} catch (Exception ex) {
throw new RuntimeException(ex);
}
};
return generateTextResultReader;
}
}
5. 문제 해결하기
만약 모델을 배포하거나, Fine-tune 작업을 실행하다고 오류가 발생한 경우 작업 생성 시 지정한 로깅 서비스에서 확인하거나, Notebook 세션에서 Terminal 기능에서 아래 명령어를 통해 jobrun 로그를 확인할 수 있습니다.
5-1. 로깅서비스에서 오류 로그 확인
- 실패한 작업 세부정보 화면에서 logging 링크를 클릭하여 로깅서비스 화면으로 이동합니다.
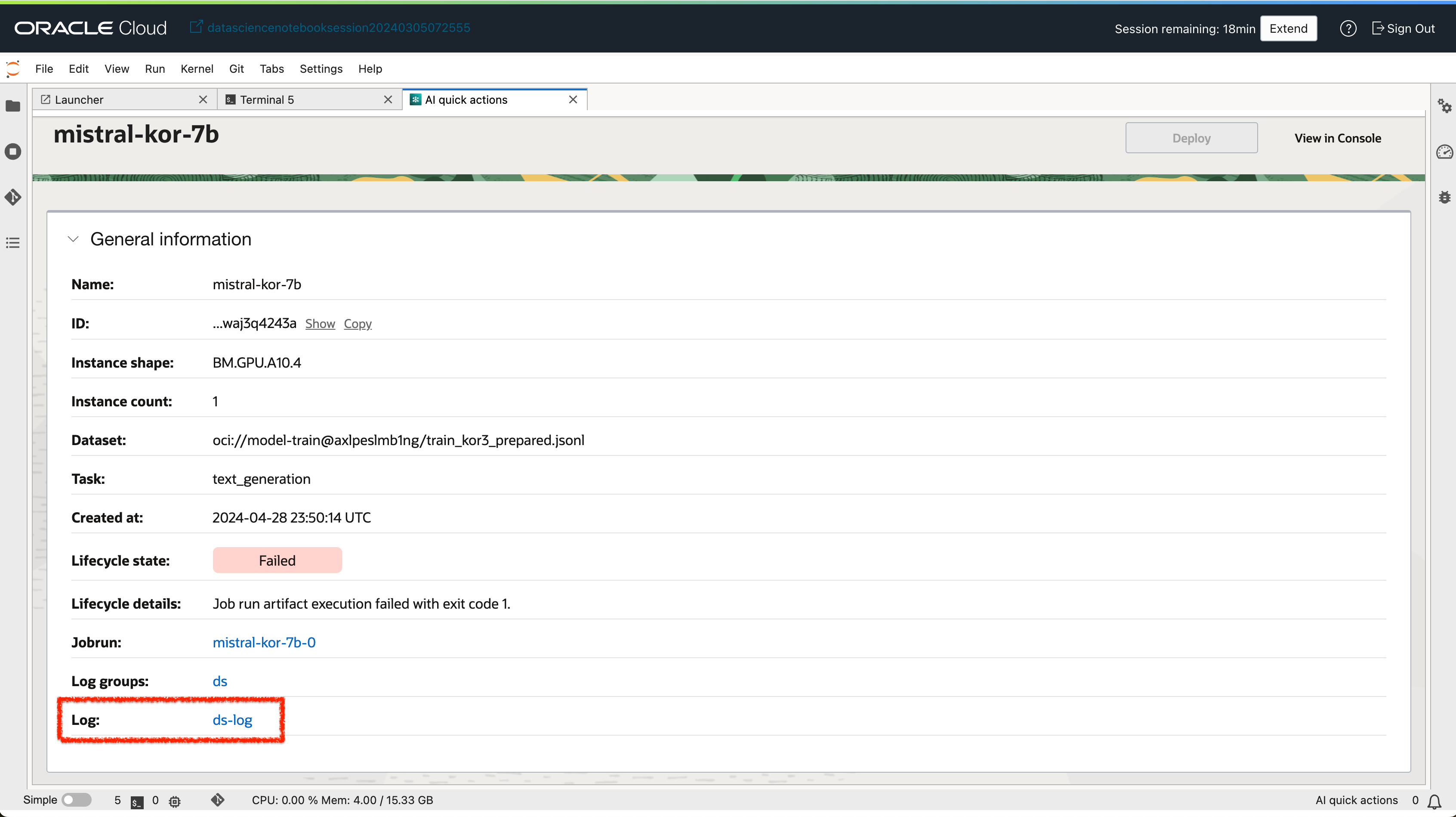
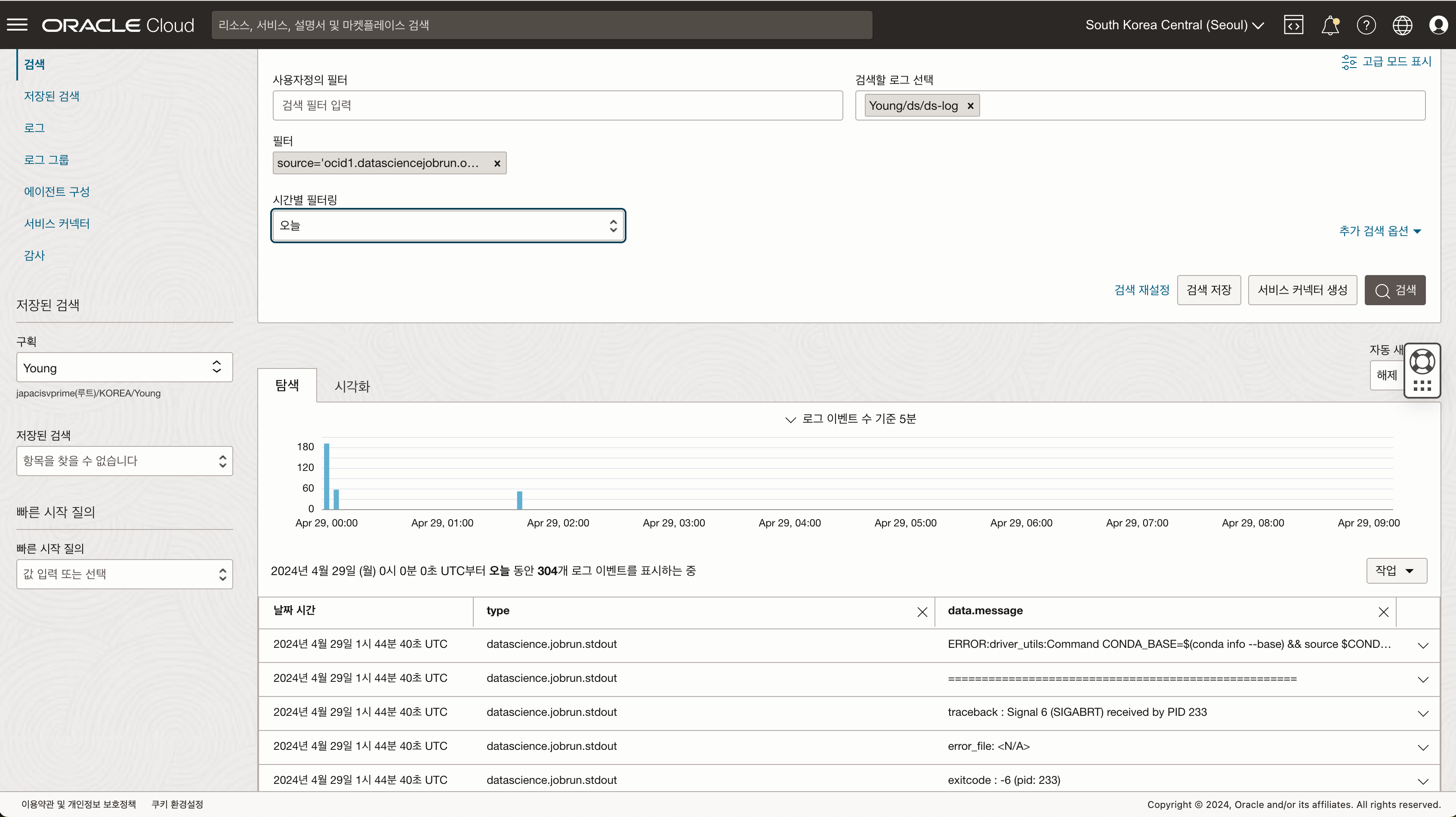
- 실패 로그를 확인합니다. (Output 라인별로 확인 가능)
5-2. Data Science 세션 터미널에서 jobrun 로그 확인하기
- 실패한 작업 세부정보 화면에서 jobrun 링크를 클릭하여 jobrun 화면으로 이동합니다.
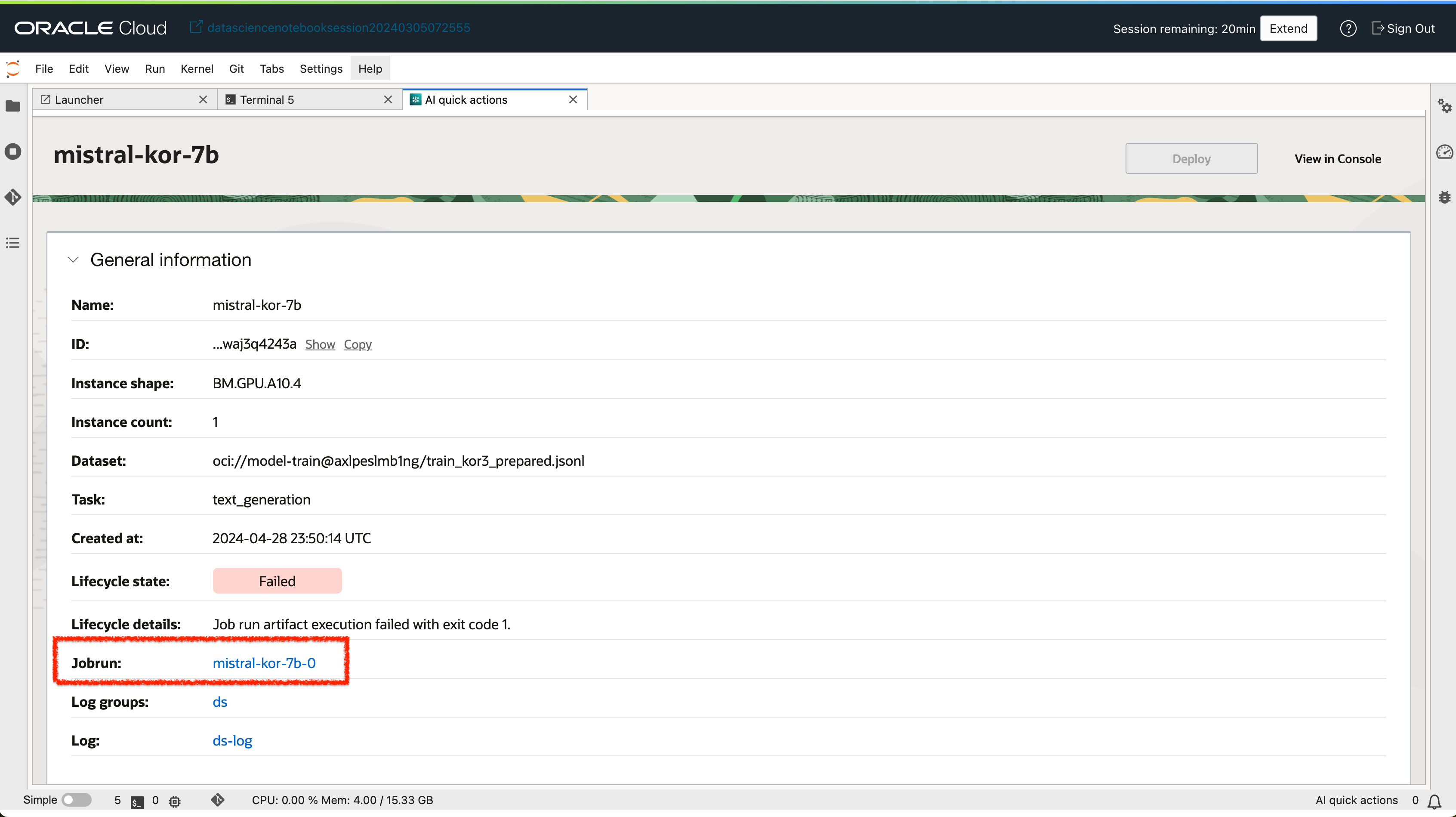
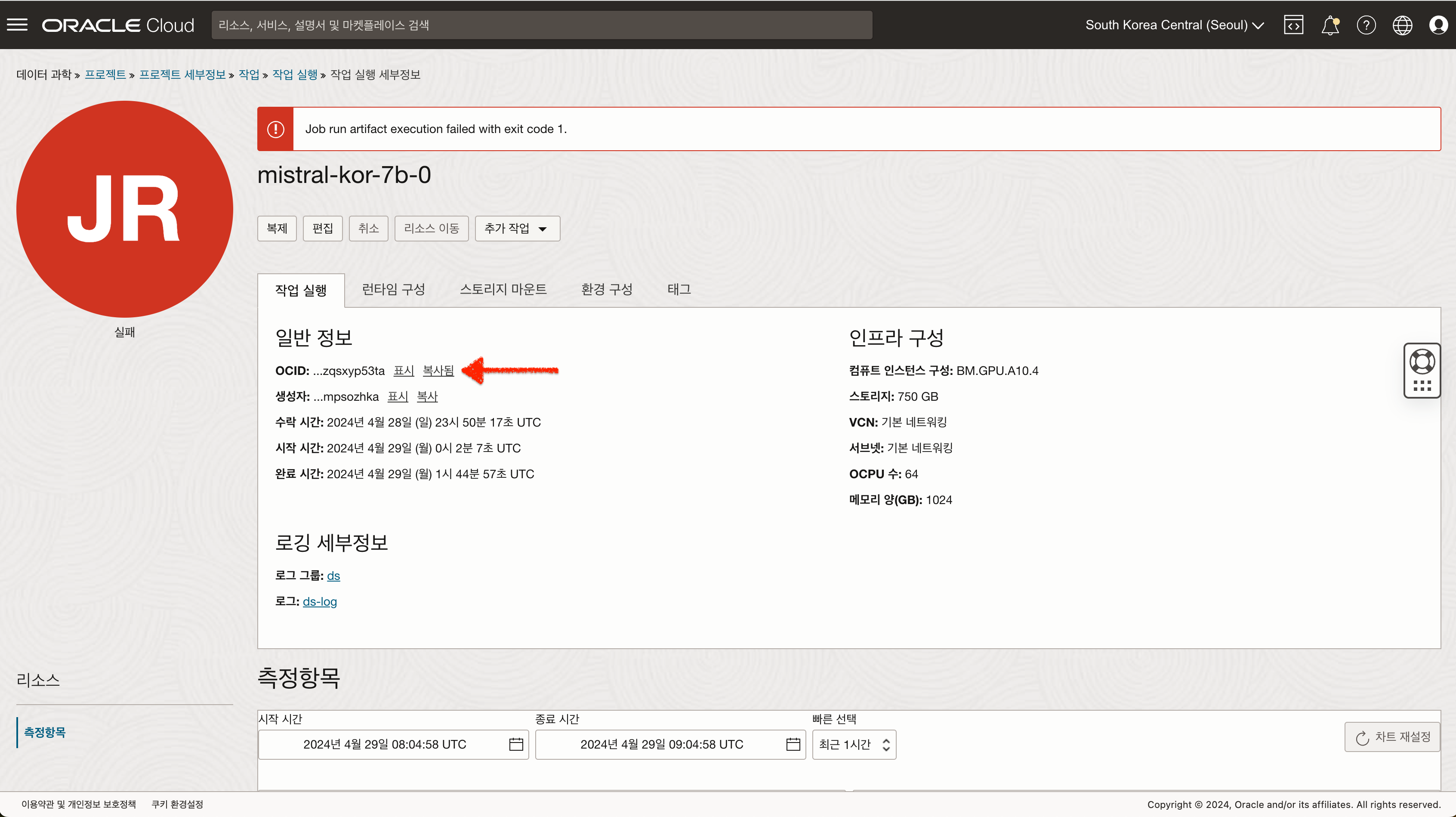
- jobrun의 OCID를 복사합니다.
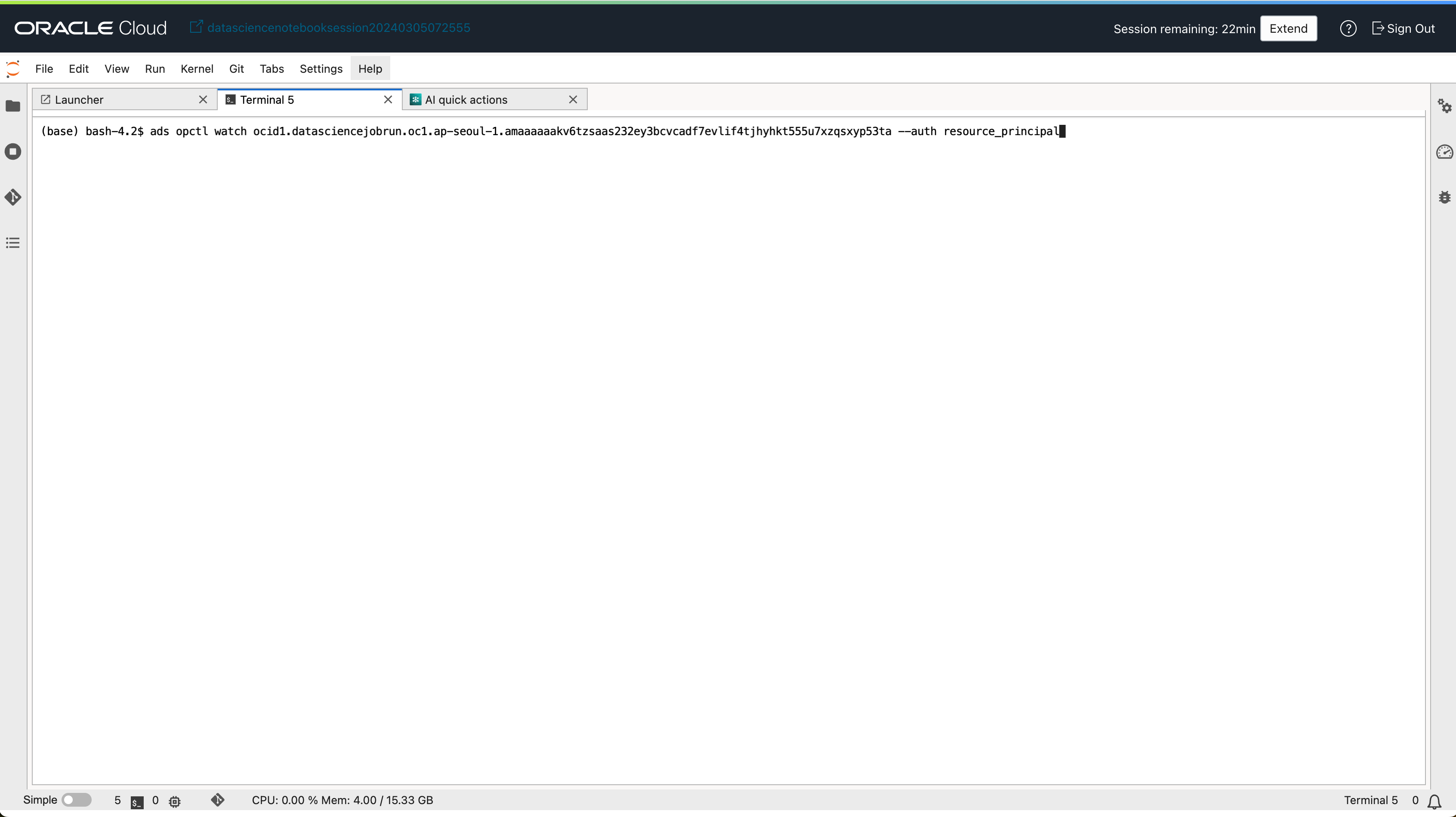
- Data Science 노트북 세션에서 터미널을 열고 아래 명령어를 실행합니다.
ads opctl watch [jobrun-ocid] --auth resource_principal
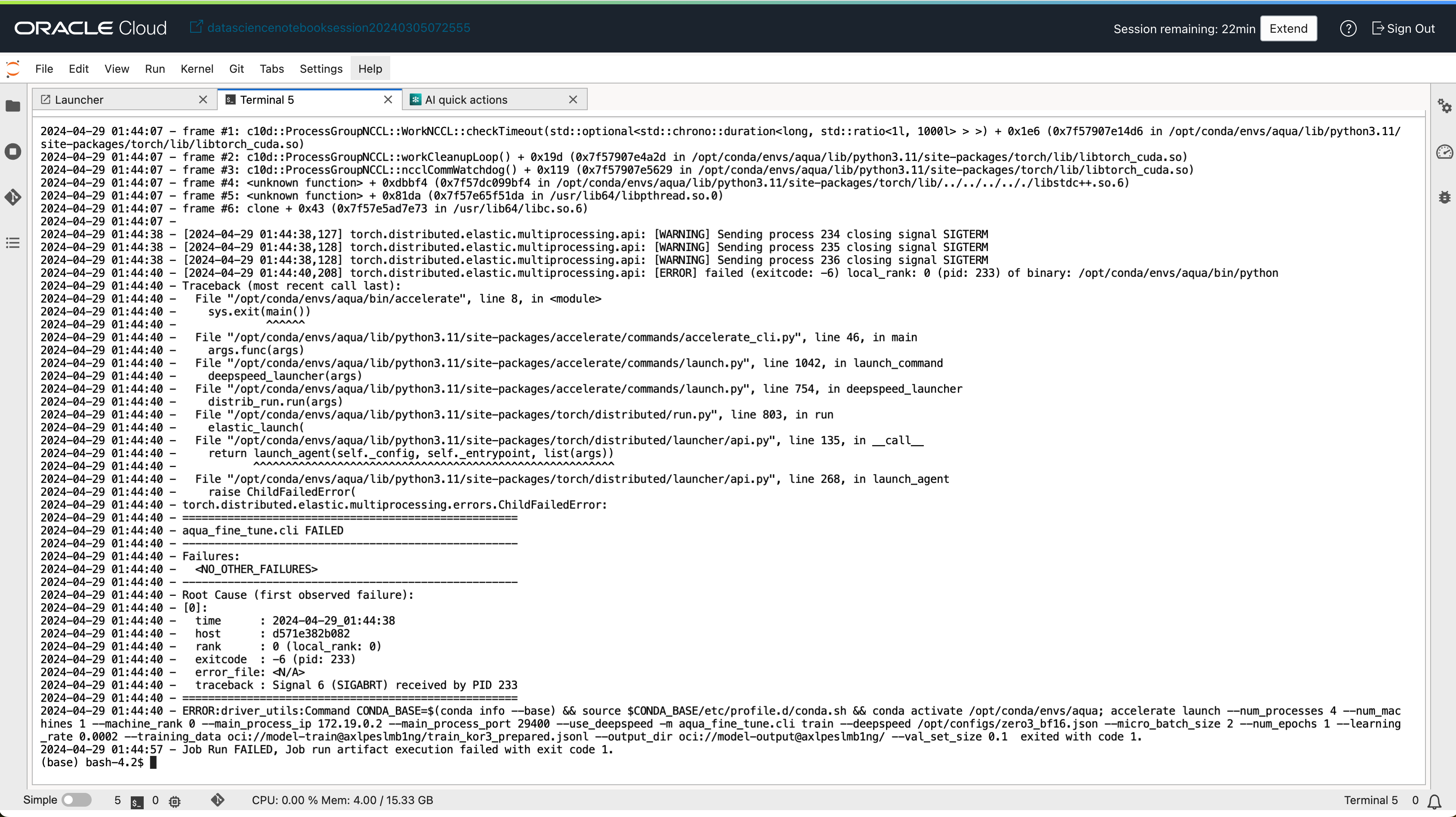
- 결과를 확인합니다.
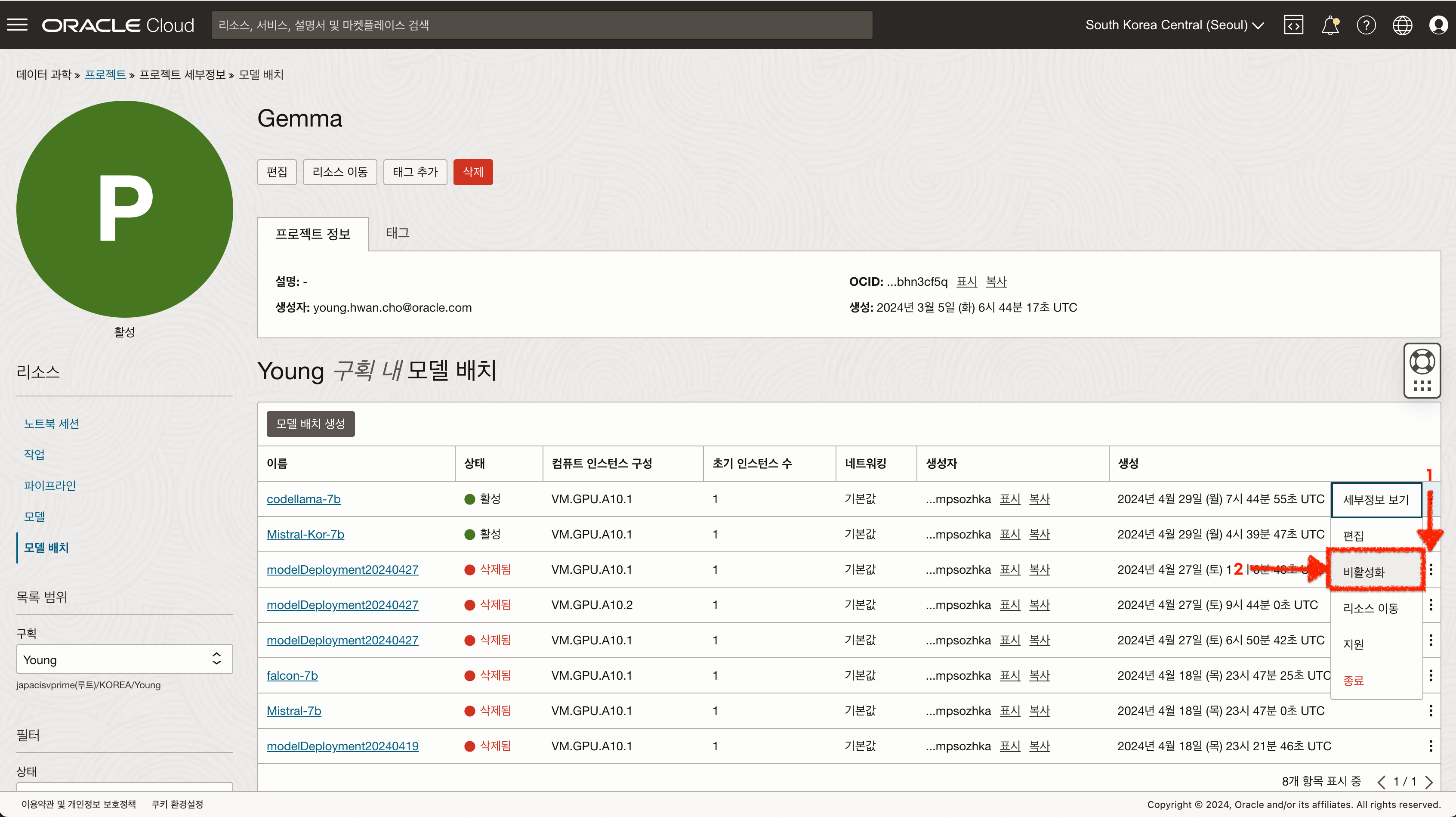
6. 비용 세이브를 위한 리소스 비활성화 하기
A10 리소스는 중지할 경우 비용이 발생하지 않기 때문에 비용을 절감하기 위해서 사용하지 않을 때에는 모델 배치를 비활성화 하여 리소스를 중지할 수 있습니다.
- 데이터 과학 - 프로젝트 - 모델 배치 화면으로 이동합니다.
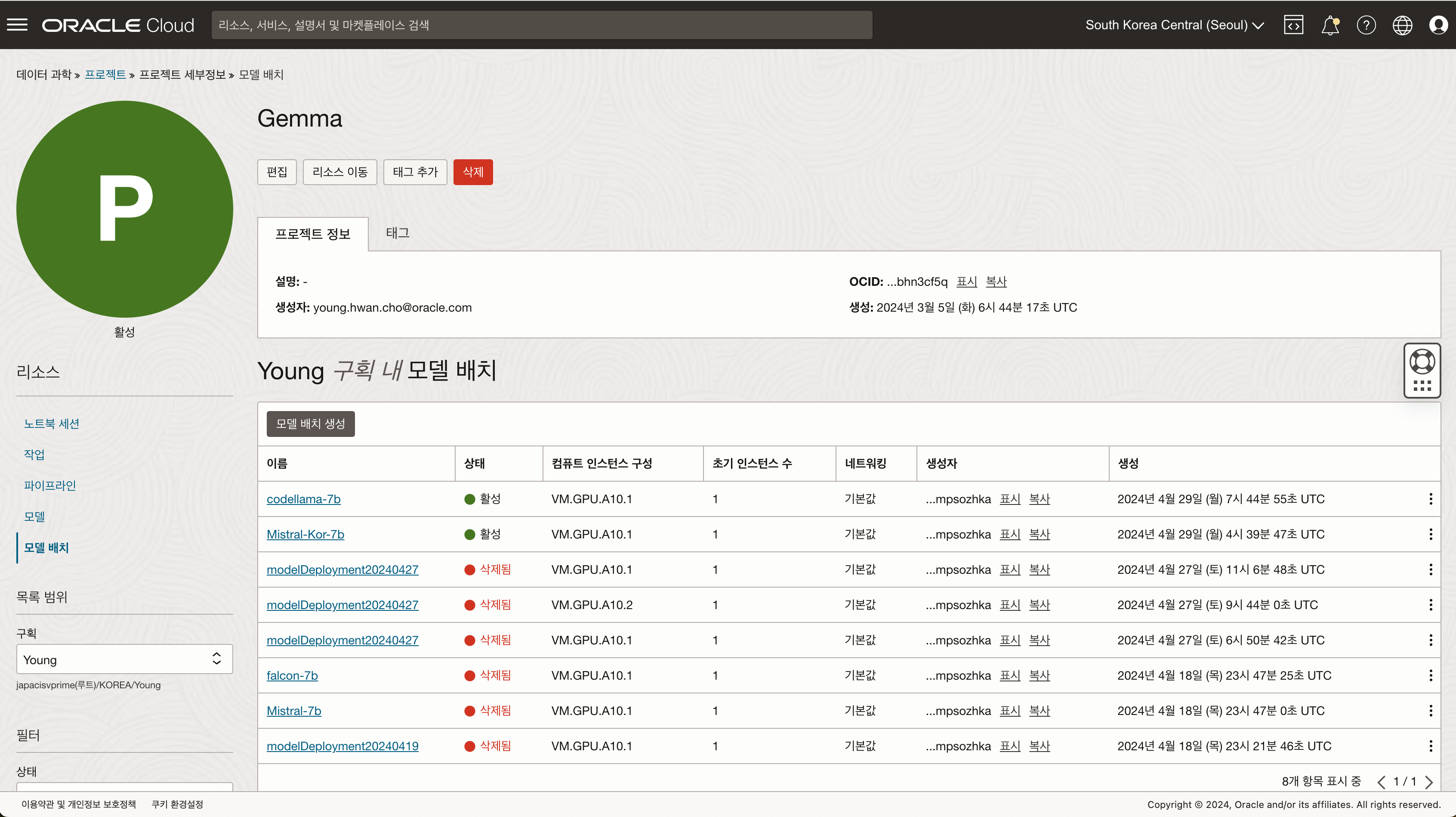
- 비활성화 하고자 하는 모델 배치의 액션 버튼을 클릭 후 “비활성화” 버튼을 클릭합니다.
이 글은 개인적으로 얻은 지식과 경험을 작성한 글로 내용에 오류가 있을 수 있습니다. 또한 글 속의 의견은 개인적인 의견으로 특정 회사를 대변하지 않습니다.
Younghwan Cho AIML
oci data science generative ai gen ai aqua ai quick action ai llm