Data Science
Python 코드를 활용하여 OCI DLS(Data Labeling Service)의 레코드에 라벨링 하기
Table of Contents
시작하기 앞서…
이번 포스팅에서는 OCI의 Data Labeling 서비스에서 데이터 집합을 라벨링 하는 과정을 소스코드(Python)을 통해 자동화 하는 샘플 코드 실습을 진행할 예정입니다. 공식 샘플코드에서는 Java 버전도 존재하지만 이번 포스팅에서는 Python 언어로 실습을 진행할 예정입니다.
사전 준비 사항
- Oracle Cloud Infrastructure(OCI) 계정.
- 만약 OCI 계정이 없는 경우 OCI 무료 계정 생성하기를 통해 무료계정 생성 후 진행 필요
- 파이썬 3버전 이상이 설치된 개인 PC
- OCI CLI 도구 설정
- OCI CLI 도구 설정하기 통해 설정 후 진행이 필요합니다.
샘플 코드 다운로드 받기 (Python)
실습에 앞서 실습에 필요한 소스코드를 링크로 이동하여 다운로드 받습니다.
- 소스코드 직접 다운로드 : 링크의 레파지토리 최상위 폴더로 이동하여 “CODE” 버튼 클릭 -> “Download ZIP” 버튼을 클릭하여 다운로드 받습니다.
- 레파지토리 클론 : 소스코드를 다운받으려는 위치에서 git clone 명령어를 통해 소스코드를 다운로드 받습니다.
$ git clone https://github.com/oracle-samples/oci-data-science-ai-samples.git
소스 코드별 역할 소개
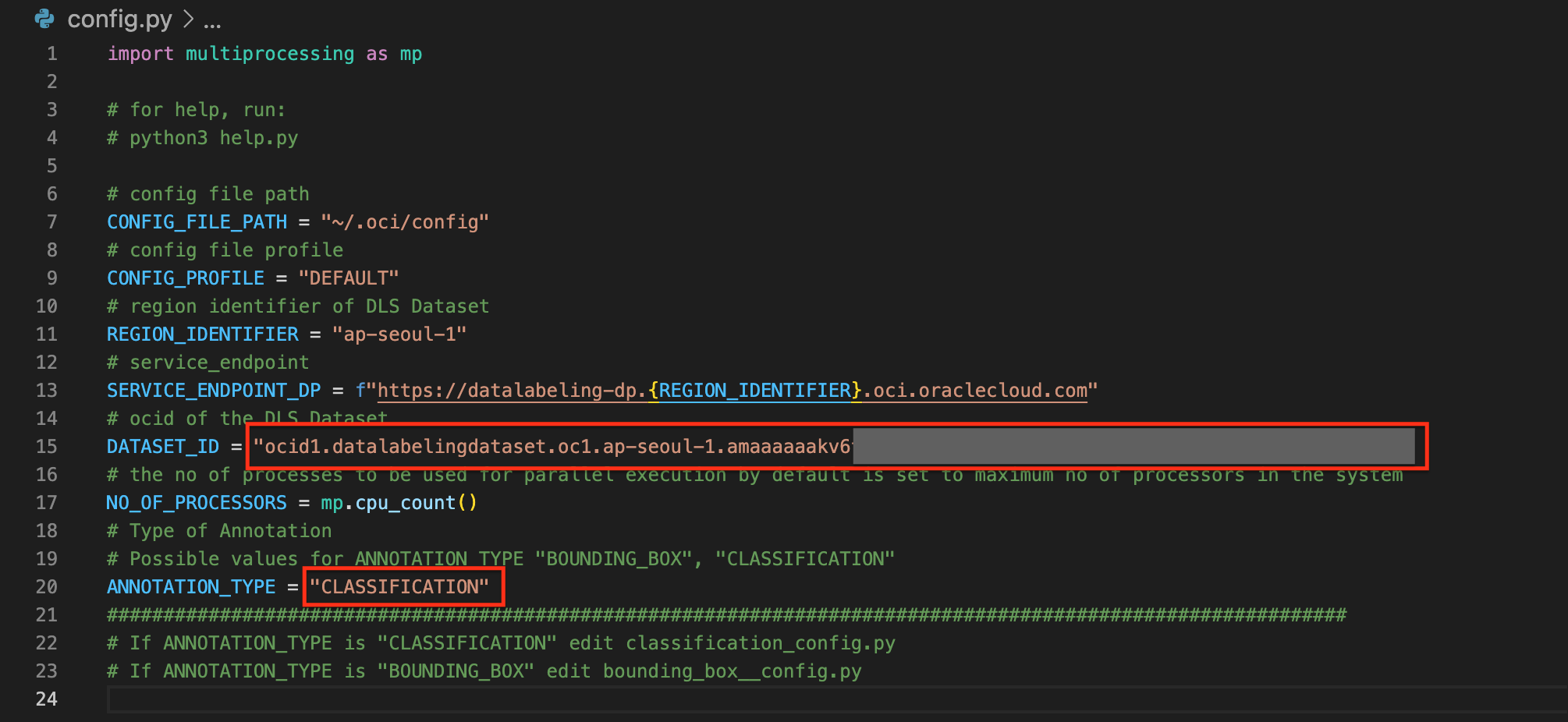
- config.py : 샘플 코드 실행을 위한 설정 정보를 작성하는 파일
# config file path CONFIG_FILE_PATH = "~/.oci/config" # config file profile CONFIG_PROFILE = "DEFAULT" # region identifier of DLS Dataset REGION_IDENTIFIER = "ap-seoul-1" # service_endpoint SERVICE_ENDPOINT_DP = f"https://datalabeling햐-dp.{REGION_IDENTIFIER}.oci.oraclecloud.com" # ocid of the DLS Dataset DATASET_ID = "[데이터셋의 OCID를 이곳에 작성합니다.]" # the no of processes to be used for parallel execution by default is set to maximum no of processors in the system NO_OF_PROCESSORS = mp.cpu_count() # Type of Annotation # Possible values for ANNOTATION_TYPE "BOUNDING_BOX", "CLASSIFICATION" ANNOTATION_TYPE = "CLASSIFICATION" ############################################################################################################## # If ANNOTATION_TYPE is "CLASSIFICATION" edit classification_config.py # If ANNOTATION_TYPE is "BOUNDING_BOX" edit bounding_box__config.py - classification_config.py : config.py 파일에서 ANNOTATION_TYPE 을 CLASSIFICATION 으로 지정한 경우 사용되는 설정 파일
# maximum number of DLS Dataset records that can be retrieved from the list_records API operation for labeling # limit=1000 is the hard limit for list_records LIST_RECORDS_LIMIT = 1000 # the algorithm that will be used to assign labels to DLS Dataset records # Possible values for labeling algorithm "FIRST_LETTER_MATCH", "FIRST_REGEX_MATCH", "CUSTOM_LABELS_MATCH" LABELING_ALGORITHM = "CUSTOM_LABELS_MATCH" # an array where the elements are all of the labels that you will use to annotate records in your DLS Dataset with. # Each element is a separate label. LABELS = ["dog", "cat"] # use for first_match labeling algorithm FIRST_MATCH_REGEX_PATTERN = r'^([^/]*)/.*$' # For CUSTOM_LABEL_MATCH specify the label map LABEL_MAP = {"dog/": ["dog", "pup"], "cat/": ["cat", "kitten"]} - bounding_box_config.py : config.py 파일에서 ANNOTATION_TYPE 을 BOUNDING_BOX 으로 지정한 경우 사용되는 설정 파일
# the path of the csv file PATH = "/Users/puneetmittal/Desktop/input_data.csv" - bulk_labeling_script.py : 실제 벌크 라벨링을 수행하기 위한 로직이 작성되어 있는 파일
Bulk Labeling 실행하기
데이터셋 준비
- 데모 데이터셋 링크를 클릭하여 데이터셋을 다운로드 받습니다.
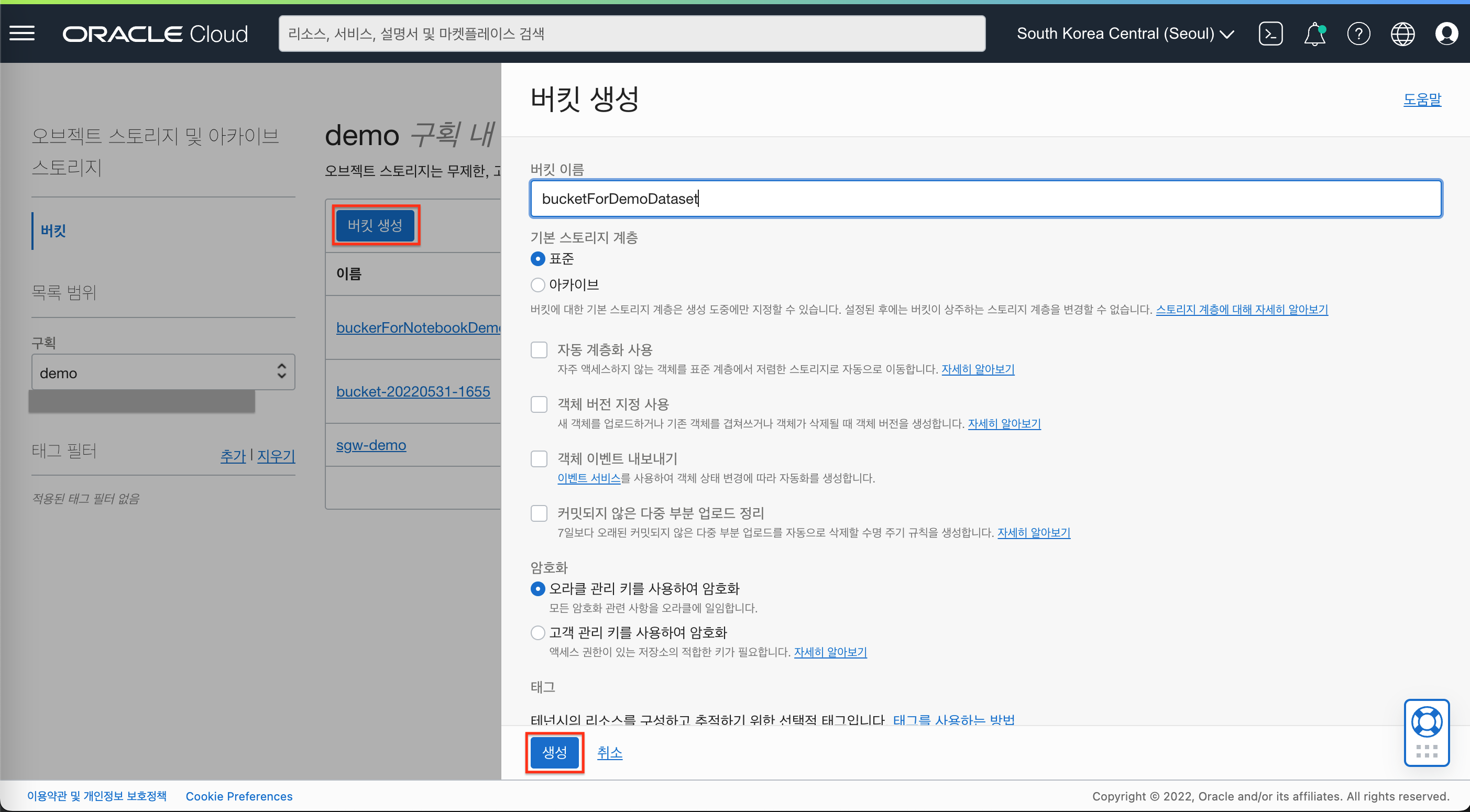
- 다운로드 받은 데이터셋을 업로드할 버킷을 생성합니다. (햄버거 메뉴 -> “스토리지” -> “버킷”)
- 버킷이름 : bucketForDemoDataset
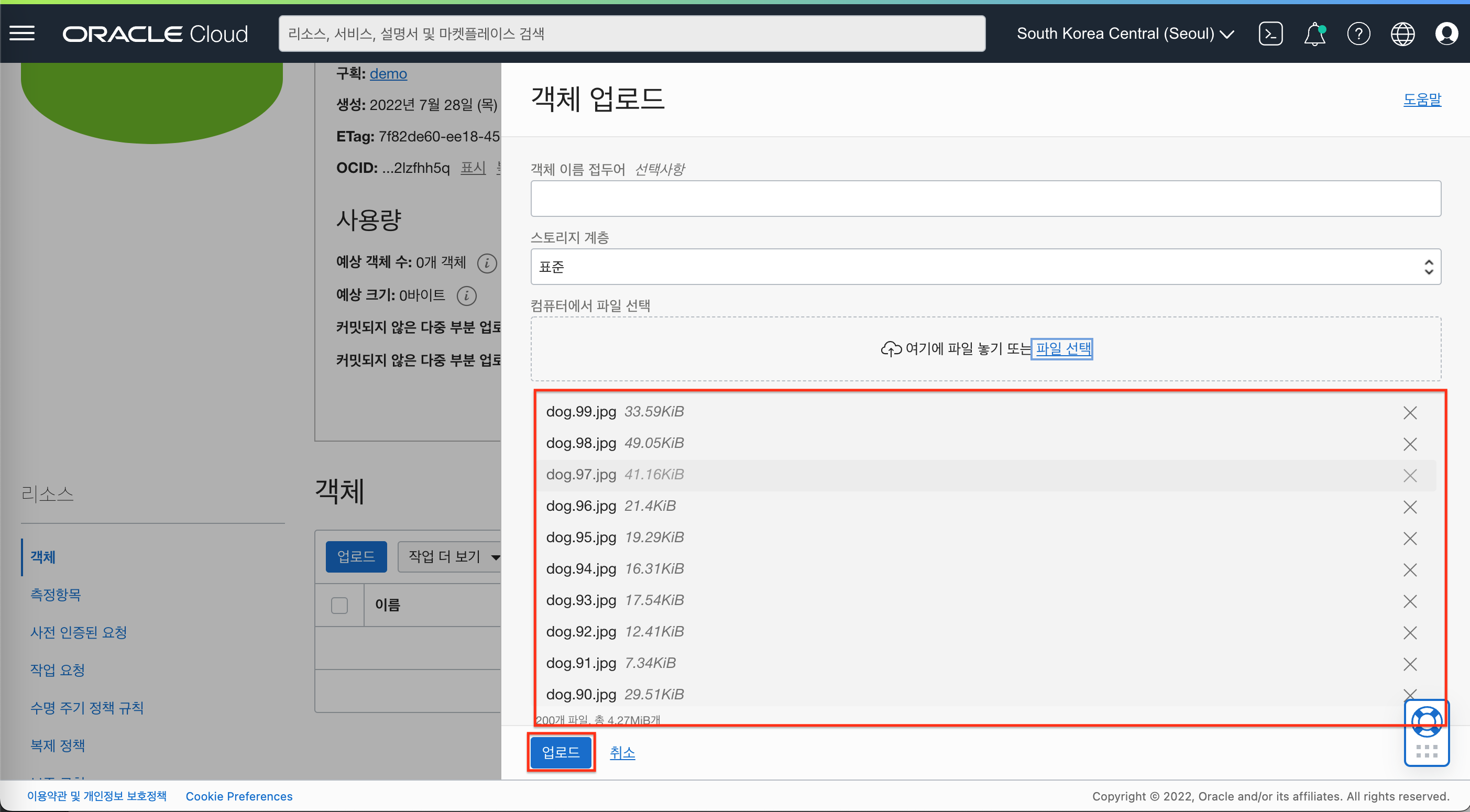
- 다운로드 받은 파일의 압축을 해제하여 모두 업로드 합니다.
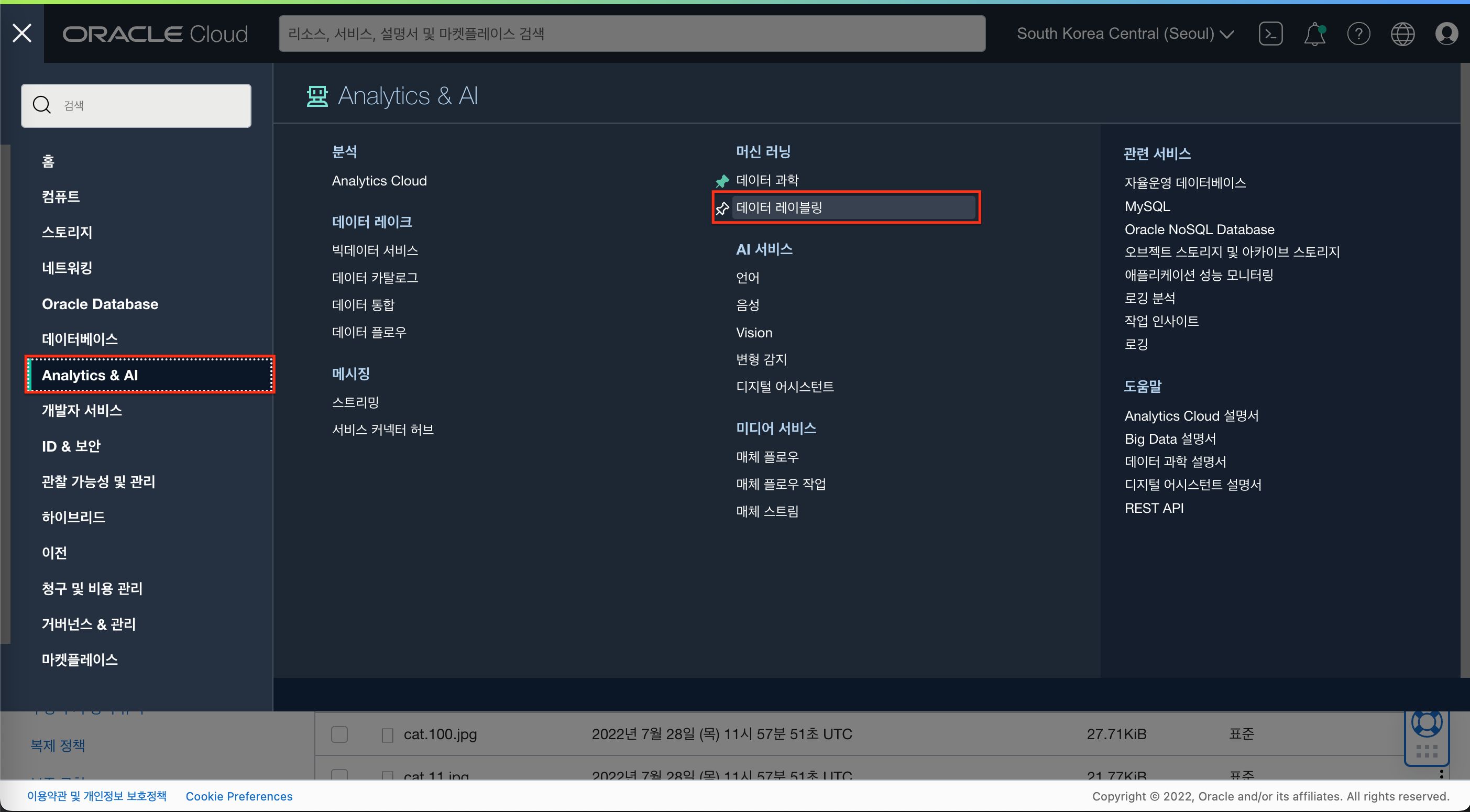
Data Labeling 생성
- 햄버거 메뉴를 클릭하고 “Analytics & AI” -> “데이터 레이블링” 메뉴를 클릭합니다.
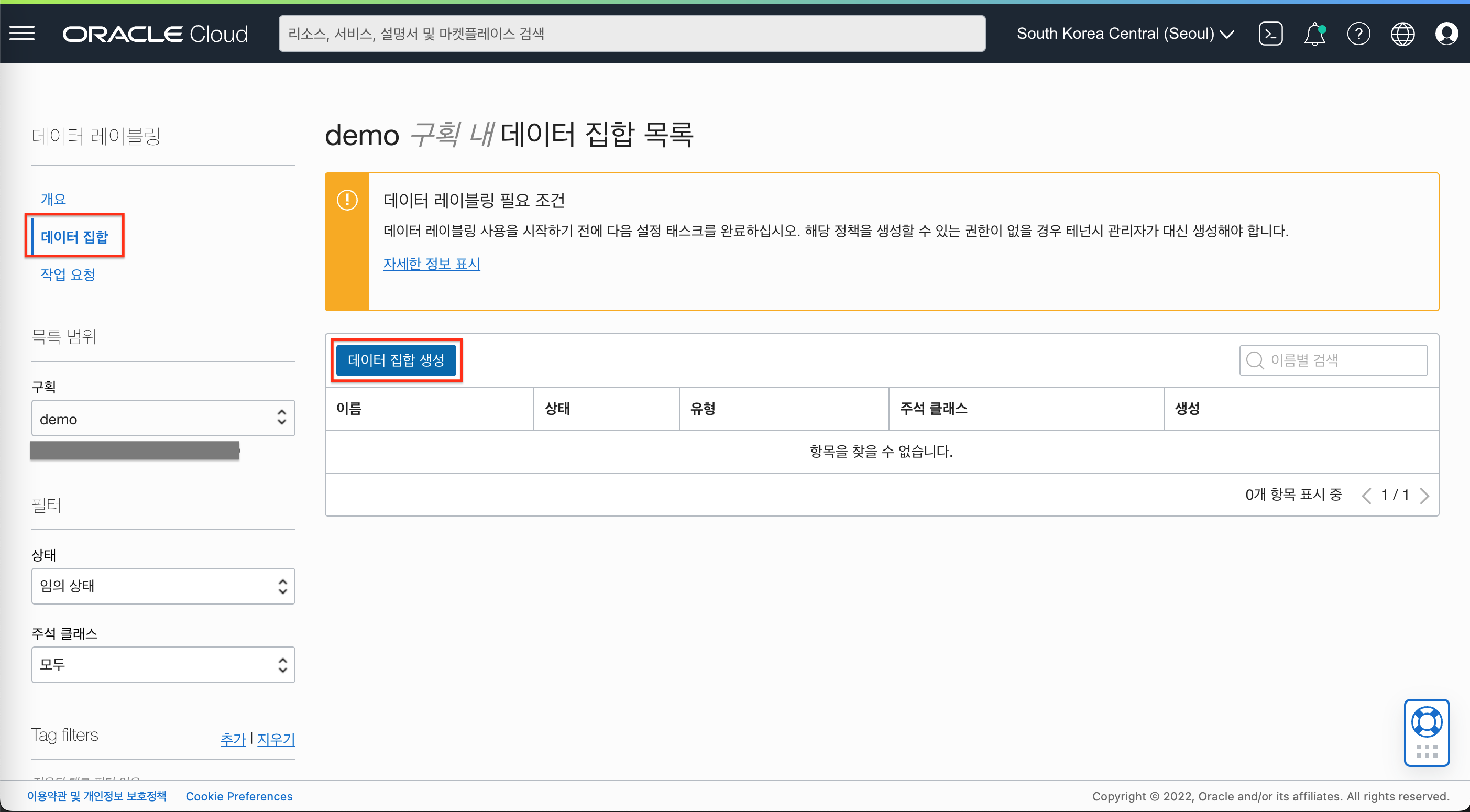
- “데이터 집합” 메뉴를 클릭하고, “데이터 집합 생성” 버튼을 클릭합니다.
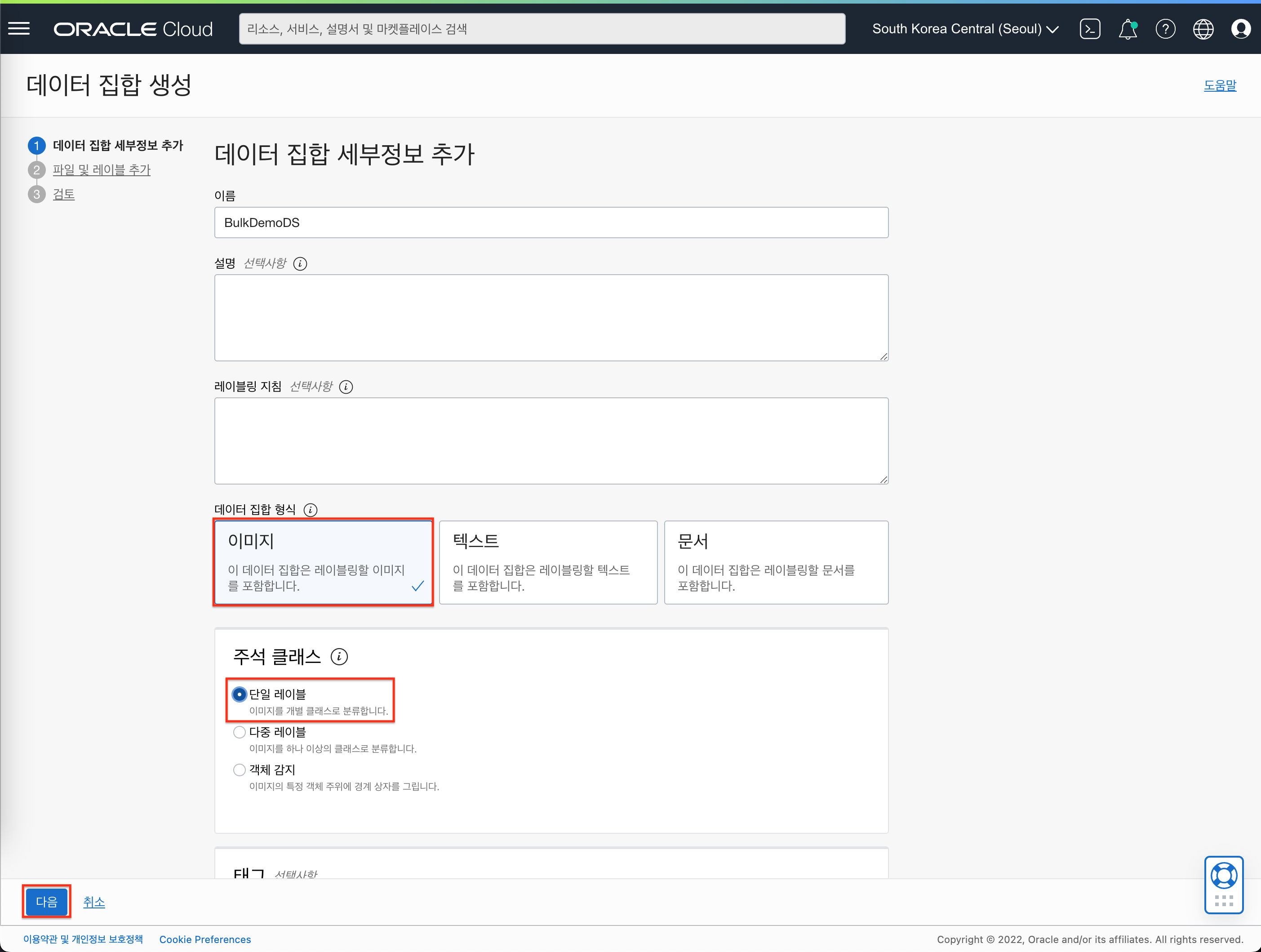
- 아래와 같이 선택 및 입력합니다.
- 이름 : BulkDemoDS
- 데이터 집합 형식 : 이미지
- 주석 클래스 : 단일 레이블
- “다음” 버튼을 클릭합니다.
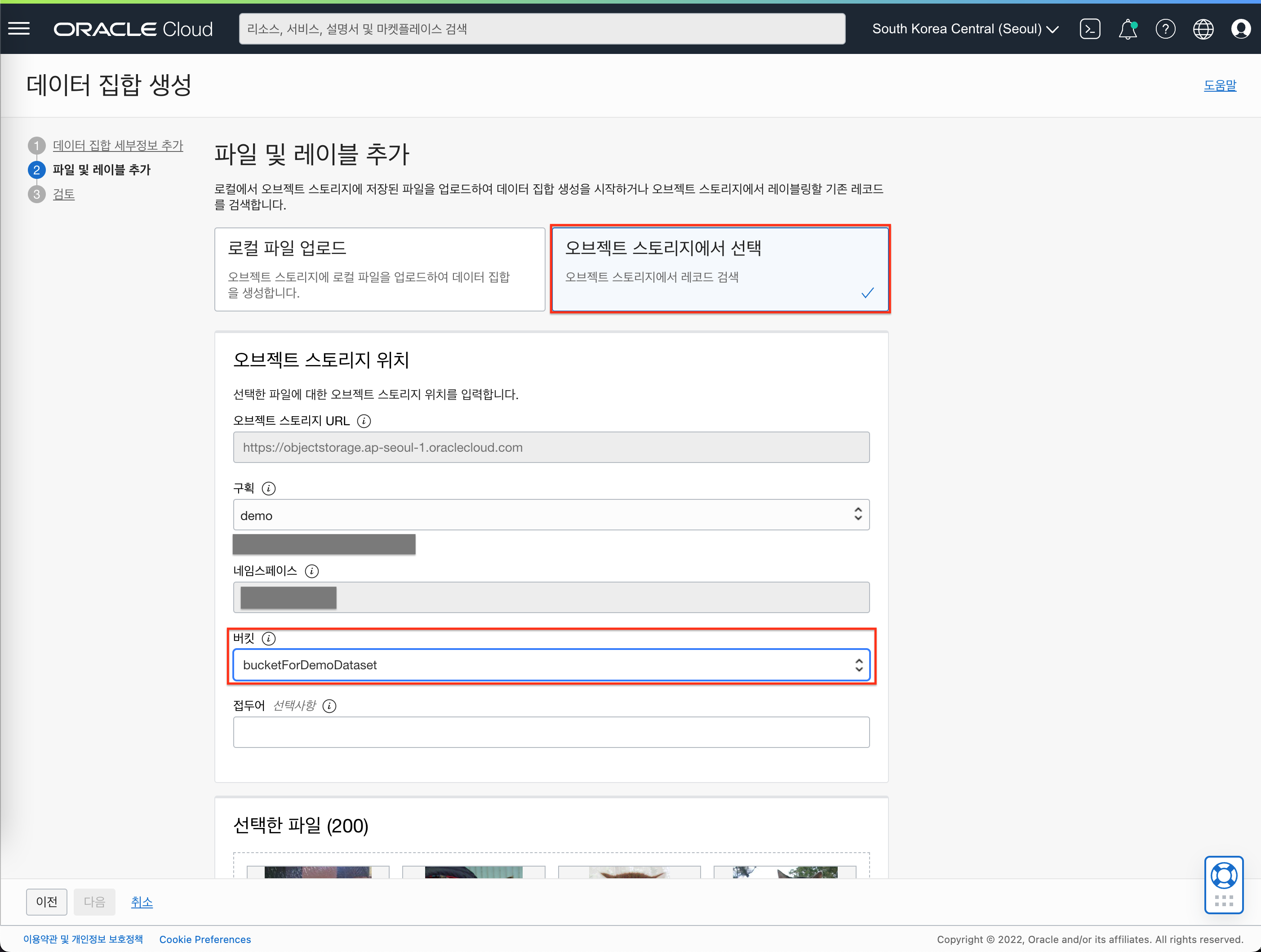
- 아래와 같이 선택 및 입력합니다.
- “오브젝트 스토리지에서 선택” 유형을 선택합니다.
- 버킷 : bucketForDemoDataset 선택
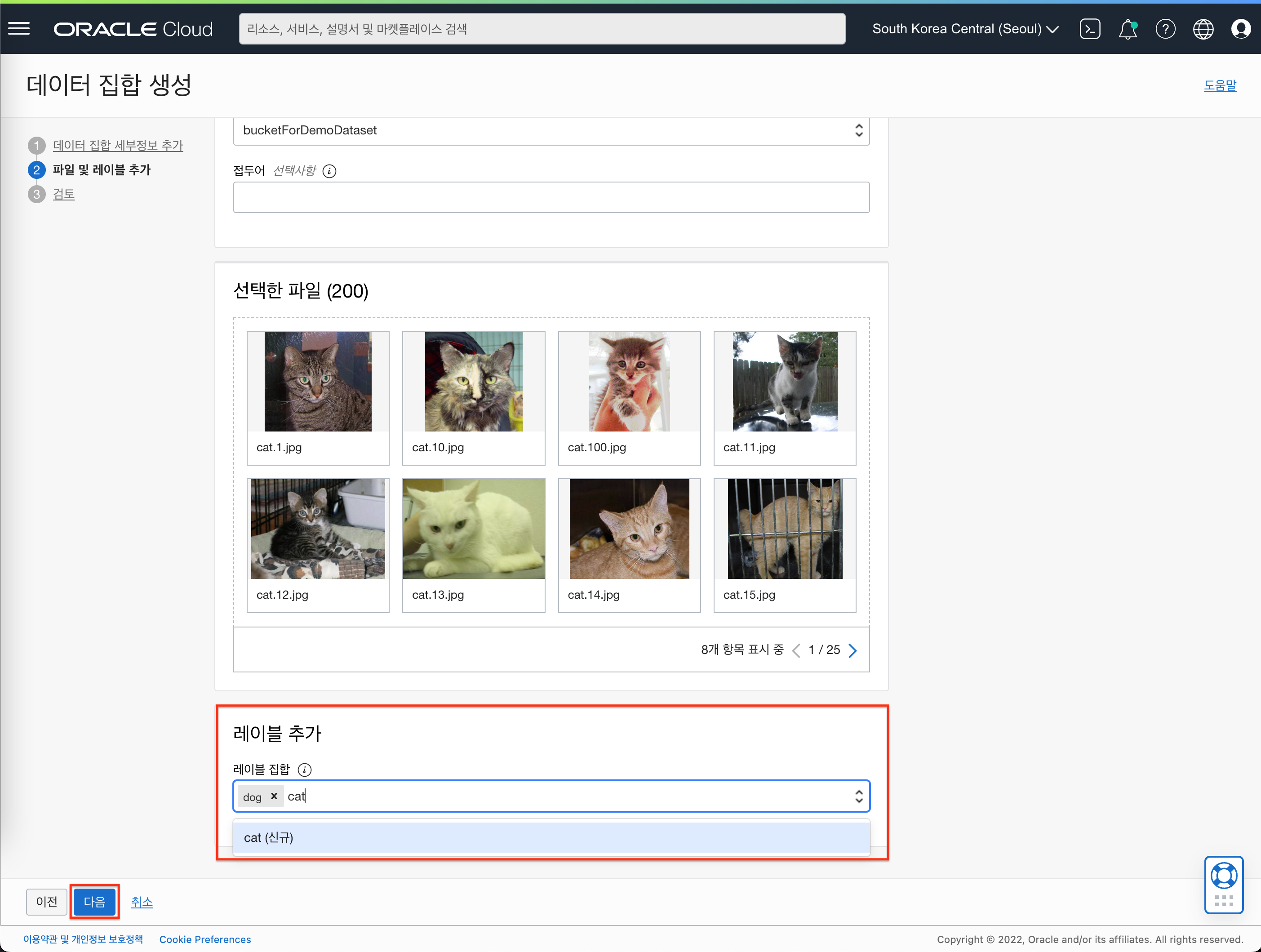
- 아래와 같이 선택 및 입력합니다.
- 레이블 추가 : dog, cat을 차례대로 입력 합니다. (단어 하나씩 입력 후 엔터)
- “다음” 버튼을 클릭합니다.
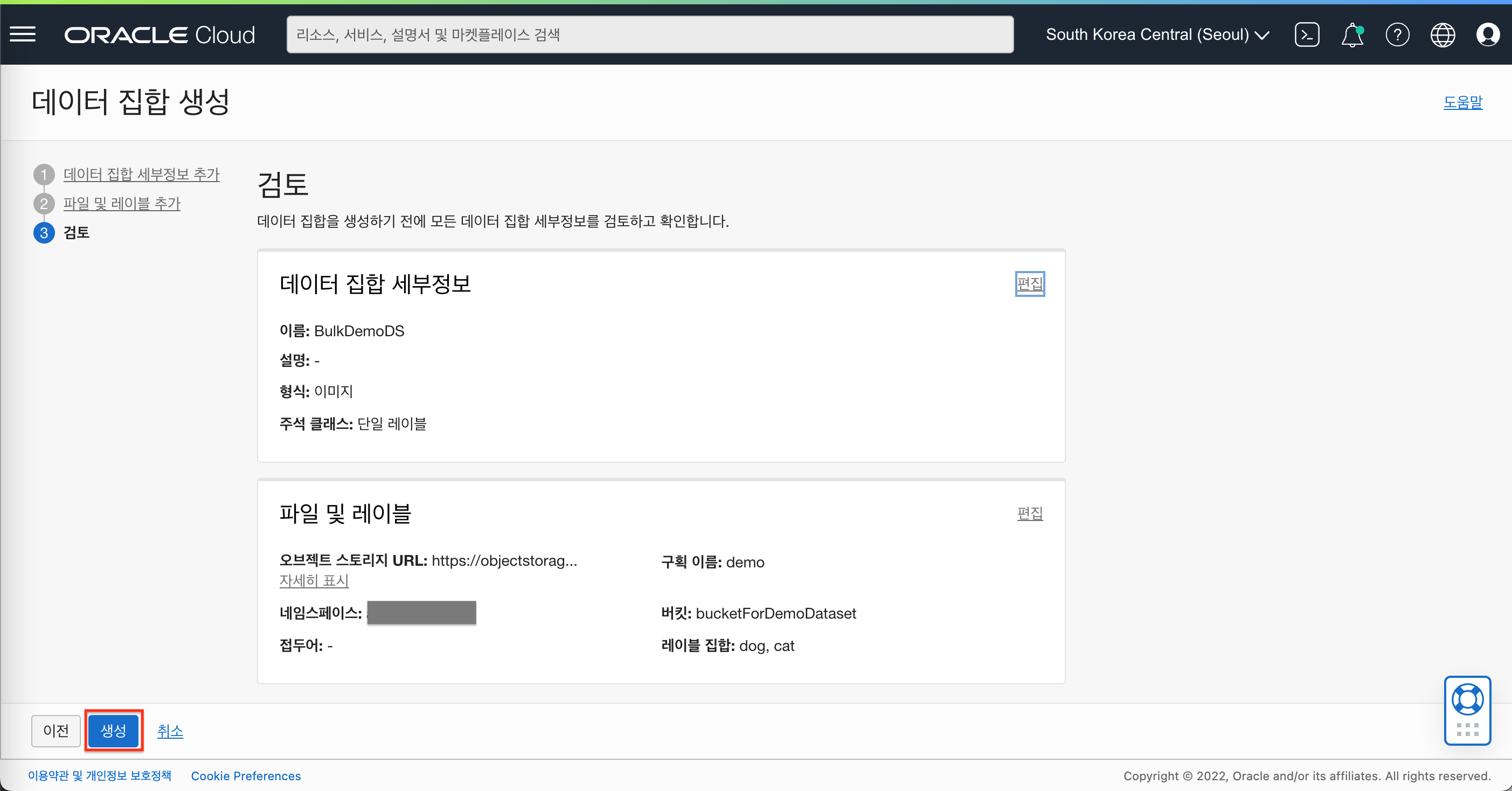
- 생성 정보를 확인 후 “생성” 버튼을 클릭하여 데이터셋을 생성합니다.
- 데이터셋 생성 확인
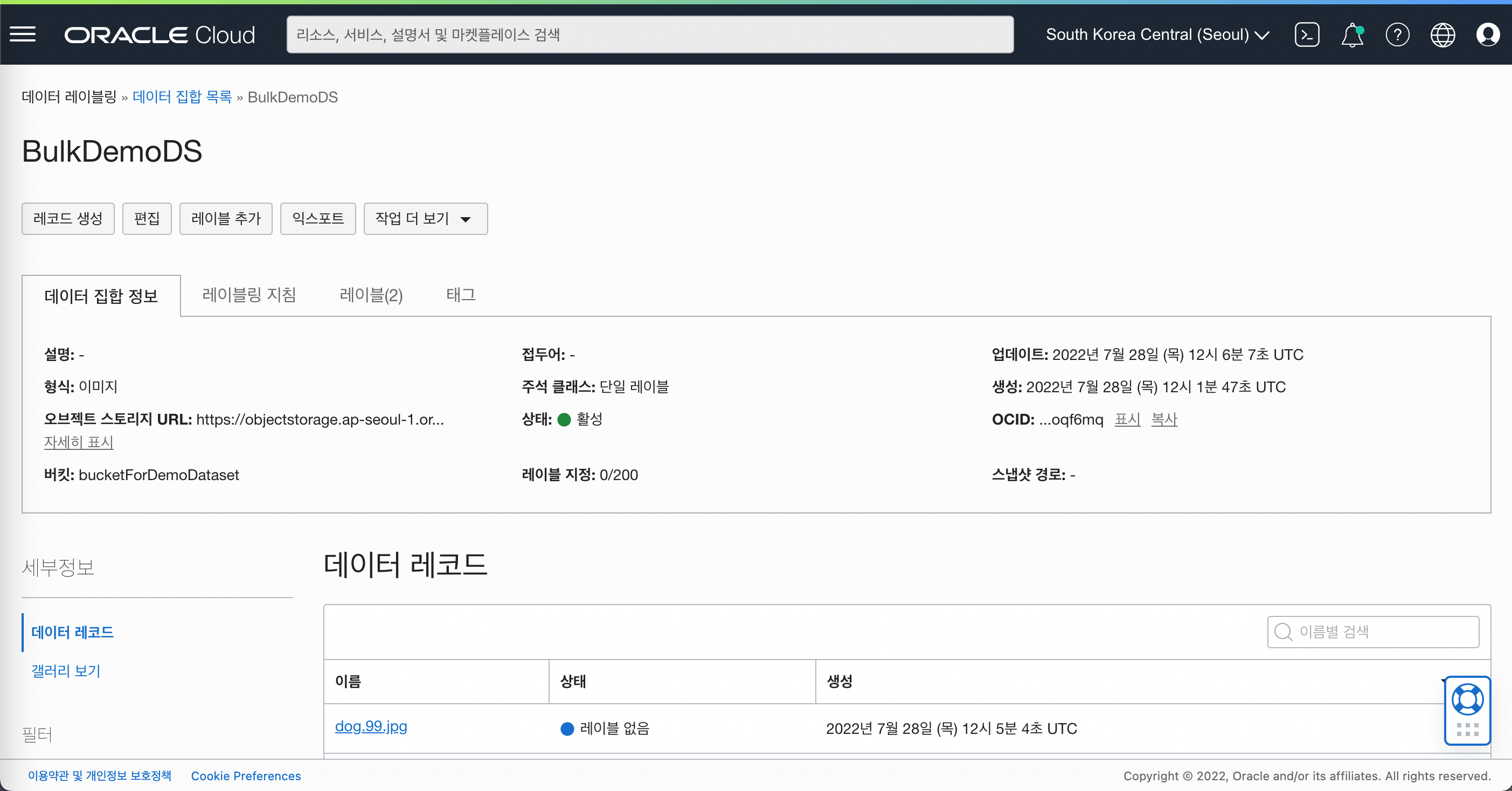
설정파일 변경
- config.py 파일의 내용을 변경합니다.
- DATASET_ID : 위 단계에서 생성한 데이터 집합의 OCID를 입력합니다.
- ANNOTATION_TYPE : CLASSIFICATION
- classification_config.py 파일의 내용을 아래와 같이 변경합니다.
- LABELING_ALGORITHM : FIRST_LETTER_MATCH
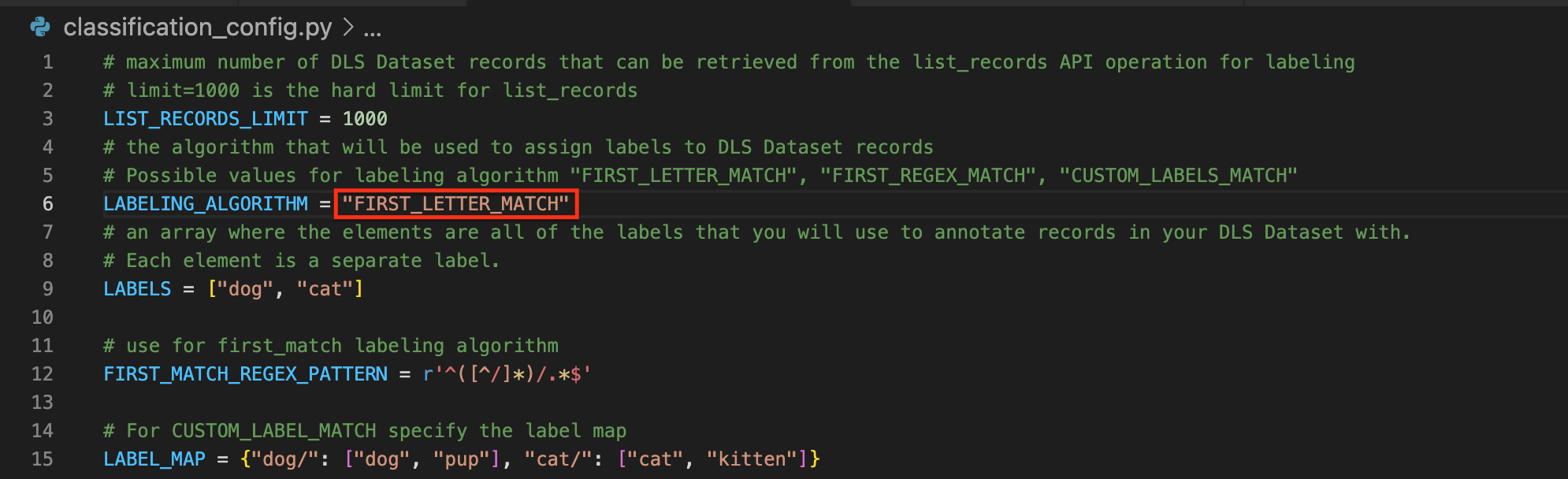
- LABELING_ALGORITHM : FIRST_LETTER_MATCH
실행 및 결과 확인
- 터미널에서 아래와 같이 입력하여 Bulk Labeling 을 실행합니다.
$ python3 bulk_labeling_script.py - 실행 결과 예시 (200개 레코드 약 24초에 처리 완료)
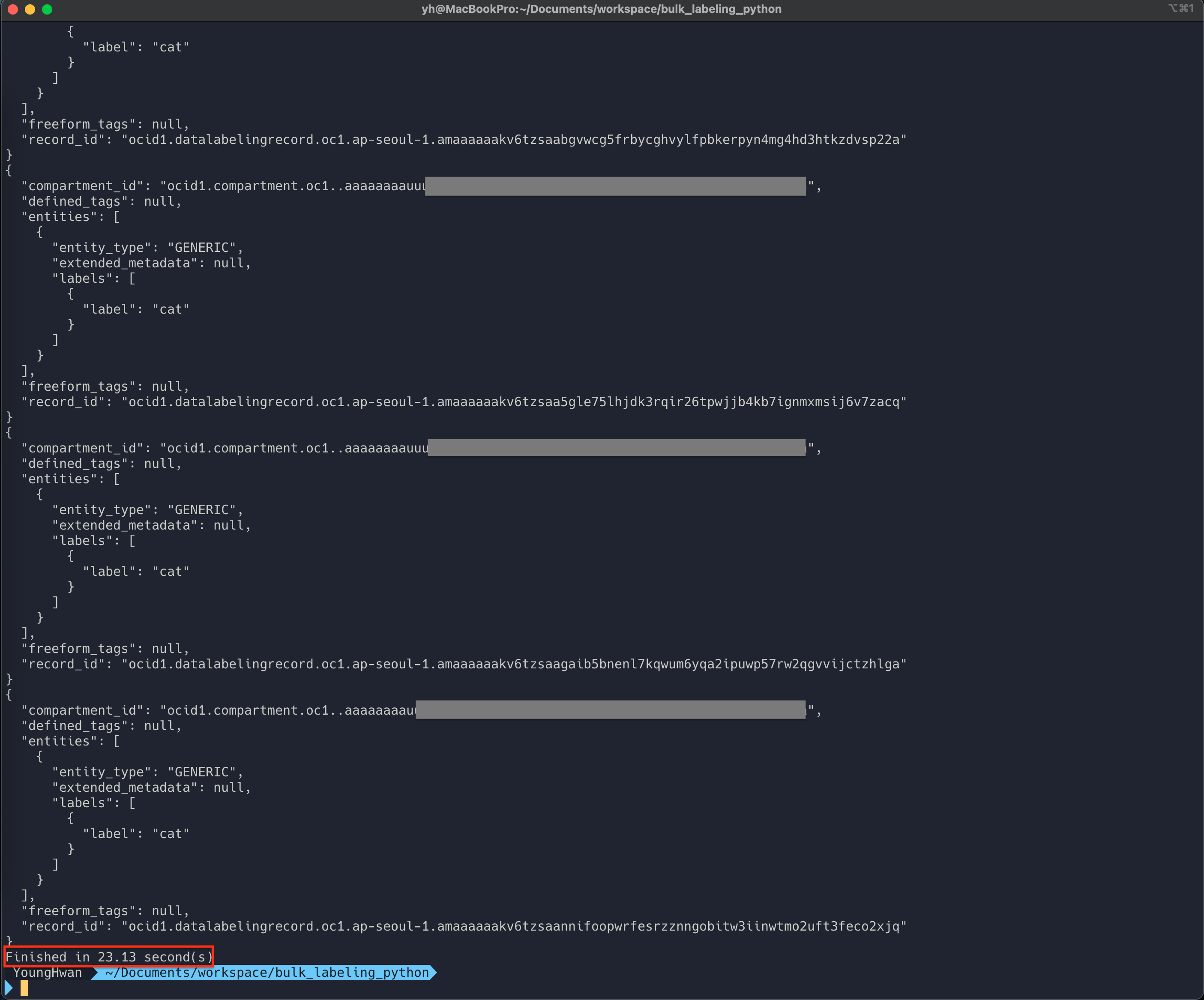
- 라벨링 결과 확인
- 라벨링 완료된 레코드 수치 확인
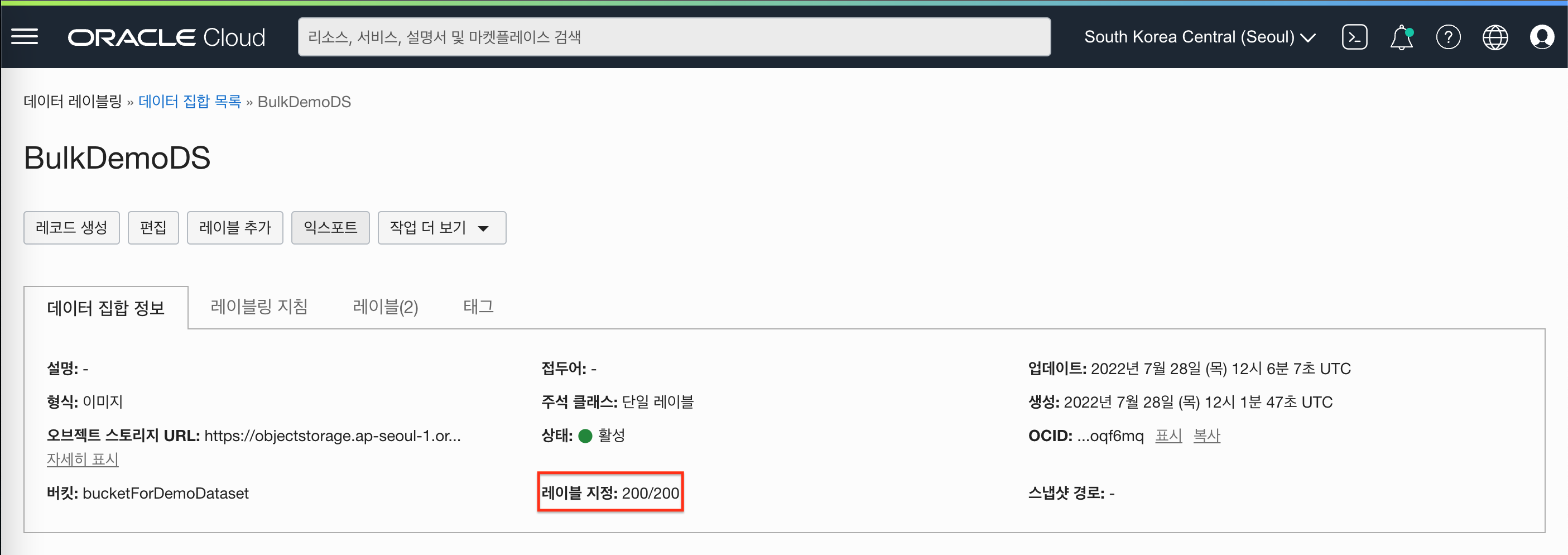
- 라벨링 된 레코드의 레이블 확인
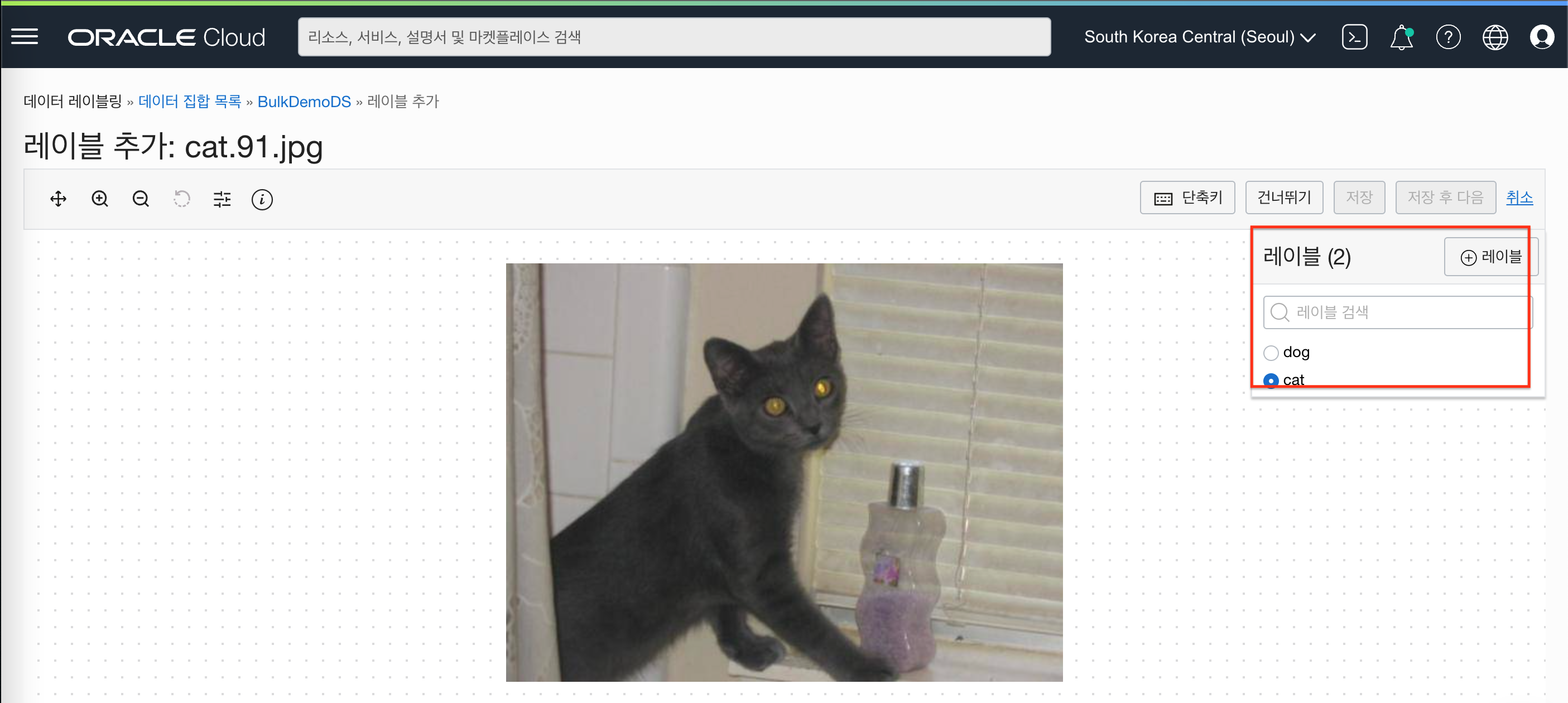
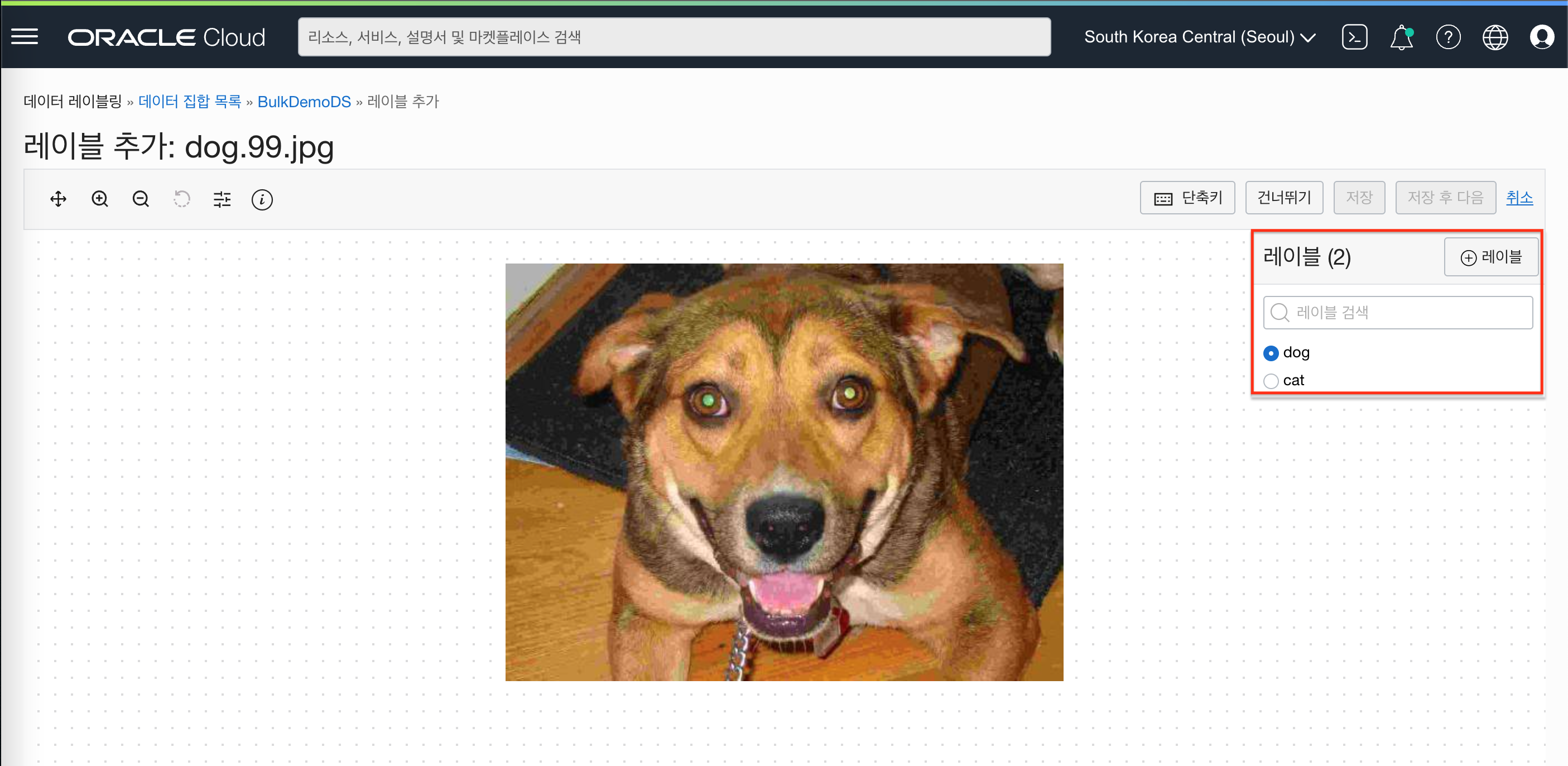
- 라벨링 완료된 레코드 수치 확인
이 글은 개인적으로 얻은 지식과 경험을 작성한 글로 내용에 오류가 있을 수 있습니다. 또한 글 속의 의견은 개인적인 의견으로 특정 회사를 대변하지 않습니다.
Younghwan Cho AIML
oci data science data labeling python bulk labeling